※随時若手目線でFabricとDatabricksとSnowflakeの違いが分かってきたら追記します。
※一部生成AIを使用して記事を作成しているため、必ずしも情報が正しい保証はできかねます。ご了承ください。間違っている点ございましたら、コメントお願いします!
この記事は、
- 初心者の方にとっては必見の内容です。
- どちらか一方に精通している方も、比較の視点が得られるはず。
- そして、既に両方のスキルをお持ちの方にとっては少し物足りないかもしれませんが、 「部下や初心者がどんな視点で見ているのか」を知る参考になるかと思います。
Microsoft Data Analytics Day(Online) 勉強会にて発表してきました!
Microsoft Data Analytics Day(Online) 勉強会にて
「Microsoft Fabric vs Databricks vs (Snowflake):若手エンジニアがそれぞれの強みと違いを比較してみた」というタイトルで発表をしてきました!以下も併せてご覧ください。
▽資料
▽アーカイブ
▽毎月開催!Microsoft Fabricの勉強会(Microsoft Data Analytics Day(Online) 勉強会)
ぜひご参加ください!
▽忙しい方には「ながら聞き」で学習できるpodcastバージョンもおすすめです。
はじめに
データエンジニアとして未経験で入社して約1年、少しずつ業務にも慣れ、FabricやDatabricksを業務で扱っています。(ときどきSnowflake)
