はじめに
近年基盤モデルや生成AIが人気ですが、2023年の7月にIBMからwatsonxが利用可能になったので、IBMCloudでも生成AIを利用することが可能になりました。本稿ではwatsonxの中のwatsonx.dataについて記載します。
watsonx.dataはすべてのデータ、分析、AI ワークロードを拡張するために最適化したレイクハウスを作成することが可能です。2023年11月現在ではIBM Cloudの他にAWS上にも構築可能で、IBM Cloudではダラス、ワシントンDC、フランクフルトで利用可能です。watsonx.dataについてより詳細な情報はdocsを参照ください。
また、本記事ではオンプレミスの環境へセキュアに接続するためにIBM Cloudの新しいソリューションである"Satellite Connector"を使用しています。
本ソリューションを使用することでオンプレミス側にAgent導入用のLinuxサーバー(冗長構成の場合は2台必要)を用意するだけでセキュアなTLSトンネリングによる接続が可能になります。
本稿ではwatsonx.dataからオンプレミス上にあるデータベースへSatellite Connectorを用いたアクセス方法について記載します。
本記事ではSatellite Connectorを用いてwatsonx.dataからオンプレミスのデータベースへの接続に関して記載していますが、冗長化などのより詳細な接続手段について以下の記事、docsも参考になりますので、ぜひご覧ください。
今回は以下のdocsの手順を参考に構築します。
docs : Satellite コネクターの作成
docs : watsonx.data データベース・カタログペアの追加
本稿の構成図は下記の通りです。
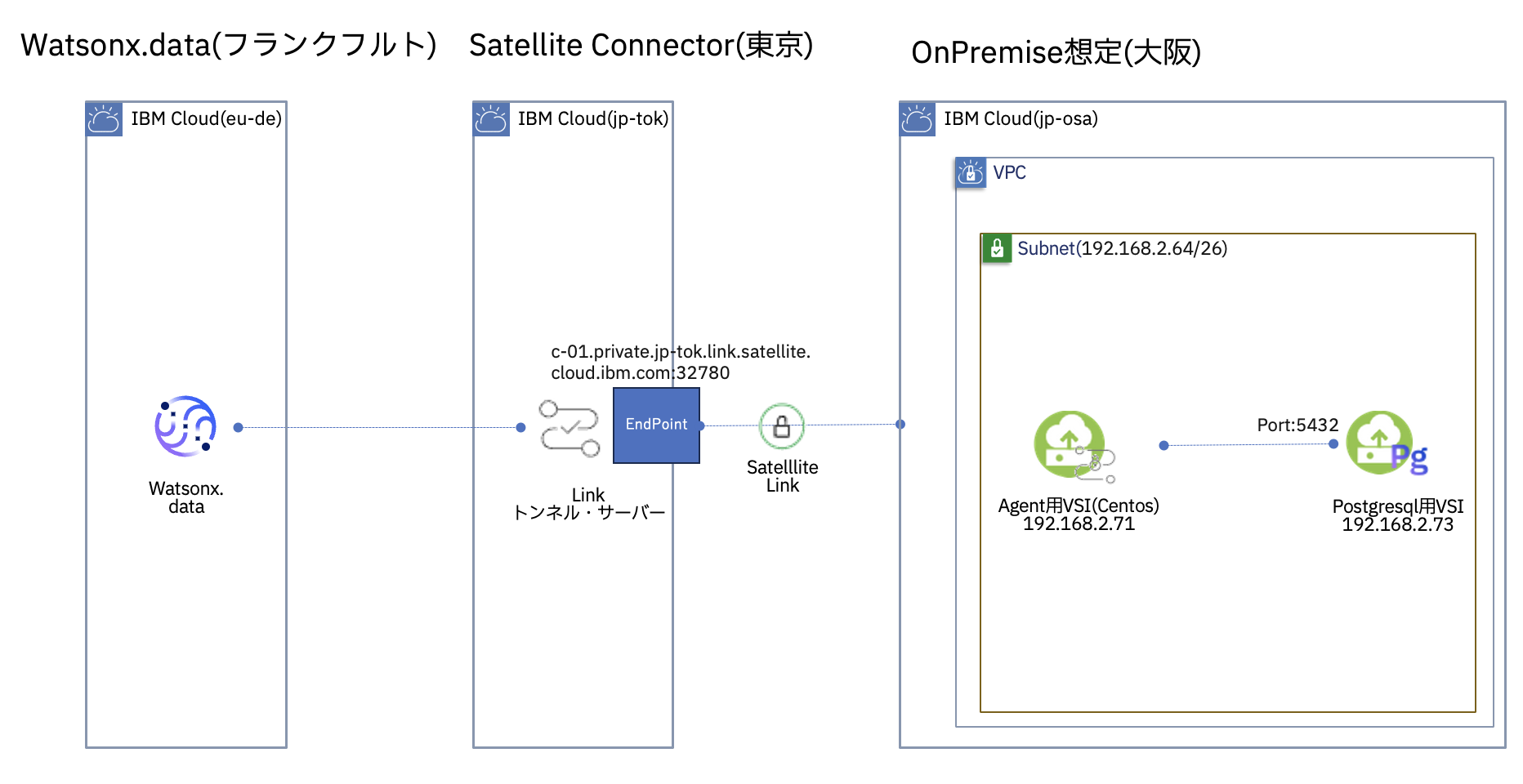
今回はフランクフルトのwatsonx.dataから東京リージョンにあるSatellite Connectorを経由し、大阪リージョンにあるオンプレミス想定のデータベース(PostgreSQL)に接続方法を記載します。本構成ではwatsonx.dataとSatellite Connectorは別リージョンで構成していますが、同リージョンに作成しても問題ないです。最終的な目標としてwatsonx.dataのポータル画面からデータベース内のテーブルを確認できるようにします。
事前準備
すでに以下の環境は構築済みであることを想定します。
- VPC(大阪リージョン), サブネット(今回は192.168.2.64/26)
- 1のVPCサブネット内のConnector Agent用仮想サーバー(2Core, 4GB, CentOS, 大阪リージョン, floating IP付与済み)
- 1のVPCサブネット内のPostgresql用仮想サーバー(2Core, 4GB, ubuntu, 大阪リージョン)
Agent用サーバーからPostgresqlサーバーへJDBCで接続できるようにあらかじめ設定してあるものとします(CP4DaaSからPostgreSQLへの接続はJDBC接続で行います)。
また、オンプレミス想定のVPC環境はSatellite Connector導入のためのFloating IPしか公開されておらず、データベースに関しては外部との通信は一切できない構成になっております。
構築手順
1. watsonx.dataの構築
まずはじめにwatson.dataを構築していきます。
IBMのポータル画面の左側のメニューから「watsonx」を選びます。

