Machine&Deep Learning論文紹介 Advent Calendar 2020の二日目
生成モデルによる異常検知をまとめたので記事にする
生成モデルの前に
Auto encoder (science,2006,hinton):Reducing the Dimensionality of Data with Neural Networks
autoencoderはhinton氏が「次元削減」という目的に2006年に投稿した論文
高次元なデータ、画像はノイズを含んでいることも多く、さらに次元の呪いなどもあり扱いづらいので
次元を減らせたら嬉しい
考え方としては主成分分析が近い
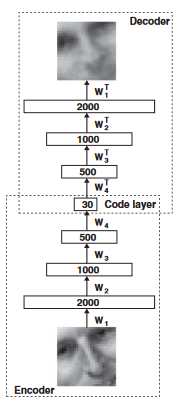
ネットワークを図のように構築する
入力画像2000次元を30次元の特徴量にまで減らす
減らした特徴量から元画像を再構築する
再構築した画像と元画像が似るように最適化することで、
画像の中の特に重要な要素だけを30次元に詰め込む考え
元画像(X)と構築画像(X hat)の差はL2誤差(二乗誤差)
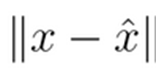
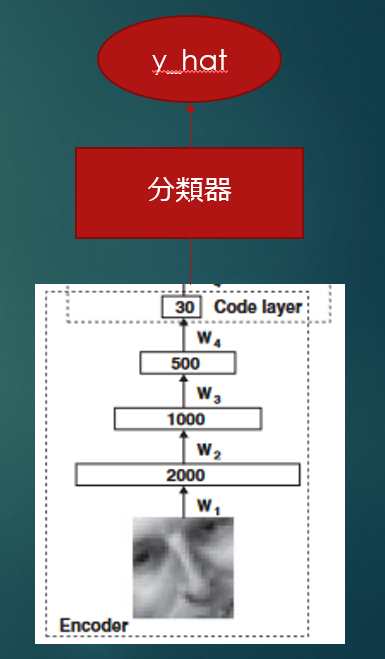
元画像の重要な情報だけになったので、この特徴量を使って分類器をつくることもできる
autoencoderは自己符号化器とも呼ばれ、自身の画像を低次元の特徴量に直すことが目的だった
生成モデル全体
生成モデル全体を俯瞰する
生成モデルとは、何もない所からデータを作り出すモデルである
autoencoderは入力である自分自身の画像が必要だったが、
生成モデルはノイズのような特定の画像のようなデータを持っていなくとも、目的の画像やデータが生成できる
その種類も複数ある
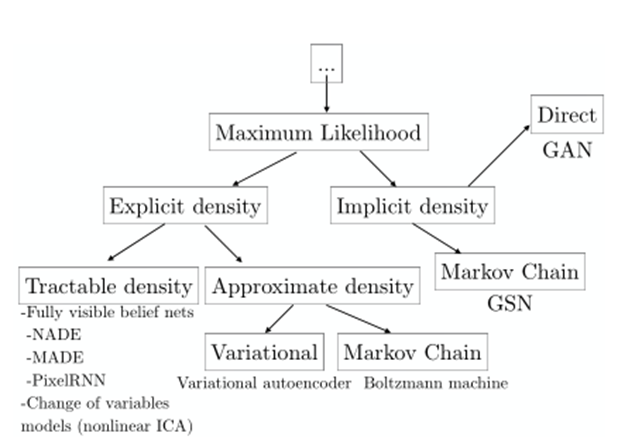
2017,Ian,NIPS 2016 Tutorial:Generative Adversarial Networks
種類を説明するためにはautoencoderで出てきたような「特徴量(潜在空間,潜在変数)」の考え方が重要になるので、
これも順次説明するつもり
VAE,GAN,GANを使った異常検知の順で紹介していこうと思う
まず簡単に他の背景を紹介
pixel-RNN
2016, Pixel Recurrent Neural Networks,AVDoord
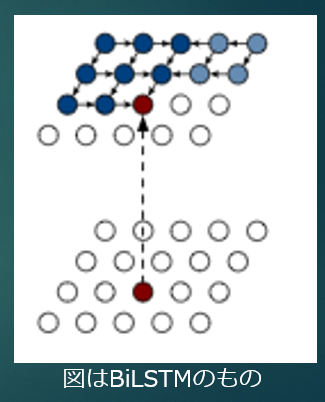
画像のピクセルはある法則で連なりながら生成することができるという考え
入力の一番最初のピクセルを入力すると画像が生成されていく
