【FabCon Atlanta 2026 レポート】Fabric IQ Ontology をどう見たか
FabCon Atlanta 2026 に参加してきました。
会場の雰囲気が伝わるショート動画も作ったので、よければ先にこちらも見てみてください。
この記事では、FabCon の現地で見聞きした内容を踏まえつつ、Fabric IQ の中でも特に Ontology に絞って、現時点でどう捉えるのがよさそうかを整理してみます。
Fabric IQ は OneLake 上のデータをビジネスの言葉で整理して、分析や AI エージェントから一貫した意味で扱えるようにするための workload として説明されています。
なお、Fabric IQ ワークロード には semantic model や data agent まで含みますが、その中に Ontology が含まれています。
「Fabric IQ」=「Ontology」と捉えている方は多いのではないでしょうか?
間違いではありませんが、Fabric IQは広い言葉ですので、
この記事では混乱を避けるため、主に「Ontology」という言葉を使っていきます。

FabCon 現地での Fabric IQ の温度感
FabCon の現地では海外の方も Fabric IQ への関心はかなり高かった印象です。
一方で、質問の中には「What is IQ(そもそも IQ って何?)」というかなり基礎的なものもありました。
つまり、注目度は高いが、まだ米国本土でも理解が浸透している段階ではない、というのが現地で受けた率直な印象です。
また、私自身も IQ 関連のセッションに参加しましたが、参加した範囲では、まだ「で、結局どの案件でどう使うのか」が明確に見えたとは言いにくかったです。
もちろん、Ontology のデモや、「AI がビジネスの意味を理解しやすくなる」「semantic layer が重要になる」といった方向性の話はありました。公式にも Ontology は、エンティティ、プロパティ、リレーションシップ、ルールを通じてビジネスを機械可読な形で表現するものと説明されています。
ただ、現時点ではまだ概念の魅力が先行していて、導入パターンが広く腹落ちしている段階ではない、というのが正直な感想です。
先に結論:Ontology はまだ本番環境では様子見したい
結論から言うと、私は現時点では Ontology を本番環境の中心に据えるのはまだ様子見 でよいと思っています。
理由はシンプルで、まず公式にも preview とされていること、
そして現時点でData Agentの精度を高めていく(ビジネスコンテキストを渡す)には、実は semantic model の使用でかなりカバーできる と感じているからです。
【よくある勘違い】
- Ontologyはビジネスの塊でエンティティを作ることができる。またビジネス的な意味のつながりを自然言語で表現しつつリレーションを作成することができる、一方でOntologyにテーブルや列の説明を自然言語で書くことはできない仕様
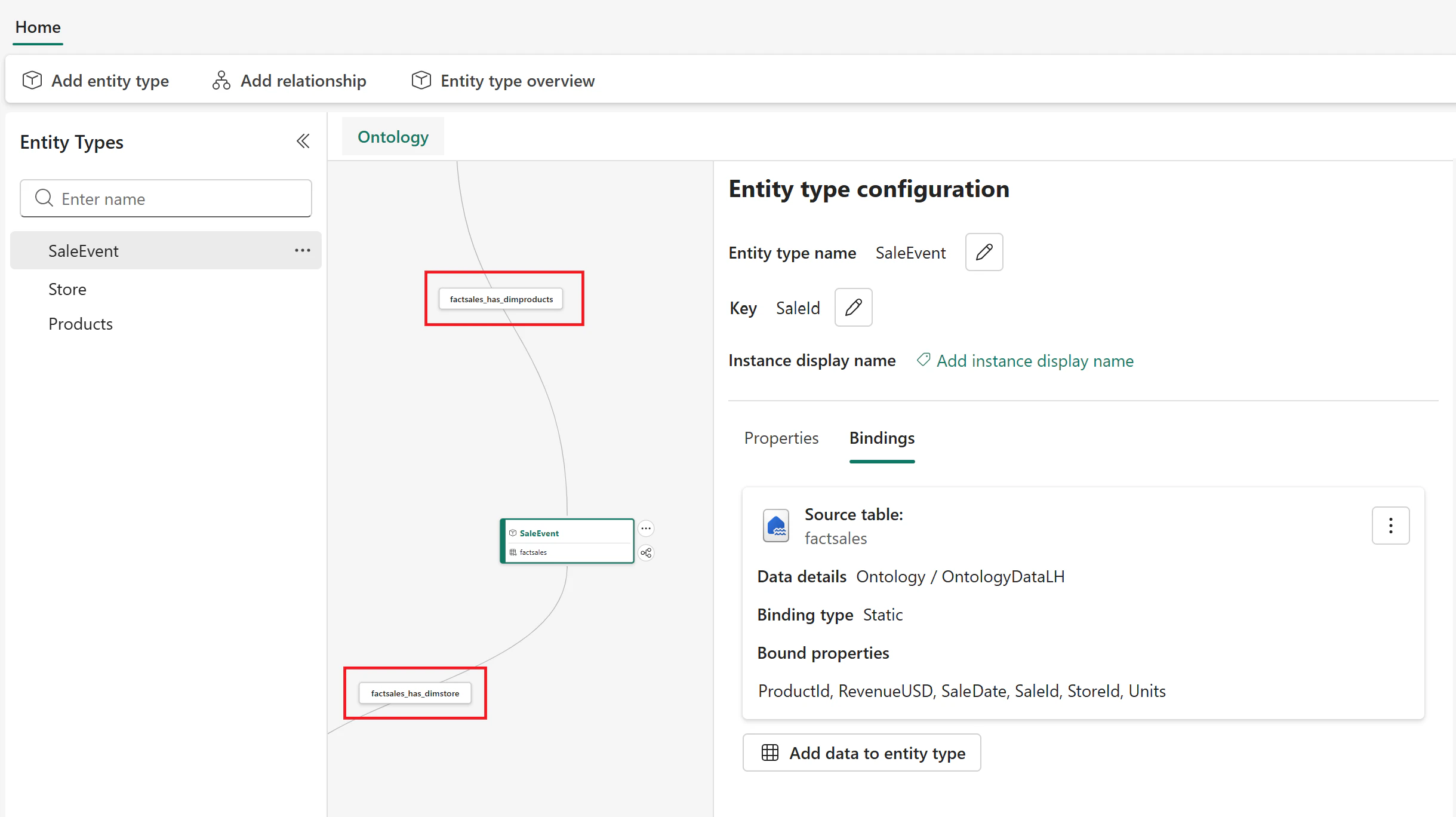
もちろん、これは「Ontology はいらない」という話ではありません。
むしろ Microsoft が今後かなり力を入れていく領域だと思いますし、私自身も期待しています。
ただ、少なくとも今は
- 開発部門が検証環境で触ってみる
- 将来のアーキテクチャ候補としてウォッチする
という段階なのかなと思います。
逆に、今すぐ本番で全面採用する前提で語るのは、少し早い と思っています。
