はじめに
この記事は,加茂IT塾Advent Calender2024の12日目です.
今回は現在あえてやる人が少ないであろうTransformerのEncoderモデルでMasked Language Modelを作りました.
一度自分で実装することによって論文の内容がどのように実現されているのか体感することができるのでより理解が深まると思います.
ぜひTransformerの理解に役立ててもらえたら幸いです.
目次
-
背景
-
前処理
2.1 トークナイズ
2.2 マスクデータの作成
2.3 データローダーの作成 -
モデルの構築
3.1 Self Attention
3.2 Multi Head Attention
3.3 Positionwise Feedforward
3.4 Positional Encoding
3.5 Encoder Layer
3.6 Encoder
3.7 TransformerMLM -
モデルの訓練
1. 背景
現在世の中を支配していると言っても過言ではない大規模言語モデル.その基盤技術としてTransformerが挙げられてきました.
しかし近年Transformerを代替する存在としてRetNetというアーキテクチャが提案されています.論文ではDecoderモデルでの実装,評価になっていました.
そこで今回は,EncoderモデルではRetNetの威力を十分に発揮できるのか,一般的な事前学習に比べて少量のデータセットではTransformerの場合とどれだけ差があるのか.これについて検証するためベースのモデルとしてTransformerのMasked Language Modelを学習まで実装した流れとなっています.
2. 前処理
ここではモデルを学習する上で絶対に必要となる,データの加工について取り扱っています.
2.1 トークナイズ
自然言語をよりモデルが理解しやすい形にするためまずは文章の区切りを行います.ここでは文章の区切りと区切った単語が辞書に入っている語彙の中のどの番号に対応するのか,数値データに変換するところまでを取り扱います.
tokenize_data.py
ここではトークナイザとしてBertTokenizerを使っています.
BertTokenizerは単語をサブワードに分割した後サブワードを辞書に対応したインデックスへと変換します.
インデックスへと変換されたものがinput_idsです.
input_idsの長さがデフォルトだと512個です.
512より多いと打ち切られ,足りないとパディングで足されて揃えられます.
attention_maskはパディングトークンを計算で使わないようにするためのものです.
パディングされていない位置は"1",パディングされている位置は"0"になっています.
訓練データとしてブックコーパスを使用しています.巨大なデータセットなので全体のうち1パーセント使用するようにしています.
動作確認用のコメントアウトではトークナイザの動きが正常か確かめるために少ないデータを入力しています.icecreamのic関数をprint関数のように使うことでわかりやすく出力できるでしょう.
from datasets import load_dataset
from transformers import BertTokenizer, DataCollatorWithPadding
from torch.utils.data import DataLoader
from icecream import ic
def tokenize_data(raw_datasets, checkpoint):
tokenizer = BertTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["text"], truncation=True, padding='max_length', max_length=512)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True) # {text, input_ids, token_type_ids, attention_mask}
tokenized_datasets = tokenized_datasets.remove_columns(["text", "token_type_ids"])
tokenized_datasets.set_format("torch")
return tokenizer, tokenized_datasets
if __name__ == "__main__":
raw_datasets = load_dataset("bookcorpus", split="train[:1%]") # {text}
checkpoint = "bert-base-uncased"
# raw_datasets = raw_datasets.select(range(0, 10))
# raw_datasets = raw_datasets.filter (lambda x: len(x["text"]) < 16)
tokenizer, tokenized_datasets = tokenize_data(raw_datasets, checkpoint)
2.2 マスクデータの作成
Masked Language Modelとはそもそも文章中の隠された部分がどの単語であるか,を当てるモデルとなっています.そのためには当然入力データもマスクする必要があるのでここで数値データをマスク付きの数値データにします.
create_mlm_data.py
入力インデックスの中からランダムな確率でマスクトークンのインデックスに置き換える関数です.
masked_input_idsというのが入力をマスクトークン込みに変換したものです.
mlm_labelsはマスクされた位置が正解のトークンインデックス,他は-100になっています.
