Introduction
This paper explains the basic concept of Bidirectional RNN by making the benefits of this new architecture clear and its implementation as well.
The reason why I wrote this article was that I had to understand bidirectional LSTM which is used in state-of-the-art language models and sometimes by combining with other models, the model can obtain significant representational capability of languages.
Bidirectional RNN
The idea has initially appeared in the great paper published by Mike Schuter et al in 1999.
Link: https://pdfs.semanticscholar.org/4b80/89bc9b49f84de43acc2eb8900035f7d492b2.pdf
However, I couldn't find any mathematical reference about the architecture.
So I have decided to proceed my research further.
Architecture
I have create this ppt! lol
- Legacy RNN/LSTM
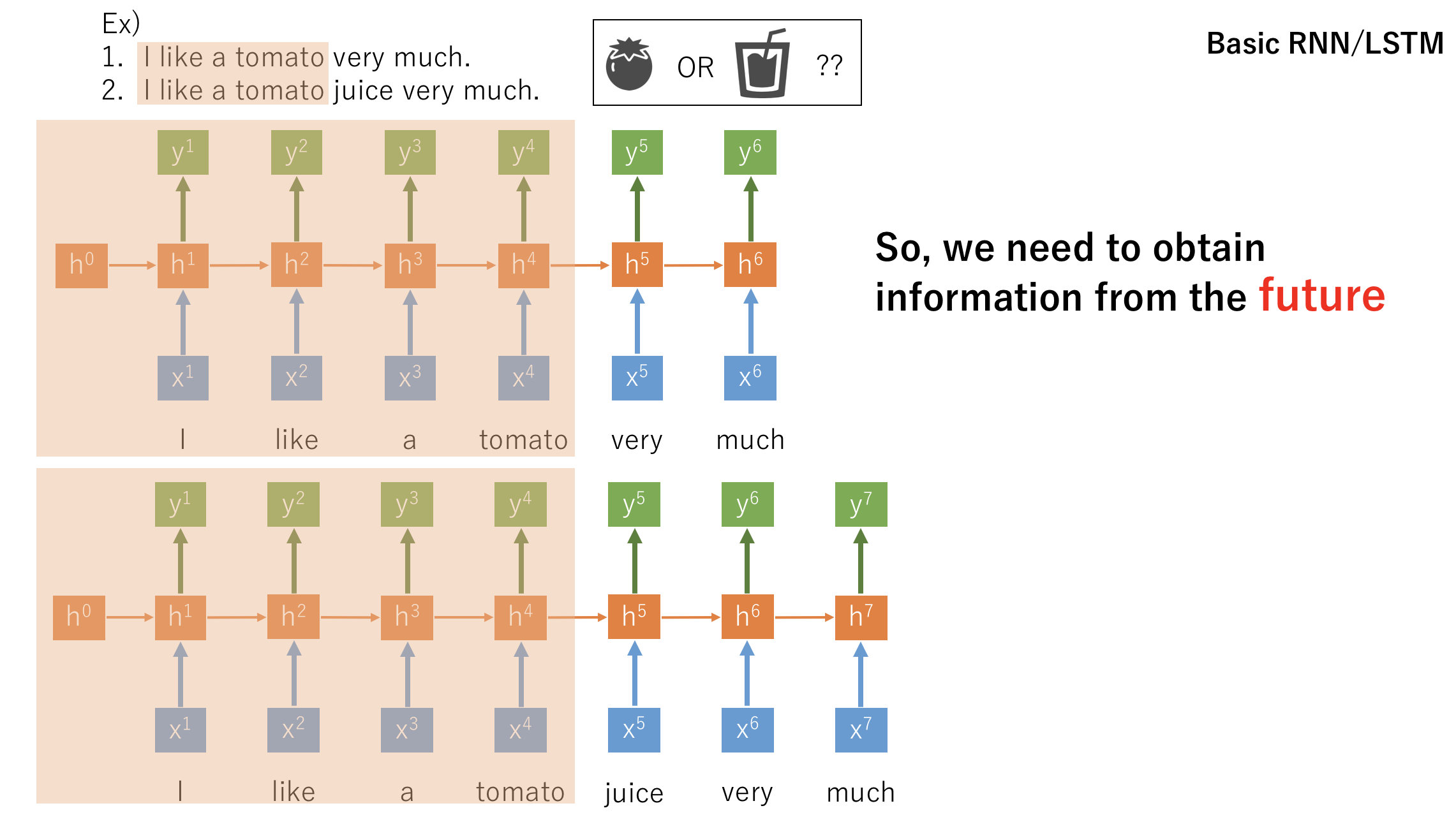
- Bidirectional RNN/LSTM


Maths
Regarding to basic RNN, please refer to this my article.
https://qiita.com/Rowing0914/items/6803fbc0af9163788a0c
Based on this, the Bidirectional RNN only differentiates its input.
Input should look like this.
h_1^{(t)} = \sigma(W_{in}X^{(t)} + W_{hh_1}h_1^{(t-1)})\\
h_2^{(t)} = \sigma(W_{in}X^{(t)} + W_{hh_2}h_2^{(t+1)})\\
o^{(t)} = softmax(W_{out,h_1}h_1^{(t)} + W_{out,h_2}h_2^{(t)})
I did Proof of concept mathematically.

from keras.layers import LSTM, Bidirectional, Dense, Dropout, Embedding
from keras.datasets import imdb
from keras.models import Sequential
from keras.preprocessing import sequence
import numpy as np
max_features = 20000
maxlen = 100
batch_size = 32
print('Loading data...')
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
print(len(x_train), 'train sequences')
print(len(x_test), 'test sequences')
print('Pad sequences(samples x time)')
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
print('x_train shape: ', x_train.shape)
print('x_test shape: ', x_test.shape)
y_train = np.array(y_train)
y_test = np.array(y_test)
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
model.fit(x_train, y_train, batch_size=batch_size, epochs=4, validation_data=[x_test, y_test])