私は今、いわゆる“ビジネス寄り”と“エンジニア寄り”のちょうど中間くらいのポジションにいて、どちらの視点もある程度理解できるようになってきたかなという実感があります。
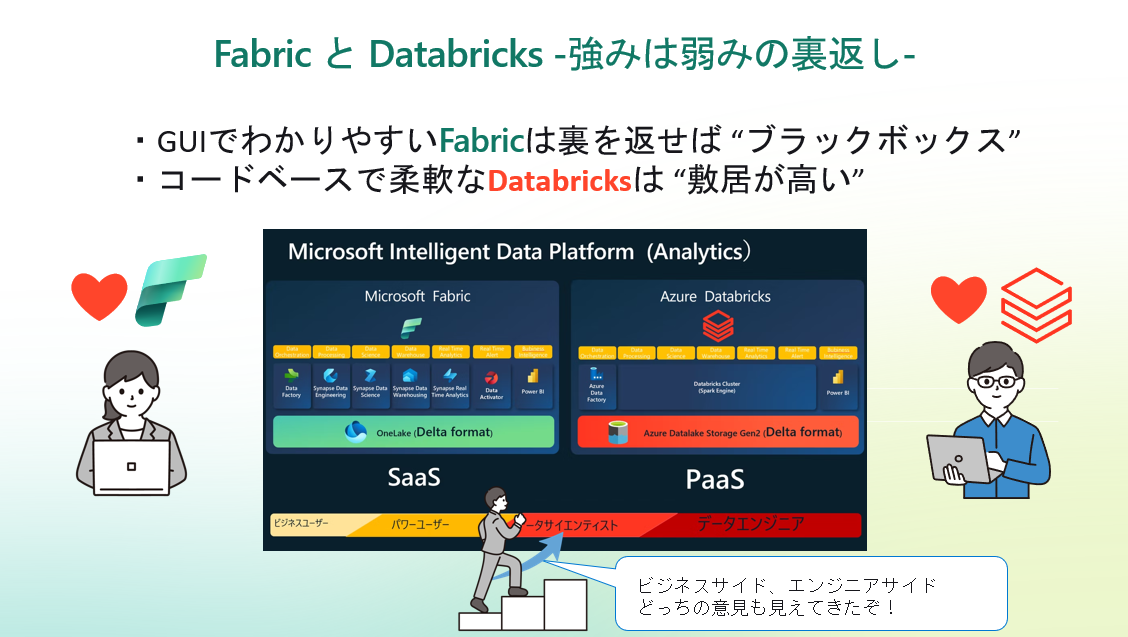
だからこそ見えてきたのが、FabricとDatabricks、それぞれの強みが裏返すと弱みにもなるということ。
- GUIでわかりやすいFabricは裏を返せば“ブラックボックス”
- コードベースで柔軟なDatabricksは“敷居が高い”
Snowflakeについても触れてはいますが、私はまだ触った回数が少ないので、やや感想ベースになります。
ただその分、初心者がどう感じるかの参考にはなると思います。
この記事では、三つのツールを比較しながら、技術的な違いや思想、実務で感じたメリット・デメリットを、若手エンジニアのリアルな視点で書いていきます。
まだまだ勉強中なこともあり、不足点ありましたら是非ご指摘お願いします🙇
なお、FabricとDatabricksは対立構造というより、同時に使うことで補完関係にあると個人的には感じています。
Delta Lakeフォーマットの互換性もあり、今後さらに連携が進んでいくことを期待しています。
▽ウェアハウスとレイクハウスの違いについてはこちら
FabricのGUIはとにかく直感的で初心者にやさしい
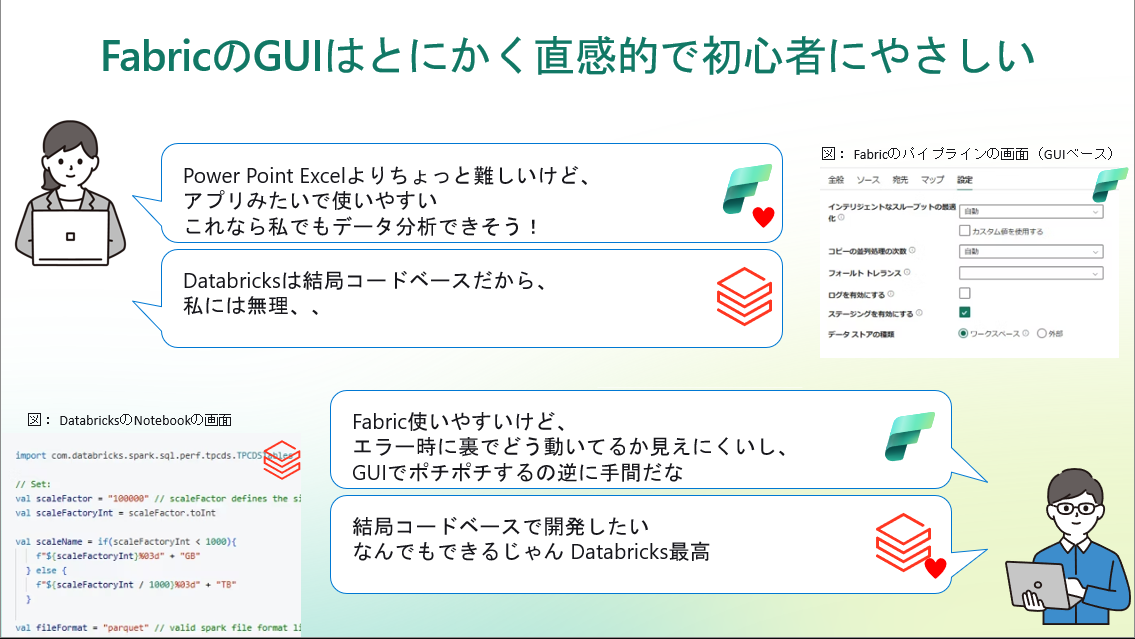
Fabricを触ってまず驚いたのは、そのGUI(グラフィカルユーザーインターフェース)の徹底した親切さです。