ただし順に伝播させていくので生成が大変に遅い
画像が大きくなればもう実用的でない
pixel-CNN
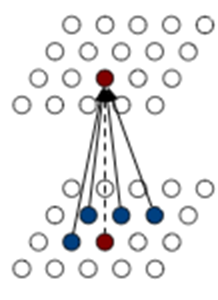
2016, Conditional Image Generation with PixelCNN Decoders,AVDoord
pixel-RNNは順にピクセルを伝播したが、画像は上下左右斜めの情報も大事なので
周辺を畳み込みネットで見る
周辺から一つ次のピクセルを予測することで生成していく
これも遅い
改善策としてスキップ構造の採用などが提案された
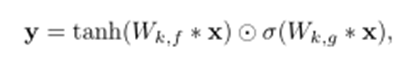
VAE(変分オートエンコーダー)
2014-D.P.kingma Auto-Encoding Variational Bayes
画像がautoencoderのように少ない特徴量にエンコードできるならば、
特徴量部分を確率分布にできないか?という考えから生まれた
確率分布(正規分布,ホワイトノイズ)に落とし込めたら、元画像が無くても画像が生成できるネットワークとなる
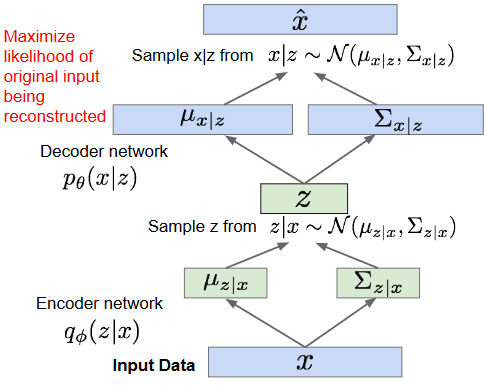
μとσだけで画像が生成できるネットワークfを作る
ただし、正規分布という確率分布に収めたために画像がボケてしまう問題が残る
それらしい画像はできるが高解像度には使いにくい
GAN
Generative Adversarial Networks, ian, 2014
ian氏が報告した生成モデル
二つのネットワークがゲーム理論的に戦い合い、正規分布ノイズから画像を生成するネットワーク:ジェネレータ
と
ジェネレータの作った画像が本物か偽物かを判断するネットワーク:ディスクリミネータ
の二つが戦う
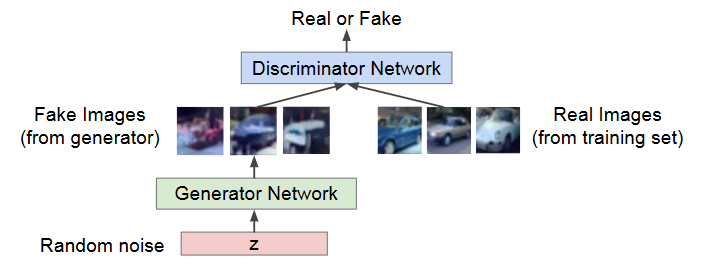
ジェネレータはノイズを入力として、最初はノイズのような画像しか生成しない
ディスクリミネータは生成したいリアル画像か、ジェネレータから作られた画像化を判断する
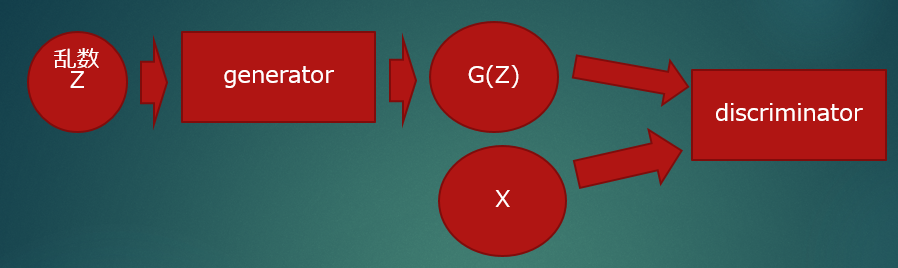
ディスクリミネータを騙せなかった場合にはジェネレータが再度騙せるようにネットワークを変更して挑む
・ディスクリミネータは騙されないように
・ジェネレータは騙すためのリアルな画像を作るように試行錯誤
この繰り返しによってジェネレータははリアルな画像を生成するようになる。
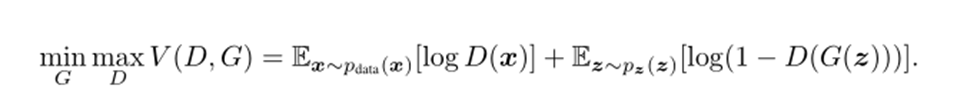
式を少し解説すると
G:ジェネレータ
D:ディスクリミネータ
- ニセモノの画像を判定する時は後ろの項だけ見る
- 乱数zをGに入力したニセモノの画像はG(z)
