はじめに
Microsoft Fabricでは、Warehouse(データウェアハウス)内で使用できるSQLエンジンとしてTransact-SQL (T-SQL)が提供されています。
一方で、Lakehouse(レイクハウス)にはSparkベースのエンジンがあり、ノートブック上でSpark SQL(PySparkのSQLモード)を使ってデータ操作が可能です。
両者はどちらもSQLに似た構文を持ちますが、細かな違いがいくつも存在します。
本記事では、Microsoft FabricのWarehouse向けT-SQLとLakehouseノートブック向けSpark SQLの間にある地味だけれど重要な違いについて
現場でじっそうしていて気づいたところを整理します。
ここに記載のない違いがもあるかと思うので、ぜひコメントで教えてください!
T-SQLに慣れた方がSpark SQLを使う場合や、その逆の場合に「あれ、書き方が違う...」となったときに振り返っていただけると幸いです。
Microsoft Fabric内でT-SQLとspark SQLが使える場面
簡単に整理します
T-SQL:ウェアハウスのSQLエディタ、およびレイクハウスに付随するSQLエンドポイント内で使用可能
spark SQL:ノートブックで使用可能(レイクハウス内のデータへのクエリになる)
▽ウェアハウスのSQLエディタ
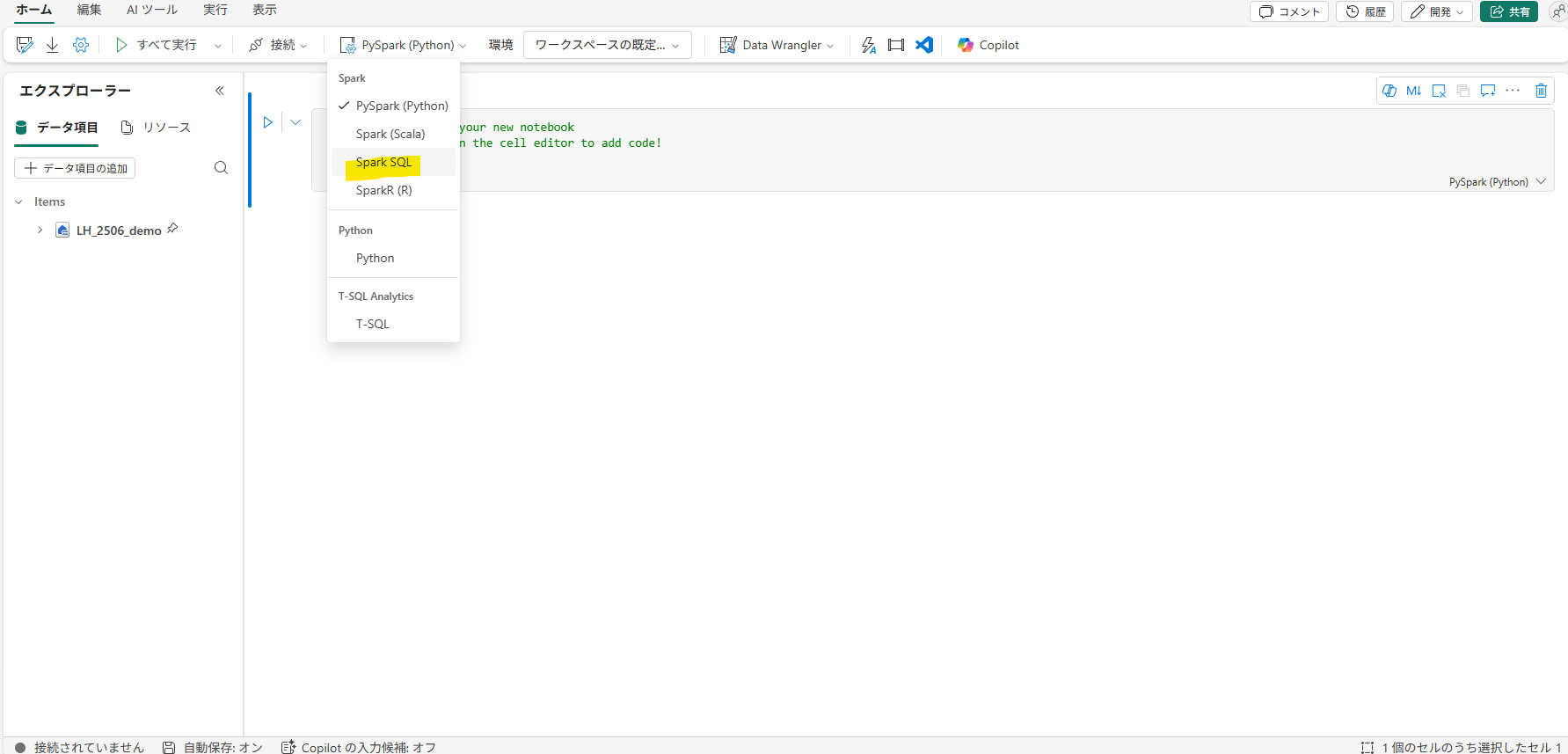
▽ノートブックの画面・リボンからデフォルトの言語をspark SQLにすることが可能。他の言語をデフォルトにしている場合はセルの最初に %%sqlと記載することでそのセル内でspark SQLが使用可能になる。
基本的な構文の違い
まずはT-SQLとSpark SQLの基本的な構文上の違いです。クエリの書き方そのものに関わる部分で、両者のSQLにはいくつか相違点があります。
列名の囲いの違い
T-SQL
T-SQL (SQL Server)では、列名にスペースなどの特殊文字を含める場合、角かっこ[ ]で囲むか、二重引用符"で囲む必要があります。
なお、列名に特殊文字などがない場合はとくに囲わなくてもOKで非常に楽です。