Power BIの延長線上にある製品ということもあり、データ分析基盤というよりも“業務アプリ”のような感覚で操作できます。
たとえば、Lakehouseの作成からNotebookの実行、Power BIへの可視化連携までが一気通貫でGUI上で完結します。
GUIベースのワークフローがしっかりしているため、非エンジニアでもデータパイプラインを組んだり、レポートを出したりが容易です。Microsoft製品に馴染みのある人なら直感的に操作できるでしょう。
一方で、この“簡単すぎる”UIは、エンジニアから見ると「裏側が見えにくい」「何がどう動いているかブラックボックス」という印象を持つかもしれません。
実際に、Fabricに慣れてきたころには「もう少し細かく制御したいな」と感じる場面もありました。
Databricksの場合、ノートブック自体は使いやすいものの、クラスターの設定やジョブの作成などでどうしても事前知識やコードベースの操作が必要になります。
最初にDatabricksを触ったときはクラスタ設定項目の多さに戸惑いましたが、Fabricではそうしたインフラの存在を意識せずに始められました。
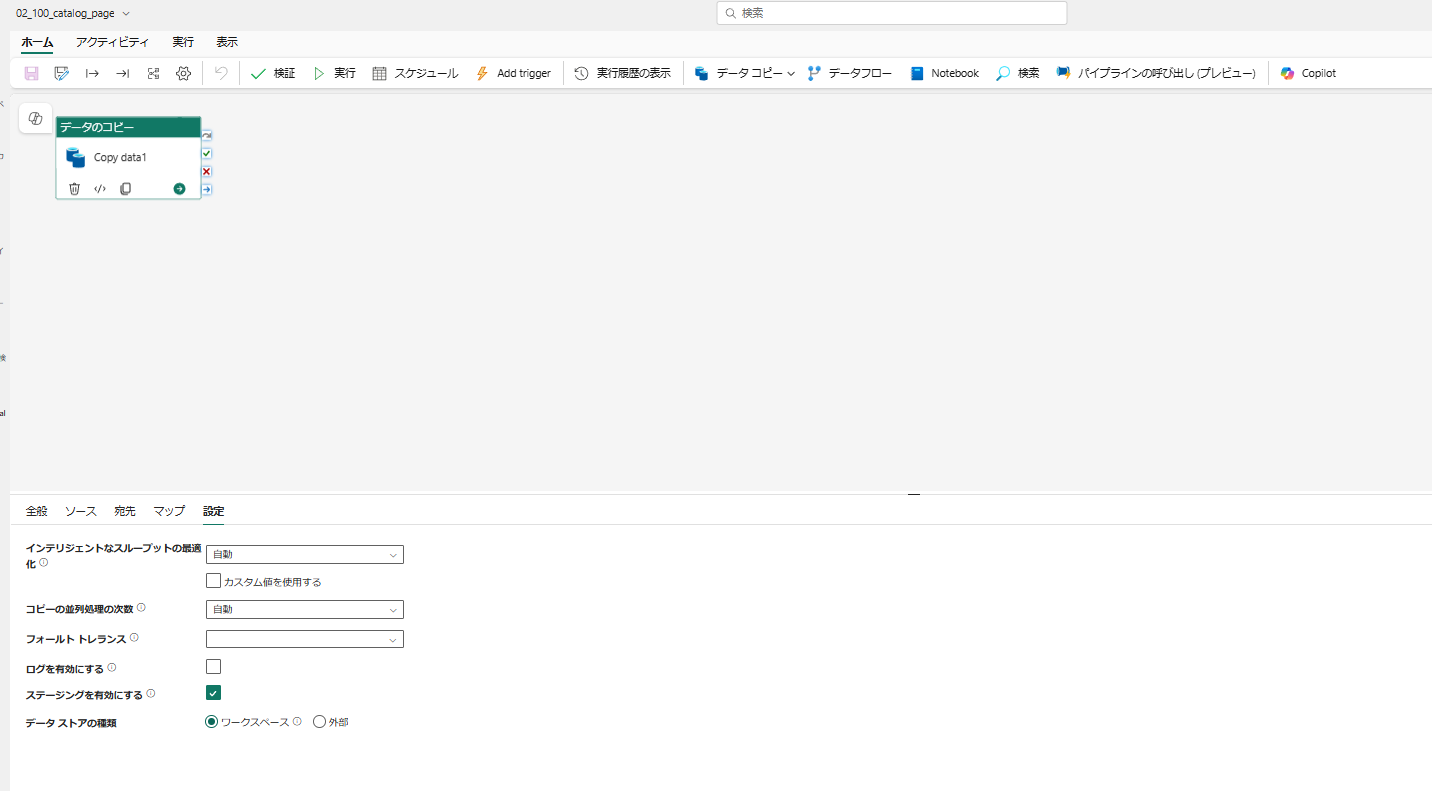
▽Fabricのパイプラインの画面
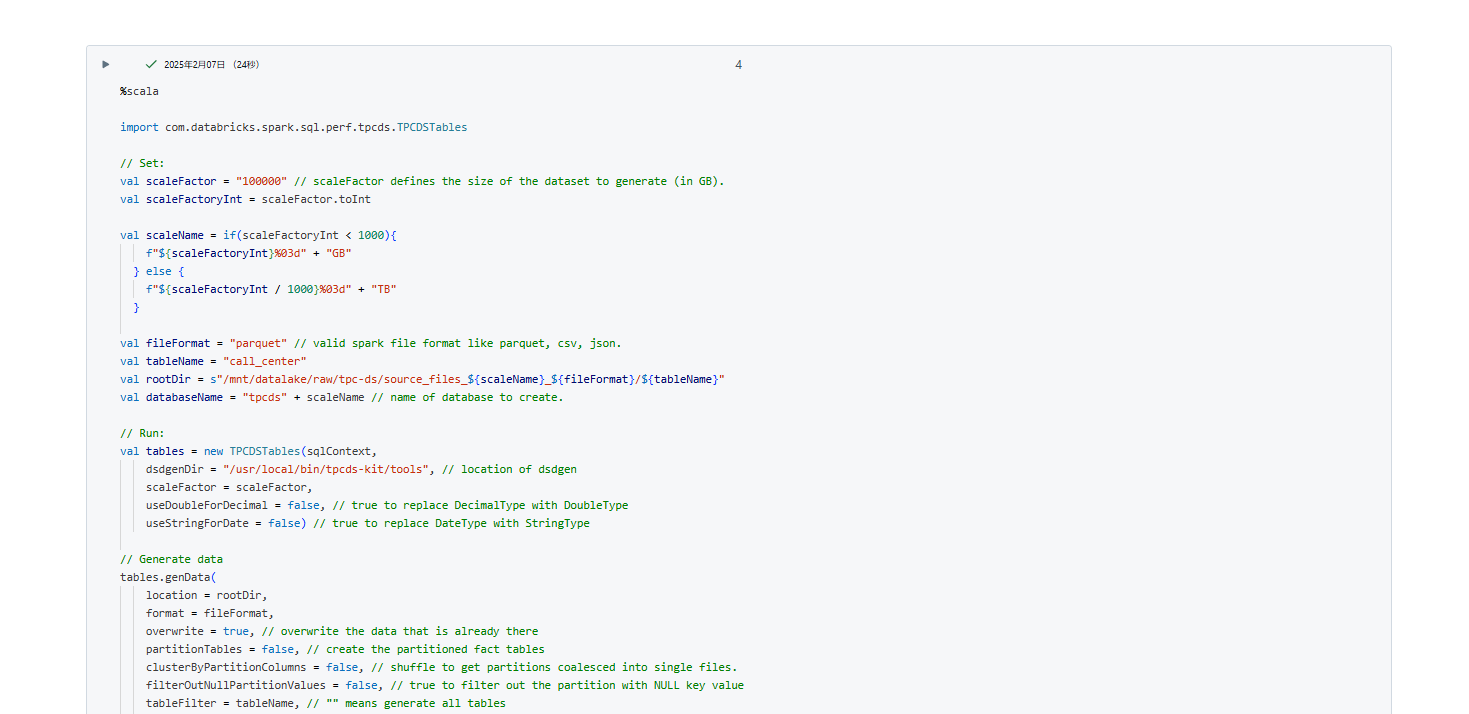
▽Databricksのノートブックの画面
機能が多いFabric、シンプルなDatabricks。それぞれの設計思想の違い
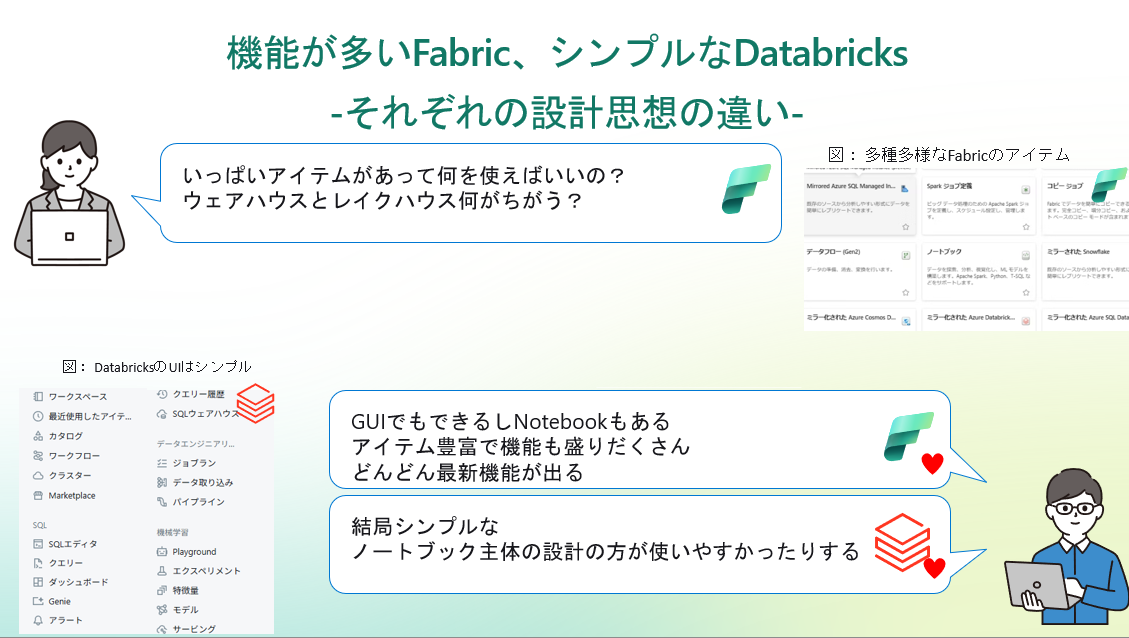
