About the paper
Title: Deep Reinforcement Learning : An overview
Author: Yuxi Li
Published Year: 2017
Link: https://arxiv.org/abs/1701.07274
Foreword
Recently we have seen the explosive evolution in Reinforcement Learning.
Many people might have heard something related with AI(artificial intelligence) somewhere and some motivated people actually started learning. In fact, when it comes to AI, what do we imagine at first? The standalone walking robot? or Alexa-like cognitive speaker? This is quite deep topic though, the famous researcher David Silver has come up with the core concept of AI in his research paper in 2015.
'artificial intelligence' = 'reinforcement learning' + 'deep learning'
So we can say that the composition of RL and DL is AI.
In this article, My aim is to clarify the connection between RL and DL by reviewing recent work and its success cases.
Agenda
- Introduction
- BackGround
1.Machine Learning
2. Deep Learning
3. Reinforcement Learning - Core Elements
- Value Function
- policy
- Reward
- Model
- Planning
- Exploration
- Important Mechanisms
- Attention and Memory
- Unsupervised Learning
- Transfer Learning
- Multi-Agent RL
- Hierarchical RL
- Learning to Learn
- Applications
- Games
- Robotics
- Natural Language Processing
- Computer Vision
- Neural Architecture Design
- Business Management
- Finance
- Healthcare
- Industry4.0
- Smart Grid
- Intelligent Transportation Systems
- Computer Systems
- More Topics
1. Introduction
It's been for ages that Reinforcement learning has become one of the hottest topic in profound AI domain. With the recent development of DL, it accelerated a lot.
But why DL does help RL? How does it affect?
So in this section before jumping into any description of algos, let's see the link between them shortly. Simply saying, because of the capability of generalisation in DL, it doesn't rely on tedius feature engineering. So it allows us to use the algo for wide domain. And this consequently helps RL to be able to handle the environment more efficiently and precisely.
So the generality, expressiveness and flexibility of DL make some tasks feasible and achievable.
2. BackGround
In this part, he has briefly explained each topic, ML, DL and RL.
2.1 ML
ML is the learning methods to make predictions and/or decisions based on the given data and it has actually three branches.
- SL(supervised learning): classifications and regressions algos(DT, Logistic Regression etc.)
- UL(unsupervised learning): clustering/categorisatoin, Attempting to extract information from data without labels
- RL(reinforcement learning): you know this, init?
And he elaborated some techniques in ML for subsequent topics, but for now I'd like to skip it and if you need, please refer to it.
2.2 DL
DL is like other ML algos, it has input layer and output layers.
But between them, we can pile the various types of layers, e.g. Dropout/Activations(ReLU,Sigmoid,Softmax etc.)/LSTM/RNN cell and so on.
So it contains huge dynamics inside and with the strong knowledge on the architecture, we can build our own custom models as well.
And as you might aware already, recently DL is not just used for classification/regression tasks though, it's used to encode/decode information.
For example, Word2vec is three layers simple FNN(feedforward neural network).
But it aims at creating the word embeddings not predicting anything. So with its representational power, we can use DL for data preprocessing as well.
2.3 RL
Please refer to my another article for the basic RL algos.
If you are not sure if it's required for you to go back a bit for reviewing your notes again, please check the algos below for now.
If you can get some sense from them, i think it's alright for now!



2.3.5 Function Approximation
So far basic RL is based on the tabular systems, which means the value function or action-value function are stored in a tabular form.
