分散分析のF値についての疑問
導入は端折る。
分散分析は群間で差があるかを検定している。
群間の差はサンプルサイズによって変化するし、
分散分析で使用する統計量はF分布に従う。
ホンマか??
正規分布やカイ二乗分布は理解しやすい。
F分布ってあんま使わんし、理解していない部分が多い。
なのでホントにF分布に従うのか試してみる。
n <- 10000
m <- 100
s <- 30
hist(rnorm(n,m,s))

まず同じ正規分布(平均100,標準偏差30)の母集団から得られた、サンプルサイズ5のデータ間の統計量はF分布に近似するのか?
例えばサイズ5のサンプルをランダムで選び、4群とってくるとこんな図ができるはず。

もともとの母集団を後ろに書き込むと
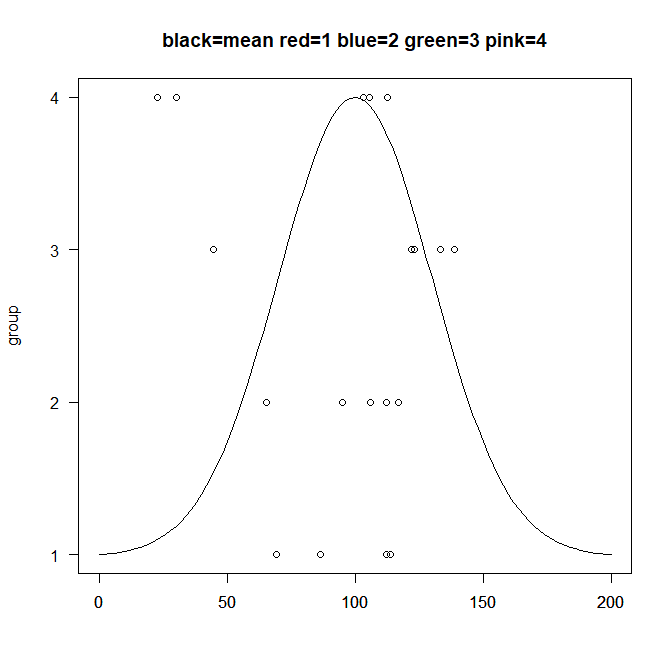
たしかにそんな母集団から抽出されたデータっぽくは見える。
各郡の平均値を引いてやる
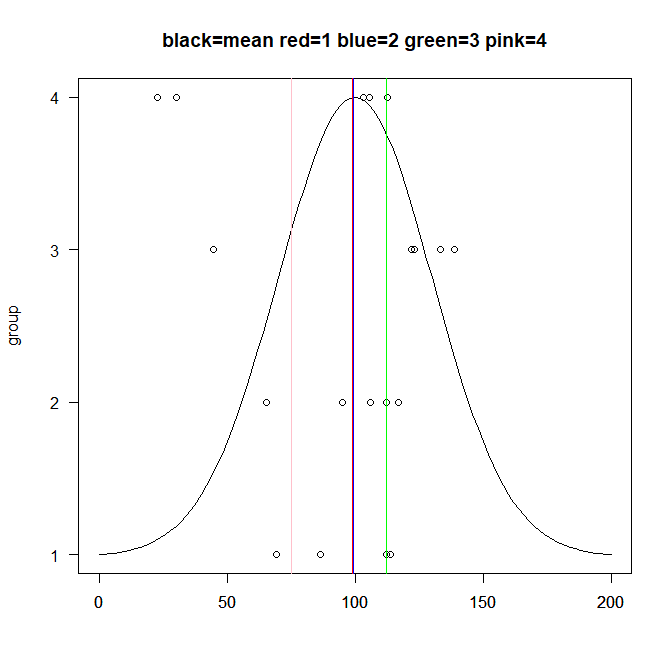
pinkの群だけが多少中心から離れている気がするが、同じ母集団から抽出されたデータのためそんなに離れることもないだろう。
複数回試行を繰り返すと今回のピンク以上に離れた標本平均が得られることもある。
そんな時はF分布の0から離れた部分にF値が来ることだろう。
ということで10万回くらい試行を繰り返してもらって、統計量FがF分布に従うのかを確認する。
いけ!ポンコツコード!君に決めた!
norm_data <- rnorm(n,m,s)
bind <- NULL
for(i in 1:100000){
set_number <- sample(n)
group_1 <- norm_data[set_number[1:5]]
group_2 <- norm_data[set_number[11:15]]
group_3 <- norm_data[set_number[21:25]]
group_4 <- norm_data[set_number[31:35]]
y <- c(group_1,group_2,group_3,group_4)
x <- c(rep(1,length(group_1)),rep(2,length(group_2)),
rep(3,length(group_3)),rep(4,length(group_4)))