- ディスクリミネータにG(z)を通した判定結果はD(G(z))
- ディスクリミネータはD(G(z))を0(ニセモノ)と判定したい
- →少しでもD(G(z))を0に近づけたい(正しく判定)
- →1-D(G(z)) = 1 となるのはD(G(z))が0のとき
- →よって後ろの項は最大化の問題となる max D
- ジェネレータはD(G(z))を1(本物)にするようにニセモノを作りたい
- →D(G(z))が1になるならば、1-D(G(z))は0になる
- →よって最小化の問題となる min G
- ディスクリミネータはD(G(z))を0(ニセモノ)と判定したい
理想的なゴールは、
・ジェネレータは本物に近い画像を生成することでディスクリミネータは偽物か本物か判断できない=0.5という出力を行うようになる(ナッシュ均衡)
を迎える


ほんの少しだけ損失関数にも触れておくが、GANの学習は大変に厄介な問題が多く、
その一つに損失関数の問題がある
勾配が非常に小さい値となるので初期の学習が進みにくい(経験的なテクニックの紹介が元論文にある。実験項を参照。)
そのため、勾配を急にする損失関数が提案されているが、理論的に収束が保証されなくなる欠点がある
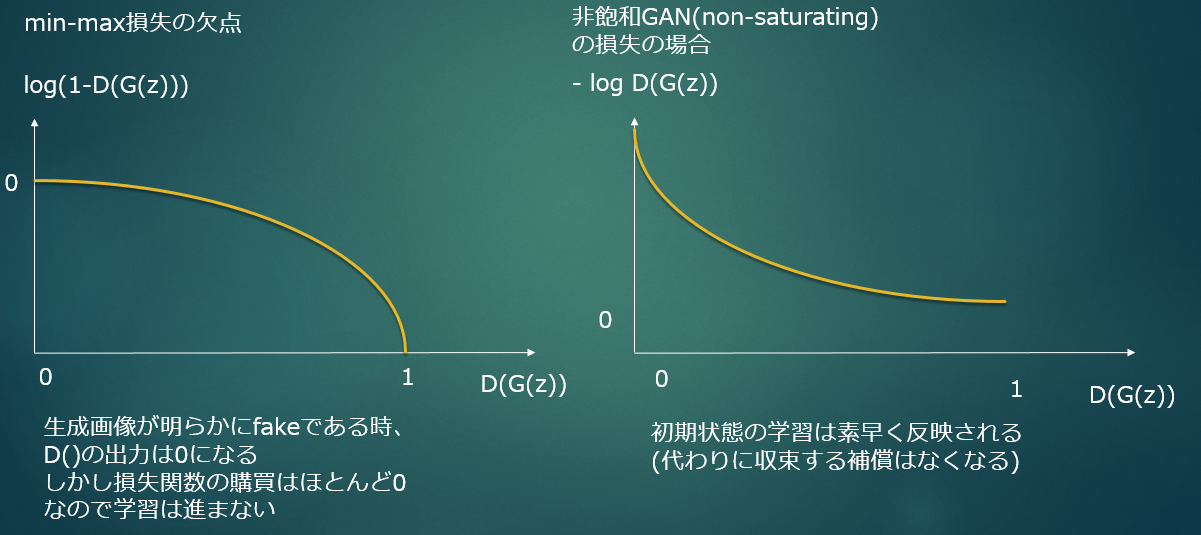
損失関数の改善の試みは今も研究されているが、W-GAN:Improved Training of Wasserstein GANs,2017が有名な解決策
具体的なGANのネットワーク構造
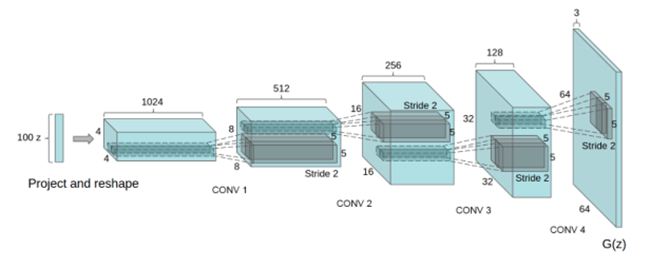
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2016では具体的なGANの構造が試されている。
DCGANと略されるこの方法では、up-convの構造によってノイズを画像の次元まで拡大していくジェネレータ構造を作っている
この構造はSTRIVING FORSIMPLICITY:THEALLCONVOLUTIONALNET, 2015, springbergを参考にしているらしい。
VAEと同じく、正規分布から生成することができる
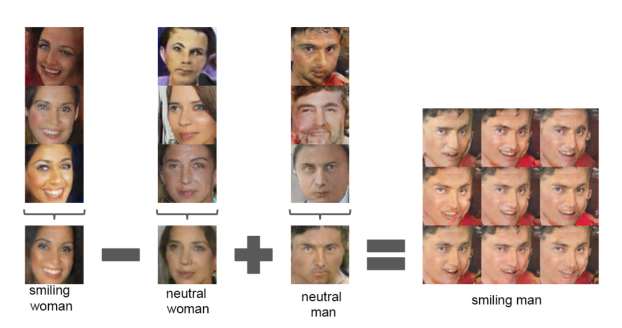
VAEでも特徴量空間は画像の特徴的な傾向を学習していたが、GANでも同様のことが起こっている
GANでも入力が複数軸の正規乱数の場合、「笑顔-真顔」を学習するベクトルや「男性-女性」を学習するベクトルが出来上がる
条件付きGAN(conditional-GAN:c-GAN)
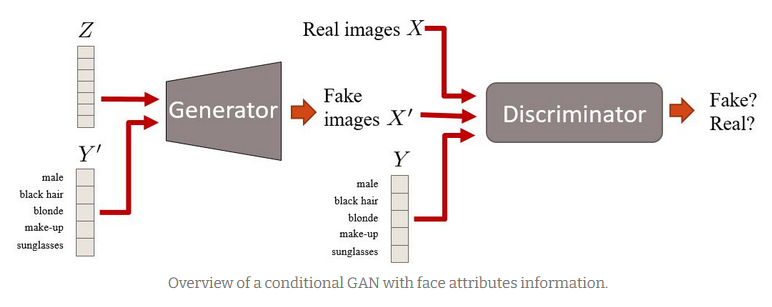
