Machine&Deep Learning論文紹介 Advent Calendar 2020の一日目
スタイル変換に興味があり、まとめたので紹介
スタイル変換とは
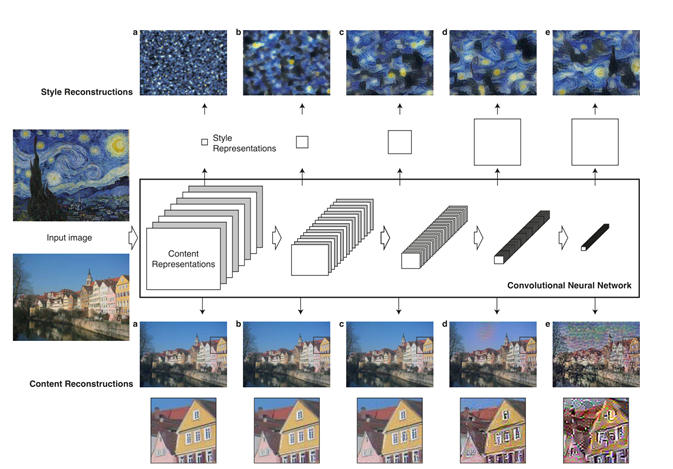
そもそも「スタイル変換」とは以下のような技術です

これはゴッホの「星月夜」で、鮮やかな青色と枯山水のような筆の流れがスタイル変換の分かりやすい例になっています
このように一方の画像の「画風」をもう一方に移すことで、絵画の作者が描いたような画像を作り出す事ができます
この技術的な背景を紹介していきます
むかしのスタイル変換を簡単に

「image quilting」という主張で名付けられた技術がありました
これは「小さなテクスチャ画像」を横に並べ、そのつなぎ目を緩やかに繋ぐ技術です
しかしこれではあまりに適応できる範囲が狭い
小さいテクスチャの範囲だけでしか移せないし、テクスチャに指定した範囲でしか変換できない
どうしても思い通りに柔軟にスタイル変換を行いたければ人手がかかってしまう
深層学習を使ったスタイル変換

gatys氏が畳み込みネットワークを利用したスタイル変換が発表されました
このお話はyoutubeに非常に分かりやすい説明があったので紹介しておきます
私の記事よりも分かりやすいと思います
その概要は畳み込みネットワークVGGの畳み込み層の特徴マップを可視化する技術がありまして、その技術から
・畳み込みの深い層(出力側)は画像の全体を大雑把にとらえているらしい
・浅い層(入力側)は単純な線、曲線の枠だけを捉えているらしい
という事がわかってきました

