はじめに
こんにちは。株式会社ジールの@RizumuUEDAです。
今回は、2024/10/22アップデートの「Amazon Redshift がクエリのモニタリングと診断を強化するクエリプロファイラーを発表」についての検証結果をご紹介します。
本アップデートでは、クエリの可視性とトラブルシューティングを強化するための「Query Profiler」が導入され、クエリの分析と最適化を従来よりも容易に行うことができます。
1. 背景・目的
本章では、前提知識となるQuery ProfilerおよびEXPLAINコマンドに関する説明と、本記事の検証目的の説明を行います。
1-1. Query Profilerについて
AWSコンソール内でクエリのコンポーネントとパフォーマンスを分析するためのグラフィカルツールで、Amazon Redshift Serverlessおよびプロビジョニングクラスタで提供されます。
Redshiftで実行されたクエリの「クエリID」を用いて検索をすることで、クエリの実行計画や統計情報が記載されたダッシュボードを表示することができます。
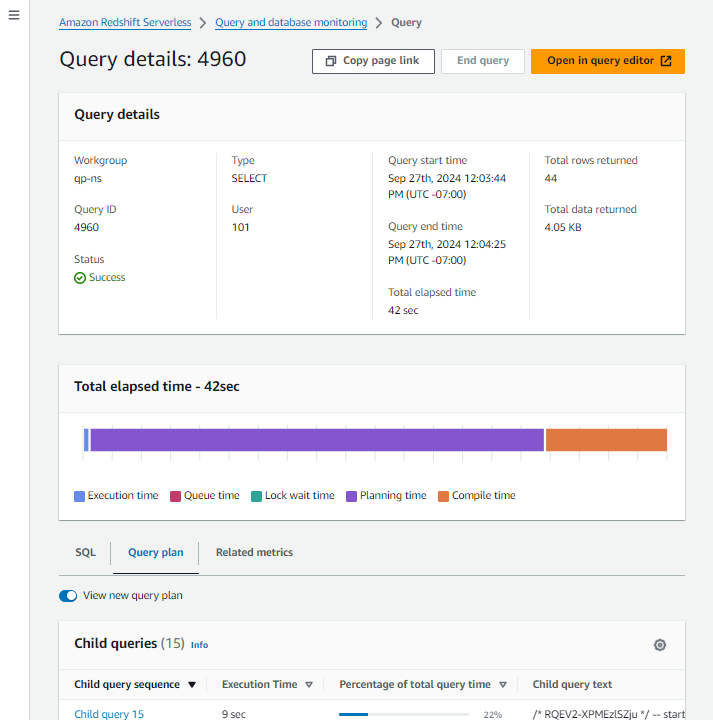
※参考1より引用
クエリの実行計画は「Query plan」から確認できます。ここでは「子クエリ」「ストリーム」「ステップ」といったコンポーネントに階層的にクエリが分解され、各単位でのメトリクスを確認することができます。
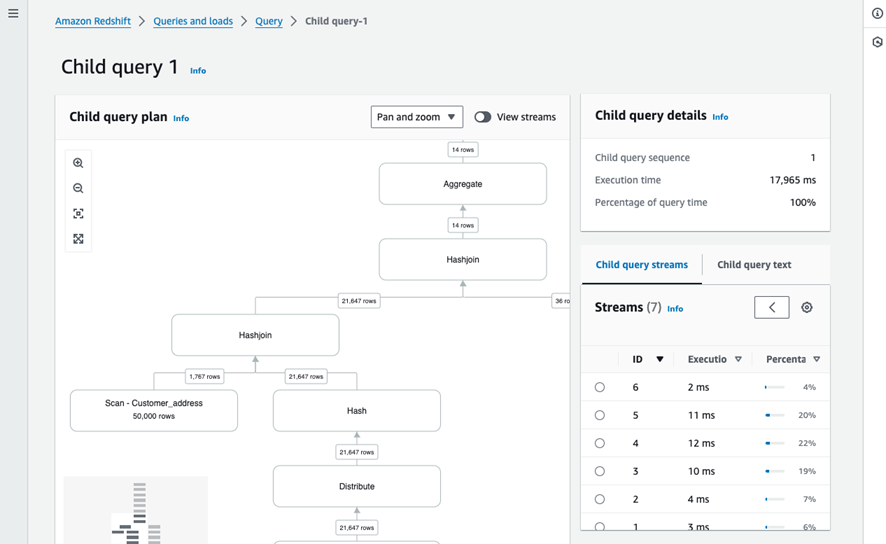
※参考1より引用
また、表示されるメトリクスはシステムビュー(SYS_QUERY_DETAILなど)のデータに含まれる実行時間、入出力行数、読み取り/書き込みバイト数などになっています。
