はじめに
PythonとEelというライブラリーを使ってAIアシスタント(GitHubからダウンロードできます)を作っていたのですが、漢数字が入ってきたときのために文章中の漢数字を数字に変換するプログラムを作りました。
ネットで調べるといくつか記事が見つかりますが、おそらく私の考えたこの方法が一番シンプルで短く書けます。
また、解説付きの記事がほとんどなかったので、仕組みの考え方とプログラムの解説も付けておきます。
Python 3.8で動作確認しています。f-stringを使っているのでPython 3.6以上が必要です。古いPythonの場合はf-stringの部分を修正してください。
プログラム
「九千九百九十九京九千九百九十九兆九千九百九十九億九千九百九十九万九千九百九十九」まで対応しています。「垓」以上はあまり聞かないので京までの対応です。
注意
- 漢数字の書き方が正しいことを前提に作られています。変な漢数字の書き方(0万など)は上手く動きません
- 数を表していない漢数字(「万華鏡」など)も算用数字に変換されてしまいます
import re
def convert_kanji_to_int(string):
result = string.translate(str.maketrans("零〇一壱二弐三参四五六七八九拾", "00112233456789十", ""))
convert_table = {"十": "0", "百": "00", "千": "000", "万": "0000", "億": "00000000", "兆": "000000000000", "京": "0000000000000000"}
unit_list = "|".join(convert_table.keys())
while re.search(unit_list, result):
for unit in convert_table.keys():
zeros = convert_table[unit]
for numbers in re.findall(f"(\d+){unit}(\d+)", result):
result = result.replace(numbers[0] + unit + numbers[1], numbers[0] + zeros[len(numbers[1]):len(zeros)] + numbers[1])
for number in re.findall(f"(\d+){unit}", result):
result = result.replace(number + unit, number + zeros)
for number in re.findall(f"{unit}(\d+)", result):
result = result.replace(unit + number, "1" + zeros[len(number):len(zeros)] + number)
result = result.replace(unit, "1" + zeros)
return result
例えば
print(convert_kanji_to_int("お会計は五千京二百三十億八百六十五円になります。"))
とすると
お会計は50000000023000000865円になります。
というように文章中の漢数字が数字に変換されます。
また、壱、弐、参にも対応していますし、「五〇五」などの0を〇で表す書き方にも対応しています。
もちろん文章中に漢数字が複数ある場合でも
print(convert_kanji_to_int("お会計は百円と消費税の十円で百十円になります。"))
お会計は100円と消費税の10円で110円になります。
というように正しく変換されます。
プログラム中のconvert_tableは漢数字と0の個数の組み合わせです。例えば「百」なら数字に直すと100で0が2つなので「00」となっています。このルールに従ってconvert_tableに追記すれば、さらに大きな数にも対応できます。
考え方
ここでは例として
一千二十三
を数字に変換していきます(この後の説明のために千ではなく一千にしておきます)。
まず、〇〜九を0〜9に変換します。
1千2十3
次からが複雑ですが、理解すれば簡単です。
十(じゅう)や千を0に置き換えていきます。「十(じゅう)」という漢数字は「10」なので「0」は1個ですね。そして今回の場合、十の右に数字が1つ書かれているので0の数は1-1=0、つまり十を0個の0と置き換えます。よって、「十」を消してしまいます。
すると
1千23
になりますね。下の画像を見てもらうと分かりやすいと思います。
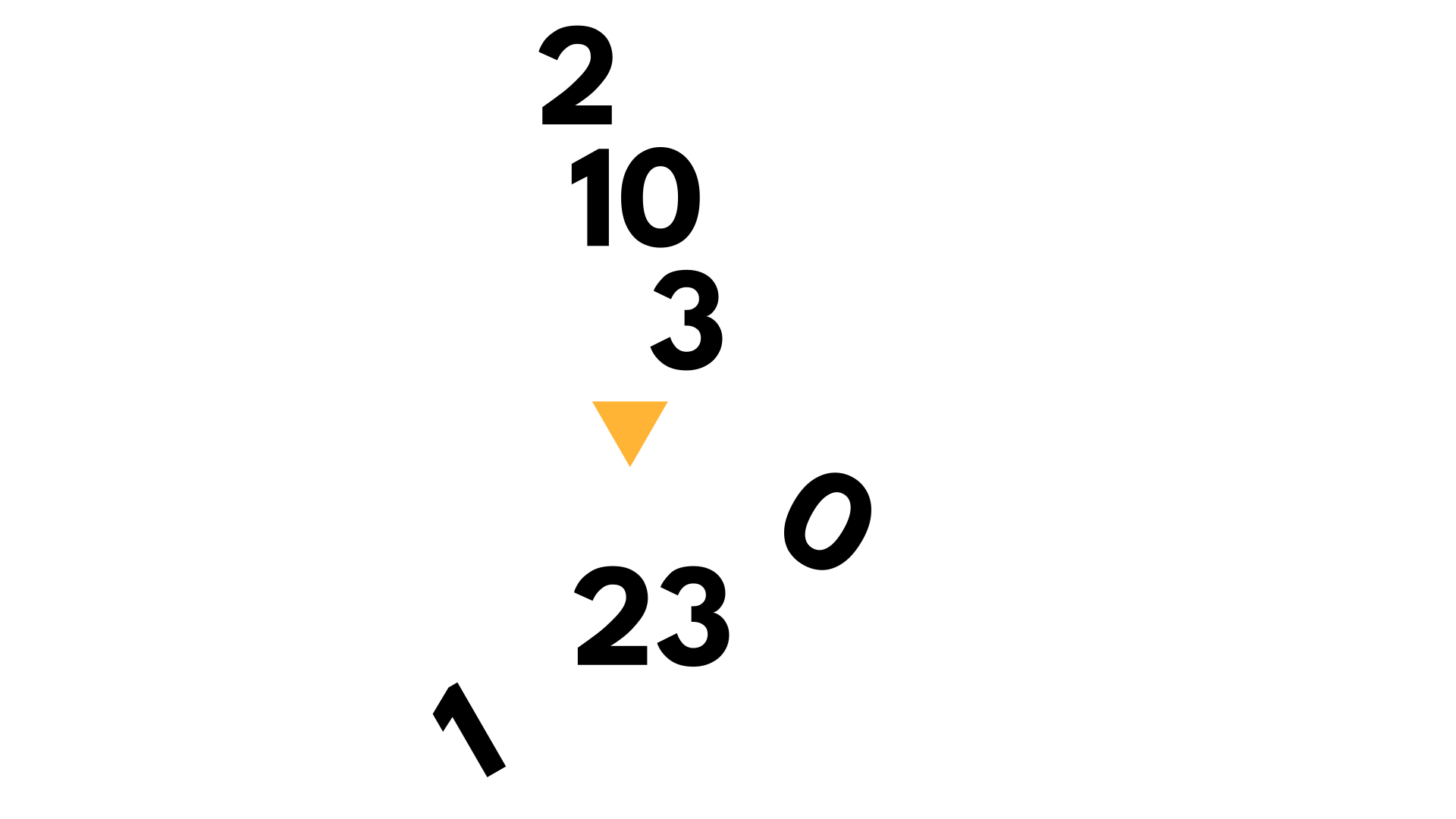
2と10と3をくっつけて23を作るとき、2や3がある分、10を構成する1・0が不要になりますね。0の個数が1-1=0というのは、そういうことです。
以降は、これの繰り返しです。