セマンティックモデルは今もこれからもAIに活躍すると予想
では、「semantic layer はまだこれから」なのかというと、私はそうは思っていません。
むしろ今この瞬間でも、semantic model をしっかり作ることはかなり有効ですし、Ontology が将来 GA した後も、その重要性は変わらないはずです。
公式にも、Ontology は semantic model から生成できるとされています。つまり、Ontology は semantic model を置き換えるというより、semantic model を土台のひとつとして、さらにビジネスの意味や関係性を拡張していく方向で見るほうが自然です。
semantic model で今でもできること
Data Agentの登場により、semantic model は、単なる BI 用モデルにとどまりません。
Data Agentのデータソースにsemantic modelを指定することや、Data Agentのカスタマイズで、AIにビジネスメタデータを与えることができます。
具体的には
- semantic model
- Prep for AI 機能を使う
- プロパティ(テーブル/列の名前、テーブル/列の説明)にテーブルや列のビジネス上の意味を記載する
- DAX で計算式やビジネスロジックを事前定義する
- DataAgent
- 指示文でAgentの役割を明確にし、どういう動きをするべきか教える
- データソースの説明を記載し、Agentが質問に応じて使い分けられるようにする
- 予想できる質問などは事前クエリセットを使う(こちらはsemantic modelでは使えない)
より詳しくはまずはこちらのドキュメントから読み進めてみてください。
また、DataAgentのデータソースは必ずしも1つである必要はなく、
データ量が多いときや事前クエリセットを使いたいときなどは lakehouse や warehouse と組み合わせる設計も十分現実的です。
- 大量データは lakehouse / warehouse 側で持つ
- AI で使わせたい指標や定義は semantic model 側で整理する
もし、ビジネスメタデータを各テーブルや列に付けたいという要望があるのなら、
個人的なおすすめとしてはsemantic modelのプロパティに記載するのが現状いいかと思います。Data Agentはsemantic modelのプロパティを参照できます。
▽関連記事(セマンティックモデルのプロパティをノートブックから編集する方法)
Fabric のセマンティックリンクでセマンティックモデルのメタデータ(プロパティ)をノートブックから編集する
では、どんなときに Ontology が必要になりそうか
ここまで見ると、「だったら semantic model だけでいいのでは?」という話になります。
実際、多くのケースではかなりの部分を semantic model で賄えると思います。
その上で、あくまで私の理解でですが、
Ontology が必要になるのはこういう場面 だと感じたのは、主に次の2つです。
(逆に以下の2つのパターンでないときはsemantic modelで十分かもしれない。)
1. 多層のリレーションをつないで、グラフ的に問い合わせたいとき
1つ目は、多段の関係をまたいで問い合わせたいケースです。
semantic model でもリレーションは表現できますが、複雑になるほど JOIN の発想が強くなります。