1-2. EXPLAINコマンドについて
クエリチューニングに活用されるSQLコマンドの一種で、クエリの実行に際してデータベース内でどのように処理が行われるか(実行計画)を出力します。
使用方法は、実行計画を取得したいクエリの文頭にEXPLAINを付すだけでよく、簡単に実行できます。
出力された情報から
- どのテーブルにアクセスしているのか
- フルスキャンかインデックススキャンか
- JOINの順序や方法(Nested Loop/Hash Joinなど)は何か
- 各ステップで何行が出力されているか
などが分かり、クエリのボトルネックを発見するのに役立ちます。
1-3. 検証内容
【目的】
本記事では、クエリチューニングにおいて「新たに導入されたQuery Profilerの位置づけが
- EXPLAINコマンドの代替になるもの
- EXPLAINコマンドを補助するもの
のいずれなのか」を検証します。
【検証環境】
Redshiftにプロビジョニングクラスタ(ノードタイプ: ra3.large [vCPU: 2、Memory: 16 GiB]、ノード数:1)を作成しました。
2. 検証対象・結果
本章では、実際にサンプルテーブルに対してクエリを実行し、その実行計画をEXPLAINコマンドおよびQuery Profilerを用いて確認します。
2-1. 作成SQL・テーブル構成について
まず、検証で用いたテーブルおよびクエリのSQLを以下にまとめます。
テーブルは以下の4種類を作成しました。各テーブルの概要と先頭10行を示します。
①sales:店舗の商品売上のトランザクションデータ(10,000行)
②store_m:店舗情報のマスタデータ(100行)
③product_m:商品情報のマスタデータ(501行)
④type_m:区分情報のマスタデータ(23行)