たとえば、Country Nameという列を持つテーブルから選択する場合、T-SQLでは次のように書けます。
-- T-SQLでの例(列名にスペースを含む場合)
SELECT Country Name
FROM [Sample Table];
Spark SQL
一方、Spark SQLでは列名はバッククォート(`)で囲むのが基本です。
バッククォートは「Shift + @」で入力することができます。
-- Spark SQLでの例(列名にスペースを含む場合)
SELECT Country Name
FROM `sample table`;
結果行数の制限(TOP句 と LIMIT句)
クエリの結果から先頭N行だけ取得したい場合の構文が異なります。
T-SQL
T-SQLではSELECT文でTOP句を使います。
(Limit句を使用することはできません。)
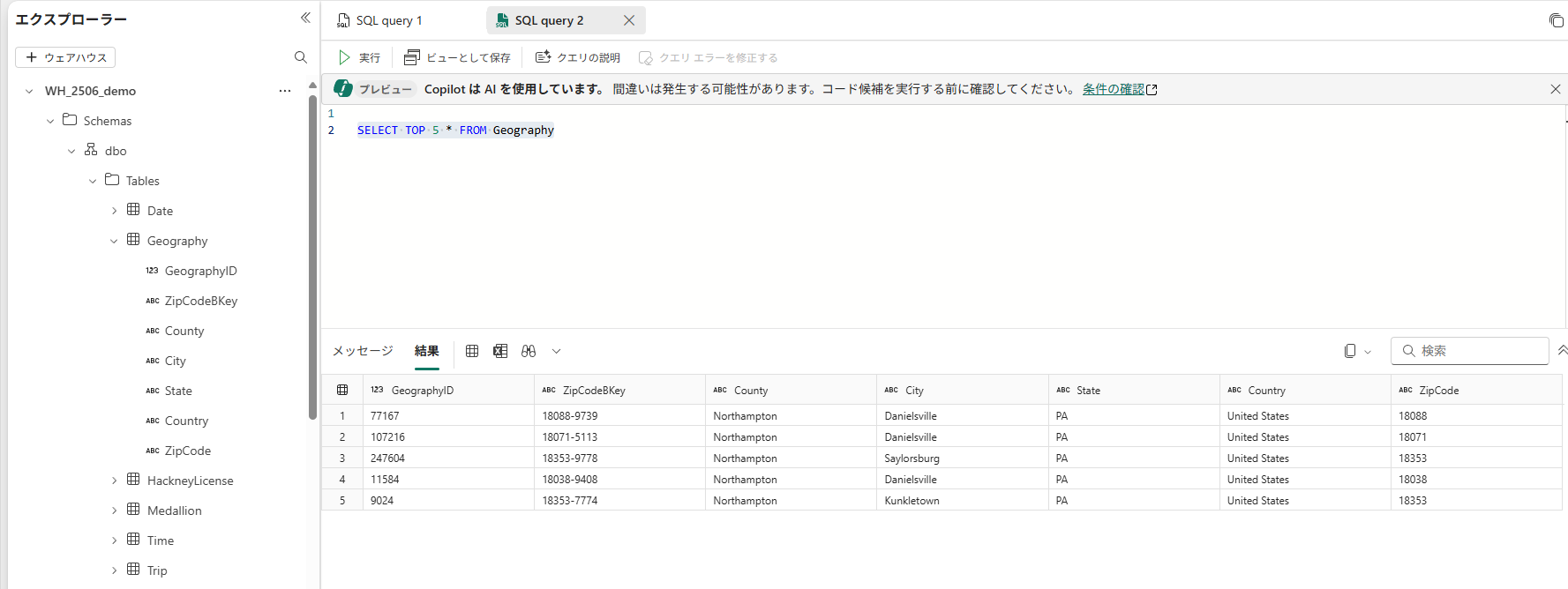
例えば「先頭5行」を取得するには以下のSQL文になります。
-- T-SQL(上位5行を取得)