watsonx.dataの「Get started」ボタンを選択します。

watsonx.dataのオーダー画面に移行するのでロケーションとサービス名を入力します。設定が終わったら、右側の利用条件にチェックを入れ、「作成」ボタンを押して作成します(名前、タグは自由で問題ないです)。
プロモーションクレジットを使用したい場合は右側の「Apply a code」にコードを入力してください。


作成されたインスタンスはポータル左上ハンバーガーメニューから「リソースリスト」→「データベース」で確認できます。

クリックするとwatsonxのサービス画面が出るので、右上の「Webコンソールを開く」を押して、watsonxのポータル画面に移行します。

watsonxの初期設定を行います。

バケット構成は「新規IBM管理バケットのプロビジョン」を選択します。
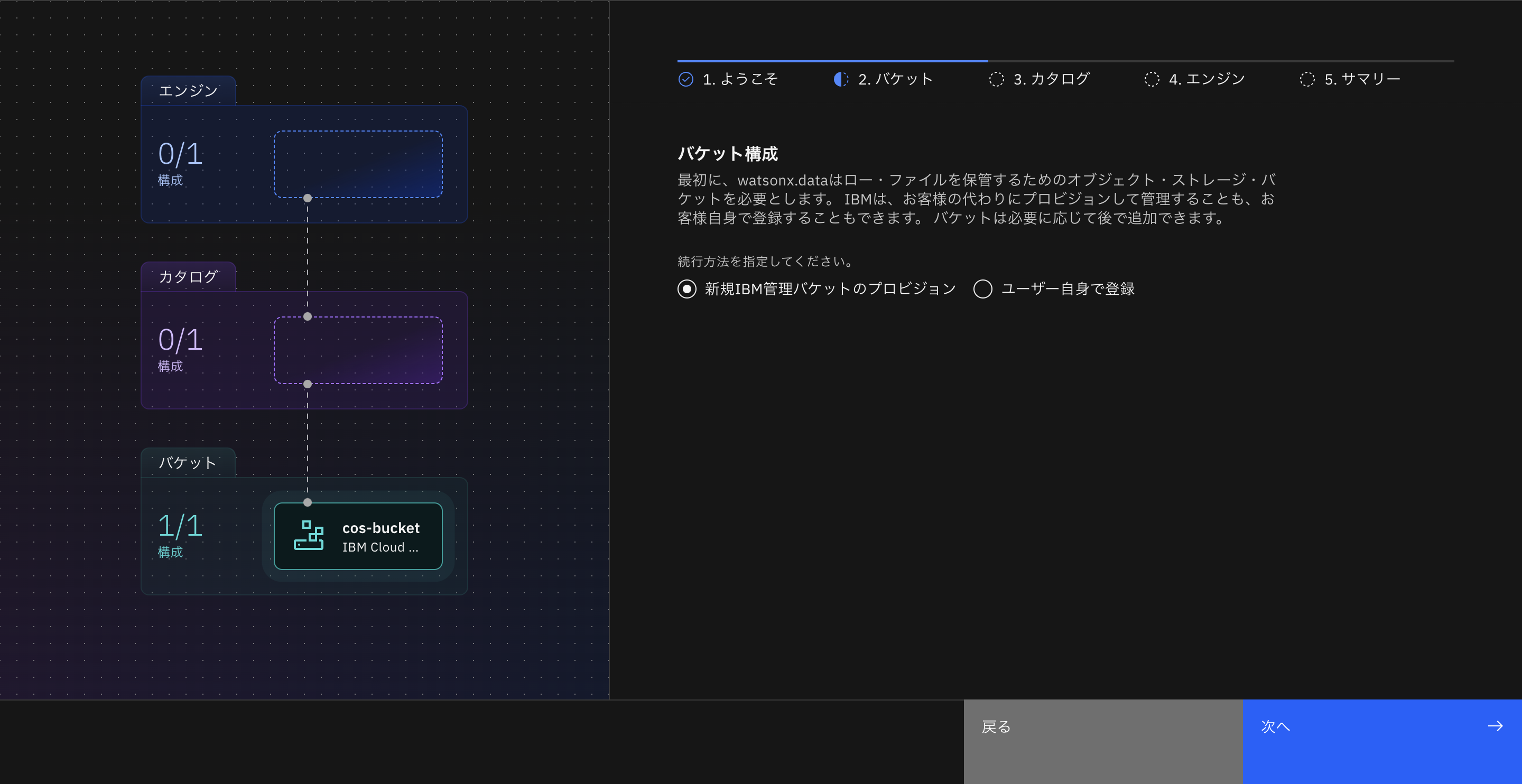
カタログ構成では「Apache Iceberg」を選びます。

