コンペ→Toxic Comment Classification Challenge
NBSVMを選択する際にJeremy Howardさんが参考にした論文
Baselines and Bigrams: Simple, Good Sentiment and Topic Classification
今回の紹介カーネル
Jeremy Howardさんのカーネルを紹介しつつ写経勉強する。
そのほか翻訳時に参照したサイト
(http://ailaby.com/tfidf/)
(https://www.pytry3g.com/entry/2018/03/21/181514)
このカーネルでは、攻撃的なコメントをNBSVM(Naive Bayes - Support Vector Machine)を使用して分類する方法を書いている。
NBSVMはsidawangとchris manningがこの論文で紹介している。
このカーネルでは、sklearnのロジスティック回帰を使用する。
SVMではないが、実際のところこの二つはそんなに変わりはない。
import pandas as pd, numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
train = pd.read_csv('C:/train.csv')
test = pd.read_csv('C:/test.csv')
subm = pd.read_csv('C:/sample_submission.csv')
# ## Looking at the data
# The training data contains a row per comment, with an id, the text of the comment, and 6 different labels that we'll try to predict.
train.head()

(エクセルをコピペすると画像でupできるのしらなかった・・・)
攻撃性の判断として、変数は
・攻撃的
・多少攻撃的
・わいせつ
・威嚇
・侮辱
・個人的否定?個性の否定、差別?
が項目として設定されており、該当するものに1が入力されている。
testデータにはIDとテキストしか入っていない。
lens = train.comment_text.str.len()
lens.mean(), lens.std(), lens.max()
(394.0732213246768, 590.7202819048923, 5000)
コメントの長さは様々です
lens.hist()
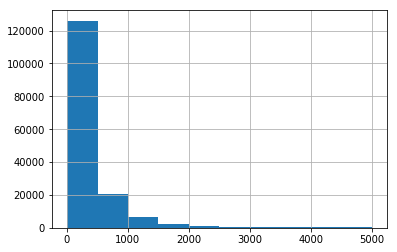
コメントの文字数の分布
長文はめずらしい。
予測するためにはまず、ラベルを作成します。
ラベルがついていないこと(攻撃的コメントではない)を判断できる「none」というラベルも新しく追加します。
label_cols = ['toxic', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
train['none'] = 1-train[label_cols].max(axis=1)
train.describe()
toxic severe_toxic obscene threat insult identity_hate none
count 159571.000000 159571.000000 159571.000000 159571.000000 159571.000000 159571.000000 159571.000000
mean 0.095844 0.009996 0.052948 0.002996 0.049364 0.008805 0.898321
std 0.294379 0.099477 0.223931 0.054650 0.216627 0.093420 0.302226
min 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000
25% 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
50% 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
75% 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 1.000000
max 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000 1.000000
0,1で記入されているものに1-[data]をしたら、
0は1になり、1は0になる。
そんな処理をしたデータの1の数をカウントしたら、ラベルがついていないコメントが判別(カウント)できる。
len(train),len(test)
(159571, 153164)
いくつか取り除くべき空のコメントがあるようです
sklearnにおこられないためにも。
COMMENT = 'comment_text'
train[COMMENT].fillna("unknown", inplace=True)
test[COMMENT].fillna("unknown", inplace=True)
空のセルにはunknownを代入します。
モデル構築
bag of words
自然言語処理で文書をベクトルで表現した単語集のこと。
単語に分解してone hot encorderなどで1,0で表現させたりする。
まず文書を単語に分解して行列で表現しましょう。
論文ではngramsが推奨されているのでngramsをつかってみます
import re, string
re_tok = re.compile(f'([{string.punctuation}“”¨«»®´·º½¾¿¡§£₤‘’])')
def tokenize(s): return re_tok.sub(r' \1 ', s).split()
気になったので確認
ちなみにtokenizeを使っているところを確認すると、このように単語を分離しています。
tokenize(test[COMMENT][0])
['Yo',
'bitch',
'Ja',
'Rule',
'is',
'more',
'succesful',
'then',
'you',
"'",
'll',
・・・・略
'you',
'to',
'kiss',
'my',
'ass',
'you',
'guys',
・・・・略
'dont',
'diss',
'that',
'shit',
'on',
'him']
なかなか下品な言葉を言っています。
testの0番目を分類して攻撃的の項目に1が付きそうです。
話をもどして
TF-IDFを使用すると、論文中のようにバイナリ化するよりも良いけっかが得られます。
良い結果といっても0.55が0.59になる程度のものですが。
n = train.shape[0]
vec = TfidfVectorizer(ngram_range=(1,2), tokenizer=tokenize,
min_df=3, max_df=0.9, strip_accents='unicode', use_idf=1,
smooth_idf=1, sublinear_tf=1 )
trn_term_doc = vec.fit_transform(train[COMMENT])
test_term_doc = vec.transform(test[COMMENT])
スパースな行列をつくりました。
このあたりがSVMのようにスパース化させて分類している過程か?
trn_term_doc, test_term_doc
(<159571x426005 sparse matrix of type '<class 'numpy.float64'>'
with 17775104 stored elements in Compressed Sparse Row format>,
<153164x426005 sparse matrix of type '<class 'numpy.float64'>'
with 14765755 stored elements in Compressed Sparse Row format>)
def pr(y_i, y):
p = x[y==y_i].sum(0)
return (p+1) / ((y==y_i).sum()+1)
ベイズ式
x = trn_term_doc
test_x = test_term_doc
モデルをあてはめてみます
def get_mdl(y):
y = y.values
r = np.log(pr(1,y) / pr(0,y))
m = LogisticRegression(C=4, dual=True)
x_nb = x.multiply(r)
return m.fit(x_nb, y), r
logの中身は「yが1であるベイズ的な確率」/「0である確率」を計算している。っぽい
(その値をロジスティク回帰している。nb-svmならここがLRでなくSVMをつかうのか?)
攻撃的なコメントの判別
preds = np.zeros((len(test), len(label_cols)))
for i, j in enumerate(label_cols):
print('fit', j)
m,r = get_mdl(train[j])
preds[:,i] = m.predict_proba(test_x.multiply(r))[:,1]
test_xに対して定義したget_mdlを適応させて、文章の含んでいる攻撃性を推定する。
submid = pd.DataFrame({'id': subm["id"]})
submission = pd.concat([submid, pd.DataFrame(preds, columns = label_cols)], axis=1)
submission.to_csv('submission.csv', index=False)
適応した結果をコンペに投稿できるようにcsvに吐く。
以上
実際と予測を見比べてみると
submission.head()
id toxic severe_toxic obscene threat insult identity_hate
0 00001cee341fdb12 0.999988 0.106264 0.999987 0.002369 0.962578 0.094957
攻撃性が判定されています。
ちなみにこのコメントは先ほど単語分解の時に見た口の悪いコメントの判定です。
id comment_text
0 00001cee341fdb12 Yo bitch Ja Rule is more succesful then you'll...
SVMは言語の分類に向いているみたいな話をちょろちょろ見かけましたが、こんな感じで文字を数値化して分類しているんですね。
言語処理はまだまだ勉強が必要です。