Fabricは「全部入り」のデータプラットフォームだけあって、機能が盛りだくさんです。
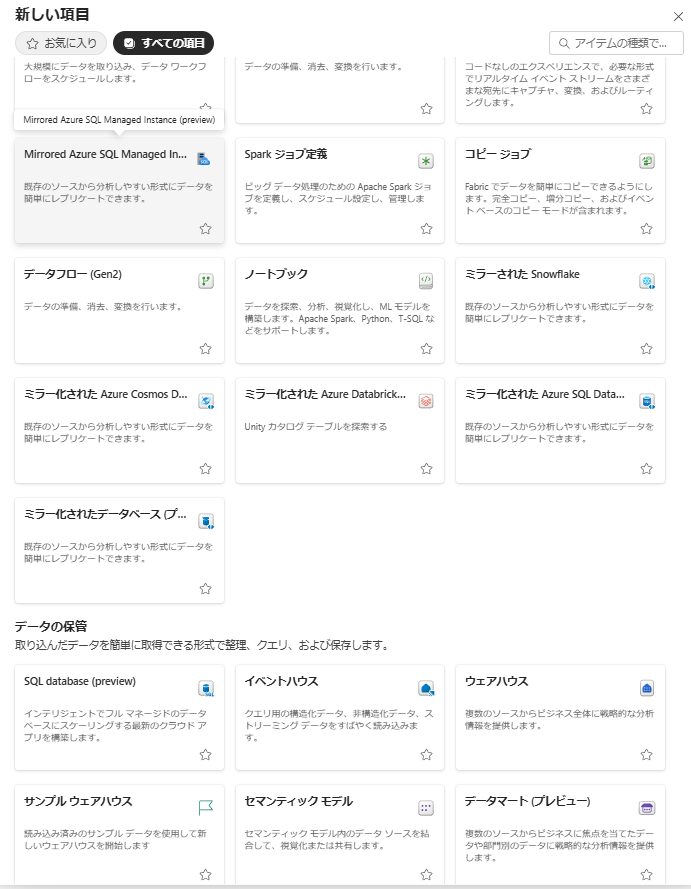
ワークスペース内にはデータエンジニアリング、ウェアハウス、リアルタイム分析など用途別のメニューが並んでおり、GUIでできることは多岐にわたります。
その反面、初見ではややごちゃついた印象も受けました。それゆえに「どれを使えばいいのか迷う」みたいなことも起こります。
一方、Databricksは提供する機能を絞り込み、シンプルなノートブック主体の設計になっています。
もちろんDatabricksでも高度な処理は可能ですが、その核となるのは「Sparkでデータを処理しDelta Lakeに蓄える」という一貫した流れで、サービス内の構成も分かりやすくまとまっています。
例えばFabricにはノーコードETLのDataflowやPipelineが内蔵されていますが、複雑な処理になるとかえってフローが煩雑になりがちです。
その点、Databricksならコードでロジックを組む分、処理の構造を自分でコントロールできてシンプルさを保ちやすいと言えます。
多機能ゆえの混み入った感じと、機能の絞り込みによる洗練さ――両者の開発体験にはそんな対比があるように感じました。
▽Fabricにはたくさんのアイテムがある。スクリーンショットのものだけでなく、それ以上に存在する。
コンピュートについて - Fabricの自動化 vs Databricksの柔軟な設定、どちらが使いやすい?