エンジン構成ではタイプ「Presto v0.282」、サイズを「スターター」で選びます。

以上の項目入力完了したら12分ほどでwatsonx.dataが作成されます。下の画面が表示されてもエンジンがまだ構築されていないのでエンジンが1/1になるまで待ってください。

以上でwatsonx.dataの構築は完了です。
2. Satellite Connectorの注文
次に東京リージョンでSatellite Connectorを作成します。ポータル画面の検索機能から「Satellite」を検索します。

Satelliteのホーム画面に移行したら、左側メニューの「Connector」を選択し、右上の青い「Connectorの作成」ボタンを選択します。

今回は東京リージョンにConnectorを作成するので、リージョンにjp-tokを指定し、「コネクターの作成ボタン」で作成します。
作成したConnectorを選択すると以下の画面が表示されます。

Connector IDは後ほど使用するのでどこかに記録しておきます。
3. ConnectorAgentの作成
次にAgent用サーバーにConnectorAgentを作成します。
3-1. Agent導入のための準備
まずはじめにConnectorAgentをインストールするため、Agent用サーバーにsshでログインしdockerのインストールを行います。
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
systemctl enable docker
systemctl start docker
続いて環境ファイルを作成し、環境変数を設定します。
mkdir -p ~/agent/env-files
vi ~/agent/env-files/env.txt
env.txtの中身は以下の通りに設定します。
SATELLITE_CONNECTOR_ID=U2F0ZWxsaXRlQ29ubmVjdG9yOiJjazk0dDI0dDFjcGQ4dms0NDg1ZyI
SATELLITE_CONNECTOR_IAM_APIKEY=xxxxxxxxxxx
SATELLITE_CONNECTOR_REGION=jp-tok
SATELLITE_CONNECTOR_TAGS=sample tag
SATELLITE_CONNECTOR_IDはConnector画面で確認できます。APIKEYはポータルのIAMから作成できます。詳しくはdocsを参照ください。
これでConnectorAgentのコンテナを作成する準備ができました。
3-2. Agentの作成
まずはAgentイメージをpullするため、Container Registoryにログインします。パスワード要求にはAPIKEYを入力します。
docker login -u iamapikey icr.io
Password:
Login Succeeded
ログインができたらConnectorAgentのイメージをコンテナレジストリからpullします。
docker pull icr.io/ibm/satellite-connector/satellite-connector-agent:latest
docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
icr.io/ibm/satellite-connector/satellite-connector-agent latest 66b5c7f42805 12 days ago 415MB
イメージのpullが確認できたので、コンテナを起動します。
docker run -d --env-file ~/agent/env-files/env.txt icr.io/ibm/satellite-connector/satellite-connector-agent:latest
aaef3d2f49ded9b800d4a2c254e42caa1941de0930547052b705912b8f4a9ccb
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
aaef3d2f49de icr.io/ibm/satellite-connector/satellite-connector-agent:latest "/usr/local/bin/node…" 9 seconds ago Up 8 seconds great_colden
docker logs aaef3d2f49de
{"level":30,"time":"2023-10-23T02:29:35.437Z","pid":13,"hostname":"aaef3d2f49de","name":"agentOps","msgid":"A02","msg":"Load SATELLITE_CONNECTOR_ID value from SATELLITE_CONNECTOR_ID environment variable."}
{"level":30,"time":"2023-10-23T02:29:35.438Z","pid":13,"hostname":"aaef3d2f49de","name":"agentOps","msgid":"A02","msg":"Load SATELLITE_CONNECTOR_IAM_APIKEY value from SATELLITE_CONNECTOR_IAM_APIKEY environment variable."}
...
docker logでログを確認していますが、ちゃんと起動していることがわかります。
また、この時点でSatellite Connectorの画面でもアクティブなエージェントとして作成したコンテナのIDが確認できます。

3-3. ユーザーエンドポイントの設定
次にオンプレミス環境にアクセスするためのエンドポイントをConnector側に作成します。
Connectorメニューから「ユーザーエンドポイント」タブ→「エンドポイントの作成」を選択し、エンドポイントを作成します。

リソース詳細は任意のエンドポイント名、宛先FQDNまたはIP(今回はDBサーバーである192.168.2.73)、宛先ポートはPostgresqlの外部接続ポートである5432番に設定します。