これは後で学習をするときに正解ラベルの役割を果たします.
import torch
from datasets import load_dataset
from tokenize_data import tokenize_data
from icecream import ic
def create_mlm_data(input_ids, mask_token_id, pad_token_id, mask_prob = 0.15):
"""
Create masked input and labels for MLM training
Args:
input_ids: Original input ids
mask_token_id: ID of [MASK] token
vocab_size: Size of vocabulary
mask_prob: Probability of masking token
Returns:
masked_input_ids: Input with masks
mlm_labels: Labels for masked tokens (-100 for unmasked positions)
"""
mask = (torch.rand(input_ids.shape) < mask_prob) & (input_ids != mask_token_id) & (input_ids != pad_token_id)
masked_input_ids = input_ids.clone()
masked_input_ids[mask] = mask_token_id
mlm_labels = input_ids.clone()
mlm_labels[~mask] = -100
return masked_input_ids, mlm_labels
# テスト用のコード
if __name__ == "__main__":
raw_datasets = load_dataset("bookcorpus", split="train[:1%]") # {text}
checkpoint = "bert-base-uncased"
tokenizer, tokenized_datasets = tokenize_data(raw_datasets, checkpoint)
input_ids = tokenized_datasets['input_ids'][0]
ic(tokenizer.decode(input_ids))
ic(input_ids)
mask_token_id = tokenizer.mask_token_id # [MASK] トークンのID
ic(mask_token_id)
pad_token_id = tokenizer.pad_token_id # [PAD] トークンのID
ic(pad_token_id)
masked_input_ids, mlm_labels = create_mlm_data(input_ids, mask_token_id, pad_token_id)
ic(masked_input_ids)
ic(mlm_labels)
2.3 データローダーの作成
これまで順にデータセットを処理してきましたが,実際にモデルにデータを入力して訓練するときはミニバッチで重みを更新します.ここではミニバッチ学習において便利なデータローダーにデータセットを格納します.
preprocess.py
学習に必要なmasked_input_ids,attention_mask,mlm_labelsを一つのデータセットに格納します.
その後に訓練,検証,テストにデータを8:1:1の割合で分割します.
バッチサイズを設定し,これらをデータローダーに格納すると,学習に必要なデータが揃います.
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader
from datasets import load_dataset, Dataset
from tokenize_data import tokenize_data
from create_mlm_data import create_mlm_data
from icecream import ic
def exec_preprocess(raw_datasets, checkpoint, batch_size=8):
tokenizer, tokenized_datasets = tokenize_data(raw_datasets, checkpoint)
masked_input_ids, mlm_labels = create_mlm_data(tokenized_datasets['input_ids'], tokenizer.mask_token_id, tokenizer.pad_token_id)
tokenized_dict = {
'input_ids': masked_input_ids,
'attention_mask': tokenized_datasets['attention_mask'],
'labels': mlm_labels,
}
tokenized_datasets = Dataset.from_dict(tokenized_dict)
tokenized_datasets.set_format("torch")
train_testvalid = tokenized_datasets.train_test_split(test_size=0.2)
valid_test = train_testvalid['test'].train_test_split(test_size=0.5)
train_dataset = train_testvalid['train'] # {input_ids, attention_mask}
valid_dataset = valid_test['train']
test_dataset = valid_test['test']
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size)
dataloaders = [train_dataloader, valid_dataloader, test_dataloader]
return tokenizer, dataloaders
# 例として、train_dataloaderからデータを取り出す
def check_dataloader(dataloader):
for batch in dataloader:
ic(batch['input_ids'])
print(batch['labels'])
break # 最初のバッチだけを表示するためにbreakを使用
if __name__ == "__main__":
raw_datasets = load_dataset("bookcorpus", split="train[:1%]") # {text}
checkpoint = "bert-base-uncased"
# raw_datasets = raw_datasets.select(range(0, 10))
raw_datasets = raw_datasets.filter (lambda x: len(x["text"]) < 16)
tokenizer, dataloaders = exec_preprocess(raw_datasets, checkpoint)
train_dataloader, valid_dataloader, test_dataloader = dataloaders
check_dataloader(train_dataloader)
3. モデルの構築
ここでは主に画像で示した部分を実装します.

