はじめに
この記事は R Advent Calendar 2021の9日目の記事です。
日本最大級のRコミュニティであるJapan.Rが2021年度も無事開催され、Rに関する様々な知見が共有されておりました。
かくいう私も昨年に引き続き、tidymodelsについて稚拙なライトニングトークをさせていただきました。
今回はtidymodelsについて抜粋してパッケージを紹介し、より皆様にtidymodelsを、そしてR言語を知っていただければ幸いです。
autoMLとは
ML・・・つまりマシンラーニング(機械学習)
を
auto・・・自動化
にしたものです。
検索するといくつか有名な企業のソフトウェアが表れます。
pythonにもautoMLを志向したパッケージがあります。
「自動化」と呼ばれる範囲は様々であり、コーディング無しでcsvを突っ込むだけでなんとかしてくれることを自動化という場合もあれば、簡単な入力をすることで必要な物を吐き出してくれる仕組みのことを自動化と呼ぶ場合もあります。
本記事では後者の内容になります。
tidymodelsでの機械学習
tidymodelsをご存じでない方に向けて簡単にご紹介を。
tidymodelsとはtidyverseと同じくRstudio社が開発する「機械学習のためのパッケージ群」の名称です。
tidymodelsでは
「アルゴリズムの選択」「学習テストデータの用意」「前処理」を分割的に保持して最後に学習させ、学習済みオブジェクトを可搬性高い状態で保持することができます。
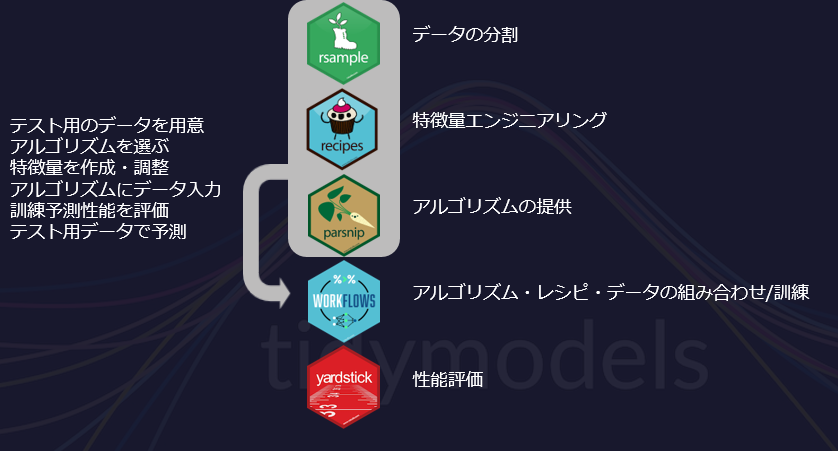
図:catching-up-with-the-tidymodelsより
モデル構築は主題ではないのでこれ以上説明は致しません。
tidymodelsを詳しく知りたい方はget startedをご一読ください。
機械学習と自動化{usemodels}
機械学習を行っている諸先輩方であれば
「まーた同じコード書くのか。めんどくさいなぁ。」
と感じられたことはあるのではないでしょうか?