以降は特に設定に変更はなので次にを選択しつづけ、最後に「エンドポイントの作成」を選択するとエンドポイントの作成が完了します。
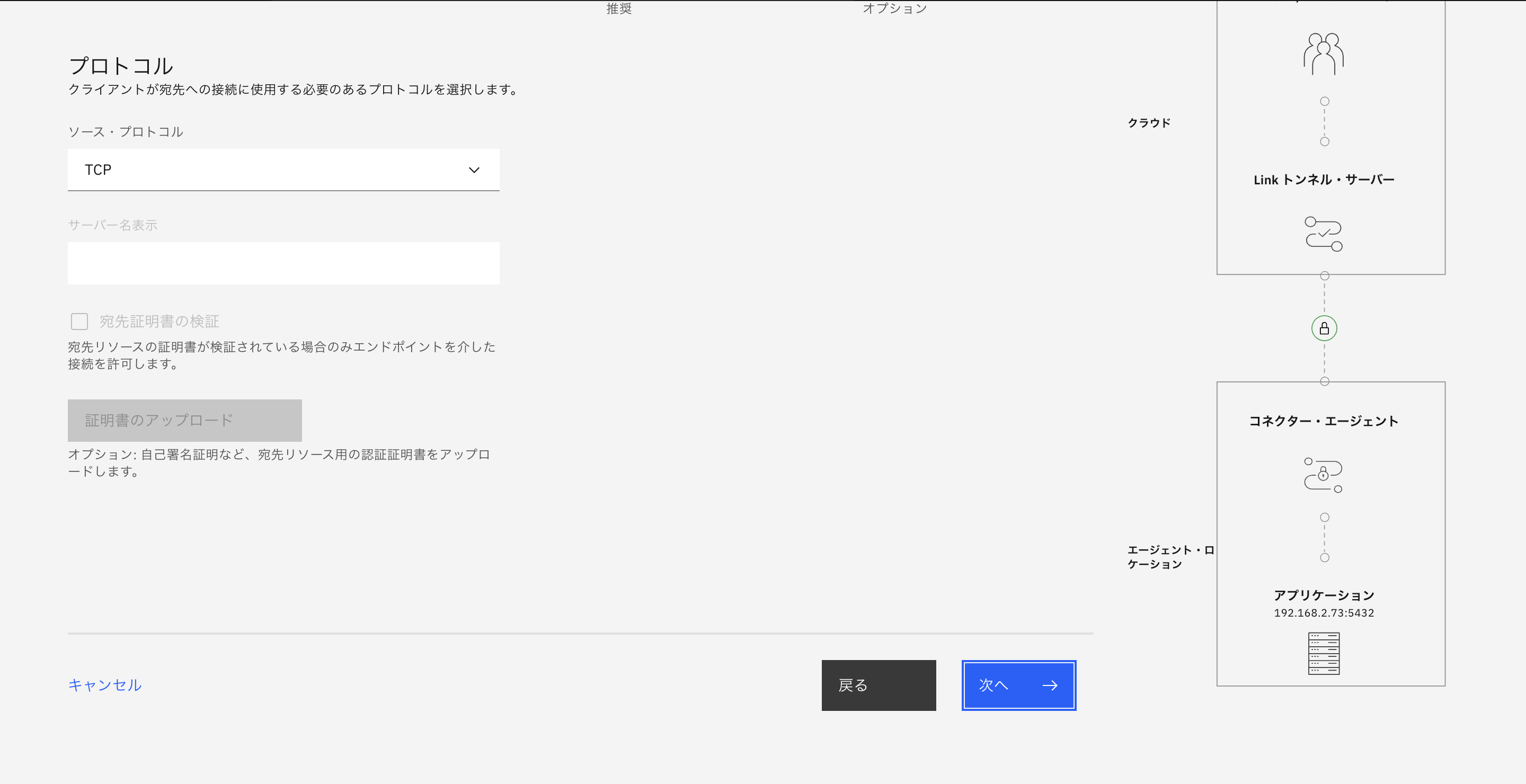


作成が完了するとConnector画面から作成したエンドポイントが確認できます(c-01.private.jp-tok.link.satellite.cloud.ibm.comの32780番ポート)。このエンドポイントとポートは後ほど使用するので記録しておきます。

4. watsonx.dataとデータベースの接続の作成
最後にwatsonx.dataとオンプレミスのデータベースとの接続を作成します。
4-1. カタログ・データベースの追加
外部データベースをカタログとデータベースをインフラストラクチャー・マネージャーに追加します。インフラストラクチャー・マネージャーのカタログについては以下を参照ください。
docs : Presto Overview
Prestoホワイトペーパー
watsonx.dataポータルの左側の「インフラストラクチャー・マネージャー」を選択します。