以下の順でTransformerのMasked Language Modelを構成する各要素に分けて説明します.
3.7のTransformerMLMのforwardを見た時にどのようにテンソルが変換されていくのか,3.1から3.6を見ながら順に追っていけると理解が深まると思います.
3.1 Scaled Dot-Product Attention
ここではTransformerの中の一番注目されているAttentionについて取り扱います.
後述する3.2ではこのScaled Dot-Product Attentionを複数組み合わせて作られています.
このセクションで関連しているのは赤枠の部分です.

Scaled Dot-Product Attention
以下の図に従って実装をしています.
入力の埋め込みを線形変換して得られた,Q,K,Vの三種類のベクトルに対して図のような演算をしているだけです.

class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, mask=None):
# Q: (batch_size, num_heads, seq_len, d_k)
# K: (batch_size, num_heads, seq_len, d_k)
# V: (batch_size, num_heads, seq_len, d_v)
d_k = Q.size(-1)
attention_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k) # (batch_size, num_heads, seq_len, seq_len)
if mask is not None:
attention_scores = attention_scores.masked_fill(mask == 0, -1e9) # Masking
attention_weights = torch.softmax(attention_scores, dim=-1) # (batch_size, num_heads, seq_len, seq_len)
context = torch.matmul(attention_weights, V) # (batch_size, num_heads, seq_len, d_v)
return context, attention_weights # (batch_size, num_heads, seq_len, d_v), (batch_size, num_heads, seq_len, seq_len)
3.2 Multi Head Attention
3.1を複数個使ってMulti Head Attentionを実装します.
関連する場所は3.1の画像と一緒です.
Multi Head Attention
ここではまずQ,K,Vのベクトルをヘッドの数だけ分割します.
その後に分割されたベクトルひとつひとつは3.1のScaled Dot-Product Attentionに入力されます.
具体的には512次元のベクトル,ヘッドの数が8個だとするとベクトルの64要素ごとにScaled Dot-Product Attentionへと入力されます.
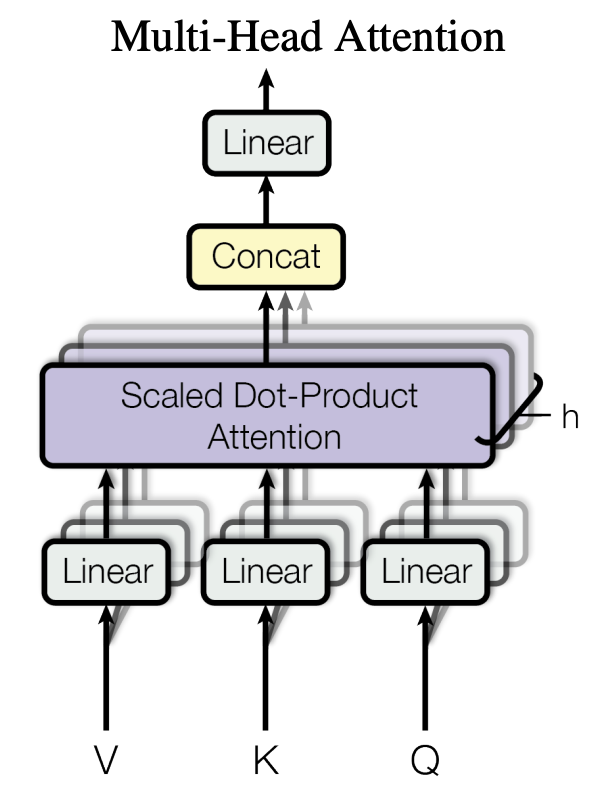
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % n_heads == 0, "d_model must be divisible by n_heads"
self.d_model = d_model
self.n_heads = n_heads
# d_k: dimension of key/query vectors per head (d_model/n_heads)
self.d_k = d_model // n_heads