そして、これらのテーブルに対するクエリとして、以下2つのSQLを作成しました。
【Query1】salesテーブルに対する単純なSELECT文です。
select *
from sales
order by sales_dt, store_cd, product_co, price, cost, num, type1, type2, type3
limit 30;
【Query2】4つのテーブルに対する結合を含む冗長なSQL文です。
select
TO_CHAR(sal.sales_dt, 'YYYY-MM-DD HH24:MI') as dt,
st.store_nm,
p.product_nm,
pt.item_nm as product_type,
case
when t.item_nm = '非課税' then '0'
else r.item_nm
end as tax_r,
case
when r.item_nm = '0' then '非課税'
else t.item_nm
end as tax_t,
(sal.price - sal.cost) * sal.num as reve,
sex.item_nm as sex,
visit.item_nm as visit,
family.item_nm as family
from sales sal
left join store_m st
on sal.store_cd = st.store_cd
left join product_m p
on sal.product_co = p.product_co
left join type_m pt
on p.item_cd = pt.item_cd and pt.type_cd = 1
left join type_m r
on p.tax_rate = r.item_cd and r.type_cd = 3
left join type_m t
on p.tax_type = t.item_cd and t.type_cd = 2
left join type_m sex
on sal.type1 = sex.item_cd and sex.type_cd = 4
left join type_m visit
on sal.type2 = visit.item_cd and visit.type_cd = 5
left join type_m family
on sal.type3 = family.item_cd and family.type_cd = 6
where 1 = 1
or sal.product_co = p.product_co
or (p.tax_rate = r.item_cd and r.type_cd = 3)
2-2. 検証結果
2-2-1. Query1
【EXPLAINコマンド】
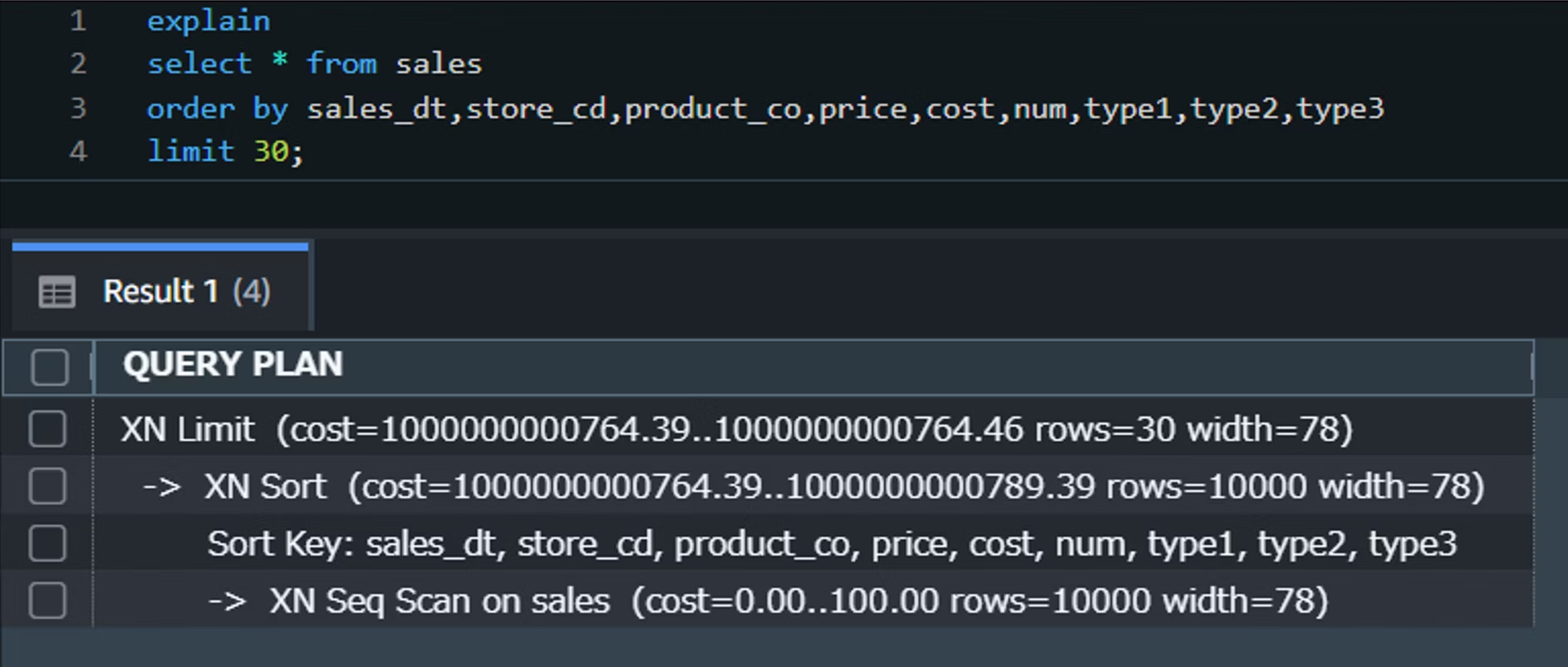
Query1に対するEXPLAINコマンドの出力は以下のようになりました。
下から順に「読み込み(Scan)・並び替え(Sort)・先頭行抽出(Limit)」が実行されており、cost値が高いSortなどが実行のネックになっていると推測できます。
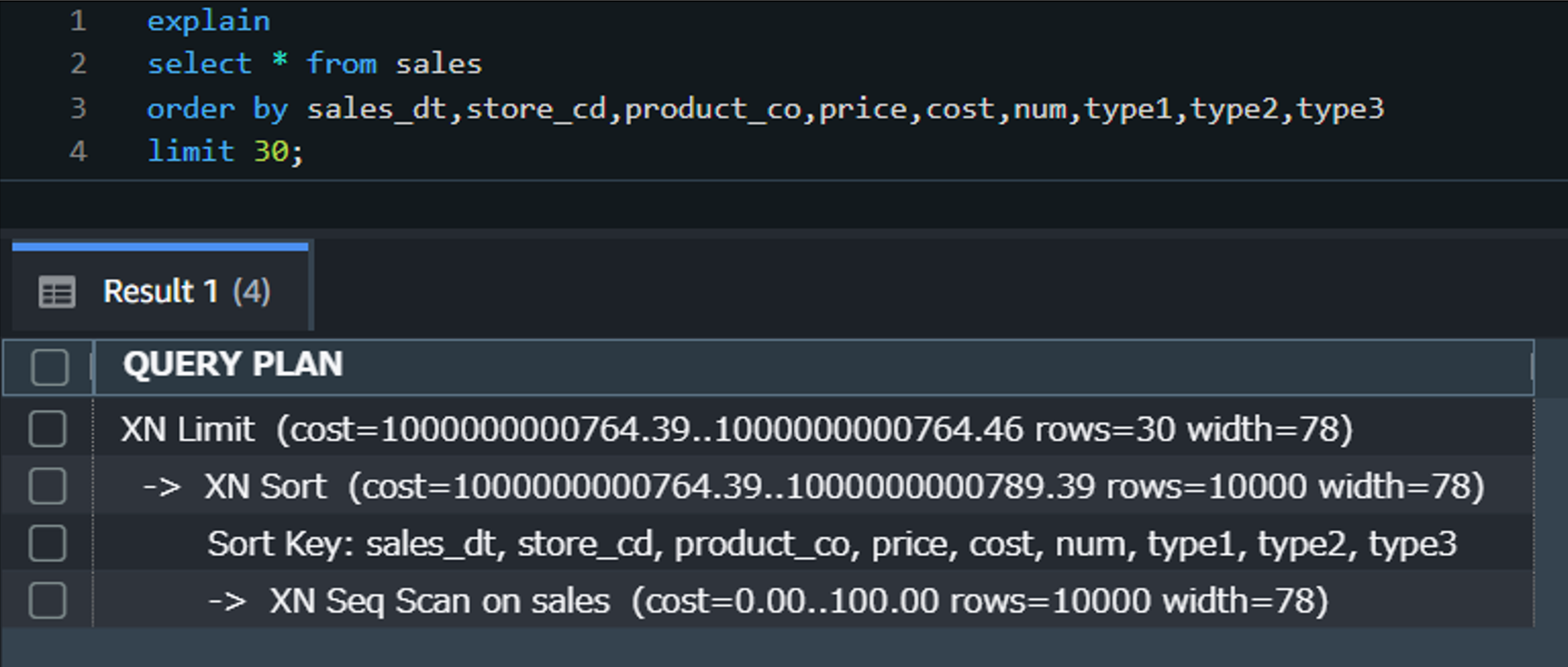
cost:1.00がシーケンシャルでの1ページ読み込みに相当するコストの相対値
rows:クエリが処理する推定行数
width:クエリ結果の各行が占めるバイト数
【Query Profiler】