インフラストラクチャー・マネージャーの右上の「コンポーネントの追加」→「データベースの追加」を選びます。
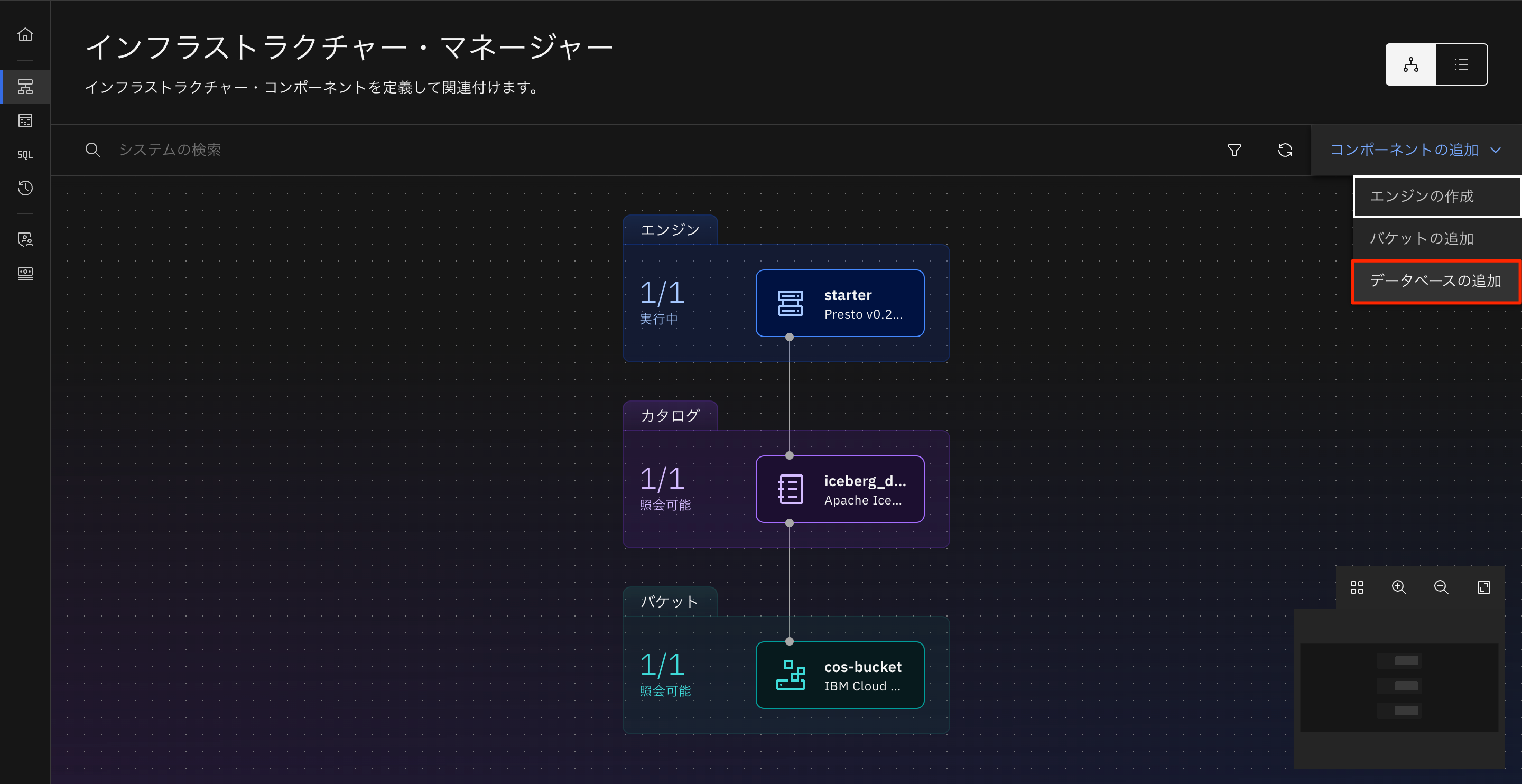
データベースの追加では以下のパラメータを入力します。
| パラメーター | 値 |
|---|---|
| データベースタイプ | PostgreSQL |
| データベース名 | オンプレミス内のデータベース名 |
| ホスト名 | c-01.private.jp-tok.link.satellite.cloud.ibm.com |
| ポート | 32780 |
| ユーザー名 | データベースのユーザー名 |
| パスワード | ユーザー名のパスワード |
| カタログ名 | Postgresql(任意なカタログ名) |
データベース名、ユーザー名、パスワードはそれぞれオンプレミス上のデータベースで作成したものを入力します。ホスト名、ポートはSatellite Connectorのユーザーエンドポイントからエンドポイントアドレスの値を入力します。
また、パラメータ入力後に「Test connection」をクリックすることで接続ができているかのテストを行うことができます。