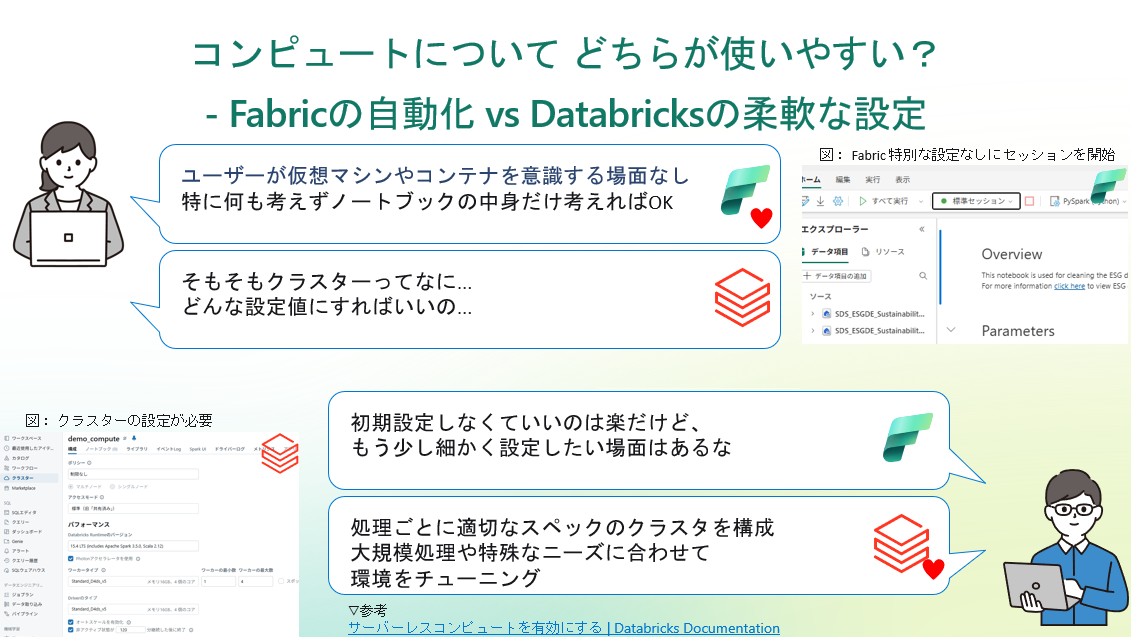
FabricとDatabricksのアーキテクチャを比べると、根底にある“インフラとの向き合い方”の違いが見えてきます。
FabricはSaaSサービスだけあって、ユーザーが仮想マシンやコンテナを意識する場面がほぼありません。
初心者や、細かいリソース設計に興味のないユーザーには非常に親切です。
Sparkジョブを実行するときも「どのサイズのマシンを何台用意するか」を指定する必要はなく、Fabric側がキャパシティ内で自動的にリソースを割り当ててくれます。
裏側では当然Sparkクラスタが動いているはずですが、その存在を感じさせない設計です。
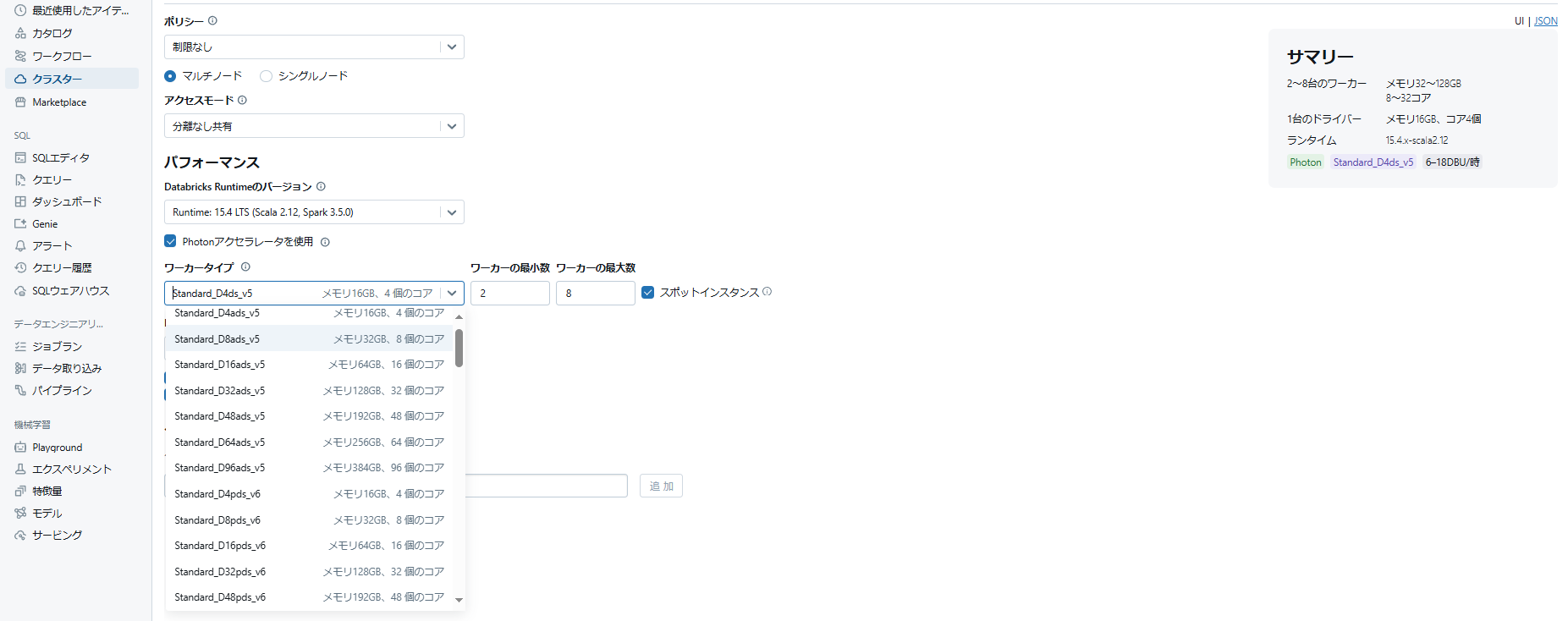
一方のDatabricksでは、自分でクラスターを定義してからジョブを動かすのが基本です。ノード数やインスタンスタイプを選び、場合によってはSparkの設定も微調整できます。
ノードタイプ、オートスケーリング、ドライバ/ワーカーの設定など、初心者からすると正直「何をどうすればいいの?」ってなります。
自由度が高い分、最適な構成を自ら考える必要がありますが、大規模処理や特殊なニーズに合わせて環境をチューニングできるメリットがあります。
「すべてお任せでシンプルなFabric」と「手動で作り込めるDatabricks」という形で、クラウドサービスとしての思想が対照的だと言えるでしょう。
▽Databricksのクラスター作成画面。初心者からするとハードルが高い。
2025/3/31追記
ちなみに最近は、Databricksにもサーバーレスコンピュートが登場しています
▽参考
サーバレスコンピュートに接続する
AWS東京リージョンにノートブック用サーバレスがやってきました!
これまで「クラスタの設定が難しい」と感じていた人にとっては、サーバーレスで使い始められるのは大きなハードルの低下になると思います。
ノートブックやジョブ、DLTの実行でもクラスタ構成を気にせずに始められるのは、正直かなり快適です。
「とりあえず気軽に試したい」ときはサーバーレス、「もっと細かくチューニングしたい」ときは従来のように自分で設定、というように使い分けができるのもエンジニア目線ではありがたいポイントですね。
※なお、ノートブック/ジョブ/DLTでサーバーレスを使うには、アカウント管理者による有効化が必要です。詳しくは Enable サーバレス コンピュートを参照してください。
大規模バッチ処理はDatabricksに軍配、Fabricは制限に注意

小規模な検証ではFabricもDatabricksも遜色なく動作しますが、スケールが大きくなると両者の違いが見えてくるかもしれません。
Databricksは元々ビッグデータ処理で定評があり、必要に応じて大規模なクラスターを構築して膨大なデータを並列処理できます。大規模なデータ処理、特にSparkベースのバッチ処理においては、Databricksの方が安定しています。自由なクラスタ設計ができるため、大量データの並列処理や、ETLジョブの高速化が実現しやすいです。
対してFabricはサービス自体が新しく、極端にヘビーなワークロードでは苦戦する可能性もあります。
