asyncioについて
概要
Python3.4以降の標準ライブラリに含まれている、非同期処理を実現させるためのライブラリです。非同期処理は主に、シングルスレッド内で複数のI/Oバウンドな処理を効率的に実行するために使用されます。
I/Oバウンドな処理であれば、asyncioによる非同期処理化により、他のタスクへの切り替えが可能なため、実行時間の大幅な短縮が見込めます。一方、CPUバウンドな処理の場合は、その処理がシングルスレッド内で完結するため、他のタスクへの切り替えができず、asyncioによる高速化はあまり期待できません。CPUバウンドな処理を高速化するためには、マルチスレッディングやマルチプロセッシングなどの並列処理手法を用いる必要があります。
Column: 非同期処理と並列処理は別物である
これらは似た概念であり、混同しがちですが、実際には別物です。
並列処理 (Parallel Processing)
複数のタスクやプロセスが同時に異なるCPUコアで実行される処理手法。
例:マルチコアのCPUを使って、複数のタスクを同時に実行する場合。
Pythonの場合、multiprocessingモジュールが典型的な並列処理をサポートしています。
非同期処理 (Asynchronous Processing)
シングルスレッドの中で、複数のタスクを「効率的に」実行する方法。ブロッキングされる操作(例えばI/O操作)が発生した場合、他のタスクに切り替えて効率的に待ち時間を減少させる。
例:Webサーバーが複数のクライアントからのリクエストを効率的に処理する場合。
Pythonの場合、asyncioは非同期処理をサポートするためのライブラリです。
使い分けについて:
- CPUバウンドのタスク(計算処理が重いタスク):
- 並列処理を使用して、複数のCPUコアを効率的に使用します。Pythonでは、multiprocessingやconcurrent.futuresのProcessPoolExecutorを使ってこれを実現できます。
- I/Oバウンドのタスク(ネットワークやディスクへのアクセスなど、待ち時間が発生しやすいタスク):
- 非同期処理を使用して、待ち時間中に他のタスクを進めます。Pythonでは、asyncioや関連する非同期ライブラリを使って実現できます。
ただし、現代の多くのアプリケーションでは、並列処理と非同期処理の両方の利点を組み合わせることがよくあります。例えば、非同期I/Oを使用しながら、CPUバウンドの部分を別のプロセスで並列に実行する、といったことが考えられます。
コルーチン
一時中止や再開が自由に行えるオブジェクト。このオブジェクトをベースとして非同期的な処理を実現するため、この概念がasyncioの核になります。
コルーチンというと、基本的にはコルーチン関数かコルーチンオブジェクトを指します。コルーチン関数は以下のようにasync defで定義された関数です。
async def co_routine():
# some task running...
print("finished")
コルーチンオブジェクトとは、コルーチン関数を呼び出した際に作成されるオブジェクトのことです。
co_obj = await co_routine()
Taskオブジェクト
上記のコルーチン関数はそのままでは実行できず、基本的にはasyncio.create_task(coro_obj)のようにTaskオブジェクトとしてwrapしてあげる必要があります。
流れとしては、以下のようにしてTaskオブジェクトに変換した後に実行します。
task = asyncio.create_task(co_routine())
asyncio.run(task)
※ 後述するloop.run_until_complete(co_routine())やasyncio.ru(co_routine())のように、コルーチンオブジェクトのまま実行関数に渡すこともできますが、こうした場合は、内部的にTaskオブジェクトに変換(wrap)してから実行されています。ただ、処理の理解を深めるために最初のうちは毎回明示的にTaskオブジェクトに変換した方が良いかなと思います。
Column: ガベージコレクション
少し難しい話なのですが、こちらのTaskオブジェクト、ほっとくと勝手に消えてしまうようです。
Python では、オブジェクト(例えばリスト、辞書、クラスのインスタンスなど)はメモリ内に存在し続けるために、少なくとも1つ以上の参照を保持している必要があります。オブジェクトへの全ての参照が失われた時点で、そのオブジェクトは不要になったとみなされ、ガベージコレクションの対象となります。つまり、そのオブジェクトが使用していたメモリ領域が解放され、再利用可能になるということです。
ここで、Taskオブジェクトは弱参照という状態でオブジェクトを保持するようで、ほかに参照元がなければ、そのタスクが完了していなくてもホストマシンの機嫌次第でガベージコレクションの対象となり、タスクが途中で終了してしまう可能性があるらしいです。
そのため、安全にタスクを実行し続けるためには、作成したタスクへの強参照(strong reference)を保持しておく必要があります。以下のように、リストか集合などに格納しておけば大丈夫みたいです。
tasks = []
tasks.append(task_1)
tasks.append(task_2)