Conditional Generative Adversarial Nets,2014,M.Mirza
画像生成と同時に教師ベクトルも学習することで、教師ベクトルを入力として任意の画像を生成するモデルが出来上がる
今までのGANでは0~9の手書き文字を学習させると0~9のどれかを吐き出すようなネットワークしか作れなかった
これを発展させると分類器や異常検知にもなる(ACGAN等)
ようやく本題:GANでの異常検知
ここから本題であるGANでの異常検知の紹介をしていく
anoGAN
GANを異常検知に使った初めての試みらしい
Unsupervised Anomaly Detection with Generative Adversarial Networks to Guide Marker Discovery, 2017
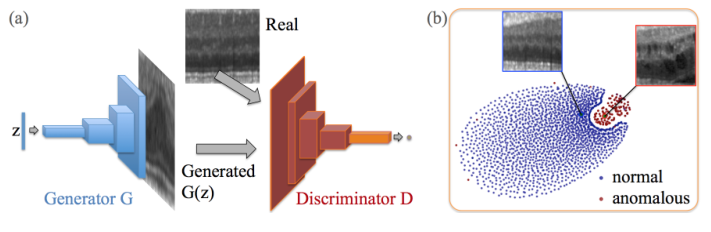
異常検知というタスク全般に言えることだが、
異常検知というのは検知したい異常というのが非常に少ない
なぜならば、人手で異常をはじく仕組みを作っていたり、不良が出ないように制御しているから
より分かりやすく説明するならば、車の異常検知をしたくとも、部品の寿命分析がしたくとも、
車検が間に入って壊れる前に交換されてしまうのでデータが無いのである
しかし正常な部品のデータは沢山取得できる。
そこで正常なデータの分布を学習させて、正常なデータ「以外」を見つける「1クラスのクラスタリング」を行うのが異常検知の一つの方法(1-class-SVMとか,EM-algolithmの応用とか)
正常画像だけを学習に使ったGANを用意する。
ディスクリミネータはジェネレータの「本物っぽい画像(本物か少し怪しい画像)」と「本物画像」を判定するようになっている
もし異常な画像が来た場合には、容易に判断できるだろう
Discrimination Loss:ディスクリミネータを判定器として使う
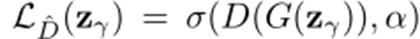
さらにImproved Techniques for Training GANsから、ディスクリミネータの最終判断に使っている特徴量が重要な情報(画像の特徴量空間)を握っている、という事でGANによる画像生成の精度が上がることが分かっていた
画像生成の精度が上がるのであれば、より正常画像らしさも学習できるだろう
ということで、この特徴量を使うことにした。
(上記ディスクリミネータの判定でなく、特徴量の差分を判定の基準とする)
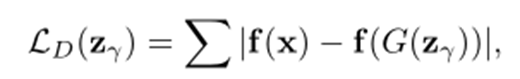
ここでZγというのは乱数Zの一層後に入っている調整層を特徴量とみなしている。