例えばメモリを大量に使う処理で、Databricksならワーカーのスペックを上げる等の対策が取れますが、Fabricではそこまで細かな調整は現状できません。
現状ではTB級のロードなどで、スロットリング(リソース制限)がかかることもあり、大きなワークロードを流すと途中で止まる/待たされるといった問題が起きることがあります。
Fabricはどちらかというと、分析や可視化を前提にした“軽め”の処理に向いている印象です。
ガッツリ大規模処理したいならDatabricksの方がストレスなく運用できると思います。
2025/4/9追記
最近、FabricでもDatabricksのように従量課金制で使える「オートスケール課金(Autoscale Billing)」がSparkワークロード向けに導入されました。
これはつまり、Fabricのキャパシティとは別にサーバーレスのSparkコンピュートを立てて処理できるようになるという仕組みです。
たとえば、これまでだとFabricの容量(キャパシティ)内で重い処理を走らせた場合、スロットリングが発生してしばらく他の操作ができなかったり、同じ容量を使っているレポートすら見れない…という状況が起きることもありました。
今回の新機能では、従量課金で別のSparkリソースを使うことでそういった状況を回避できる可能性があります(もちろんその分コストは追加でかかります)。
個人的にはこれは結構嬉しいアップデートで、Fabricでも「重い処理をガンガン回す」ような使い方がしやすくなってきたと感じています。
初心者向けというよりは、ある程度Fabricを使いこなしている中~上級者向けの機能かもしれませんが、開発や検証の自由度が上がるのはありがたいですね。
Fabricの料金体系は分かりやすいが、コストがかさみやすい場面も

Microsoft Fabricの料金モデルは、一見シンプルです。
Power BI Premiumのようにキャパシティ単位(Capacity Unit)でリソースを購入し、その範囲内でFabricの各機能を使い放題という形になっています。
細かなリソース別の課金を気にせずに済む反面、必要なキャパシティを確保するには相応の予算が必要です。
特にエンタープライズ規模で大量のデータ処理や多数のユーザーを支えようとすると、十分な容量をまかなうために高額のプランが必要となり、コストインパクトが大きく感じられるでしょう。
一方のDatabricksは、より従量課金に近いモデルです。
クラスターの稼働時間や選択したVMタイプに応じて料金が発生し、使わないときはクラスターを停止してコストを抑えることができます。
価格体系自体はFabricに比べると複雑(ワークロード別のDBU課金など)ですが、その分利用状況に合わせて柔軟にコストコントロールが可能です。
「単純明快だけど大雑把なFabric」と「細かく調整可能だけど複雑なDatabricks」という対照的な印象を受けます。
自社の利用パターン次第で、お得さも変わってきそうです。
Fabricのショートカットとミラーリング機能はかなり便利

Fabricの独自機能で特に気に入っているのが、OneLakeショートカットとミラーリング機能です。
ショートカットでいえば、これはOneLakeというFabricのストレージ基盤から、他の外部ストレージ