# d_v: dimension of value vectors per head (d_model/n_heads)
self.d_v = d_model // n_heads
# Linear Layers
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention()
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# Linear projection
Q = self.W_Q(Q) # (batch_size, seq_len, d_model)
K = self.W_K(K) # (batch_size, seq_len, d_model)
V = self.W_V(V) # (batch_size, seq_len, d_model)
# Split
Q = Q.view(batch_size, -1, self.n_heads, self.d_k) # (batch_size, seq_len, n_heads, d_k)
K = K.view(batch_size, -1, self.n_heads, self.d_k) # (batch_size, seq_len, n_heads, d_k)
V = V.view(batch_size, -1, self.n_heads, self.d_v) # (batch_size, seq_len, n_heads, d_v)
# Reshape
Q = Q.transpose(1, 2) # (batch_size, n_heads, seq_len, d_k)
K = K.transpose(1, 2) # (batch_size, n_heads, seq_len, d_k)
V = V.transpose(1, 2) # (batch_size, n_heads, seq_len, d_v)
if mask is not None:
# mask: (batch_size, 1, seq_len, seq_len)
mask = mask.repeat(1, self.n_heads, 1, 1) # (batch_size, n_heads, seq_len, seq_len)
# Apply attention
context, attention_weights = self.attention(Q, K, V, mask) # (batch_size, n_heads, seq_len, d_v), (batch_size, n_heads, seq_len, seq_len)
# Concatenate heads
context = context.transpose(1, 2) # (batch_size, seq_len, n_heads, d_v)
# Ensure contiguous memory layout after transpose for the subsequent view operation
context = context.contiguous() # (batch_size, seq_len, n_heads, d_v)
context = context.view(batch_size, -1, self.d_model) # (batch_size, seq_len, d_model)
# Final linear projection
output = self.W_O(context) # (batch_size, seq_len, d_model)
return output, attention_weights
3.3 Positionwise Feedforward
Feedforward層です,
Transformerアーキテクチャの画像ではこの部分を実装します.
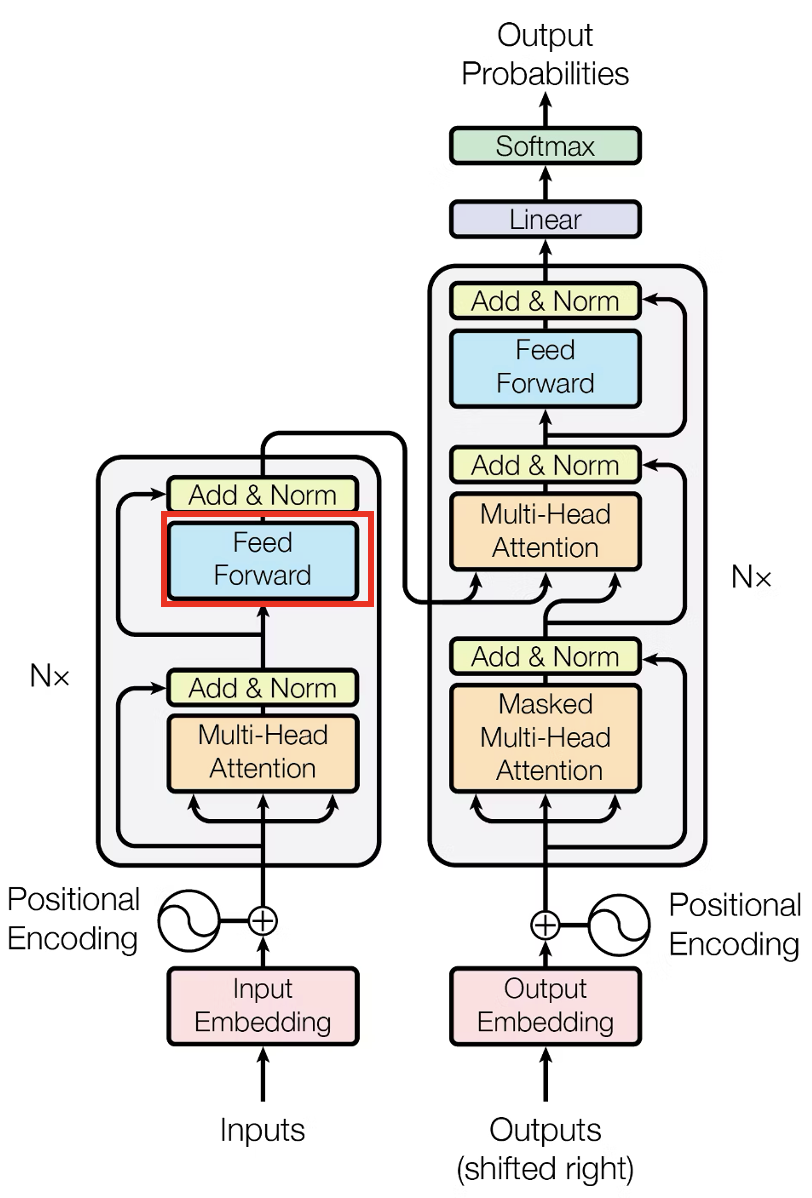
Positionwise Feedforward
Transformerのアーキテクチャの中でも一番シンプルな部分です.