正常画像は図中のディスクリミネータのオレンジ色の棒(特徴量)に圧縮されたとき、b図の青色の空間にマッピングされているはず
しかし、異常画像をディスクリミネータに通した場合には青色でない空間(赤色の空間)にマッピングされると考えられる
(ディスクリミネータの特徴量変換が既に1-classのクラスタリングになっていると考える)
Residual Loss:再構成できなかった差分
500回ほどジェネレータ(の手前の入力ノイズ)を最適化させても真似できなかったら異常画像なのでしょう
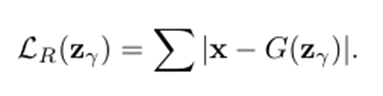
あとはこれらの損失に重みをつける(再構成loss=0.9,特徴量loss=0.1)
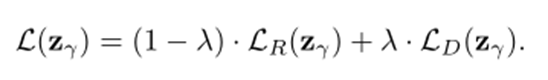
そしてこの差分を異常度と考える
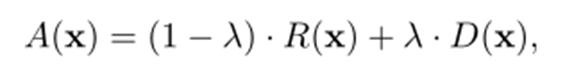
高速化anogan:Efficient anogan
これをさらに高速化したものがEfficient GAN-Based Anomaly Detection
500回も訓練していると時間が遅いので、この訓練課程もネットワークで置き換えたもの
発想はBiGANから得ている
ganomaly
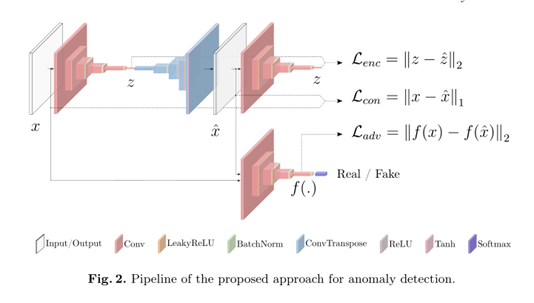
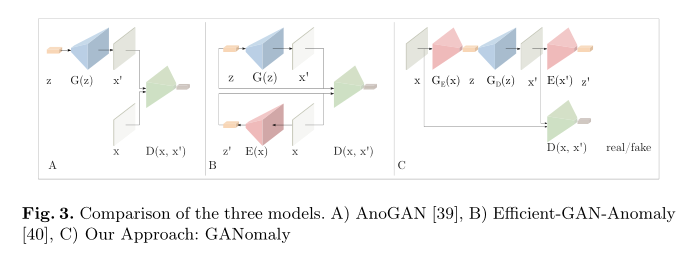
GANomaly: Semi-Supervised Anomaly Detection via Adversarial TrainingはanoGANに加えて特徴量として次元圧縮によって作り出した特徴量を追加している
- 構造
- すべて正常品の学習とする
- 画像Xをオートエンコーダーを通して再構成Xhatにする
- Zが特徴量として得られる
- 再構成Xhatを再度構造が同じでパラメタが異なるエンコーダーに通し、二つ目のZhatを作る
- オートエンコーダーは学習した画像ならば再構築できるはずなので特徴量Zの差は小さくなる
- 同時に再構築画像の差分(オートエンコーダーの入出力差)
- 同時にanoGANのディスクリミネータの特徴量の差
これらを比較する
オートエンコーダーと、再構築画像をエンコーダーに通した後の特徴量の差:encoder loss
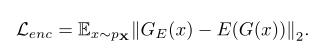
オートエンコーダーの再構築差:contextural loss
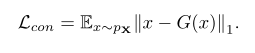
特徴量の差:adversarial loss
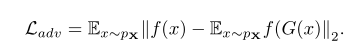