それに対して Ontology は、graphが使われているので、パス探索などのグラフ的な扱いが得意です。
たとえば、
- 顧客
- 注文
- 商品
- 契約
- サポート履歴
- 担当組織
- 関連イベント
のように、複数ドメインをまたいで「この顧客に関係するものをたどって知りたい」という問いは、Ontology のほうが自然に表現できそうです。
つまり、単純な集計や KPI 問い合わせではなく、関係性そのものが価値になるケースでは Ontology の意味が出てきます。
2. 蓄積データとリアルタイムデータを、ひとつのビジネスエンティティとして扱いたいとき
2つ目は、履歴データとリアルタイムデータを、別々のシステムではなく同じビジネス対象として扱いたいケースです。
公式にも、Fabric IQ は OneLake 上のデータをビジネスの言葉で統一し、分析や AI エージェントに一貫した意味を与える方向で説明されています。
たとえば、
- Eventhouse に入っている直近の注文イベント
- Lakehouse に蓄積された過去の注文履歴
これらを「注文」といった1つのビジネスエンティティの文脈で横断的に扱いたいなら、Ontology の思想はかなり相性がよさそうです。
このあたりは、単なる BI モデル(物理モデル)というより、業務の意味構造を AI が理解するための基盤(論理モデル)として見たほうがしっくりきます。
Ontology を急いで入れる必要はない。今は「準備期間」だと思う
ここまで書いてきた通り、Ontology はとても可能性のある仕組みだと思います。
ただ、だからといって「今すぐ最優先で導入しなければならないものか」というと、個人的にはそう思っていません。
Ontology は、いわばビジネスの意味レイヤーを後から補強していくための仕組みです。
そのため、最初に必ず入れておかなければならない土台というよりは、ある程度データ基盤や意味整理が進んだ組織が、その上にさらに意味づけを強めていくためのものとして捉えるほうが自然です。
むしろ、Ontology を使いたいと思ってもそれ以前に、そもそも組織のデータ側が整っていないと難しい場面は多いはずです。
たとえば、
- 必要なテーブルがそろっていない
- キーの定義や意味が複数存在している
- ゆえに、つながるはずのテーブルが綺麗にリレーションでつながらない
といった状態では、Ontology を作る以前の問題になりやすいと思います。
だからこそ、来るべき Ontology 活用時代に備えて、今まず重要なのは組織のデータを整えておくことではないでしょうか。
Microsoft もこの領域には今後かなり力を入れていくはずですし、Ontology 自体の考え方は今後ますます重要になっていくでしょう
その意味で、今は「Ontology を急いで本番導入する時期」というより、Ontology を活かせる状態を作るための準備期間だと考えるのが良いのではと思います。
加えて、Ontology の構築には意外と高度なスキルが必要だとも感じています。
必要なのは単なるデータモデリングの知識だけではありません。
その組織の業務やデータが持つビジネス上の意味を理解していることと、それを構造として落とし込むデータモデリングの知識の両方が求められます。
つまり、Ontology は IT 部門だけで閉じて作れるものでも、逆にビジネス部門だけで定義できるものでもありません。
IT 側とビジネス側の協業、あるいはその両方をある程度理解している人材が重要になるはずです。
【おまけ①】Foundry IQ は既に現実味がある