Attention層から出力された特徴ベクトルに線形変換を2回するだけです.
class PositionwiseFeedforward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedforward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.relu = nn.ReLU()
def forward(self, x):
# x: (batch_size, seq_len, d_model)
x = self.linear1(x) # (batch_size, seq_len, d_ff)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x) # (batch_size, seq_len, d_model)
return x # (batch_size, seq_len, d_model)
3.4 Positional Encoding
ここではAttentionに入力する前の埋め込みベクトルに位置情報を付加する処理をしています.

Positional Encoding
以下の式に従って実装をしています.
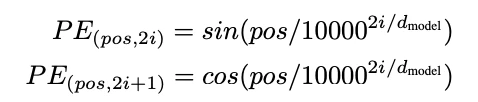
トークン系列の中の位置がposに対応しています.
0番目のトークンはpos = 0,3番目のトークンはpos = 3となります.
iは埋め込みベクトルのi次元をさしています.
奇数の次元にはcosを,偶数の次元にはsinを計算しています.
コードではこの計算を実装するために計算機の計算ならではのテクニックを使用しています.
詳しくはコメントアウトを追っていくと分かるでしょう.
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length=5000, dropout= 0.1):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Create constant 'pe' matrix with values dependant on pos and i
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1) # (max_seq_length, 1)
# The use of exponential and logarithm in div_term calculation:
# 1. Direct calculation of 10000^(2i/d_model) would result in extremely large numbers
# 2. Using log(10000) enables the following transformation:
# exp(log(10000^(-2i/d_model))) = exp(-2i/d_model * log(10000)) = 1/10000^(2i/d_model)
# 3. This improves numerical stability and computational efficiency
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model)) # (d_model/2)
# Apply sin to even indices in the array; 2i
pe[:, 0::2] = torch.sin(position * div_term)
# Apply cos to odd indices in the array; 2i+1
pe[:, 1::2] = torch.cos(position * div_term)
# pe: (max_seq_length, d_model)
pe = pe.unsqueeze(0) # (1, max_seq_length, d_model)
self.register_buffer('pe', pe) # Register the buffer as a persistent buffer
def forward(self, x):
"""
Args:
x: input tensor (batch_size, seq_len, d_model)
"""
# Add positional encoding
x = x + self.pe[:, :x.size(1)]
return self.dropout(x)
3.5 Encoder Layer
今まで作ってきたモジュールを一つのブロックにまとめます.