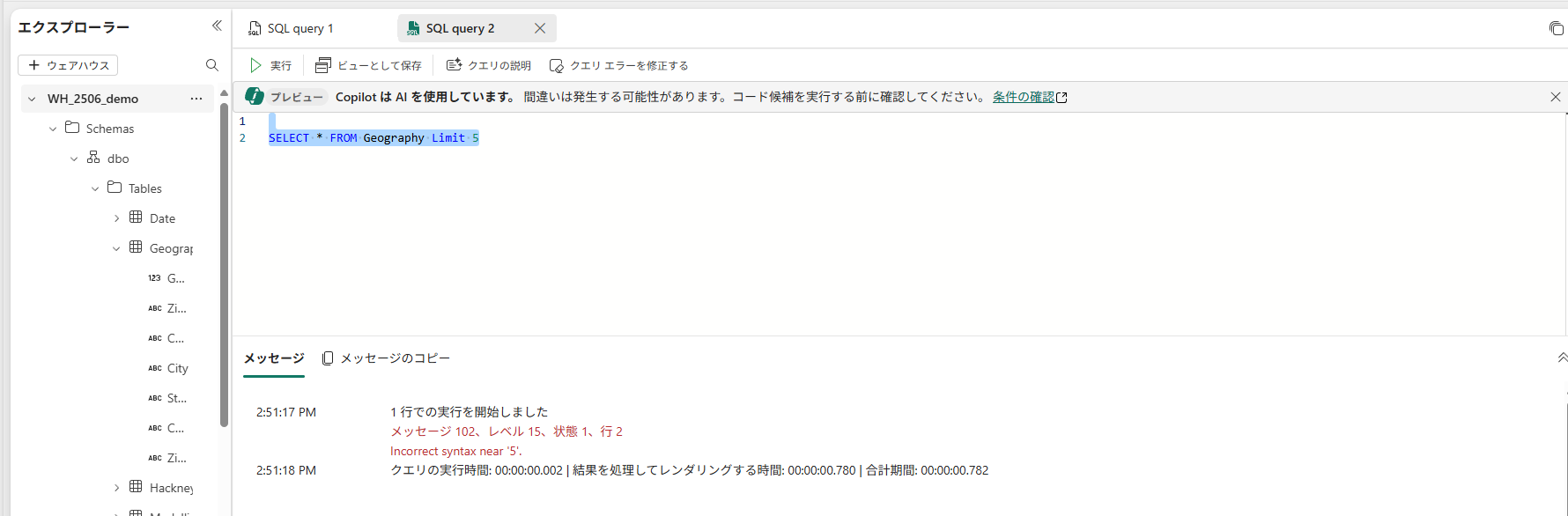
SELECT TOP 5 *
FROM Sales;
▽Limit句を使うとエラーになる
Spark SQL
一方、Spark SQLにはTOP句がなく、代わりにLIMIT句を使用します。
例えば同じく先頭5行を取得するには、Spark SQLでは次のように書きます。
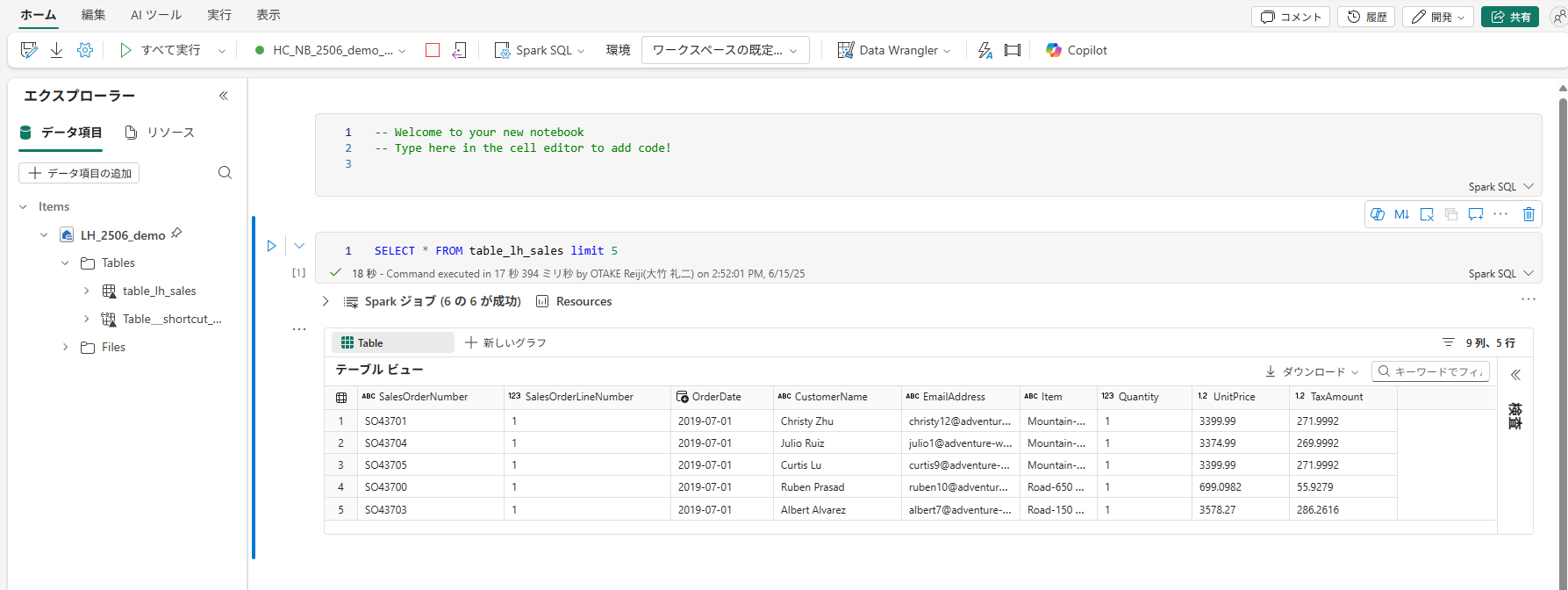
-- Spark SQL(上位5行を取得)
SELECT *
FROM sales
LIMIT 5;
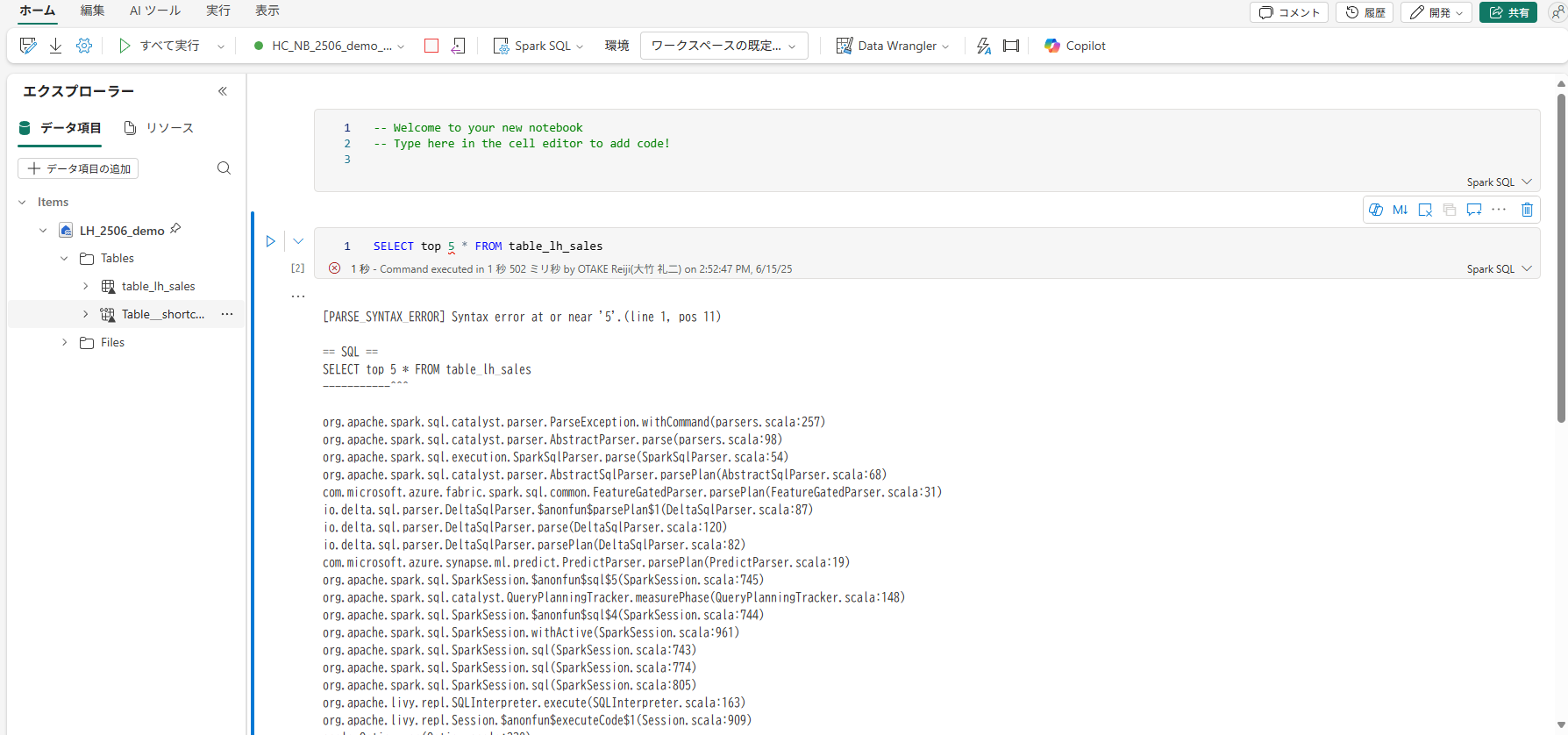
▽top句を使うとエラーになる
関数の挙動の違い
次に、T-SQLとSpark SQLで組み込み関数の動作や書き方に違いがある点を見ていきます。
集計関数(SUMなど)の挙動
数値以外の型に対するSUMの挙動が両者で異なります。
T-SQLはデータ型に忠実
T-SQLでは、SUMやAVGといった集計関数は基本的に数値型カラムに対してのみ使用できます。