tasks = set()
tasks.add(task_1)
tasks.add(task_2)
Futureオブジェクト
Futureオブジェクトは、未来のある時点で計算される結果を表す特殊な低レベルの待機可能オブジェクトです。コルーチンの実行が終了すると、その結果を保持する役割を果たします。
Taskオブジェクトと混同してしまいがちで、何が違うの?となりがちなのですが、TaskオブジェクトはFutureクラスのサブクラスです。Futureオブジェクトにいくつかの機能(コルーチンのスケジューリングと実行)がくっついたものがTaskオブジェクトになります。
アプリケーション実装者としては、Futureクラスをそのまま使用することはほとんどなく、基本的にはTaskオブジェクトを使用するため、特別意識する必要はなさそうです。
イベントループ
コルーチン、またはTaskオブジェクトを実行するためのものです。
コルーチン、またはTaskオブジェクトを実行できるのはイベントループ内でのみだけです。
例えば、以下のようなコードはRuntimeWarning: coroutine 'co_routine' was never awaitedエラーになります。
async def co_routine():
await asyncio.sleep(1)
print("main")
if __name__ == '__main__':
co_routine()
Taskオブジェクトの場合はRuntimeError: no running event loopとなります。これは、Taskオブジェクトが実行される際にevents.get_running_loop()関数が内部的に呼び出されるため、イベントループがない場合にエラーになるためです。
async def co_routine():
await asyncio.sleep(1)
print("main")
if __name__ == '__main__':
asyncio.create_task(co_routine())
以下のようにすることでイベントループを作成し、コルーチン、またはTaskオブジェクトを実行します。
async def co_routine():
await asyncio.sleep(1)
print("main")
if __name__ == '__main__':
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(co_routine()) # 内部的にTaskオブジェクトに変換されてからrunされる
loop.close()
ただ、asyncioにはasyncio.run()という、イベントループの作成からクローズまで一括で面倒を見てくれる便利な関数が存在するため、上記のように明示的にイベントループの作成をすることはあまりないかもしれません。
Column: OSスレッドとイベントループ
イベントループは、OSスレッド1つにつき1つまでしか存在できません。この制限は、OSスレッドとイベントループの関連、およびスレッドセーフな設計に基づいています。
スレッドは、プロセス内の実行単位であり、プロセス内で並列に実行することができます。1つのプロセスは1つ以上のスレッドを持ち、それぞれのスレッドは独自の実行コンテキスト(例:レジスタの値、プログラムカウンタなど)を持ちますが、メモリ空間(ヒープ、データセグメントなど)は共有します。
スレッドごとに独自のイベントループを持つことで、イベントの処理とタスクのスケジューリングがスレッドローカルに保持されます。これにより、スレッドのコンテキストを切り替えることなく、非同期の操作を効率的に管理することができます。複数のイベントループが1つのスレッドに存在すると、互いの操作に影響を及ぼす可能性があり、デッドロックや競合状態などの問題を引き起こす可能性があります。
asyncio.run()
asyncio.run()はPython 3.7から導入された、コルーチンの最も簡単な実行方法です。これを使用すると、イベントループの作成、コルーチンの実行、ループのクリーンアップが自動的に行われます。
こちらを使用した場合、上記の実行コードが以下のようにかなり簡潔になります。基本的にはこちらを使えば問題ないです。
async def co_routine():
await asyncio.sleep(1)
print("main")
if __name__ == '__main__':
asyncio.run(co_routine()) # 内部的にTaskオブジェクトに変換されてからrunされる
複数のコルーチンをまとめて実行する
今までの話の流れを整理すると、非同期処理の大まかな流れは↓の画像のようになっています。
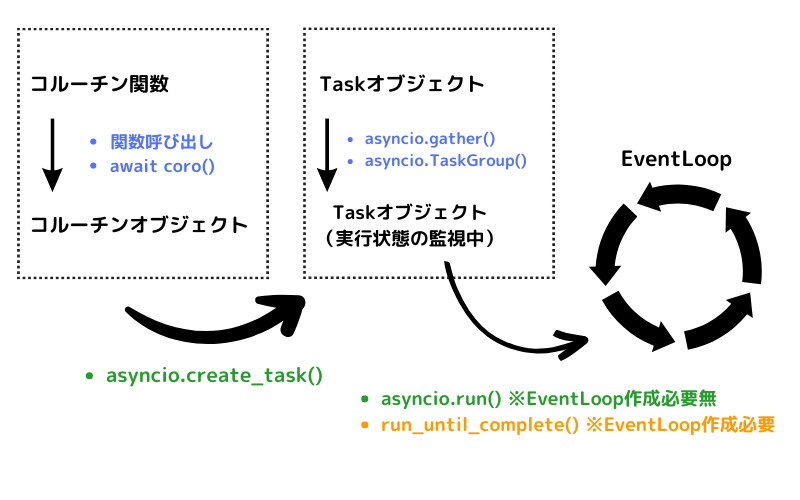
asyncio.gather()
asyncio.gather(*coros)は、複数のコルーチンを同時に実行するための関数です。渡されたコルーチンを並行して実行し、すべてのコルーチンが完了するのを待ちます。各コルーチンの結果は、渡された順序と同じ順序で結果のリストとして返されます。
async def say_hello(name, delay):
await asyncio.sleep(delay)
print(f"Hello, {name}!")
