はじめに
2026年4月6日に理研,東大所属のKen M. Nakanishi氏から衝撃的な論文がarxivにて公開されました.それがScreening is enoughという論文です.(https://arxiv.org/abs/2604.01178)
従来のAttentionベースのTransformerに比べて92%のパラメータ削減に加えて,100kトークンの文脈における推論速度が最大3.2倍になるという驚異的な結果です.自らの勉強のためにもここに内容を要約していきます.今のところ,Attentionと似ていますが,閾値で0を与えるところが大きく違うっぽいです.また,architectureの構造部分の解説のみを書いていますので,結果については原論文を当たっていただければと思います.間違えているところもあるかもしれません.コメント等でご指摘いただけると幸いです.
1 Introduction
従来のLLMはSoftmax-based attentionを用いています.これは,重みを足し合わせたときに1になり,確率分布としてとらえることができるため,非常に良いモデルとされてきました.しかし,いくつかの問題点があります.Softmaxを用いていることで,必ずAttention Weightは0以上になります.つまり,関連するトークンの信号が多数の無関係なトークンによって減衰してしまうAttention Fadingが不可避となるわけです.Multiscreenはこの無駄を取り除くことで,長距離情報のより効果的な活用を可能にします.
実験の結果,Multiscreenは約40%少ないパラメータで同等の精度を達成し,大幅に大きな学習率でも安定的に学習を行えることを示しました.また,学習時を大幅に超える文脈長においても精度低下がほとんど見られませんでした.
2 Related Work
従来のSoftmax-based attentionは入力を確率分布に変換し,全要素の和を1にします.しかし,この数学的性質が長文脈においては逆に弱点となります.
Softmax-based attentionでは,query $q$とkey $k_j$に対してスコア$s_j=q \times k_j$を計算し,重み$w$を$w_j=\frac{exp(s_j)}{\sum(exp(s_j)}$として計算します.しかし,長文脈となると,Attention Fadingが発生してしまいます.また,Softmaxは常に正の重みを割り当てるために,ノイズが蓄積されること.さらに,コンテキスト内に適切な回答がない場合も,Attentionは何かに重みを振らないといけないため,Hallucinationが発生してしまうことも問題となります.
この問題に対して,Scalable-Softmax(SSMax)やスパース性を導入するsparsemaxやentmaxなどが提案されてきました.Multiscreenはこれらの手法とは異なり,有界な類似度と明示的な閾値を導入することで,真に系列長に依存しない絶対的な関連性を表現することが可能です.
3 Model Architecture
MultiscreenはTransformerの層構造を維持しつつ,Self-AttentionとFeed Forward Networkの部分を並列化されたGated Screening Tilesで置き換えます.
3.1 Overview
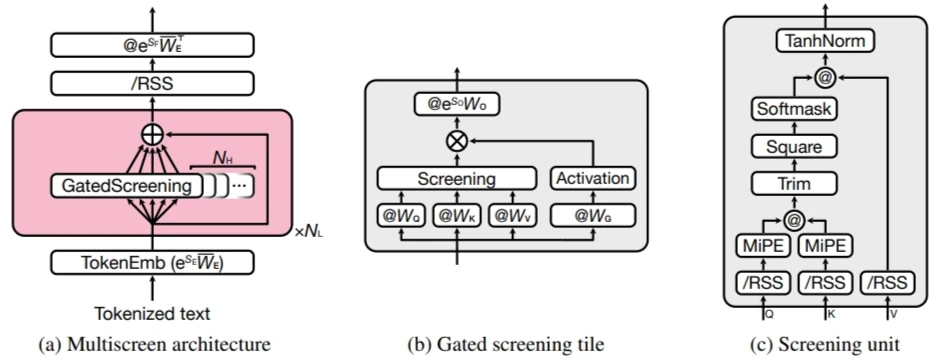
Fig.1がMultiscreenのモデル図です.モデルは$N_L$個の残差層で構成され,各層は$N_H$個の並列なGated Screening Tile $h$を含みます.入力トークン$i$の表現$x_i^{(l)}$の更新式は以下の式で表されます.
$$
x_i^{(l)}=x_i^{(l-1)}+\sum_{h=1}^{N_H}\Delta x_i^{(l,h)}
$$
ここで,$\Delta x_i^{(l,h)}$はタイル$h$からの出力を表し,次の式で表されます.
$$
\Delta \mathbb{x_i}=\mathbb{h_i}(e^{SO}W_o)
$$
TransformerのMultihead-Attentionでは集約後に一つの大きなFFNを通すのに対し,Multiscreenは各タイル内でGate制御と射影を行います.