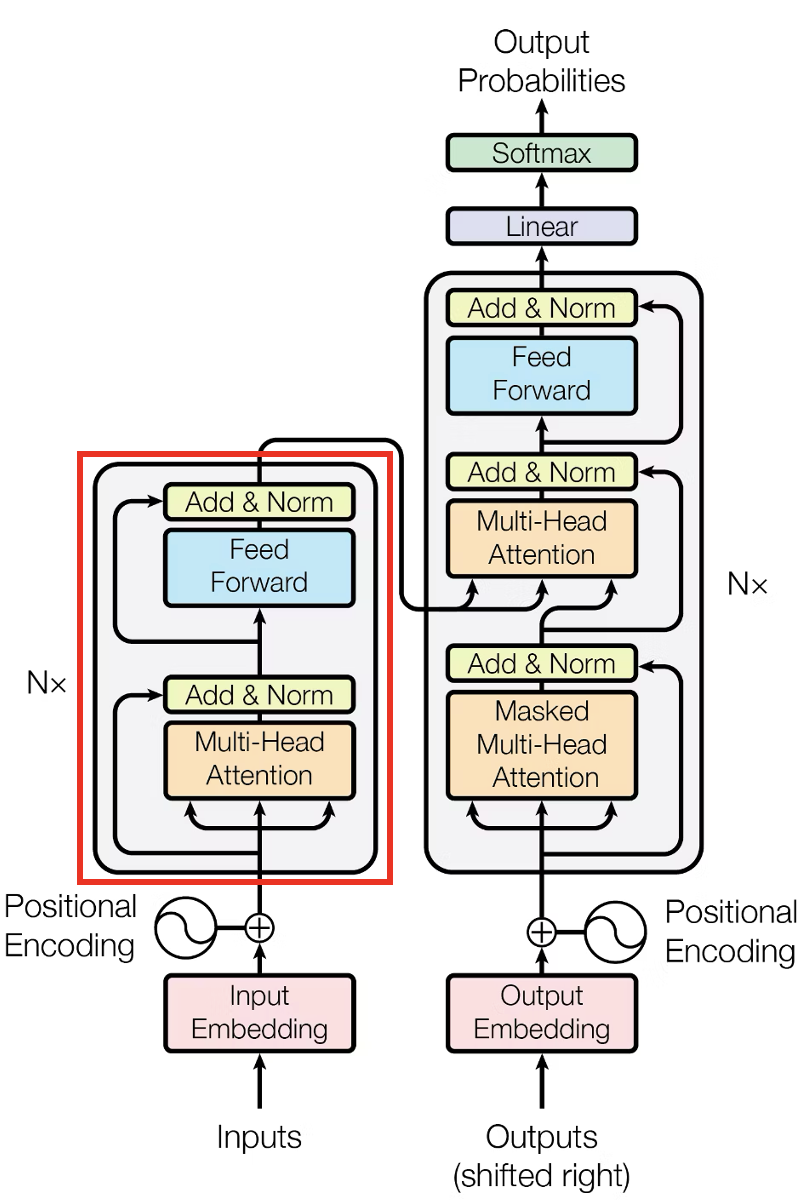
Encoder Layer
各モジュールが画像のような順番で配置されているのが分かるでしょう.
class EncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
# Multi-Head Attention Layer
self.attention = MultiHeadAttention(d_model, n_heads)
# Feed-Forward Layer
self.feed_forward = PositionwiseFeedforward(d_model, d_ff, dropout)
# Layer Normalization
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
Args:
x: input tensor (batch_size, seq_len, d_model)
mask: mask tensor (batch_size, seq_len, seq_len)
"""
# Multi-head attention with residual connection and layer normalization
attention_output, _ = self.attention(x, x, x, mask)
x = self.norm1(x + self.dropout(attention_output)) # Residual connection and layer normalization
# Feed-forward with residual connection and layer normalization
feed_forward_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(feed_forward_output))
return x
3.6 Encoder
先ほどのEncoder LayerをN層積み重ねたものです.

Encoder
何も難しいことはないです.
レイヤーをその数だけリストに格納し,テンソルを順に通していくだけです.
class Encoder(nn.Module):
def __init__(self, d_model, n_heads, d_ff, n_layers, max_seq_len, dropout=0.1):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout)
for _ in range(n_layers)
])
def forward(self, x, mask=None):
"""
Args:
x: input tensor (batch_size, seq_len, d_model)
mask: mask tensor (batch_size, seq_len, seq_len)
"""
for layer in self.layers:
x = layer(x, mask)
return x
3.7 TransformerMLM
3.4で実装したPositional Encodingと3.6で実装したEncoderを使ってTransformerのMasked Language Modelを実装します.ここでは主にモデルの一番最初に受け付ける入力部分,どの単語かを当てる出力部分を実装しています.