接続ができていると以下のように「Successful」と表示されます。
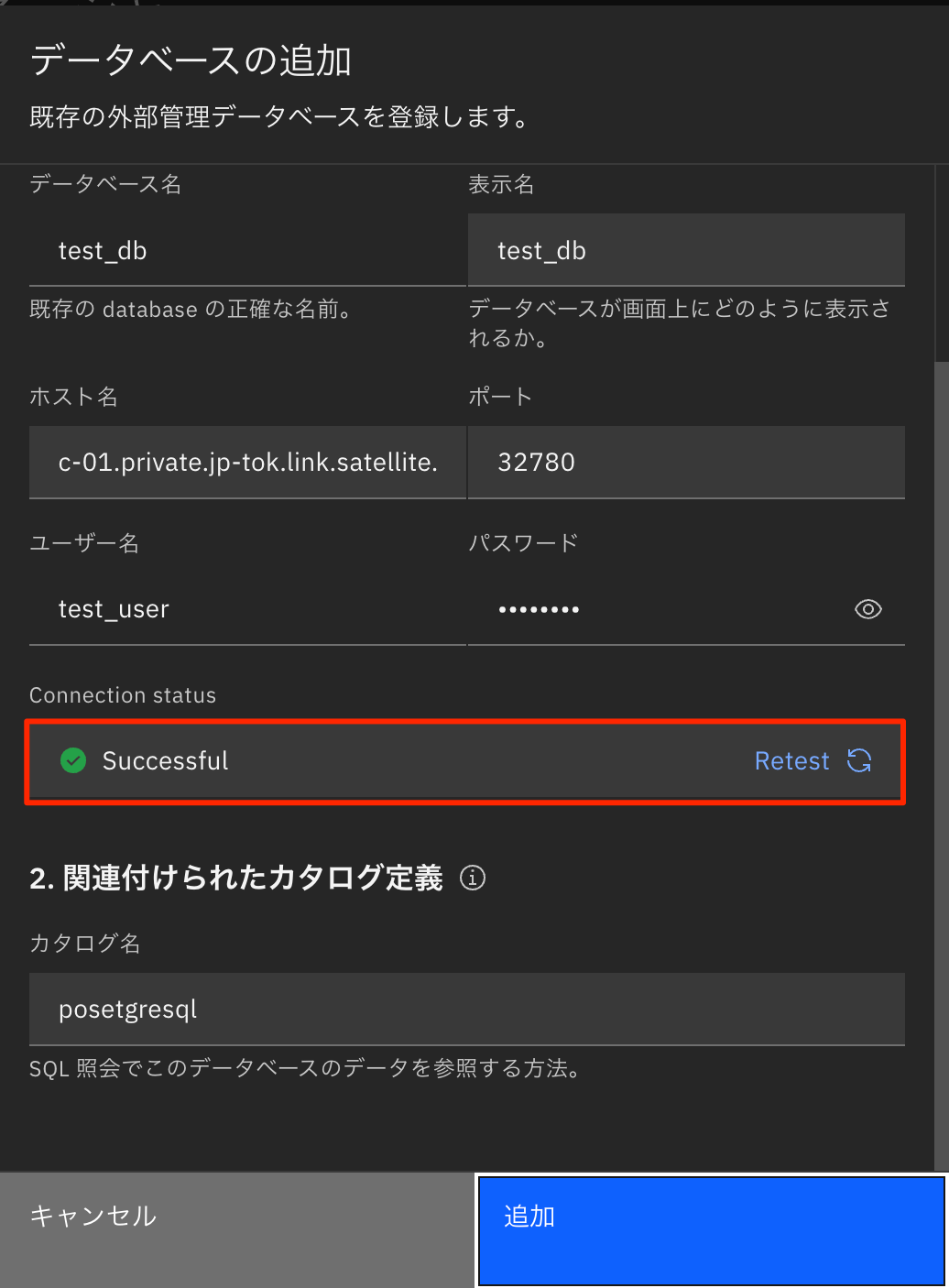
全ての項目を入力後、追加ボタンをクリックしてデータベースを追加します。
作成後、以下のようにカタログとデータベースが追加されていることがわかります。

4-2. エンジンとカタログの接続
次にエンジンとカタログを接続します。先ほど作成したカタログにカーソルを合わせ、「関連付けの管理」を選択します。
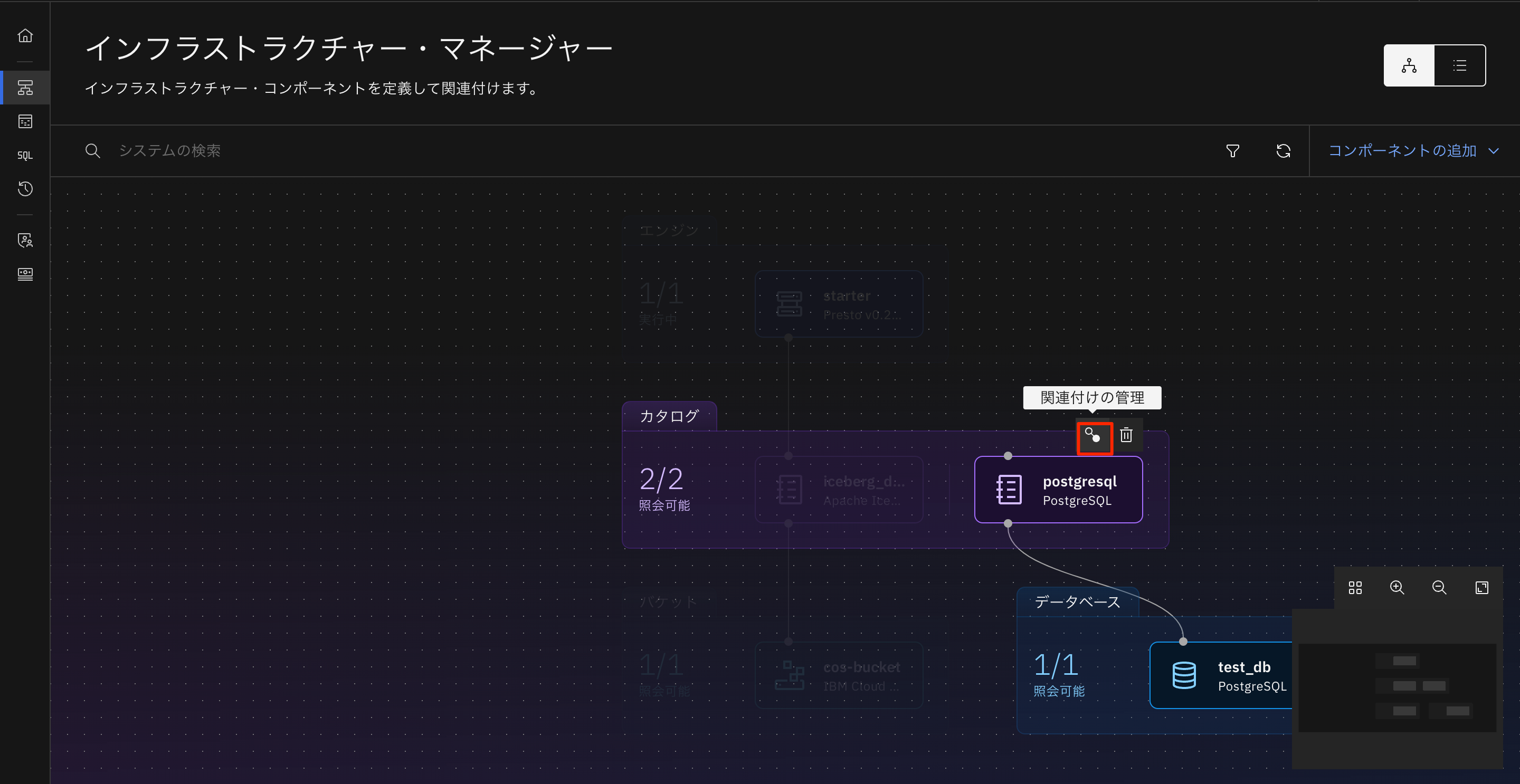
エンジンのstarterのチェックボックスにチェックを入れ、「保存してエンジンを再起動する」をクリックします。