今まで画像の特徴(線や曲線)を抽出するには既知の特徴を取り出すフィルタを組み合わせていましたが、これでは自然画像に対応できませんでした。
「VGGが精度良く特徴を取り出してくれるフィルタを学習していたので、これを利用してスタイルを学習しよう」という話です
ネットワークも特にVGG19が良いらしく、他のネットワークではスタイルが正しく変換できなかったそうです。
構造は以下のようになっています
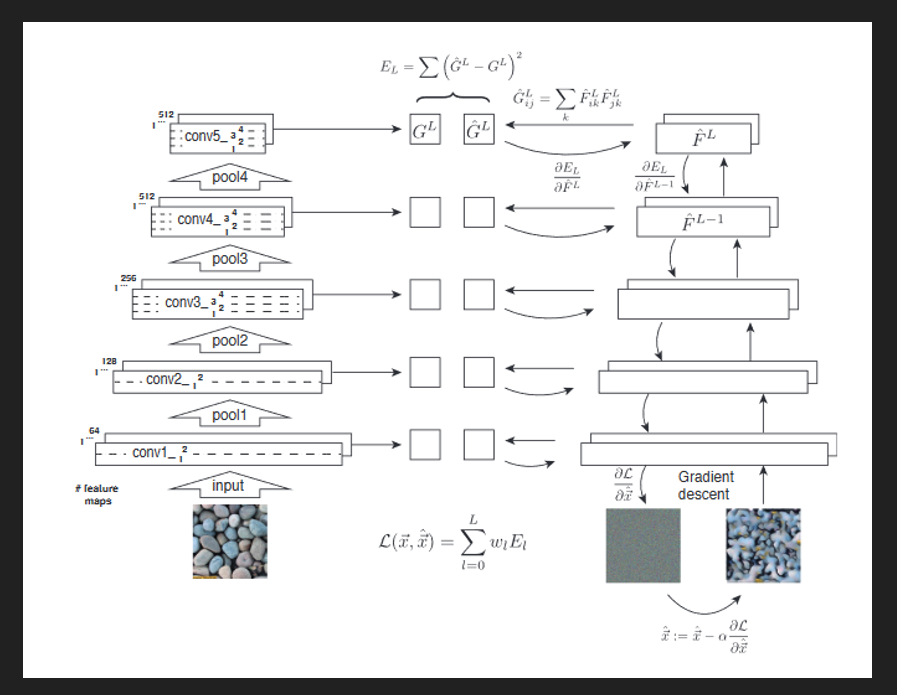
シンプルに説明しますと、
・左側がテクスチャ画像です
・テクスチャ画像を重み固定のVGGに通した時の各畳み込み層の出力を保存しておきます
・層の出力をグラム行列とします
・右側がホワイトノイズ画像です
・ノイズをVGGに通し、VGGの各層の出力を保存しグラム行列にします
・左側のグラム行列に右側のグラム行列が近くなるように最適化します
左側のテクスチャ画像からテクスチャの特徴を取得することができるので、
この特徴の相関を一致させよう
という話です
完全に一致させてしまうと元のテクスチャ画像に非常に似た出力だけを得ることになってしまい、
「パターンという特徴」を学習するには過剰になってしまうので
**相関(グラム行列)**という特徴量に変換して最適化の対象にしています
[なぜグラム行列にするんだ?って疑問の人はこちらが参考になるかと](
https://towardsdatascience.com/neural-networks-intuitions-2-dot-product-gram-matrix-and-neural-style-transfer-5d39653e7916
)
この論文もgatys氏が論文を執筆する際の背景にしたと言っていたので参考になるかと

もう少し論文の中身を見ていきます

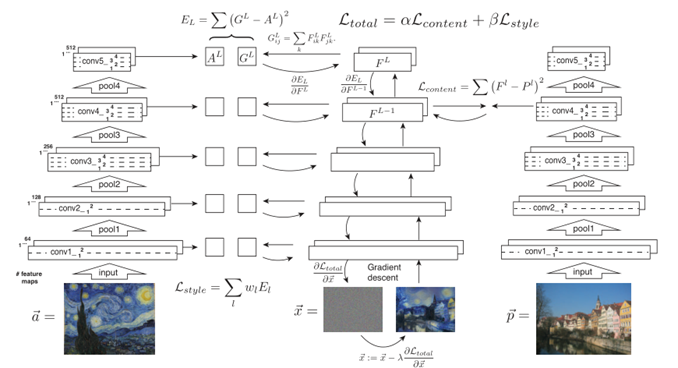
これがグラム行列Gを表していまして、畳み込み層から出力される行列Fのグラム行列(内積,分散共分散行列のようなもの)を計算します
テクスチャ側、ノイズ側で得られたGを二乗誤差の最小化によって近づけます
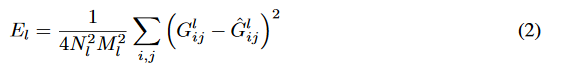
各層でこの誤差を求め、層ごとに重みを付けて何層目を重視するかをコントロールできるようにします