たとえば、カラムがテキスト(文字列)型で数値が文字列として保存されている場合、SUM(そのカラム)を直接実行するとエラーになります(「operand data type varchar is invalid for sum operator」等のエラー)。
文字列を数値として集計したい場合、明示的にCASTやCONVERTで数値型に変換する必要があります。
Spark SQL
これに対しSpark SQLでは、カラムが文字列型でも中身が数字であればSUMを実行した際に自動で数値にcastしようと試みます。
つまり、文字列カラムに数値(例えば "100" や "250" といった文字列)が入っている場合、SparkのSUM関数はそれらを数値とみなして合計を計算してくれる場合があります。
ただしこの動作には上限があるようです。
SparkのDecimal型(高精度数値)は最大38桁までしか扱えないため、それを超えるような超大きな数字が文字列で入っていると内部キャストが失敗し、集計もエラーになります。
参考リンク
⚠️注意:
Spark SQLが文字列を自動変換してくれるからといって油断は禁物です。データに数字以外の文字(空文字やNULL、数字以外の文字列)が含まれると当然エラーになりますし、暗黙の型変換に頼ると想定外の不具合を生む可能性があります。可能な限り明示的に型を変換してから集計するのが安全です。
文字列の連結
T-SQL
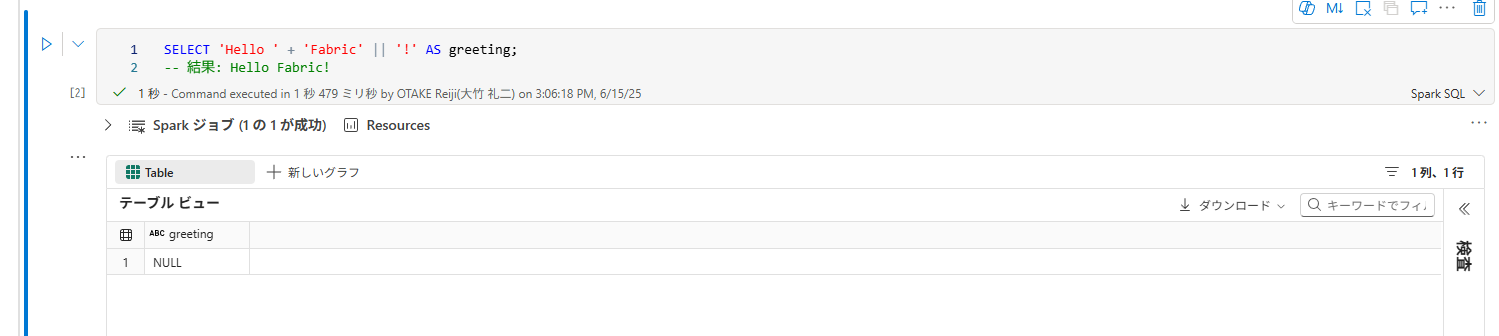
T-SQLでは、+演算子が文字列連結に使われます。
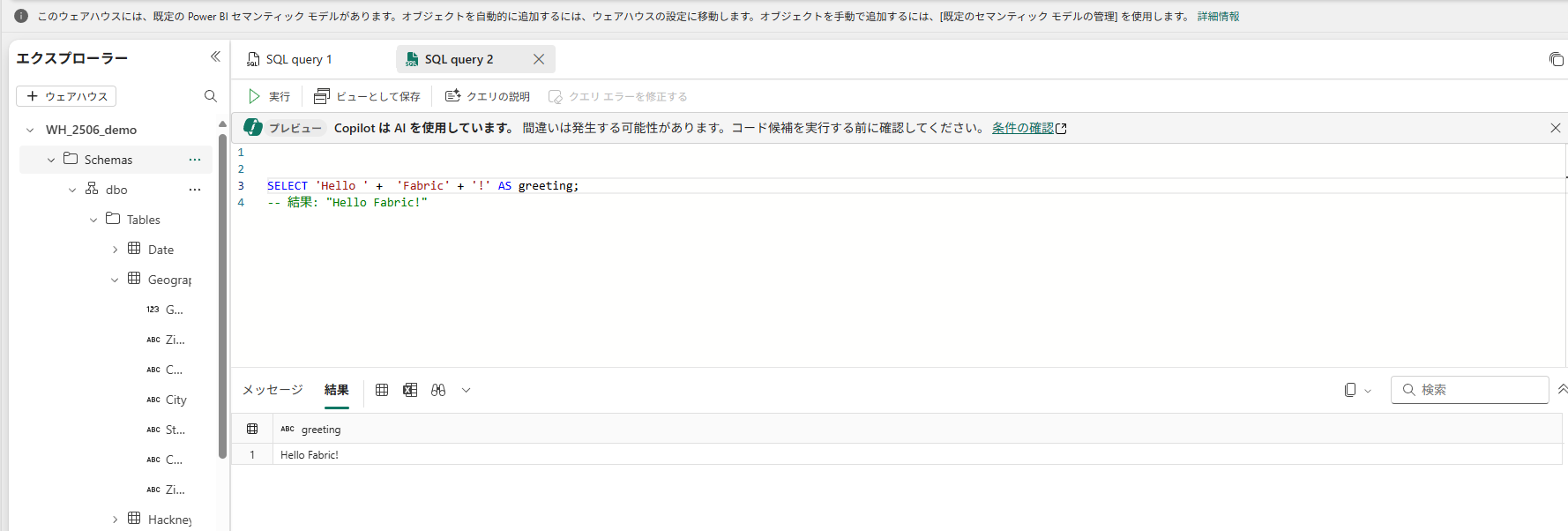
-- T-SQLでの文字列連結
SELECT 'Hello ' + 'Fabric' + '!' AS greeting;
-- 結果: "Hello Fabric!"
▽|| にするとエラーになる。
Spark SQL
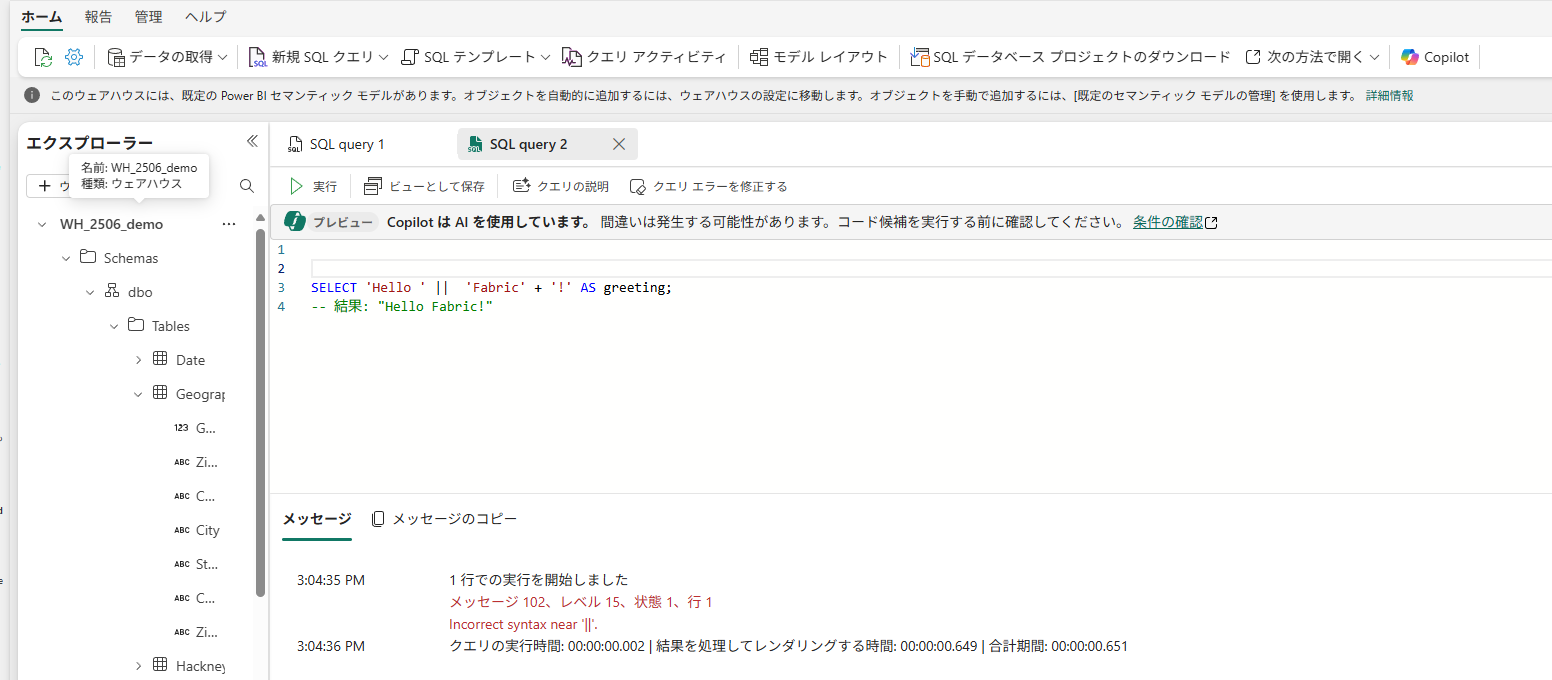
一方、Spark SQLでは||(パイプ2つ)が文字列連結のために使えます。
-- Spark SQLでの文字列連結
SELECT 'Hello ' || 'Fabric' || '!' AS greeting;