# 上の母集団と4群を書くためのコード
# curve(dnorm(x,m,s),0,200,yaxt="n",ylab="",xlab="")
# par(new=T)
# plot(y,x,ylab="group",yaxt="n",xlab="",main="black=mean red=1 blue=2 green=3 pink=4",xlim=c(0,200))
# axis(2,at=c(1,2,3,4),las=1)
# abline(v=mean(norm_data))
# abline(v=mean(group_1),col="red")
# abline(v=mean(group_2),col="blue")
# abline(v=mean(group_3),col="green")
# abline(v=mean(group_4),col="pink")
# データ全体の平均値からの因子の各水準の平均値のズレ
all_mean <- c(rep(mean(group_1),length(group_1)),
rep(mean(group_2),length(group_2)),
rep(mean(group_3),length(group_3)),
rep(mean(group_4),length(group_4)))
# 残差
data_residuals <- sum((y - mean(y))**2) - sum((all_mean - mean(y))**2)
# 残差自由度
free_residuals <- (length(y) - 1)-(length(unique(x)) - 1)
f_val <- (sum((y - mean(y))**2) / (length(y) - 1)) / (data_residuals / free_residuals)
bind <- c(bind,f_val)
}
PC落ちるかとヒヤヒヤした。
ほんでF分布と比較してやる
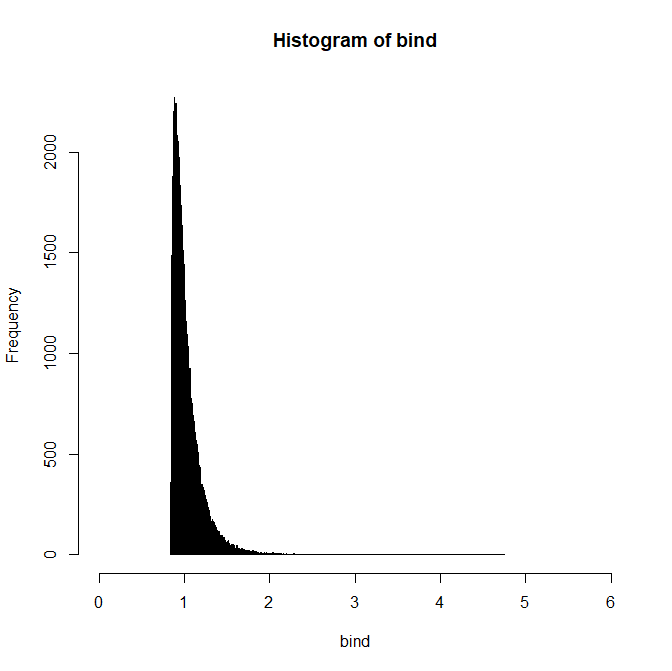
作成データをhistにする
dat<-hist(bind,breaks=1000,xlim=c(0,6))
F分布から乱数を取り出す
dat2<-hist(rf(100000,free_residuals,(length(y) - 1)),breaks=1000,xlim=c(0,6))

一致してるとは言えないでしょ
なにか間違ったかなぁ・・・
教えてわかる人!
そもそもdf(x,16,19)ってこうじゃない?

どこで間違えたのか