画像の部分に加えて単語を推測する層が続いています.
TransformerMLM
モデルの順伝搬で主に追加されたものは
トークンを埋め込み(ベクトル)に変換するtoken_embedding
Encoderを通って得られた特徴ベクトルを二層の線形層を使って単語の確率に変換するmlm_headです.
class TransformerMLM(nn.Module):
def __init__(self, vocab_size, d_model=512, n_heads=8, n_layers=6, max_seq_len=512, dropout=0.1):
super(TransformerMLM, self).__init__()
self.d_model = d_model
d_ff = d_model * 4
# Token Embedding Layer
self.token_embedding = nn.Embedding(vocab_size, d_model)
# Positional Encoding
self.positional_encoding = PositionalEncoding(d_model, max_seq_len, dropout)
# Encoder Layers
self.encoder = Encoder(d_model, n_heads, d_ff, n_layers, max_seq_len, dropout)
# Layer Normalization
self.layer_norm = nn.LayerNorm(d_model)
# MLM Prediction Head
self.mlm_head = nn.Sequential(
nn.Linear(d_model, d_model),
nn.GELU(),
nn.LayerNorm(d_model),
nn.Linear(d_model, vocab_size)
)
# Initialize weights
self.apply(self._init_weights)
def _init_weights(self, module):
"""Initialize weights similar to BERT"""
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
def forward(self, input_ids, attention_mask=None):
"""
Args:
input_ids: Tensor of token ids (batch_size, seq_len)
attention_mask: Tensor of attention mask (batch_size, seq_len, seq_len)
1 for tokens to attend to, 0 for tokens to ignore
Returns:
logits: Prediction logits for each token position (batch_size, seq_len, vocab_size)
"""
# Embedding Layer
x = self.token_embedding(input_ids) * math.sqrt(self.d_model)
# Add positional encoding
x = self.positional_encoding(x)
# Create attention mask if provided
if attention_mask is not None:
# Convert attention mask from (batch_size, seq_len) to (batch_size, 1, 1, seq_len)
attention_mask = attention_mask.unsqueeze(1) # (batch_size, 1, seq_len)
attention_mask = attention_mask.unsqueeze(2) # (batch_size, 1, 1, seq_len)
# Convert 0s to -inf, 1s to 0
attention_mask = (1.0 - attention_mask) * -1e9
# During addition, attention_mask is automatically broadcast to match attention_scores
# Therefore, we do not need to explicitly expand the attention_mask
# (batch_size, 1, 1, seq_len) + (batch_size, num_heads, seq_len, seq_len)
# Encoder Layers
encoder_output = self.encoder(x, attention_mask)
# Layer Normalization
encoder_output = self.layer_norm(encoder_output)
# MLM Prediction Head
logits = self.mlm_head(encoder_output)
return logits
def compute_loss(self, logits, labels):
"""
Args:
logits: Prediction logits for each token position (batch_size, seq_len, vocab_size)
labels: Tensor of token ids (batch_size, seq_len)
Returns:
loss: Cross-entropy loss
"""
loss_fn = nn.CrossEntropyLoss(ignore_index=-100)
# Flatten the logits and labels
logits_flat = logits.view(-1, logits.size(-1)) # (batch_size * seq_len, vocab_size)
labels_flat = labels.view(-1) # (batch_size * seq_len)
loss = loss_fn(logits_flat, labels_flat)
return loss
4. モデルの訓練
ここでは実際にモデルの訓練の流れを実装します
train.py
train関数でモデルの訓練を行います.
まずtrain_dataloaderを使ってモデルを訓練します.
その後にvalid_dataloaderを使ってモデルの検証をします.
この流れがセットで1エポックとなります.
評価指標としてパープレキシティを計算しています.
正解の単語をどのくらいの確信度で予測できているかのスコアになります.
正解の単語を100パーセント近い確率で予測できていれば1,ほとんど0パーセントに近ければ無限大に発散する指標となっています.