Query1の実行結果をQuery Profilerで確認すると以下のように表示されました。処理の大部分が大量のテーブル結合に費やされている様子が、段々状に可視化されていました。各ステップで1つずつテーブルが結合されていき、結合処理が積み重なって最終的な結果に至っていることが確認できます。
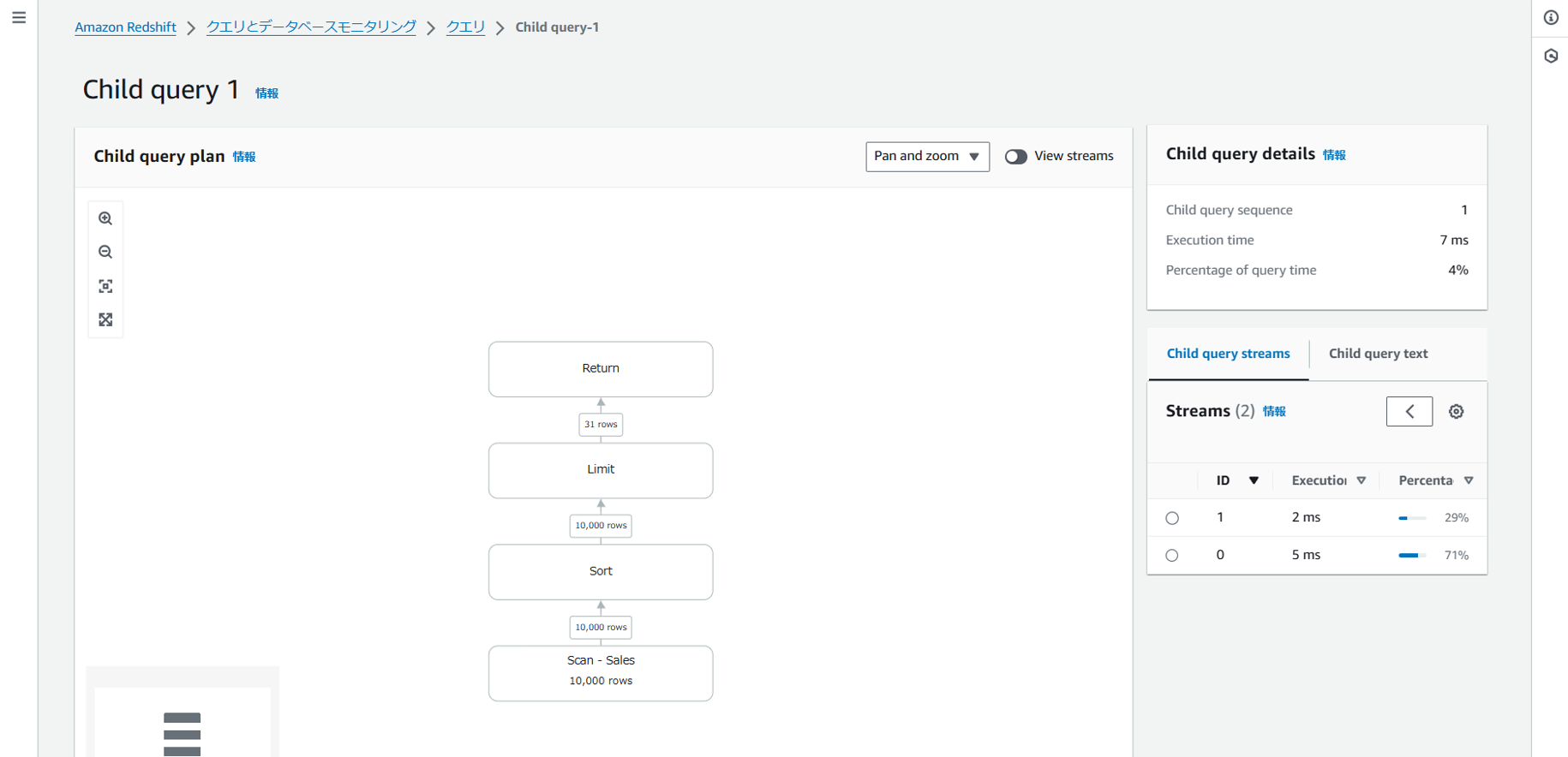
また「View streams」をオンにすることで、Streamというより大きな粒度でも捉えることができます。右ペインには全体の実行時間と、各ストリームに要した割合が表示されます。
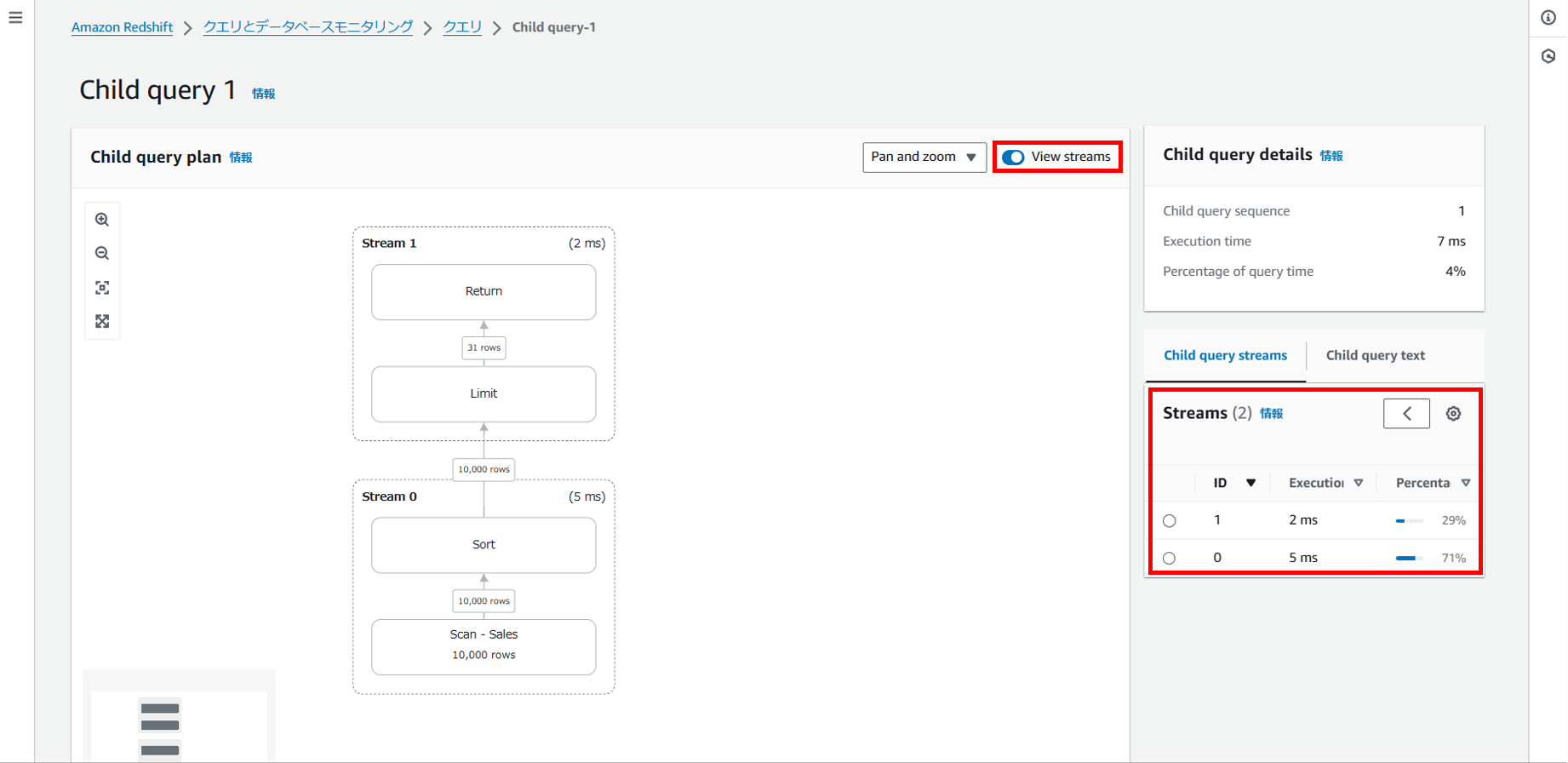
各ステップやストリームをクリックすると、右ペインにより詳細な情報が表示され、ステップ単位での入出力行数や所要時間がわかります。
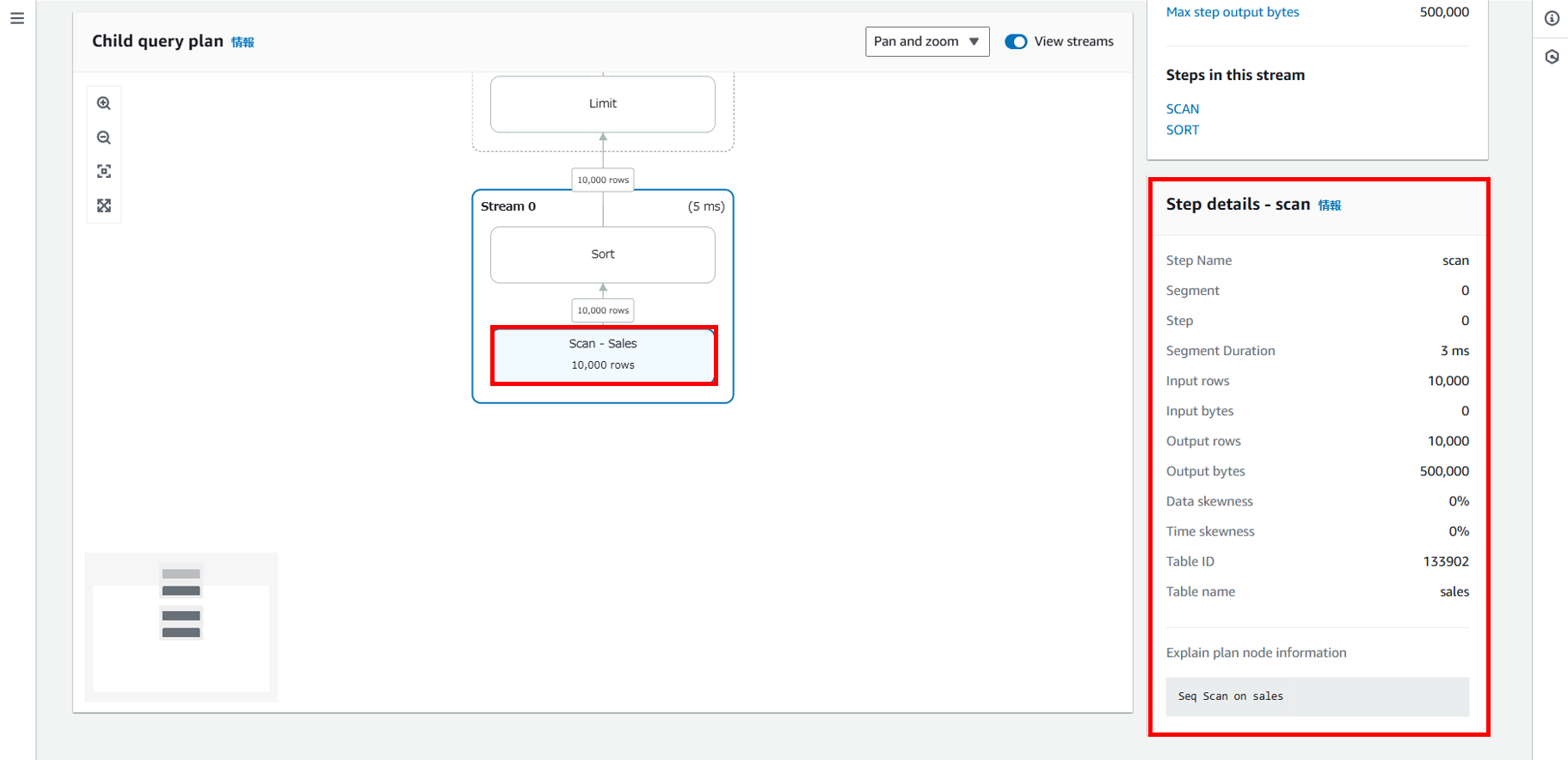
Query Profilerではフロー図と豊富な指標値によって、より直感的な実行計画の理解をサポートすると感じました。
2-2-2. Query2
【EXPLAINコマンド】
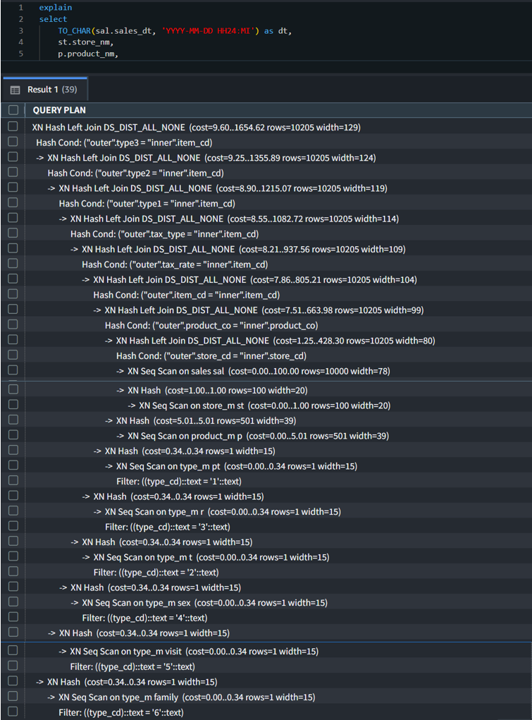
Query2に対するEXPLAINコマンドの出力は以下のようになりました。
階層的にインデントはされているものの、長大で全体の把握やネックになっている箇所の判別には時間を要します。
(
【Query Profiler】
Query2の実行結果をQuery Profilerで確認すると以下のように表示されました。Query1と比べると複雑ではありますが、木構造によって「どのテーブルがどの順で結合しているか」をより直感的に理解できます。