ADLSだけでなく、 Amazon S3、Google クラウドストレージなどを
仮想的にリンクさせて、まるで同じ場所にあるかのように扱えるという仕組みです。
やはり、わざわざデータをコピー・再ロードせずに済むことはFabricのかなりの強みかと思います。
このあたりの“統合志向の工夫”はさすがMicrosoftという印象を持ちました。
一方、Databricksでも外部テーブルとしての取り扱ってunity catalogで一元管理というのはできますが、
毎回外部テーブルとして指定してやらないと行けなかったりするので、テーブル数が多い場合や管理が複雑になるケースでは、
Fabricのショートカット機能の方が圧倒的に楽だと感じます。
正直、これがあれば仮想ビュー製品(例:Denodoなど)を導入しなくても済むケースも多いのでは?と感じています。(Denodoあまり詳しくないのであくまで感想です🙇)
Fabricのノートブックは通知が来ないのが地味に不便
FabricにもDatabricks同様にNotebook機能がありますが、現時点(2025年3月)では実行完了のブラウザでの通知機能がありません。
長時間かかるNotebookを実行したまま別作業をしていたとき、「あれ、終わった?」と自分で確認しに行く必要があるのは地味にストレスです。結果を知るにはポータルを開いてステータスを確認する必要があり、「いつの間にか失敗していた…」なんて事態になりかねません。
(Fabricでもノートブックをパイプラインに組み込めば、通知は来ますが、少し手間、、)
Databricksでは標準で、ウェブブラウザにノートブックの結果の通知が来ます。
Appendix:Snowflakeの立ち位置はどこにある?レイクハウスではなくウェアハウスとしての魅力と限界
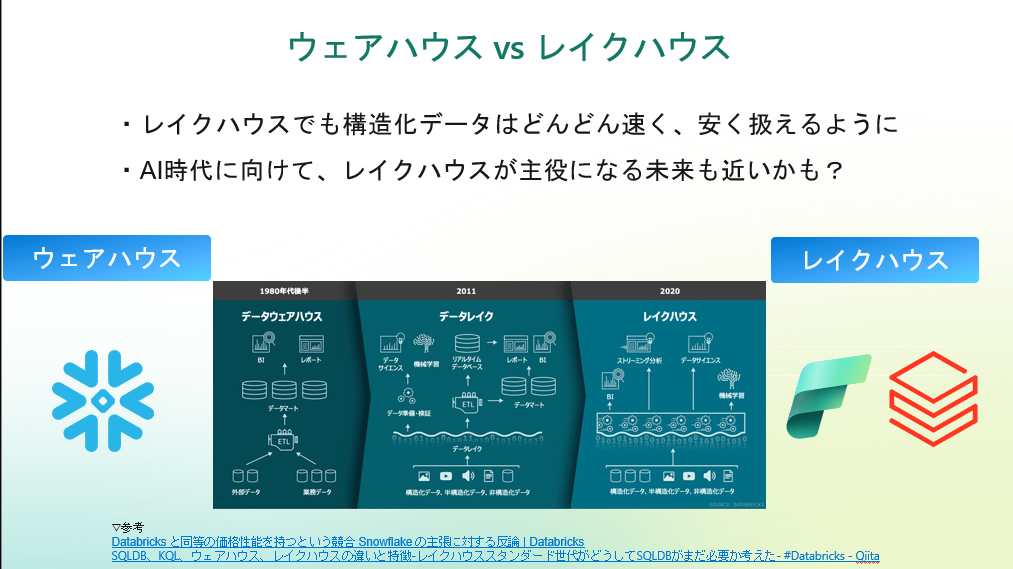
最後に、FabricやDatabricksとはアプローチが異なるSnowflakeについて触れてみます。
Snowflakeはクラウド型の純粋なデータウェアハウスで、いわゆる“レイクハウス”ではありません。
データをSnowflakeのストレージに取り込み、SQLで分析することに特化した設計で、その分野では抜群の使い勝手と性能を発揮します。
大規模データへの高速SQLクエリや高い同時実行性能など、企業のBI基盤として大きな利点があります。
私も初めてSnowflakeを使った際、その手軽さとクエリ速度に驚いたものです。
また、実行状況が「何%完了」などの形で可視化される点も、FabricやDatabricksにはない細かい配慮として好感を持ちました。
ただし、現時点でSnowflakeはレイクハウス構成ではなく、あくまでウェアハウス中心の思想です。
また機械学習や超大規模データ処理のワークロードをSnowflakeだけで完結させるのは難しく、その場合は別途Sparkプラットフォームなどとの併用が必要でしょう。
総じてSnowflakeはレイクハウス全盛の昨今でも「強力なウェアハウス」としての地位を占めており、それが最大の魅力ですが、FabricやDatabricksが志向するオールインワンの世界とはベクトルが異なる存在だと感じます。
▽ウェアハウスとレイクハウスの違いについてはこちらでわかりやすくまとめてみました!
