統計検定2級で標本平均についての問題が出てきますが、その一つに
「標本平均のばらつき(標準偏差)は
\frac{population\ sd}{\sqrt{sample\ size}}
に従う」
とされます。
これを確認します。
最初に結論から言うと、標本平均は母集団平均から正の方向にズレることもあれば負の方向にズレることもある。
しかし、標本は母集団平均の周辺から(曖昧な表現ですが)遠く離れることはあまりない。
よって母集団の標準偏差をサンプルサイズで割ったくらいの範囲に縮むのです。
一方標本平均は母集団平均の近くから抽出される確率が高いので、
標本平均は母集団平均と近しい値になります。
検証
n=10000
m=100
s=30
hist(rnorm(n, m, s))
こんな正規分布からサンプルサイズ100の標本を作る。
その標本の平均の分布を確認する。
norm_data <- rnorm(n, m, s)
bind_mean <- NULL
bind_sd <- NULL
for(i in 1:100000){
set_number <- sample(n)
group_1 <- norm_data[set_number[1:100]]
sample_mean <- mean(group_1)
sample_sd <- sd(group_1)
bind_mean <- c(bind_mean, sample_mean)
bind_sd <- c(bind_sd, sample_sd)
}
par(mfrow=c(2, 1))
hist(rnorm(n, m, s),xlim=c(0, 200), main = paste0("population sd is ", s))
hist(bind_mean, xlim=c(0, 200), main = paste0("sample mean sd is ", round(sd(bind_mean), 3)))
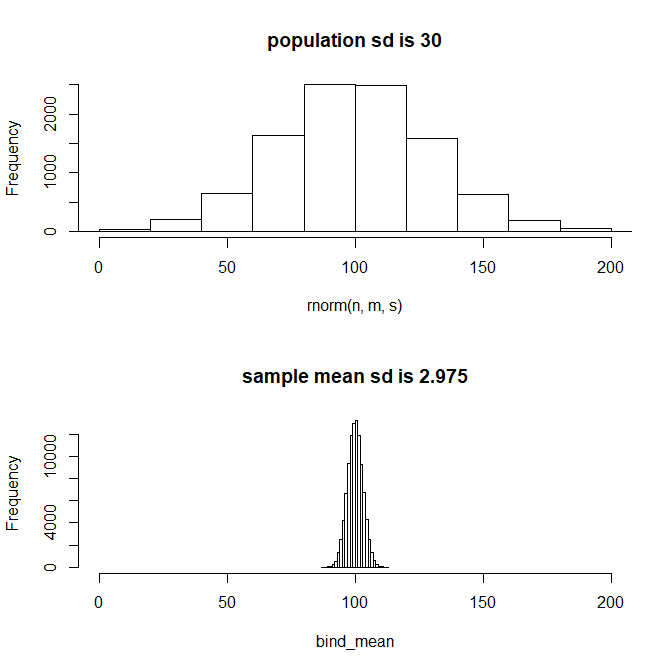
確かに母集団の平均に近い値周辺に散らばっている。
標本平均の分散を計算で求めてみると、2.975となった。
\frac{population\ sd}{\sqrt{sample\ size}}
が成り立っているのか。
> s / sqrt(100)
[1] 3
もともと創り出した母集団の標準偏差は30であり、サンプルサイズ100の平方根は10なので、
30割る10となるので3と計算される。
2.975は近しい値をとっているといえる。
ちなみに標本平均は
ヒストグラムで確認して既に「母集団平均」と「複数の標本平均の平均」は近い値になっているように見えるが念のため。
> m
[1] 100
> mean(sample_mean)
[1] 101.4024
こうした分布が発見されたために母集団のパラメータが未知の時の検定ができるようになったわけです。
どんな時につかうの?
例としてこんな問題を使う。
全国のテストのデータから算出した母数によると、点数は正規分布に従い、平均50標準偏差10だった。(母平均、母標準偏差が既知)
5人のテストの点数の平均が52点以上になる確率は?(標本平均)
ここで注意しなければいけないのは「5人の平均」というところ。
たった1人のテスト受験者が52点以上をとる確率は?と聞かれたら、純粋に標準正規分布に変換し、Zスコアを出す。
↓
標準正規分布の上側確率の表を見ながらZスコアの位置を調べ、確率(問題の答え)を得る。
Zscore=\frac{x-\mu}{\sigma}
となるが、「5人の平均」について語るときには5人の中に高い点を取る人、低い点を取る人がランダムに混ざった、その前提で52点となる確率を聞かれている。
即ち、「5人の標本平均」を標準正規分布に直すためには、「標本標準偏差」で割ってやらなければいけない。
本記事で書いた通り、標本平均の標準偏差はサンプルサイズに影響を受けるので、
Zscore=\frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}}
と計算する必要がある。
ここまで計算してしまえば、標準正規分布に従うZスコアになったので上側確率のZスコア表と見比べて答えを得ればいい。