そしてこの損失(誤差)は解析的に求められることを示すことができるので、
微分可能という事は最小二乗法,誤差逆伝播が使えるわけで、
ノイズ画像側をテクスチャ側のグラム行列に近くなるような画像に作り直すフィードバックが走らせられるわけです
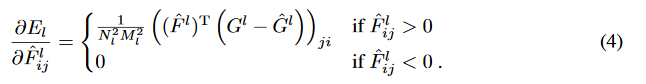
論文ではL-BFGSを最適化手法に採用していますが、これは高次元の最適化に向いている手法と考えたから採用したらしい
そして必要な計算はVGGの出力とその最適化なので、普通のGPU環境があれば実行可能である
この方法によってノイズ画像は徐々にテクスチャ画像の特徴を捉え自然なテクスチャを生成します
そしてネットワークが畳み込みであるので、ノイズ画像の再構成部分を触ってやれば画像サイズを変更することもできるようになります

上図はどの層の出力までを使うかによって結果が異なったことを報告しています
一番右の列を見てみます
pool4(3層目のブロック)まで使うことで非常に元画像全体を参考にしたようなテクスチャ画像になります
一番下の行の画像はグラム行列を使わなかった場合(portilla氏の論文)の結果で、特徴量というよりも全体を近似してしまうような画像になります
テクスチャ変換は局所的な情報(色パターンなど)を残しながら、全体的な情報(石の大きさや位置など)は無視してほしい
という気持ちから特徴マップを取り出してきましたが、その特徴マップのためのパラメタはかなりの量になりますので計算負荷も大きい
しかし、下図のようにパラメタを主成分分析で減らしてやった場合(一行目)でも十分に求めるテクスチャ画像を得られることが実験的に分かっっています

どこまで落としてもテクスチャ画像と呼べる情報が残るのかは別の研究対象とします
もう一つ実験的にわかっているのは、レンガ壁のような規則的な構造の場合にはパラメタを減らすと失敗しやすいという事です。
最初に少し紹介しましたがVGG以外のネットワーク、ここではalex-netを使った場合の出力も紹介されています

二行目がalex-netで実行した結果ですが、画像の表面に小さな網目構造が浮かんでいてあまりいい結果にはなりませんでした。
三行目はVGGの重みをランダムにしたネットワークを使った場合です。この場合はノイズしか出力しなくなります。
最後にもう少しだけグラム行列について触れます
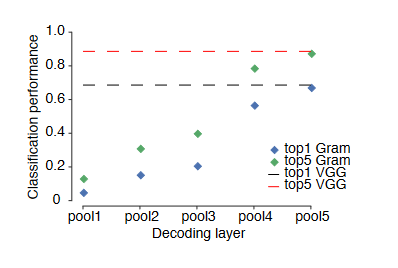
グラム行列がどれだけ画像の特徴量として有用なのかを実験によって比較すると
元の層の出力と比例するようにグラム行列でも分類の特徴量として有用であるような結果が出ているので、
グラム行列も十分元画像の性質を持っていることが予想できる
構造を残しつつスタイルだけ変換する


片方はプレプリントです
またもgatys氏の研究紹介です
簡単に全体を説明すると
テクスチャの取得(近似させていく話)は前回の論文と同じ
同時に画像の構造(家や木や川)を残したまま、上からテクスチャを乗せたい
そのためにノイズ画像を、「構造の保存+テクスチャ」の画像へと最適化していく方法
以降から「テクスチャ」と「スタイル」という単語が入り混じりますが、
テクスチャはスタイルを表す最小の単位画像のような物と考えてください
構造はこのようになっており、左側のネットワークは先に紹介した論文と同じ構造です
テクスチャを取り出したいスタイル画像(style)からスタイルの特徴をVGGでとりだします
右側が新しい考えで、VGGネットワークに構造画像(content)を通した結果のうち、
深い層の見ている全体的な構造情報を二乗誤差によって最適化する
という考えです

さらに単純に話すと
上記matthew氏の論文で畳み込みネットワークが構造を深い層で学習していることが分かったため、
構造もノイズ画像にテクスチャとともに構築させたらうまくいくのでは?
という内容です
こちらが分かりやすいかと。
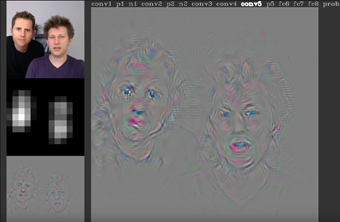

yosinski氏のCNNが構造を出力してくれる例をyoutubeで見てみる
コンテンツの損失はグラム行列に変換しません
そのままの構造を正しく保持したいからです
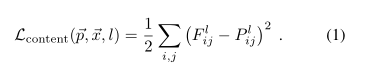
この損失も解析的に求まるため、誤差逆伝播でノイズ画像へフィードバックすることが可能です
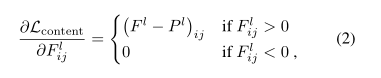
復習になるのでスタイルの損失については画像だけ載せておきます