補足すると、私の体感では Foundry IQ のほうが、現時点ではより現実味があるように見えました。
たとえば、
- OneLake をナレッジソースにする
- SharePoint をナレッジソースにする
といった使い方は、今すぐ検証イメージを持ちやすいです。
Fabric 側の Ontology はまだ「将来かなり面白くなりそう」という段階に見える一方、Foundry 側はすでにユースケースを描きやすい印象がありました。もちろん両者は競合ではなく、今後つながっていく領域だと思います。
【おまけ②】Data Agent 開発は CI/CDと相性がいい(Git統合すべき)
これは Ontology とは少し離れますが、FabCon を通して改めて感じたのは、Data Agent は CI/CD と相性がいいということです。
みなさん、Fabric の Git 統合は活用しているでしょうか。
Data Agent の開発では、先に紹介したように、指示文、データソースの説明、事前クエリセットなどを定義していきます。
このうち、データソースの説明はそこまで頻繁には変わらないかもしれません。
一方で、指示文や事前クエリセットは、実際に使い始めると継続的に育てていく性質が強いと感じます。
たとえば、
- ユーザーから想定外の質問が来て、「このパターンに対応するクエリセットを追加したい」となる
- 指示プロンプトを調整したら、逆に精度が下がってしまった
- 以前のバージョンに戻して挙動を確認したい
- 前のバージョンと最新バージョンを比較しながらテストしたい
といったことは、実運用ではかなり起こりそうです。
つまり Data Agent は、一度作って終わりの設定ではなく、運用しながら継続的に改善していく対象だと思います。
だからこそ、変更履歴を管理できて、差分を追えて、必要に応じて戻せる Git 統合との相性がとても良いわけです。
Fabric で Data Agent を本格的に活用していくなら、単にエージェントを作るだけではなく、Git 統合を前提に育てていくという考え方が重要だと考えます。
▽関連記事
Microsoft Fabric Git統合 × Azure DevOps -別テナント間でFabricアイテムをリリースする方法-
Azure DevOps Pipelineで別リポジトリへ反映する方法:Repo A→Repo Bの最小構成メモ
まとめ
最後に、現時点での私の整理をまとめます。
- Fabric IQ / Ontology への期待値は高い
- ただし、現段階ではまだ preview であり、本番環境で使うには慎重に見たい
- 多くのケースでは semantic model と data agent の組み合わせがかなり有効
- そのうえで Ontology が刺さるのは、
- 多層リレーションを横断する問い合わせ や
- 蓄積データとリアルタイムデータを1つの業務文脈で扱うケースなど
今後 Microsoft が力を入れていく領域であることは間違いなさそうなので、今のうちにキャッチアップしておくことや、Ontologyをいち早く導入するために組織のデータ基盤の整備をして準備をする段階だと思います。
長くなりましたが、ここまで読んでくださりありがとうございました!
Youtubeもやってます!
FabricやDatabricksについて学べる勉強会を毎月開催!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページへ移動後、申し込み可能です!