学びのメモとして、pandas周辺のコードをチートシート代わりに自分の参考用としてまとめています。
1. pandasのインポート
import pandas as pd
2. DataFrameの作り方
辞書から作成する方法と、CSVファイルから読み込む方法の2つがある。
①辞書から作成する方法
import pandas as pd
dict = {"name":["Hokkaido","Tokyo","Aichi","Osaka"],
"capital":["Sapporo","Shinzyuku","Nagoya","Osaka"],
"area":[83424,2191,5172,1905],
"population":[5286,13822,7537,8813]}
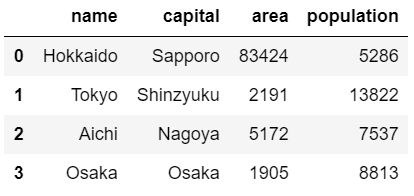
prefecture = pd.DataFrame(dict)
prefecture
②CSVファイルから読み込む方法
import pandas as pd
# read_csv関数を使用
prefecture = pd.read_csv("path/to/prefecture.csv")
しかし、このままではcsvファイルの行ラベルが、それ自体が列として認識されてしまうため、最初の列に行インデックスが含まれていることを以下の様に知らせる。
import pandas as pd
# index_col=0とすることで、インデックスが0である列が行ラベルであることを知らせる
prefecture = pd.read_csv("path/to/prefecture.csv", index_col = 0)
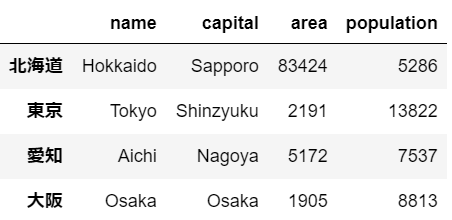
3. 行ラベルの設定
prefecture.index = ["北海道","東京","愛知","大阪"]
4. DataFrameからデータを選択
角括弧("[]")を用いる方法と、locやilocなどのアクセスメソッドを用いる方法の2種類がある。
①[]を用いる方法
# nameの列のみを選択
prefecture["name"]

しかし、この方法で取り出したデータ型はpandasSeriesというデータ型であり、DataFrameではない。DataFrameとしてデータを取り出すには以下の様に[]を2重にして記述する。
# 角括弧を二重にすることでデータ型をDataFrameにしたままデータを抽出
prefecture[["name"]]

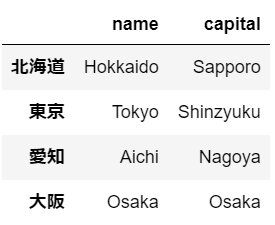
また、以下の様にして複数列を取り出すこともできる
# 複数の列を選択できる
prefecture[["name","capital"]]
横の行を取り出すためにはスライスを使用する。
prefecture[1:3]

②loc、ilocを用いる方法
locはラベルに基づいてデータを選択、ilocは位置に基づいてデータを選択できる。
locは、以下の様にDataframe名.loc["行ラベル"]と記述すると、その行のデータを選択できる。
prefecture.loc["東京"]

しかし、このやり方ではまだデータ型がDataFrameではなくなってしまうため、DataFrameとして選択したい場合は角括弧を二重で用いる。
prefecture.loc[["東京"]]

以下の様に記述することで、複数の行を選択できる。
prefecture.loc[["東京","愛知"]]

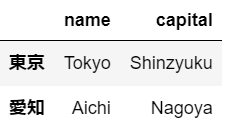
さらに、以下の様に記述すれば、列も指定ができ、指定をした行と列の交差点のみのデータを選択できる。
prefecture.loc[["東京","愛知"],["name","capital"]]
リストと同様、":"だけで全選択を意味する。
# ":"を用いて、行を全選択
prefecture.loc[:,["name","capital"]]
ilocはlocで行ラベルを使用する代わりに、インデックスを使用。
# 下記2つは全く同じ結果を返す。
prefecture.loc[["東京"]]
prefecture.iloc[[1]]
# 下記2つは全く同じ結果を返す。
prefecture.loc[["東京","愛知"]]
prefecture.iloc[[1,2]]
# 下記2つは全く同じ結果を返す。
prefecture.loc[["東京","愛知"],["name","capital"]]
prefecture.iloc[[1,2],[0,1]]
# 下記2つは全く同じ結果を返す。
prefecture.loc[:,["name","capital"]]
prefecture.iloc[:,[0,1]]