三つの差に重みを付け学習を進める
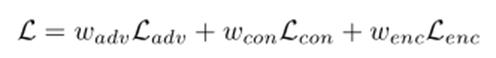
異常度はエンコーダーの特徴量の差だけを見る
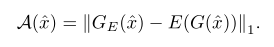
何とも有用そうな特徴全部盛り!な内容
anogan,efficient anogan,ganomalyの構造の違い
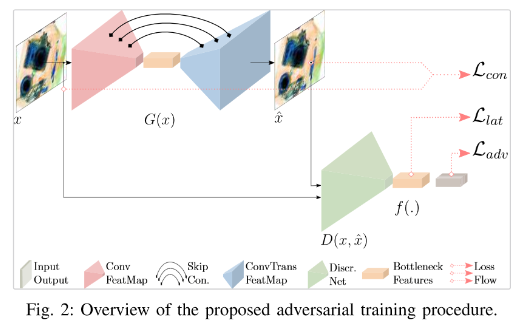
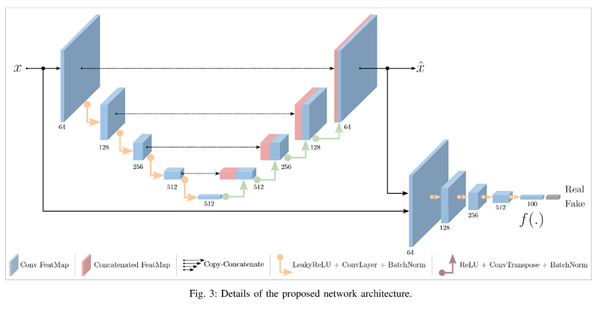
skip-ganomaly
skip構造がGANによる画像生成の精度を上げたので、異常検知の手法でもskip構造を使ってみよう
という話
Skip-GANomaly: Skip Connected and Adversarially Trained Encoder-Decoder Anomaly Detection
余談:情報が少なく、自分の解釈が正しいか不明だが一部で話題になっていたので
論文中の流れを意訳しながら記述していく
Modeling the Distribution of Normal Data in Pre-Trained Deep Features for Anomaly Detection
・分野背景
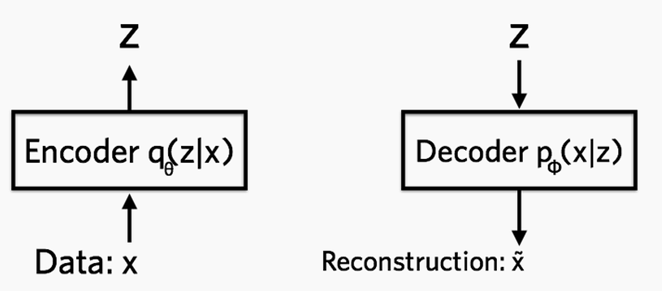
オートエンコーダーのように、正常画像だけを再構築するような、唯一の対象を生成するモデルは異常検知において様々な活用例がみられている。
k-NNや1-class-SVMによるアプローチも検討されている。
・深層モデルによる特徴量の抽出
AlexNetやVGGを使い、画像の特徴量を抽出する方法が見られている。
特徴を多変量正規分布として収束させることに成功し、マハラノビス距離をもって異常度の数値化を行っている。
しかし、この試みは小規模なデータセットだけでしか行われていない。
ここで刺している論文たちは以下3報
Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity
Uninformed Students: Student–Teacher Anomaly Detectionwith Discriminative Latent Embeddings
Deep-Anomaly: Fully Convolutional Neural Network for Fast Anomaly Detection in Crowded Scenes
巨大なデータセットであるImageNetを使って学習を行ったVGGが画像の特徴をよく抽出すると考え、