各タイル$h$は,入力$x_i$をquery $q_i\in \mathbb{R}^{d_K}$,key $k_i\in \mathbb{R}^{d_K}$,value $v_i\in \mathbb{R}^{d_V}$およびゲート$g_i\in \mathbb{R}^{d_V}$に射影します.Screening Unitは射影された$q,k,v$を用いて,関連するコンテキストを集約し,有界な表現$u_i$を生成します.非線形層は$g_i$に対して,$\hat{g_i}=\mathrm{tanh}(SiLU(g_i))$を適用し,情報の通過を制御します.ここで$SiLU$とは,$SiLU(x)=\frac{x}{1+\mathrm{exp}(-\beta x)}$で表される非線形活性化関数です.$\beta$は学習可能パラメータです.次に,$h_i=u_i\odot\hat{g_i}$を計算します.
この構造はGLU(Gated Linear Unit)の拡張とみなすことができ,線形変換の一部がScreeningによるコンテキスト集約に置き換わったものと解釈できます.
Screening Unitは次の手順で情報を処理します.
まず,query,key,valueをそれぞれ行ごとにユニット長に正規化します.
$$
\overline{q_i}=\frac{q_i}{|{q_i}|},\overline{k_j}=\frac{k_j}{|{k_j}|},\overline{v_i}=\frac{v_i}{|{v_i}|}
$$
これにより,queryとkeyのドット積である類似度$s_{ij}=\overline{q_i}\overline{k_j}^T$は$[-1,1]$の範囲に収まります.これは,固定の閾値の適用するために行っています.
Multiscreenは長距離外挿を可能にするために,minimal positional encoding(MiPE)を導入します.これはRotary Positional Embedding(RoPE)に似た回転をqueryとkeyに適用します.RoPEとはTransformer内のpositonal encodingに用いられるencoderです.sinとかcosで文章内での単語の位置情報を付加してベクトルを回転させるものです.MiPEは以下の二つの特徴を持ちます.回転はベクトルの最初の2座標のみに適用され,回転の強さは学習された窓パラメータ$w$に依存する関数$\gamma{(w)}$で制御され,次の式で表されます.
$$
\gamma(w) = \begin{cases} \frac{1}{2}(\cos \frac{\pi w}{w_{th}} + 1) & w < w_{th} \ 0 & w \ge w_{th} \end{cases}
$$
つまりモデルがこのタイルは局所的な情報を処理するべきだと判断して,$w$を小さくした場合のみ位置情報が付加され,長距離情報を処理する場合には位置情報が無効化されます.これにより,学習時以上の長時系列における未知の位置パターンによるエラーをふさいでいます.
類似度$s_{ij}$は学習可能なパラメータ$r$を用いて非線形な関連性$a_{ij}$に変換されます.
$$
\alpha_{ij} = [\max(1 - r(1 - s_{ij}), 0)]^2
$$
つまり,$s_{ij} \leq 1-\frac{1}{r}$のときに$\alpha_{ij}=0$となります.この$0$がとても重要で,Transformerとの最大の違いです.このおかげでノイズの蓄積を防いでいます.
因果性を維持しつつ窓の境界を滑らかにするために,softmaskを適用します.
$$
m_{ij}(w) = \begin{cases} \frac{1}{2}(\cos \frac{\pi(j-i)}{w} + 1) & -w < j-i \le 0 \ 0 & \text{otherwise} \end{cases}
$$
最終的な関連度は次の式のようにあらわされます.
$$
\alpha_{ij}^d = \alpha_{ij} m_{ij}(w)
$$
これを用いてvalueを集約します.集約された表現は次の式で表されます.
$$
h_i = \sum_{j=1}^T \alpha_{ij}^d \overline{v_j}
$$
この$h_i$に対して,出力のノルムを制御するTanhNormを適用します.
$$
\text{TanhNorm}(h) = \frac{\tanh |h|}{|h|} h
$$
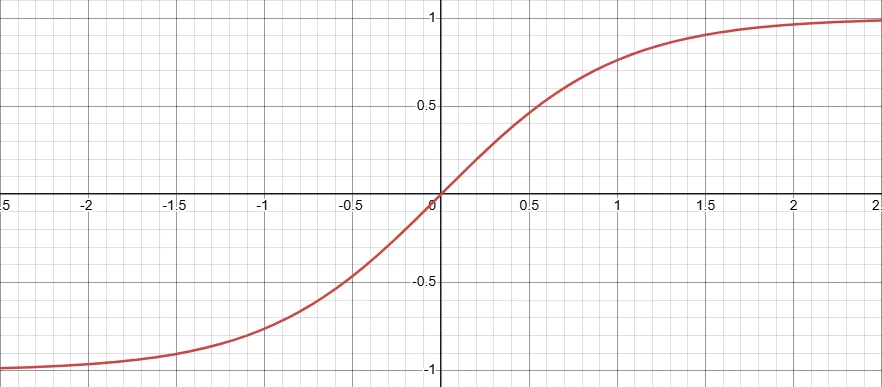
描画してみるとこんな風になり,ノルムが小さいときは恒等写像のようにふるまい,ノルムが大きくなると滑らかに1に漸近していくことがわかります.