各バッチごとのパープレキシティと1エポックの訓練データのパープレキシティ,検証データのパープレキシティを計算しています.
eval関数ではテストデータでモデルの評価をします.
train関数の検証とほとんど同じ流れでパープレキシティを計算するだけです.
import torch
from torch.optim import AdamW
from datasets import load_dataset
# import wandb
from preprocess import exec_preprocess
from transformer_mlm import TransformerMLM
from tqdm import tqdm # tqdmをインポート
from icecream import ic
def train(epoch, model, optimizer, train_dataloader, valid_dataloader):
step_ppls = []
for i in range(epoch):
model.train() # モデルを訓練モードに設定
# トレーニングフェーズ
total_train_loss = 0
j = 0
for batch in tqdm(train_dataloader, desc="Training", leave=False):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# モデルの出力を取得
logits = model(input_ids, attention_mask)
# 損失を計算
loss = model.compute_loss(logits, labels)
total_train_loss += loss.item()
step_ppl = torch.exp(torch.tensor(loss.item()))
step_ppls.append(step_ppl)
print(f"Epoch{i} Step{j} PPL: {step_ppl}")
# バックプロパゲーション
loss.backward()
optimizer.step() # パラメータを更新
optimizer.zero_grad() # 勾配をゼロクリア
avg_epoch_loss = total_train_loss / len(train_dataloader)
train_ppl = torch.exp(torch.tensor(avg_epoch_loss))
print(f"Epoch{i} Train PPL: {train_ppl}")
j += 1
# 検証フェーズ
model.eval() # モデルを評価モードに設定
total_valid_loss = 0
with torch.no_grad(): # 勾配計算を無効にする
for batch in tqdm(valid_dataloader, desc="Validating", leave=False):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
logits = model(input_ids, attention_mask)
loss = model.compute_loss(logits, labels)
total_valid_loss += loss.item()
avg_valid_loss = total_valid_loss / len(valid_dataloader)
valid_ppl = torch.exp(torch.tensor(avg_valid_loss))
print(f"Epoch {i} Validation PPL: {valid_ppl}")
torch.save(model.state_dict(), "model5p3e.pth")
with open("step_ppls.txt", "w") as f:
for step_ppl in step_ppls:
f.write(str(step_ppl.item()) + "\n")
def eval(model, test_dataloader):
model.eval()
total_test_loss = 0
with torch.no_grad():
for batch in tqdm(test_dataloader, desc="Testing", leave=False):
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
logits = model(input_ids, attention_mask)
loss = model.compute_loss(logits, labels)
total_test_loss += loss.item()
avg_test_loss = total_test_loss / len(test_dataloader)
test_ppl = torch.exp(torch.tensor(avg_test_loss))
print(f"Test PPL: {test_ppl}")
if __name__ == "__main__":
# wandb.init(project="transformer-mlm")
raw_datasets = load_dataset("bookcorpus", split="train[:5%]") # {text}
checkpoint = "bert-base-uncased"
# raw_datasets = raw_datasets.filter(lambda x: len(x["text"]) < 16)
batch_size = 16
tokenizer, dataloaders = exec_preprocess(raw_datasets, checkpoint, batch_size)
train_dataloader, valid_dataloader, test_dataloader = dataloaders
vocab_size = tokenizer.vocab_size
d_model = 512
n_heads = 8
n_layers = 6
max_seq_len = tokenizer.model_max_length
ic(max_seq_len)
model = TransformerMLM(vocab_size=vocab_size, d_model=d_model, n_heads=n_heads, n_layers=n_layers, max_seq_len=max_seq_len)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
optimizer = AdamW(model.parameters(), lr=5e-5)
train(3, model, optimizer, train_dataloader, valid_dataloader)
eval(model, test_dataloader)
おわりに
今回は一からTransformerのMasked Language Modelを学習する方法を述べました.自身が取り組んでいる課題はここで終わりではないので次回はRetNetのMasked Language Modelについて記事を出す予定です.
参考文献
記事
【Pytorch】Transformerを実装する
How to code The Transformer in Pytorch