しばらく待つとstarterとpostgresqlの接続ができていることが確認できます。
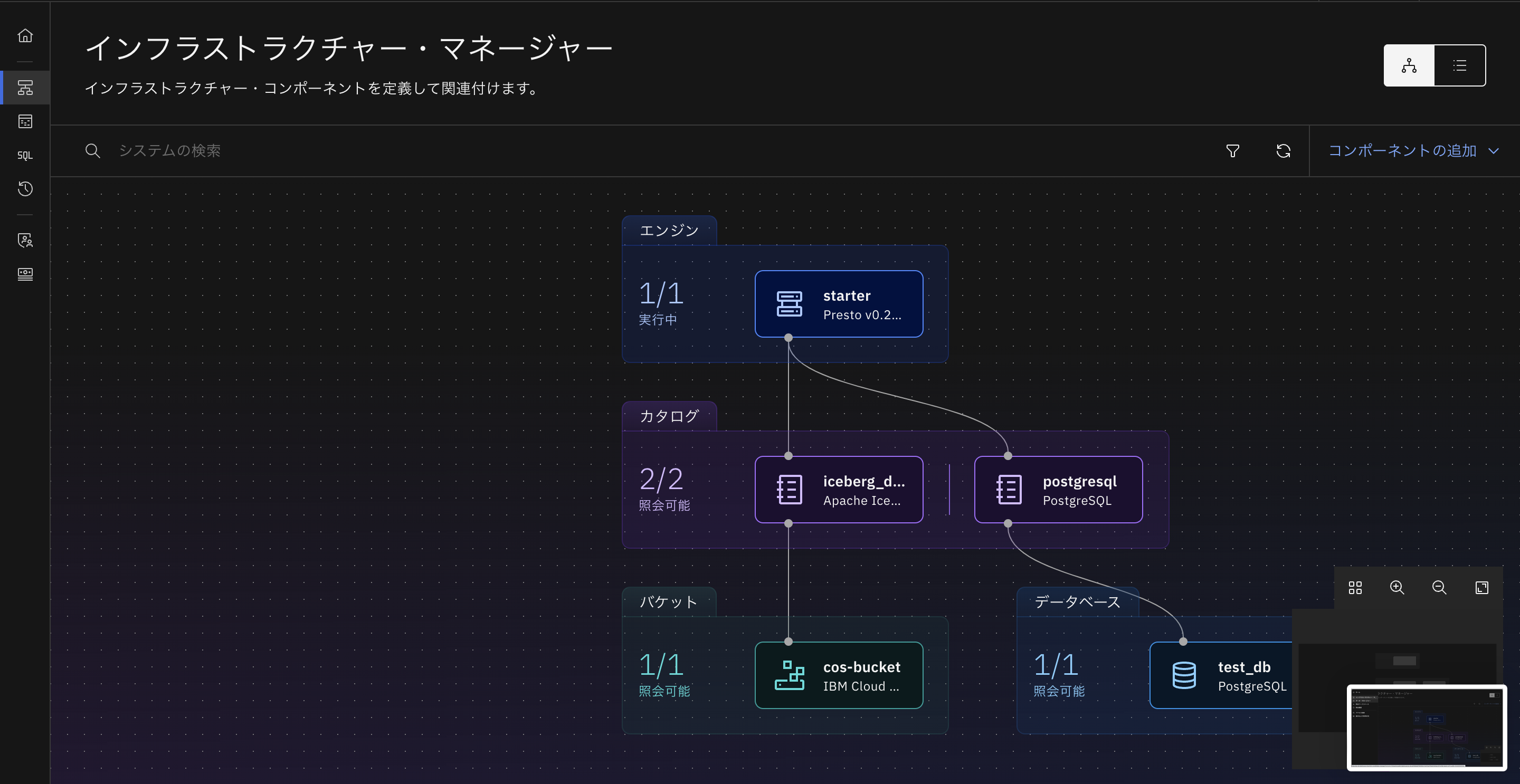
4-3. データベースの中身の確認
最後に実際にデータベースの中身を見ることができるのか確認してみます。
左側のメニューの「データマネージャー」を選択します。