特に機械学習の周辺では大半のアルゴリズムは入力と出力の設定が済めば、あとは計算機が頑張って計算するだけなのです。
課題(データ)に応じて人間が対処すべき作業は以下でしょう
- タスクに応じて適応するアルゴリズムを選ぶ
- 数学的理論を理解し入力データを正しく加工する
- データのクレンジング、正しく検証データを分割する
- 有益な特徴量を設計する特徴量エンジニアリング
- 性能の評価とモニタリング
より複雑な操作が必要なテーマとしては「調整やスクラッチでの実装が必要な深層学習」ではないでしょうか。
しかし、旧来から存在している有名なアルゴリズムは入力があれば出力を返す簡単な関数になっているので、上記の作業が終わっていればあとの大半は決まったコードを積み上げればいいだけになっています。
さらに言語やパッケージ開発者によって、コード自体も簡単に短く記述できるように抽象化されてきています。
たとえばR言語のtidymodelsパッケージを例にとると、以下のようなコードが最小限必要なコードになっています。
例としてxgboostを使いたい時のコードを記述します。
※ライブラリの読み込みは無視しています。
ames <- ames %>%
mutate(Sale_Price=log10(Sale_Price))
train_test <- initial_split(ames,strata = Sale_Price)
train <- training(train_test)
test <- testing(train_test)
xgboost_recipe <-
recipe(formula = Sale_Price ~ ., data = train) %>%
step_前処理(all_predictors())
xgboost_spec <-
アルゴリズム() %>%
set_mode("regression") %>%
set_engine("アルゴリズムを提供できるパッケージ xgboost")
xgboost_workflow <-
workflow() %>%
add_recipe(xgboost_recipe) %>%
add_model(xgboost_spec)
xgboost_fit<- fit(xgboost_workflow,train)
上記コードがデータサイエンティストが用意しなければいけない最小限のコードとなっています。
そんなに多くないように感じられますが、
- 毎日繰り返し書く
- 特定期間のうち何度も繰り返し実行する
- 少しパッケージを変えたものを試してみたい
- チューニング項目を調整する度に書き直して別で保存する
などが積み重なるとストレスになります。
そこで登場する便利なパッケージがusemodelsです。
バージョンは0.1.0(tidyverseなら1.0から正式リリース)と開発途上ですが、現在6種類のアルゴリズムに対して自動でコードを提供してくれるようになっています。
use_glmnet()
use_xgboost()
use_kknn()
use_ranger()
use_earth()
use_cubist()
たとえば上記のxgboostのコードを作り出したい時は、
usemodels::use_xgboost(Sale_Price ~ .,train)
これを実行するだけでいいのです。
するとコンソール上で
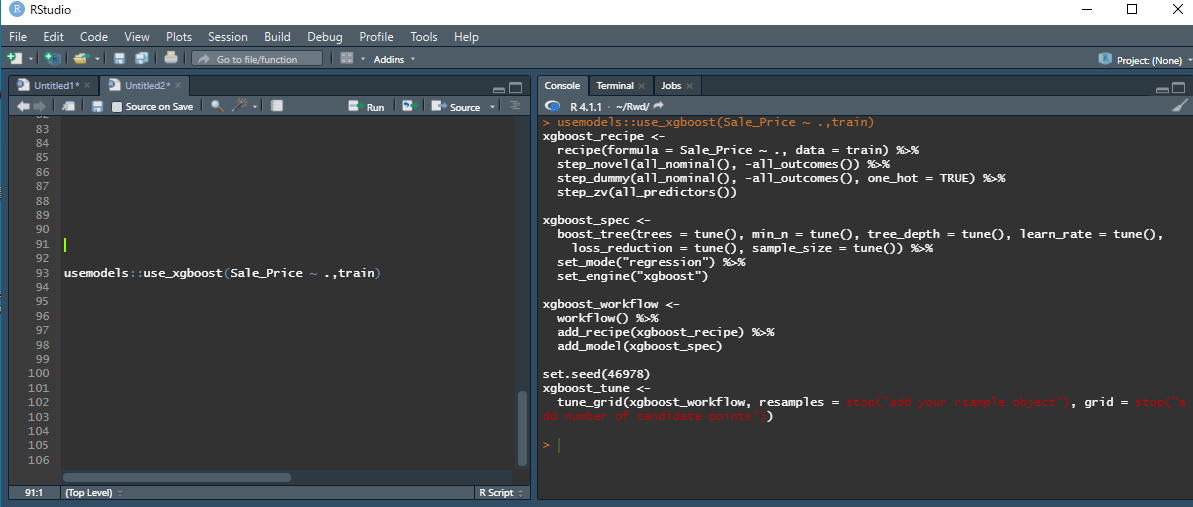
コードのテンプレートが帰ってきます。
現在チューニング項目が自動でついてくる設定になっていますが、オプションでチューニング無しを選択することも可能です。
これで劇的にコーディングストレスが低下します。
何よりアルゴリズムに対する前処理を毎回覚えているのは面倒なので、アルゴリズムに合わせた最低限の前処理を提供してくれるところには個人的に感謝しています。
複数アルゴリズムを試す過程を「自動化」と呼ぶ場合{workflowsets}
usemodelsのように「コードのテンプレートを出力してくれる」というのは一つの助けになります。
今までお話してきた中で、
タスクに応じて適応するアルゴリズムを選ぶ
少しパッケージを変えたものを試してみたい
というステップが発生することを示しました。
データとアルゴリズムの相性が未知の場合には「とりあえず試してみる」というステップが発生することもあります。
複数のアルゴリズムと前処理でベースラインを定めるような場合です。
その際にはusemodelsパッケージを使っても以下のようなコードを用意する必要が出てきます。
use_glmnet(Sale_Price ~ .,train,tune = F)
use_xgboost(Sale_Price ~ .,train,tune = F)
use_ranger(Sale_Price ~ .,train,tune = F)
帰ってくる結果は