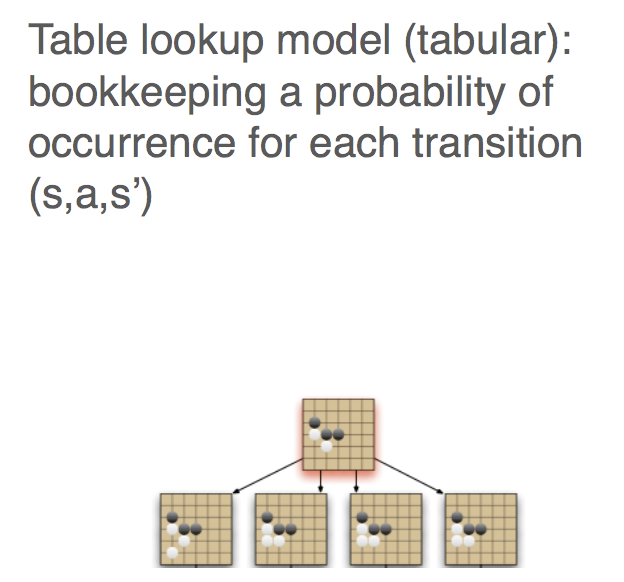
Image Source
however, if we want to apply RL to real-life problem, then this normally doesn't fit to it. Let's say the agent has a task to hit a ball and it learns from the outcomes, which is the length for a ball to move. As you might probably aware already, the length is a continuous number and also the agent needs to learn the intensity of hitting based on the length of movement. Hence, to address the issue, we will learn another method to represent the transition, which is function approximation. It estimates the action-value/state functions using machine learning techniques, like linear regression, decision trees or you can even apply SVMs and so on. Indeed, as the title indicating we will pick and focus on deep learning to approximate the components of RL in this article!!
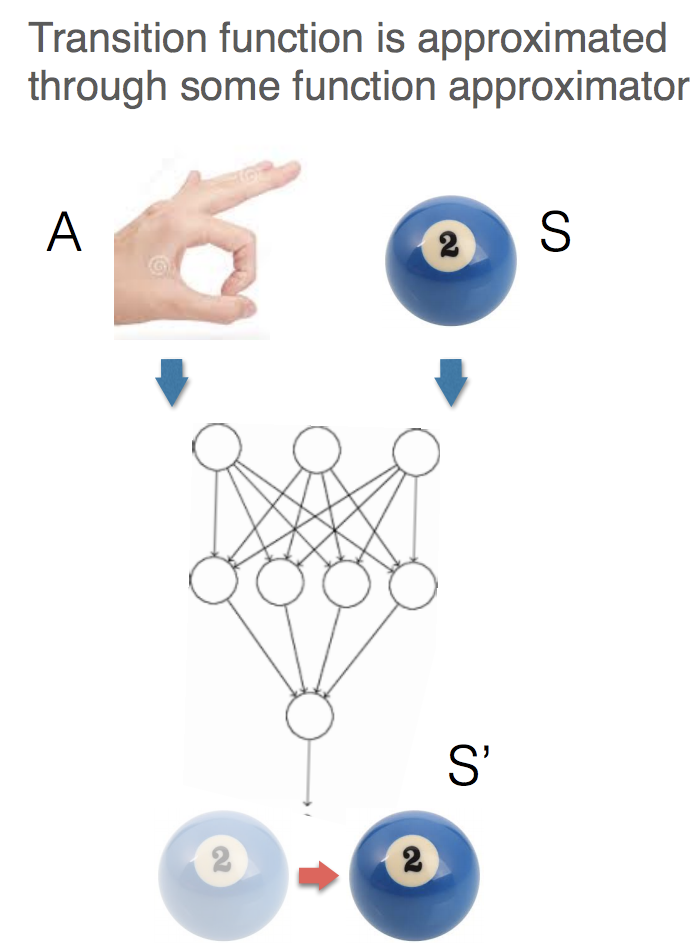
Oh,, Actually nothing to be worried!!
Because we know the algos for agents to learn, so what we are going to see in the rest of this article and the paper is just a way to describe the states of agents/environments. With this method, all algos become much more powerful and applicable to any problems you would ever have.
For running example, let's look at TD(0) with function approximation.
First of all, $\hat{v}(s,w)$ is a approximate value function, $w$ is the parameter in the approximation. Also, $\nabla \hat{v}(s,w)$ denotes the gradient of the approximate value function with respect to the parameter w. Finally the update rule is placed at the last part in the loop.
As you can see, the explicit difference between the previously seen algo above and this one is just a few lines, which are place at last inside the loop for episodes.

3. Core Element
In this section, I will talk about the latest techniques evolving in core components of RL.
3.1 Value Function
3.1.1 Deep Q-network
please refer to my another article!
https://qiita.com/Rowing0914/items/d1edf7df1df559792f62
3.2 Double DQN
please refer to my another article!
https://qiita.com/Rowing0914/items/323464f2675fe5c9b6e7