こうして計算されたstyleとcontentの情報に重みを付けてノイズ画像へフィードバックします
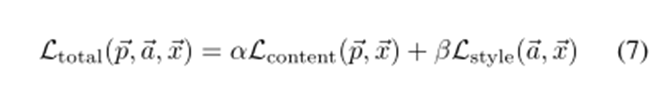
当然重みの大きさによってスタイルだけが残るか、構造だけが残るかという話にもなります。
下図の数値は重みのαとβの割合であり、左上はαの割合が小さく、右下はαの割合がβに対して大きい場合です。
確かに左上は構造情報がほとんど残っておらず、右下は川などがそのまま残っていることが確認できます

前のスタイルに関する論文でも何層目までを使うか、という話がありましたがコンテンツ画像も実験した結果が紹介されています

コンテンツ画像はpoolingによって深い層になるほど輪郭が曖昧になっていきます。
浅い層ほど構造を元画像のように明確にのこしているので、二行目に見られるような二層目のコンテンツ情報を使った場合には
元画像の上に色を付けたような画像になります。
深い層になれば元画像はより抽象的になり歪みも生じてきます。
どんな画像を生成したいかにもよりますが、元画像の構造が強く残りすぎるのは、コンテンツ画像に重みを大きくつけている場合と似た結果になってしまう傾向があります。
学習のスタート画像に関する実験も載っていました
実験の内容は、今までノイズ画像を元にVGGの出力を最適化してきたが
コンテンツ画像(A)もしくはスタイル画像(B)をノイズ画像の代わりに入れて最適化したほうが、
自然なスタイル変換画像が得られるのでは?という考えです

下側四つの画像(C)は異なるノイズを入力にした場合です
結果としてどれも似たような結果になりノイズから初めても問題は無さそう
ノイズの場合出発点が異なる影響で生成画像も異なる結果となるが、
元画像が固定されているA,Bの場合は再度走らせた場合にも同じ変換結果に収束することがわかっています
この研究の問題点は、コンテンツ画像が一枚一枚入力のたびに細かいピクセル情報を最適化する必要があり非常に生成が遅いことです。
生成が遅いという事は、スマホアプリに組み込んだりしたい場合、写真を撮った後にユーザーが10分とか変換のために待つ必要が出てきてしまうわけです。
最適化をより高速にしたい