> use_glmnet(Sale_Price ~ .,train,tune = F)
glmnet_recipe <-
recipe(formula = Sale_Price ~ ., data = train) %>%
step_novel(all_nominal(), -all_outcomes()) %>%
step_dummy(all_nominal(), -all_outcomes()) %>%
step_zv(all_predictors()) %>%
step_normalize(all_predictors(), -all_nominal())
glmnet_spec <-
linear_reg() %>%
set_mode("regression") %>%
set_engine("glmnet")
glmnet_workflow <-
workflow() %>%
add_recipe(glmnet_recipe) %>%
add_model(glmnet_spec)
> use_xgboost(Sale_Price ~ .,train,tune = F)
xgboost_recipe <-
recipe(formula = Sale_Price ~ ., data = train) %>%
step_novel(all_nominal(), -all_outcomes()) %>%
step_dummy(all_nominal(), -all_outcomes(), one_hot = TRUE) %>%
step_zv(all_predictors())
xgboost_spec <-
boost_tree() %>%
set_mode("regression") %>%
set_engine("xgboost")
xgboost_workflow <-
workflow() %>%
add_recipe(xgboost_recipe) %>%
add_model(xgboost_spec)
> use_ranger(Sale_Price ~ .,train,tune = F)
ranger_recipe <-
recipe(formula = Sale_Price ~ ., data = train)
ranger_spec <-
rand_forest(trees = 1000) %>%
set_mode("regression") %>%
set_engine("ranger")
ranger_workflow <-
workflow() %>%
add_recipe(ranger_recipe) %>%
add_model(ranger_spec)
これらをすべてで学習を実行して、さらに個別に評価指標を定め性能を評価し、加えて性能を並列で比較できるように処理する必要があります。
モデルを作るまでは楽でも、「モデル学習と性能比較」の段階での複雑さが解消されないままです。
このような場合にはworkflowsetsパッケージが役に立ちます。
簡単に説明すると、モデル、前処理の組み合わせを自動でデータにフィッティングさせて一つの結果として返してくれます。
上記のコードから、前処理である**--_recipeとモデル定義である--_spec**を取り出して使いたい前処理とモデルをリスト形式で渡すだけです。
library(workflowsets)
glmnet_recipe <-
recipe(formula = Sale_Price ~ ., data = train) %>%
step_novel(all_nominal(), -all_outcomes()) %>%
step_dummy(all_nominal(), -all_outcomes()) %>%
step_zv(all_predictors()) %>%
step_normalize(all_predictors(), -all_nominal())
glmnet_spec <-
linear_reg() %>%
set_mode("regression") %>%
set_engine("glmnet")
xgboost_recipe <-
recipe(formula = Sale_Price ~ ., data = train) %>%
step_novel(all_nominal(), -all_outcomes()) %>%
step_dummy(all_nominal(), -all_outcomes(), one_hot = TRUE) %>%
step_zv(all_predictors())
xgboost_spec <-
boost_tree() %>%
set_mode("regression") %>%
set_engine("xgboost")
ranger_recipe <-
recipe(formula = Sale_Price ~ ., data = train)
ranger_spec <-