return f"{name} said hello"
async def main():
result = await asyncio.gather(
say_hello("Alice", 1), # 内部的にTaskオブジェクトに変換されている
say_hello("Bob", 2),
say_hello("Charlie", 3)
)
return result
result = asyncio.run(main())
print(result) # ["Alice said hello", "Bob said hello", "Charlie said hello"]
asyncio.TaskGroup()
Python3.11から追加された機能で、タスクの非同期実行を高い可読性で記述できます。公式ドキュメントではgather()の項目で以下のような注釈があり、gather()よりもTaskGroup()の使用を推奨しています。
注釈 A more modern way to create and run tasks concurrently and wait for their completion is asyncio.TaskGroup.
async def say_hello(name, delay):
await asyncio.sleep(delay)
print(f"Hello, {name}!")
return f"{name} said hello"
async def main():
async with asyncio.TaskGroup() as tg:
task1 = tg.create_task(say_hello("Alice", 1))
task2 = tg.create_task(say_hello("Bob", 2))
task3 = tg.create_task(say_hello("Charlie", 3))
return [task1.result(), task2.result(), task3.result()]
result = asyncio.run(main())
print(result) # ["Alice said hello", "Bob said hello", "Charlie said hello"]
asyncioによる非同期処理化の効果検証
Case1: HTTPリクエストの非同期処理化
HTTPリクエストはI/Oバウンドな処理の代表的な例の1つになるので、例として実験してみたいと思います。
以下のコードをベースに考えてみます。HTTPリクエストを愚直に逐次処理で実行しています。
リクエスト先のjsonplaceholderは、開発者向けにREST APIを無料で提供してくれている便利なサービスです。
import requests
from performance import measure_performance
def get_post_title(id: int):
url = 'https://jsonplaceholder.typicode.com/posts'
response = requests.get(url, params={'id': id})
post_title: str = response.json()[0]['title']
print_response(f'post_title_id={id}: {post_title}')
def get_comment_user(id: int):
url = 'https://jsonplaceholder.typicode.com/comments'
response = requests.get(url, params={'id': id})
comment_user: str = response.json()[0]['name']
print_response(f'comment_user_id={id}: {comment_user}')
def get_todo_title(id: int):
url = 'https://jsonplaceholder.typicode.com/todos'
response = requests.get(url, params={'id': id})
todo_title: str = response.json()[0]['title']
print_response(f'todo_title_id={id}: {todo_title}')
def print_response(target: str):
print(f'{target} is finished!!')
def exec_loop(ids: list = [1, 2, 3, 4, 5]):
for id in ids:
get_post_title(id)
get_comment_user(id)
get_todo_title(id)
@measure_performance
def main():
exec_loop()
if __name__ == '__main__':
main()
やっていることとしては、以下のようになります。
- APIリクエストで
jsonplaceholderから特定IDのpost_title、comment_user、todo_titleを取得します。 - この処理を
def exec_loop(ids: list = [1, 3, 4, 6, 7]):の引数idsに入っている個数分だけ繰り返し実行します。
評価指標
パフォーマンスの評価関数として、今回は以下を使用します。
- 実行時間: elapsed_time
- 関数の実行にかかった実際の時間(現実時間)。
今回は以下の関数をデコレータとして使用して、デコレートされた関数のパフォーマンスを計測しています。
import time
def measure_performance(func):
def wrapper(*args, **kwargs):
start_time = time.time() # 処理の開始時間
result = func(*args, **kwargs)
end_time = time.time() # 処理の終了時間
elapsed_time = end_time - start_time # 実行時間の計算
print(f"elapsed_time: {elapsed_time:.3f} sec")
return result
return wrapper
同期処理でのパフォーマンス評価
def exec_loop(ids: list = [1, 2, 3, ..]):の引数idsをいくつか変えてそれぞれ計測してみました。
ids=[1,2,3,4,5]ids=[1,2,3,4,5,6,7,8,9,10]ids=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15]ids=[1,2,3,..,28,29,30]
| 実行時間【1】 | 実行時間【2】 | 実行時間【3】 | 実行時間【4】 |
|---|---|---|---|
| 1.461 (sec) | 3.295 (sec) | 5.208 (sec) | 15.393 (sec) |
メモ:処理が終盤の方になってくると(id=20を超えたあたり)、急に実行スピードが落ちてくるのですが、これは私のマシンパワーの問題ですかね??