左側の関連づけられたカタログの中に先ほど作成したカタログのpostgresqlが確認できます。下矢印をクリックするとスキーマや中のテーブルも見ることができます。
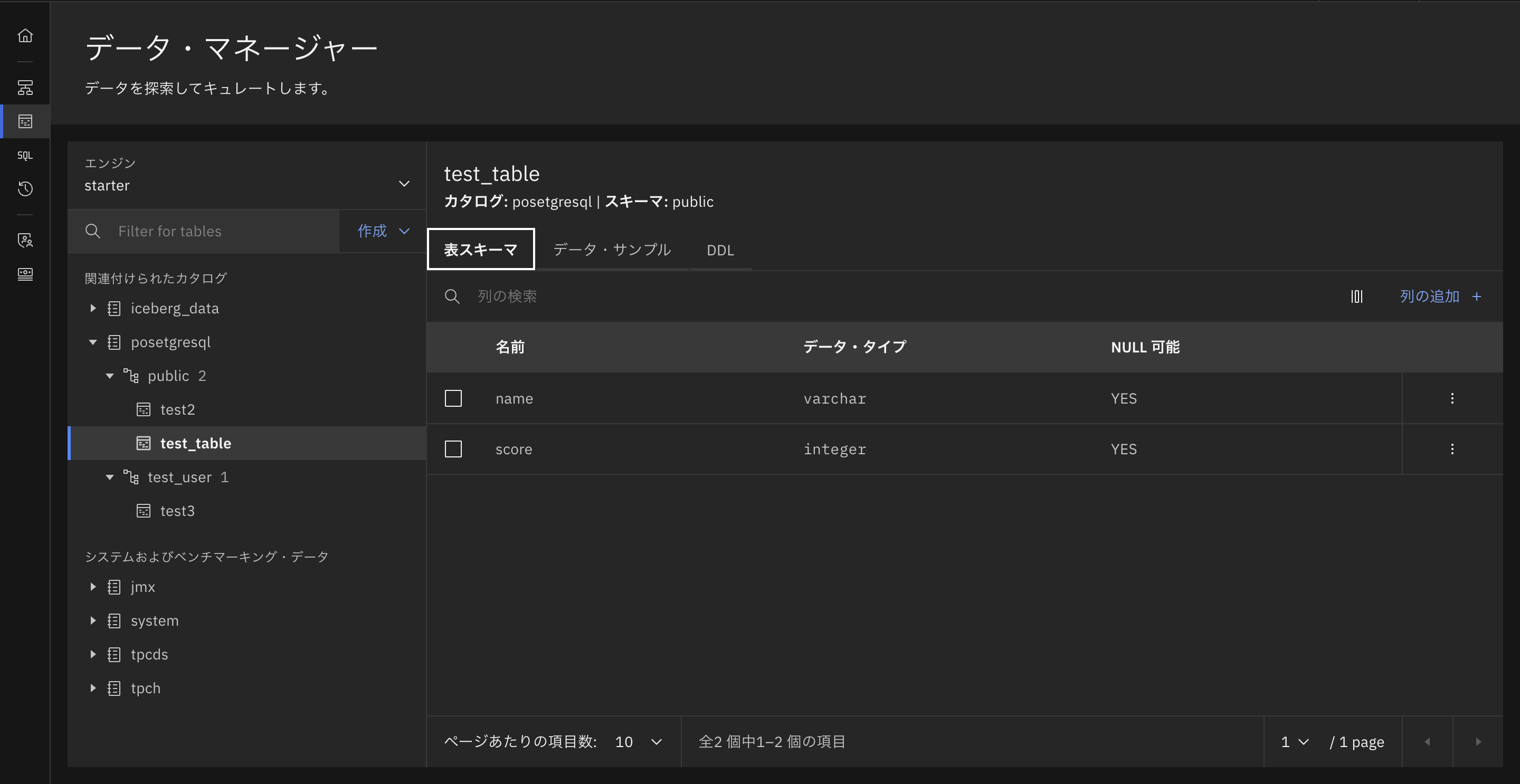
また、テーブルをクリックすると表スキーマからテーブルのパラメータを確認でき、データサンプルからはどのようなデータが入っているかを確認することが可能です。

まとめ
本記事ではwatsonx.dataと外部データベースの接続手順を紹介しました。これにより複数の外部データベースをwatsonx.dataに集め、データの収集・分析ができるようになるかと思います。watsonx.dataには他にもwatsonx.aiで生成したAIとの連携もできるらしいので試してみたいですね。
watsonxについてより詳しく知りたい場合は以下を参照してみてください。
watsonxの機能・ユースケースなど : IBM watsonx
watsonxのチュートリアル : (docs) Allowing trial experience
watsonx.dataのdemo : Get started with watsonx.data
また、Qiitaでwatsonxのタグで調べるとwatsonxの実装についての記事がいくつか出てくるのでそちらも是非ご覧ください。