変換をまたず、リアルタイムで変換するための方法です
構造全体を俯瞰してみます
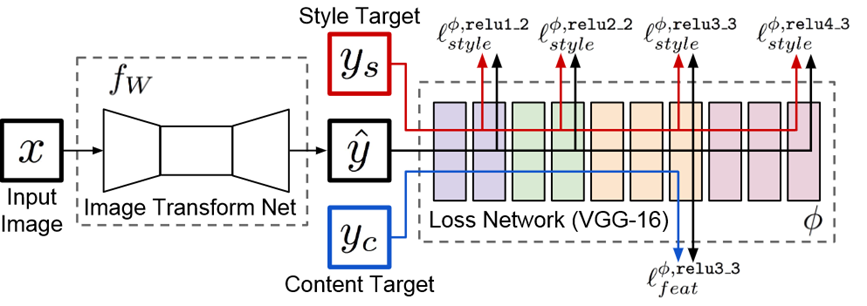
右側 loss networkは今までの研究と変わりはありません
入力yに対してycからcontentを、ysからstyleを取り出し、最適化して近づけます
この最適化の行為が非常に遅いので、その手前に生成ネットワークを置きました
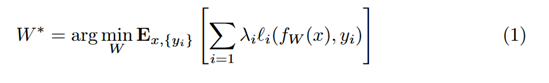
生成ネットワークは元画像とスタイル変換後画像を比較し、その差分を上記式で最小化します
スタイル変換画像を「生成」することが目的です
一度ネットワークを作っておけばあとは学習を必要とせず、順伝播するだけでスタイル変換画像が得られるため、
スマホアプリなどでも使えるようになります
多少式の記述方法が異なりますが、以下でも再度説明します
Cがチャネル、H,Wは縦横サイズです
コンテンツの情報は
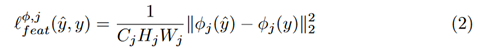
スタイルの情報は
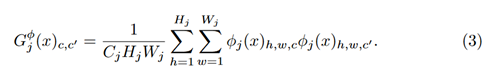
でグラム行列に直してから
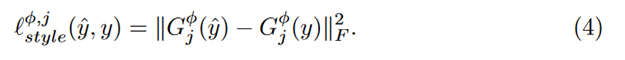
でスタイルの損失とします。
余談ですが、スタイル画像のグラム行列は計算効率を上げるため以下の式に整えてから計算しているようです
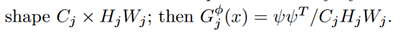
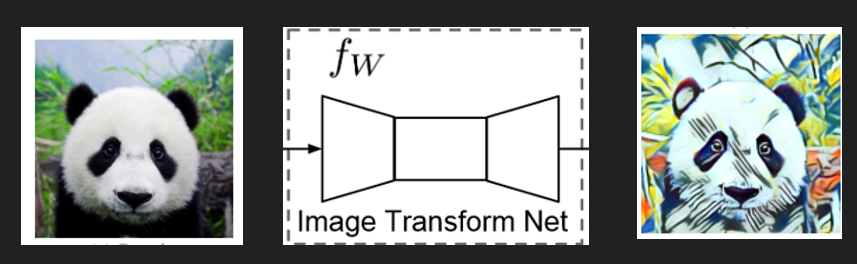
いくつかの画像をスタイル変換画像に変換できるような生成ネットワークができたらこれをloss networkと切り離してスマホアプリに組み込むわけですが、
スタイル変換の生成のために色々な画像を使って学習させると失敗することが分かっており、早期停止を使ったり学習画像を減らす必要があります
順伝播するだけなので、変換速度は数百倍早くなっています
gatysらの出力時間に対してoursの速度
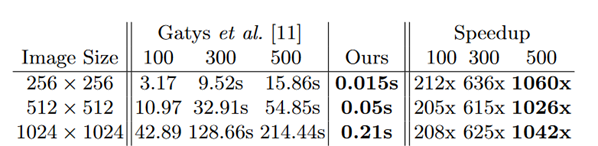
その精度もgatysらと比べて特に問題ないようなスタイル変換結果が得られる

より精度良く、早くスタイル変換を

今までからの変更点は
「インスタンス正規化」と「ジュールズサンプリング」の発想
らしいのですが
ここあたりから理解がおいついていないので、以下参考程度に読んでください。
そもそもGANやVAEと同じく、スタイル変換のアプローチはノイズからの画像生成を目指しています