VGGの特徴量を元に1-class-SVMを行った報告もあり、このVGGをX線画像の異常検知のタスクに転用した時に効果を出したことがわかっている。
Transfer Representation-Learning for Anomaly Detection
手元にあるデータの分布を多変量正規分布へと当てはめる研究は異常検知には使われていなかったが知られており、
分布外データセット(訓練にないデータ)か、訓練データセットかを判別するのに役立っていた。
ここでは、テストデータセットの分布と、訓練データセットの分布のマハラノビス距離が最大になるように学習させることで、
訓練データセットに特化した判別器を作るという狙いがある。
データを正規分布に従うように学習させる
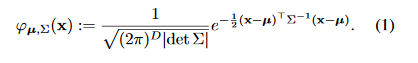
標本分散、標本平均をつかうことになる
(ここに関するテクニックも論文に書いてあったが理解できなかったので飛ばします)
ImageNetを訓練したEfficientNetによって画像特徴量を抽出する。(ResNetも検証対象にしている様子)
クラス出力の手前は、クラス出力に特化した特徴量となっているため、それよりも浅い層の出力を特徴として使う。
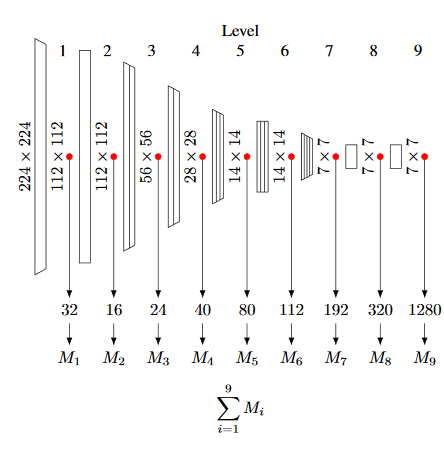
各抽出された特徴量を正規分布に当てはめ、このマハラノビス距離を元に異常を判断する
図は EfficientNet-B0 の構造
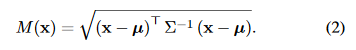
感想:
style変換の論文でもVGGの層出力を特徴量としていたが、分類器を特徴量合成器とみなして使う手法が増えているのか?
分類器としてだけでなく、画像から特徴量を抽出(合成)するための使い道なんて想像してなかった。
標本平均と標本分散の項から飛ばしたけども、バッチの平均と分散を元に正規分布にみなしているのかは読んでみたいと思う。
それよりも前提にある3報から入ったほうが理解しやすそうなのでそちらからになりそう。
ganでの異常検知実装コード
実装コードまとめました
autoencoderはkeras blog
anoganはtkwoo氏とyjucho1氏を参考にしました
ganomalyはmediumで実行している人:Abby Yeh氏のコードを参考にしました
以上
生成モデルによる異常検知の論文を調べたのでまとめた
異常を検知するための1-classを学習させるのも難しく、
学習回数(オーバー,アンダーフィット)、検証セットが無い(精度が確かめられない-人手でアノテーションする)などの問題もあるし、
そもそもGAN自体が再構築可能と言い切れない問題もあるため
なかなか難しい
というか異常検知のタスク自体が難しい
(今後に期待)