Query1と同様に右ペインにはストリームレベルで実行時間の割合が表示され、Query2では特にストリーム6で実行時間がかかっていることがわかります。
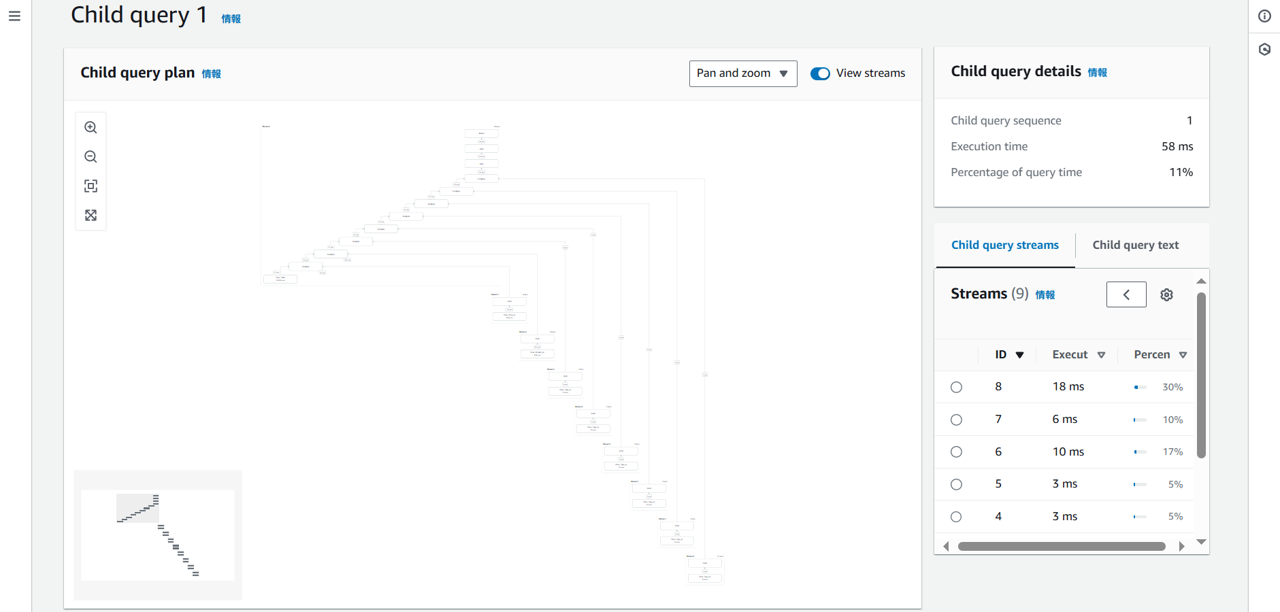
Query Profilerでは、大規模で複雑なクエリに対するボトルネックの特定をより迅速に行うことができると感じました。
2-2-3. Query2のチューニング後のQuery Profilerの情報変化の確認
最適化前後の情報変化の調査のため上記SQLとの比較用SQLを作成しました。
【Query2】4つのテーブルに対する結合を含む冗長なSQL文を最適化したものです。
with pr as (
select
p.product_co,
p.product_nm,
pt.item_nm as product_type,
case when t.item_nm = '非課税' then '0' else r.item_nm end as tax_r,
case when r.item_nm = '0' then '非課税' else t.item_nm end as tax_t
from product_m p
left join type_m r
on p.tax_rate = r.item_cd and r.type_cd = '3'
left join type_m t
on p.tax_type = t.item_cd and t.type_cd = '2'
left join type_m pt
on p.item_cd = pt.item_cd and pt.type_cd = '1'
)
select
TO_CHAR(sal.sales_dt, 'YYYY-MM-DD HH24:MI') as dt,