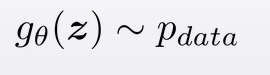
・手元の画像は神のみぞ知る確率分布から採取したデータである
・つまり手書き画像だったならば、再度手書きをしたら生成することができる
・この手書きによって得られるピクセルの配列パターンである母集団の分布は謎であるので
・正規乱数(ホワイトノイズ)を仮定してネットワークを使って生成しよう
という考えが背景にあります
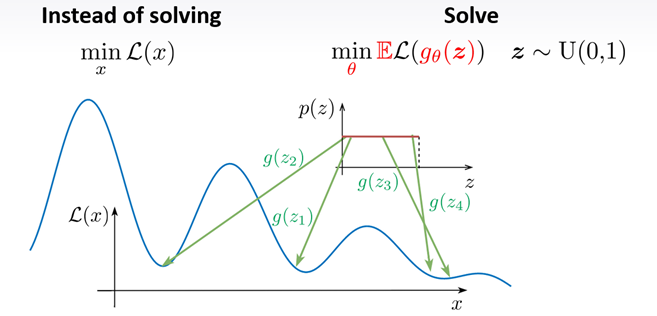
正規乱数によるサンプリングもありますが、この手法では一様分布からのサンプリングを行っています
・そもそも非凸な目的関数なので収束は難しい
・一様なノイズから一番よさそうなシードを見つけることで画像生成にアプローチしている
テクスチャだけを作りたいならば今まで通り一様乱数からテクスチャ画像Xを生成するようなネットワーク(ジェネレータ)を訓練する
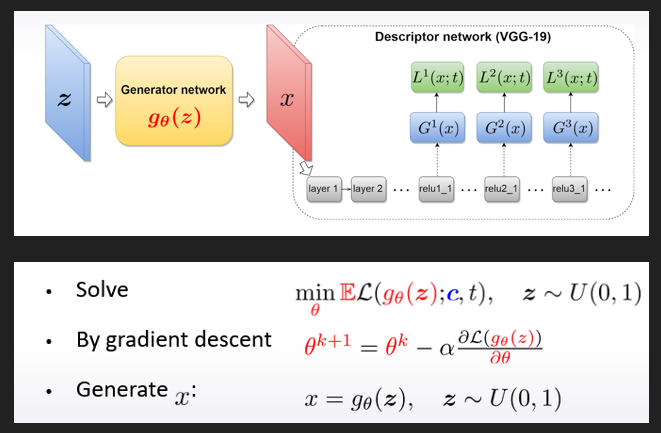
しかしコンテンツ画像も考慮したい場合にはジェネレータにコンテンツ元画像も入力することで、X側に元画像情報が残るように最適化を行わせる
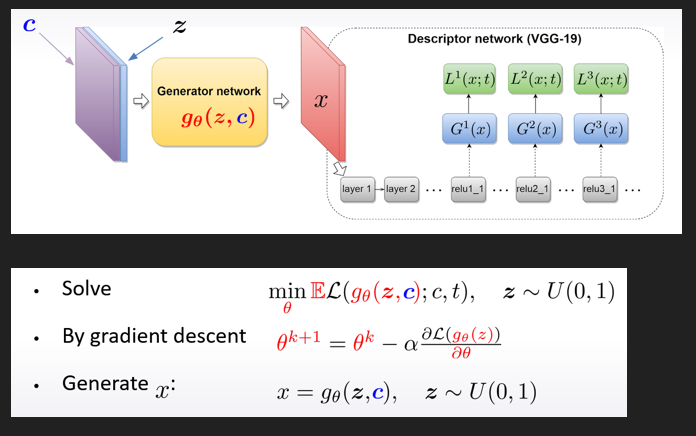
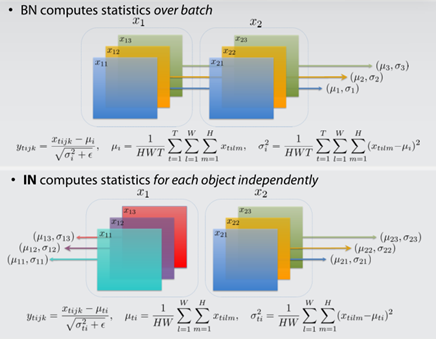
今回の研究では「インスタンス正規化」が構造に入ってきます
今までのバッチ正規化ではネットワークが画像のバッチ(特徴マップ)ごとに平均や分散を計算しておく必要がありました
正規化のパラメタも固定することで計算効率を上げ、均一な出力を得ることができるようになった

どのように生成器を最適化していくのかについては変分法などが登場してくるのですが

これを説明できるレベルにはまだ至っていないのでこの辺でまとめを締めさせていただきます
残っている周辺論文

実装コード紹介
tensor flowからNeural Style Transfer with tf.kerasとしてコードが提供されています
以上
スタイル変換の技術を調べたのでまとめ、共有しました
たのしい