-- 結果: Hello Fabric!
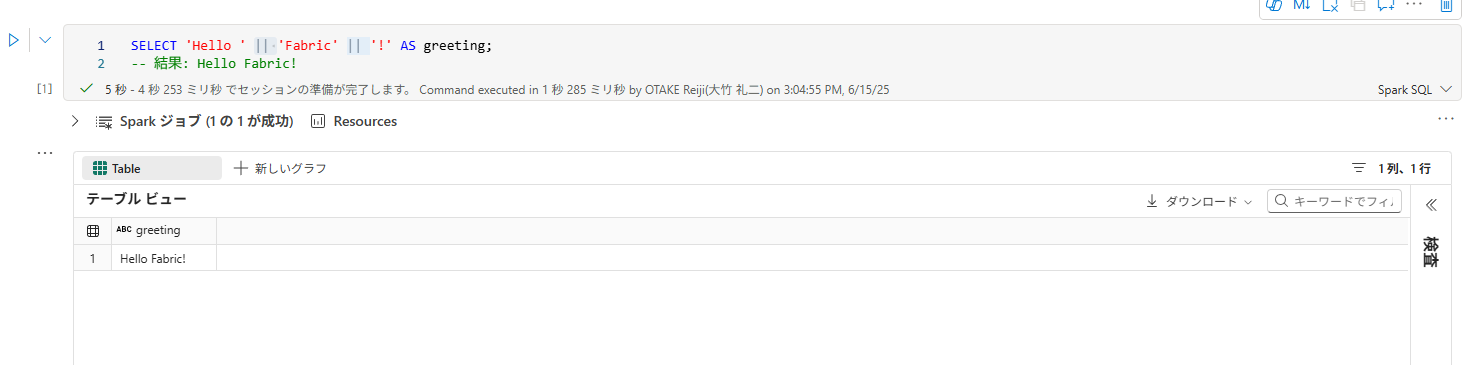
▽+を使うとNULLになる。
日付・時刻関数
日付・時間系の関数名や使い方には差異がおおかったので。主なものを以下に簡単にまとめました。
| 処理内容 | T-SQL | Spark SQL |
|---|---|---|
| 現在日時の取得 | GETDATE() |
current_timestamp() |
| 現在日付の取得 | CAST(GETDATE() AS date) |
current_date() |
| 日の加算 | DATEADD(day, n, date) |
date_add(date, n) |
| 日の差分 | DATEDIFF(day, start, end) |
datediff(end, start) |
| 曜日/月名の抽出 |
DATENAME(dw, date) など |
dayofweek(date), date_format(...)