st.store_nm,
pr.product_nm,
pr.product_type,
pr.tax_r,
pr.tax_t,
(sal.price - sal.cost) * sal.num as reve,
sex.item_nm as sex,
visit.item_nm as visit,
family.item_nm as family
from sales sal
left join store_m st
on sal.store_cd = st.store_cd
left join pr
on sal.product_co = pr.product_co
left join type_m sex
on sal.type1 = sex.item_cd and sex.type_cd = '4'
left join type_m visit
on sal.type2 = visit.item_cd and visit.type_cd = '5'
left join type_m family
on sal.type3 = family.item_cd and family.type_cd = '6';
クエリの実行計画をQuery Profilerで可視化したところ、最適化前の状態では複数のテーブル結合が段々に積み重なるような構造となっており、各ステップで順次結合処理が実行されている様子が確認できました。
この構造に対して、一部の結合処理をWITH句(共通テーブル式)として切り出すことでクエリを最適化した結果、段々状に並んでいた処理の一部が飛び出して独立したブロックとして描画されるように変化しました。これにより、処理の流れがよりシンプルかつ効率的になったことが明らかです。
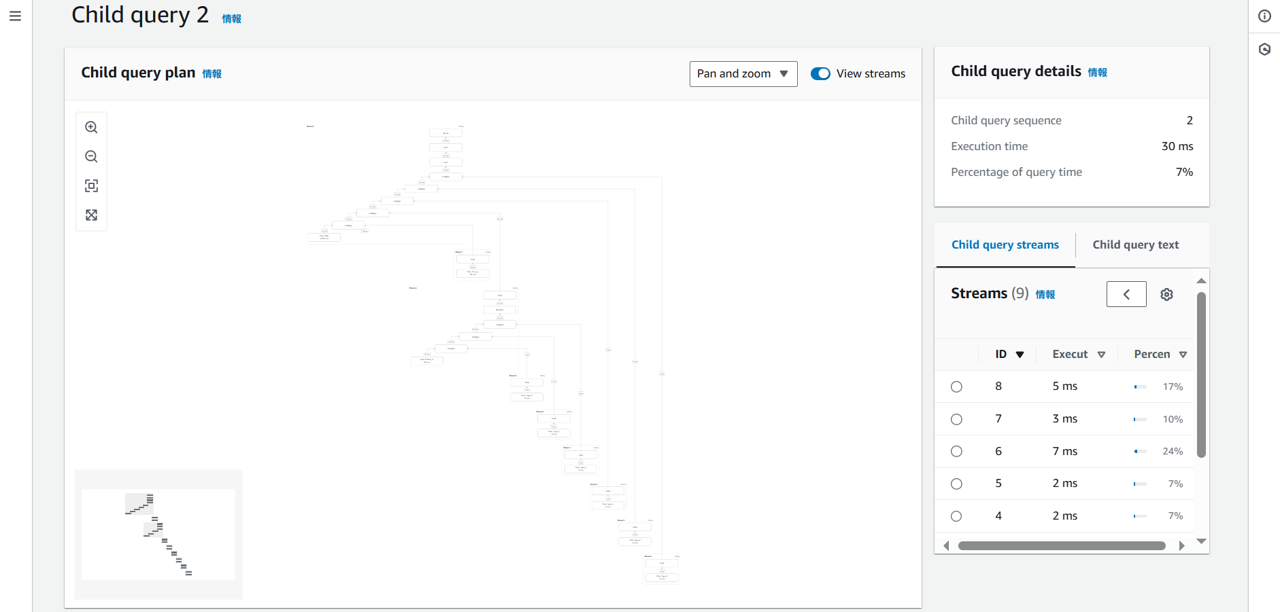