rand_forest(trees = 1000) %>%
set_mode("regression") %>%
set_engine("ranger")
multi_models <-
workflow_set(
preproc = list(
glmnet_rec = glmnet_recipe,
xgboost = xgboost_recipe,
ranger = ranger_recipe),
models = list(
glmnet_spe = glmnet_spec,
xgboost_spe = xgboost_spec,
ranger_spe = ranger_spec),
cross = F
)
multi_models
# A workflow set/tibble: 3 x 4
wflow_id info option result
<chr> <list> <list> <list>
1 glmnet_rec_glmnet_spe <tibble [1 x 4]> <opts[0]> <list [0]>
2 xgboost_xgboost_spe <tibble [1 x 4]> <opts[0]> <list [0]>
3 ranger_ranger_spe <tibble [1 x 4]> <opts[0]> <list [0]>
splits <- train %>% vfold_cv(v=4,strata = Sale_Price)
multi_models_res <-
multi_models %>%
workflow_map("fit_resamples", resamples = splits,
metrics = metric_set(mae,rmse),
verbose = TRUE)
multi_models_res %>%
rank_results()
# A tibble: 6 x 9
wflow_id .config .metric mean std_err n preprocessor model rank
<chr> <chr> <chr> <dbl> <dbl> <int> <chr> <chr> <int>
1 ranger_ranger_spe Preprocessor1_Model1 mae 17269. 162. 4 recipe rand_fore~ 1
2 ranger_ranger_spe Preprocessor1_Model1 rmse 28816. 1279. 4 recipe rand_fore~ 1
3 xgboost_xgboost_spe Preprocessor1_Model1 mae 18325. 454. 4 recipe boost_tree 2
4 xgboost_xgboost_spe Preprocessor1_Model1 rmse 29797. 1760. 4 recipe boost_tree 2
5 glmnet_rec_glmnet_spe Preprocessor1_Model1 mae 19694. 346. 4 recipe linear_reg 3
6 glmnet_rec_glmnet_spe Preprocessor1_Model1 rmse 42561. 3696. 4 recipe linear_reg 3
んー素晴らしい。
簡単にベースラインとして、どのアルゴリズムが適していそうか見当をつけることが出来ました。
まとめて学習させた後にはrank_results()やcollect_metrics()で一気に性能を表示することができます。
綺麗なtibble形式で結果が返ってくるためggplot2パッケージと自然につながり、性能をドットウィスカープロットにすることも容易です。
resampleによる結果をtidyposteriorのperf_mod()に渡すことでベイズ的な事後分布を算出することも可能です。
最後に
今回はtidymodelsの{usemodels}と{workflowsets}を紹介し、AutoMLのようなことを実現させてみました。
あくまでもモデルとデータの相性のベースラインであり、より深く確かめないと本当に適しているかはわかりませんが、これらを組み合わせることで深掘りする際にも半自動化で進められることでしょう。
さらに使い道をご紹介すると、
workflowsetsパッケージを使うことで、モデルだけでなくどのような特徴量が適しているかを知ることもできるのです。
単純な例を挙げるとするならば特徴量を一つづつのぞいた前処理を用意して、線形回帰モデルに対してworkflowsetsのworkflowmapを実行してあげれば特徴量選択が出来ます。
効果検証の目的であるならば脱落変数バイアスを見つける助けにもなるでしょう。
enjoy!!
tidymdoelsによってあなたのデータサイエンスが少しでも素敵なものになりますように。