|
| 日付のフォーマット |
CONVERT(varchar, date, style)FORMAT(date, format)
|
date_format(date, 'pattern') |
DISTINCT(重複削除)の違い
T-SQLとSpark SQLでは、DISTINCT の使い方自体は大きく変わりませんが、集計関数と組み合わせた場合の制限に違いがあります。
T-SQL:COUNT(DISTINCT 列名) は一つの列のみ対応
T-SQL(SQL Server系)では、COUNT(DISTINCT col1) のように1つの列に対しては問題なく使用できます。
-- T-SQL:単一列のユニーク件数
SELECT COUNT(DISTINCT country)
FROM Sales;
しかし、以下のように複数列をカンマで指定して COUNT(DISTINCT col1, col2) のように書くことはサポートされていません。
-- T-SQL:これは構文エラーになる
SELECT COUNT(DISTINCT country, product)
FROM Sales;
-- Msg 4145: 式の構文が間違っています
どうしても col1, col2 のユニークな組み合わせの件数を出したい場合は、サブクエリでDISTINCTを先に実行する必要があります。
-- サブクエリで複数列のDISTINCTを先に取る
SELECT COUNT(*)
FROM (
SELECT DISTINCT country, product
FROM Sales
) AS distinct_combination;
このように、T-SQLではCOUNT(DISTINCT)は1列限定と覚えておきましょう。
Spark SQL:COUNT(DISTINCT col1, col2) がそのまま書ける
一方、Spark SQLでは COUNT(DISTINCT col1, col2) のように複数列をそのまま指定することが可能です。
-- Spark SQL:複数列の組み合わせのユニーク件数
SELECT COUNT(DISTINCT `country`, `product`)
FROM sales;
DISTINCTが複数列に対応しているかどうかは、T-SQLとSpark SQLの間で特に差が出るポイントなので、「あれ、使えたはずなのに…」と混乱しないように意識しておきましょう。
データ型やNULLの扱いの違い
最後に、サポートしているデータ型の違いやNULL値の扱いの違いについてです。
サポートされるデータ型の違い
| 分類 | T-SQL(Fabric Warehouse) | Spark SQL(Fabric Lakehouse / Notebook) |
|---|---|---|
| ブーリアン型 |
BIT型(0 / 1)を使用。WHERE is_active = 1 のように明示的な比較が必要 |
BOOLEAN型(TRUE / FALSE)。WHERE is_active のように直接条件式に書ける |
| 文字列型(Unicode) |
CHAR / VARCHAR のみ。NVARCHAR / NCHAR は非サポート。UTF-8コレーションでマルチバイト文字も扱える |
STRING型。長さ指定なしの可変長。内部はUTF-8、テーブル作成時にVARCHAR(n)を明示すれば反映される |
| 日付・時刻型 |
DATE, TIME, DATETIME2, DATETIME など複数あり。TIMEやdatetimeoffsetは非サポートで代用が必要 |
DateType, TimestampType のみ。TIME型はなく、文字列またはダミー日付きで扱う |
| 特殊型 |
decimalやbinary, WKT文字列で代替 |
UNIQUEIDENTIFIER相当はバイナリ形式(16バイト)で格納され、直接結合不可。地理情報はカスタム実装が必要 |
| 整数・小数型 |
INT, BIGINT, SMALLINT, REAL, DECIMAL(p,s)。TINYINT(1バイト)は非サポート |
IntegerType, LongType, ByteType, FloatType, DecimalType(p,s) など。ByteType で1バイト対応可 |
まとめると、FabricのSparkエンジン(Lakehouse)とSQLエンジン(Warehouse)ではデータ型の対応関係に違いがあるものの、テーブルを作成すると自動で相互にマッピングされます。
まとめ
以上、Microsoft Fabric環境におけるT-SQLとSpark SQLの違いについて、基本構文から関数・データ型・NULL扱いまで幅広くまとめました。
WarehouseのT-SQLは従来のSQL Serverとほぼ同じ感覚で使えますが、一部Fabric固有の制限や挙動があります。
一方Lakehouseノートブック上のSpark SQLは、ビッグデータ処理に強みを持つSparkエンジン上で動くため、SQLながらも多少クセのある挙動(暗黙の型変換や<=>演算子など)があります。
Fabricを利用するエンジニアの皆さんは、是非この違いを押さえておき、目的に応じて両方のSQLエンジンを使い分けてください。
慣れてくれば「あれ、T-SQLではどう書くんだっけ?Sparkではこの関数無かったな」というケースでも、本記事をチェックすれば思い出せるようになるはずです。
Fabricでのデータ活用が快適になるよう、参考になれば幸いです。
Youtubeもやっているので見ていただけると嬉しいです!
FabricやDatabricksについて学べる勉強会を毎月開催しています!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページ移動後、申し込み可能です!