Appendix:各社の顧客数(2024年6月、2025年3月時点)
Fabric(2025年3月):19,000+

▽参考
https://www.youtube.com/watch?v=bI6m-3mrM4g&t=1002s
Databricks(2024年6月):12,000+
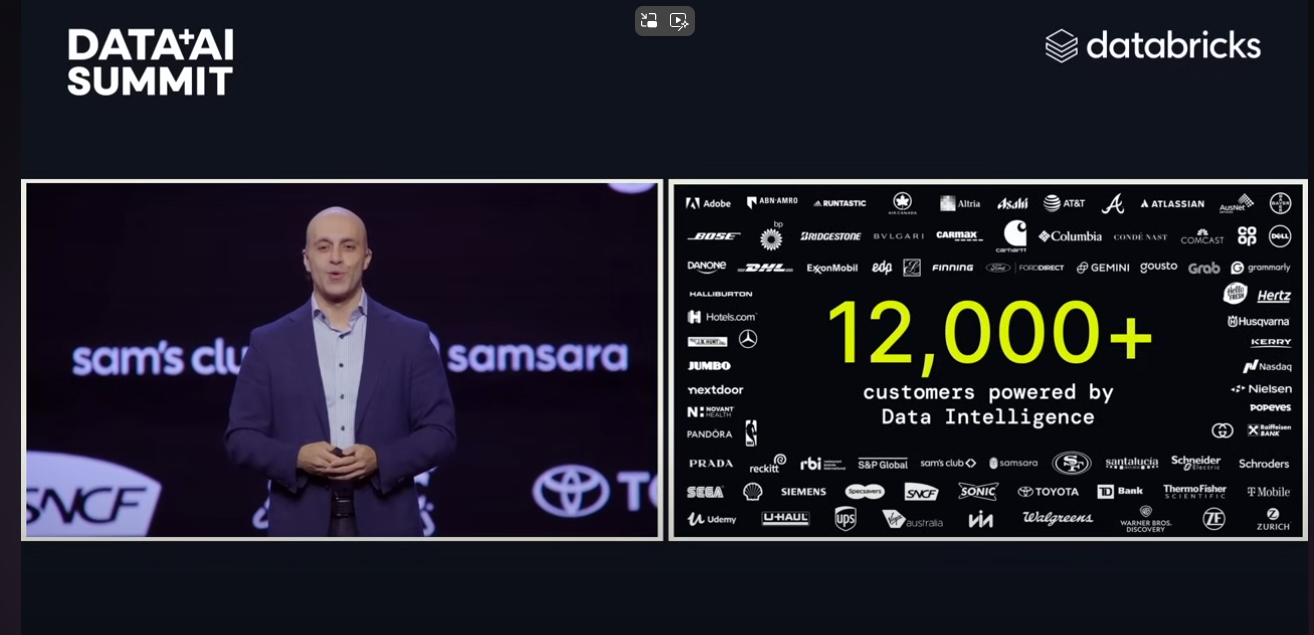
▽参考
https://youtu.be/-6dt7eJ3cMs
Snowflake(2024年6月):9,800

▽参考
https://youtu.be/KXg-HGfMCzY
まとめ:使う人の立場で“優しさ”は変わる

Fabric、Databricks、Snowflake。それぞれのツールに“使いやすさ”はありますが、その意味はユーザーの立場によって大きく異なります。
-
Snowflake:明快なUIとシンプルな構成で誰でも扱いやすいDWH
-
Fabric:ビジネスユーザーにも開かれたオールインワン基盤
-
Databricks:エンジニアが最大限力を発揮できる柔軟性と性能
ツールを比較するとき、“どっちが優れているか”ではなく、「誰にとって優しいか」という視点を持つと、より現実的な判断ができると感じました。
今回、比較してみたものの、
結構製品によってターゲットユーザーとの親和性だったりとか、ベストなシチュエーションが違ったりもするので、
絶対に1つに決めなきゃいけないとは私は思っていません。
例えば、営業部はFabric、情シスはDatabricksみたいな運用もありだと思いますし、
そういう会社さんもあるのかなと思います。
▽FabricとDatabricksの相互運用性についてはこちら
▽DatabricksとSnowflakeの相互運用性についてはこちら
今後もFabricとDatabricksを実務で触れながら、Snowflakeも含めてさらに理解を深めていきたいと思います。
随時この記事にも追記していく予定なので、よければQiitaフォローやコメントなどお待ちしています!