非同期化verのコード
この例を非同期処理化する場合、以下のように修正します。
ここでは、非同期化処理に対応したHTTPリクエストのライブラリとしてHTTPXを使用しています。
import asyncio, httpx
from performance import measure_performance
async def get_post_title(id: int):
url = 'https://jsonplaceholder.typicode.com/posts'
async with httpx.AsyncClient() as client:
response = await client.get(url, params={'id': id})
post_title: str = response.json()[0]['title']
await print_response(f'post_title_id={id}: {post_title}')
async def get_comment_user(id: int):
url = 'https://jsonplaceholder.typicode.com/comments'
async with httpx.AsyncClient() as client:
response = await client.get(url, params={'id': id})
comment_user: str = response.json()[0]['name']
await print_response(f'comment_user_id={id}: {comment_user}')
async def get_todo_title(id: int):
url = 'https://jsonplaceholder.typicode.com/todos'
async with httpx.AsyncClient() as client:
response = await client.get(url, params={'id': id})
todo_title: str = response.json()[0]['title']
await print_response(f'todo_title_id={id}: {todo_title}')
async def print_response(target: str):
print(f'{target} is finished!!')
async def exec_loop_with_tg(ids: list = [1, 2, 3, 4, 5]):
async with asyncio.TaskGroup() as tg:
for id in ids:
tg.create_task(get_post_title(id))
tg.create_task(get_comment_user(id))
tg.create_task(get_todo_title(id))
@measure_performance
def main():
asyncio.run(exec_loop_with_tg())
if __name__ == '__main__':
main()
Column: なぜrequestsライブラリではダメなの!?
asyncioでコード全体を記述したとしても、HTTPリクエストのI/O時間を有効に使用するためにはrequestsライブラリではなく、HTTPXまたはaiohttpライブラリを使用する必要があります。
I/Oの待ち時間を有効活用するためには、「今リクエストを打ってレスポンス待ちの時間だよー」ということをasyncioのイベントループに伝えてあげる必要があります。
ですが、requestsライブラリは非同期処理用に設計されていないため、レスポンス待機中だとしてもそれをasyncioのイベントループに伝える手段が無く、他の非同期タスクがあってもrequestsによるリクエストが完了するまで待たなければならないのです。
非同期化後のパフォーマンス評価
同期処理の場合と同様に、def exec_loop(ids: list = [1, 2, 3, ..]):の引数idsをいくつか変えてそれぞれ計測してみました。
ids=(1,2,3,4,5)ids=(1,2,3,4,5,6,7,8,9,10)ids=(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)ids=[1,2,3,..,28,29,30]
| 実行時間【1】 | 実行時間【2】 | 実行時間【3】 | 実行時間【4】 |
|---|---|---|---|
| 0.156 (sec) | 0.238 (sec) | 0.495 (sec) | 0.962 (sec) |
結果から考察
実験してみたところ、やはり以下のようにかなりの違いが生まれました。
リクエストの数が多くなればなるほど、非同期処理の恩恵が受けられると言うことがわかりますね。
結果の再掲
- 同期処理
| 実行時間【1】 | 実行時間【2】 | 実行時間【3】 | 実行時間【4】 |
|---|---|---|---|
| 1.461 (sec) | 3.295 (sec) | 5.208 (sec) | 15.393 (sec) |
- 非同期処理
| 実行時間【1】 | 実行時間【2】 | 実行時間【3】 | 実行時間【4】 |
|---|---|---|---|
| 0.156 (sec) | 0.238 (sec) | 0.495 (sec) | 0.962 (sec) |