実行時間にも明確な改善が見られ、最適化前は約50ms台だった処理時間が、最適化後には30ms台まで短縮されました。結合の再構成が、パフォーマンスに対して実質的な効果を持つことを裏付ける結果となっています。
3. おわりに
今回はQuery Profilerについての検証結果をご紹介しました。
今回の検証を通して、EXPLAIN は「クエリの設計図」、Query Profiler は「その設計が実際にどう動いたかを確認するレポート」のような関係であることが改めて分かりました。
実行計画だけでは読み取れない、実際の処理時間やボトルネックを確認するには、両者をセットで活用することが非常に効果的です。特に大規模で複雑なクエリに対するボトルネックの特定をより迅速に行う目的においては、以下のようなフローでSQLチューニングを行うことをおすすめします。
①EXPLAIN で実行計画を確認(インデックス・JOIN順など)
②Query Profiler で実際の処理コストを計測
③問題があるステップに対してインデックス追加やSQLの見直し
④改善前後を比較して効果を定量的に把握
SQLのパフォーマンス改善に関して、この記事が皆様の第一歩としてお役に立てれば幸いです。
参考
1.Query Profiler-AmazonRedshift
2.EXPLAIN - Amazon Redshift
株式会社ジールでは、「ITリテラシーがない」「初期費用がかけられない」「親切・丁寧な支援がほしい」「ノーコード・ローコードがよい」「運用・保守の手間をかけられない」などのお客様の声を受けて、オールインワン型データ活用プラットフォーム「ZEUSCloud」を月額利用料にてご提供しております。
ご興味がある方は是非下記のリンクをご覧ください: