はじめに
以前、MacでローカルLLMを動かすならvllm-mlxで良いという記事を書きましたが、
そのvllm-mlxを超えそうなものがでてきました。
oMLXです
oMLX
oMLXも実はvllm-mlxから派生したものらしいので、系統としては似ています。
oMLX started from vllm-mlx v0.1.0 and evolved significantly with multi-model serving, tiered KV caching, VLM with full paged cache support, an admin panel, and a macOS menu bar app
良いところ
- GUIの管理画面があるのでCLIが苦手でも使える

- もちろんCLIからもサーバー起動できる
- vllm-mlxではオンメモリキャッシュに対応していなかった
Qwen3.5がちゃんとオンメモリキャッシュで使える - LLMのランタイムとしてだけでなく、モデルの量子化を最適化するメソッドの確立など、オーナーの熱量が凄い
oQ (oMLX universal dynamic quantization)
MLX向けの新しい量子化メソッドoQが公開されました
- oQ は Apple Silicon 上で動作するデータ駆動型の mixed‑precision quantization システム
- 標準の mlx‑lm safetensors 互換モデルを作成し、oMLX、mlx‑lm などあらゆる推論サーバで動作する
- 各レイヤーの量子化感度を測定し、感度に応じてビット数を割り当てることで、oQ2~oQ8 の 7 つのレベルで既存手法(mlx‑lm)より大幅に精度を向上させている
ドキュメントにあるベンチマークを引用
| Benchmark | Samples | 2-bit | 3-bit | 4-bit | |||
|---|---|---|---|---|---|---|---|
| mlx-lm | oQ | mlx-lm | oQ | mlx-lm | oQ | ||
| MMLU | 300 | 14.0% | 64.0% | 76.3% | 85.0% | 79.7% | 83.3% |
| TRUTHFULQA | 300 | 17.0% | 80.0% | 81.7% | 86.7% | 87.7% | 88.0% |
| HUMANEVAL | 164 (full) | 0.0% | 78.0% | 84.8% | 86.6% | 87.2% | 85.4% |
| MBPP | 300 | 0.3% | 63.3% | 69.0% | 72.0% | 71.7% | 74.3% |
2bitの精度改善は凄まじく、oQ3bitとmlx4bitがほとんど同等になっています。
執筆時点で公式から出ている量子化モデルを見た感じ、ファイルサイズもかなり小さいのが良い。
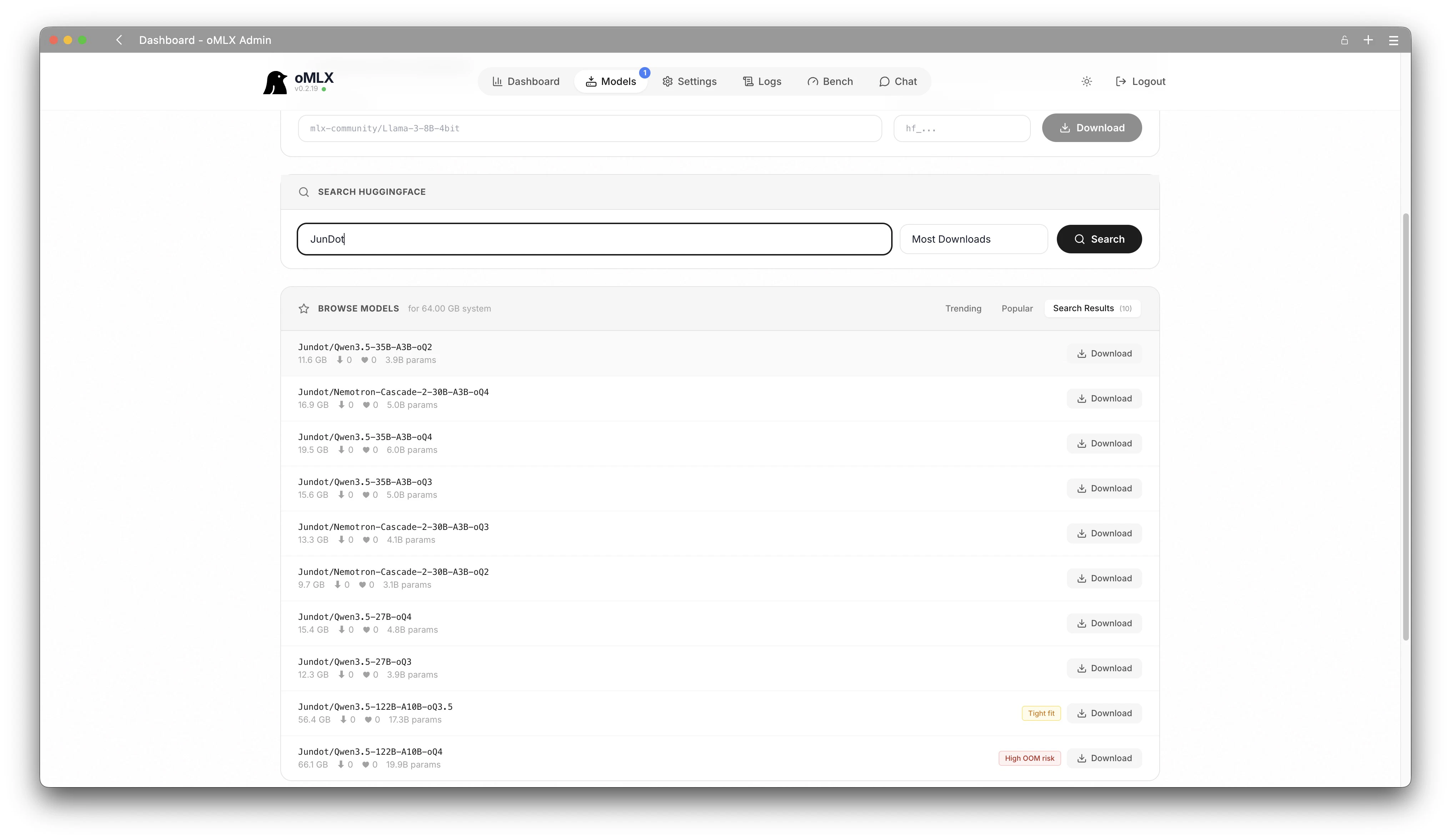
| モデル | ファイルサイズ |
|---|---|
| mlx-community/Qwen3.5-35B-A3B-4bit | 19.0 GB |
| Jundot/Qwen3.5-35B-A3B-oQ3 | 15.6 GB |
RAMが少ない端末でも動かしやすくなるだろうし、推論も多少早まるはず。
oMLXのインストール
リポジトリのReleasesにあるdmgをダウンロードし、
通常のアプリと同じようにインストールするだけ
初期セットアップもほとんどない (好きなPortとAPI Keyを設定する程度) のですぐ使えます。
〆
vllm-mlxは非常に良いアイデアで優れたランタイムですが、
oMLXが開発速度、熱量により先を行きそうな雰囲気があります。
CLIが苦手な人でも簡単に使えるので、
ローカルLLMが気になる人は一度試してみると良いかと。