「千(せん)」という漢数字は「1000」なので「0」は3個です。千の右に数字が2つ書かれているので0の数は3-2=1、つまり千を1個の0と置き換えます。よって、「千」を「0」に置き換えて
1023
となります。画像で表すとこうなります。

1000と23をくっつけるとき、23という2桁分の0が不要になります。ですから、0の個数は3-2=1個となるわけです。
しかし、今回は一千二十三だったので今の処理で問題ありませんが、先頭の一がなくなって
千二十三
を数字へ変換する場合に問題が発生します。先程の処理を行うと
023
になってしまいます。この問題は、百や千などの左に一〜九がついていない場合に発生します。
解決するためには一~九がついていない場合、左に1をつければ良いですね。
そうすれば
千二十三
は
1023
に正しく変換されます。
以上の処理を文字列中のすべての漢数字に対して、「万」・「億」なども同様に行っていけば、漢数字を数字に変換できます。
プログラムの解説
プログラムの解説は前述の考え方を読んでいないと分かりにくいので、ここまで飛ばした場合は、先に読んでおいてください。
では、解説していきます。
まず、〇〜九を0〜9に変換し、拾を十に変換します。
result = string.translate(str.maketrans("零〇一壱二弐三参四五六七八九拾", "00112233456789十", ""))
「百」なら「100」なので0が2つといったように、漢数字の0の数を定義します。
convert_table = {"十": "0", "百": "00", "千": "000", "万": "0000", "億": "00000000", "兆": "000000000000", "京": "0000000000000000"}
0の数が定義されている十(じゅう)や百、千などの漢数字の一覧を、正規表現用に作ります。
unit_list = "|".join(convert_table.keys())
〇~九以外の百や千などの漢数字が残っている場合、以降の変換処理を漢数字がなくなるまで繰り返します。
while re.search(unit_list, result):
以降の処理を「十(じゅう)」「百」などに対してそれぞれ行います。
for unit in convert_table.keys():
現在処理中の漢数字の0の数を取得します。
zeros = convert_table[unit]
(数字)+(十や百、千など)+(数字)に当てはまる箇所全てに対して、前述の考え方で説明した0に置き換える処理を行います。
for numbers in re.findall(f"(\d+){unit}(\d+)", result):
result = result.replace(numbers[0] + unit + numbers[1], numbers[0] + zeros[len(numbers[1]):len(zeros)] + numbers[1])
1つ前の処理をしてもまだ漢数字が残っている場合、(数字)+(十や百、千など)に当てはまる箇所全てに対して、前述の考え方で説明した0に置き換える処理を行います。
ただし、この場合は0の数を右に書かれている数字の個数で調整する必要がないので、各漢数字の0を数を定義したconvert_table通りに置き換えます。
for number in re.findall(f"(\d+){unit}", result):
result = result.replace(number + unit, number + zeros)
さらに、まだ漢数字が残っている場合、(十や百、千など)+(数字)に当てはまる箇所全てに対して、前述の考え方で説明した0に置き換える処理を行います。
ただし、この場合は十や百、千などの左に一~九が付いていません。よって、十や百、千などをいくつかの0に置き換えるだけでなく、その左に1を付ける必要があるわけです。
for number in re.findall(f"{unit}(\d+)", result):
result = result.replace(unit + number, "1" + zeros[len(number):len(zeros)] + number)
十や百、千などが単体で存在している部分に対して、1+(0の数)に置き換える処理を行います。この場合には、「百」などが当てはまります(「二百」などは単体でないので当てはまらない)。
ここまでの処理がwhile文によって文字列中のすべての漢数字に対して、for文によって百、千、万などのすべてに対して行われます。
result = result.replace(unit, "1" + zeros)
最後に、結果を返します。
return result
さいごに
雑なプログラムですが、一応ちゃんと動きます。
最後までお読みいただき、ありがとうございました。