この記事でわかること
Fabricミラー化データベース(Open Mirroring) の[アップロード済みのファイル]から[OneLakeのテーブル]に連携がいくら待ってもされないときの解決方法
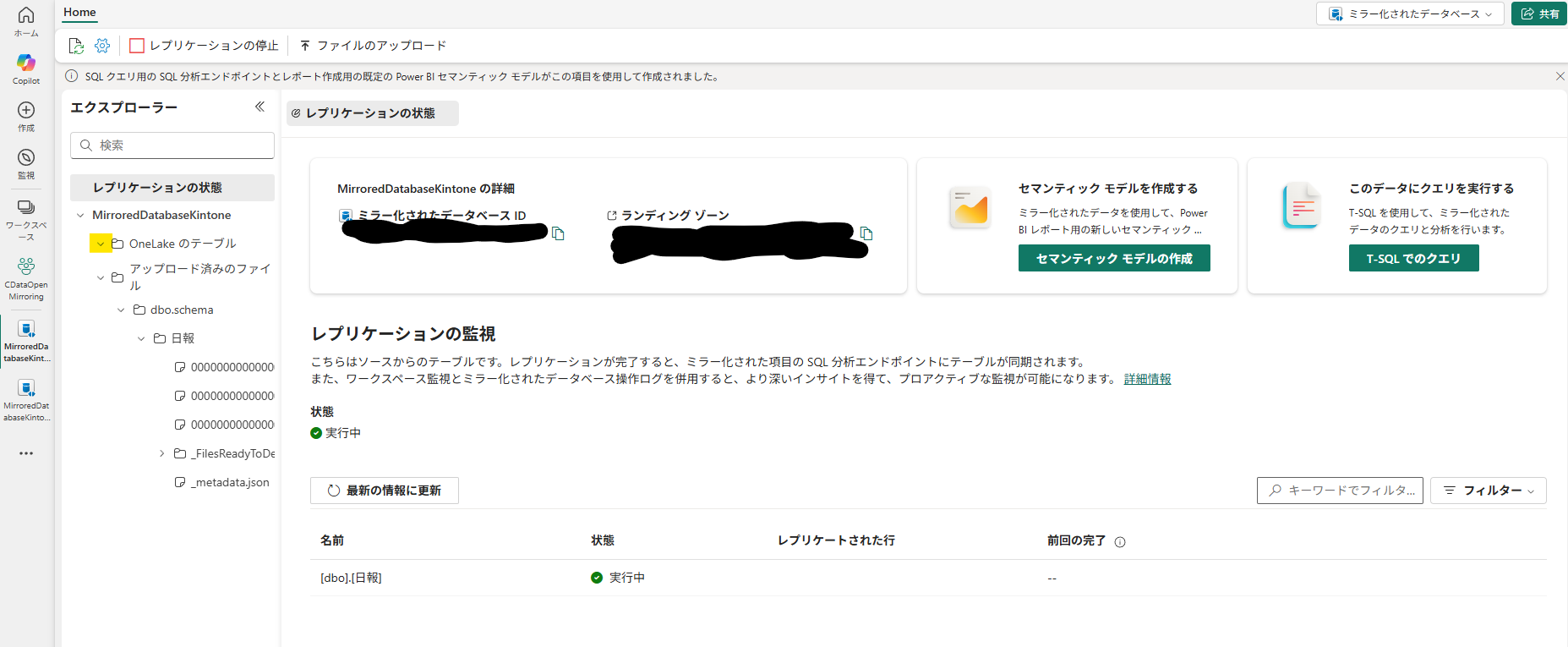
状況・前提:ファイルはあるのにテーブルが生成されない
[アップロード済みのファイル]にはParquetファイルや_metadata.jsonが連携されているのに
いくら待っても [OneLake のテーブル] 領域に Delta Table が反映されないケースがあります。
今回の環境では CData Sync を利用して Kintone のデータをミラーリングしていました。詳細な設定手順は以下の記事を参照ください。
原因:日本語列名
原因は 列名に日本語を使用していること だと考えられます。
詳細な原因は以下の記事あたりだと思っています。
Fabricの基本的なアイテムの列マッピング(Name)は[Yes]になっていますが、
ここのラインナップにミラー化データベースがない点が気になります。
解決策:列名を英語に変換する
結論としては、Parquet ファイルを配置する際に列名を英語に変換することで解決できます。
今回の場合は CData Sync を使っていたので、ソースシステム(今回は Kintone)の列名を直接変更することなく、CData Sync 上の処理だけで対応できました。
ソースシステムをいじれないケースもあると思うので、こういうときに CData は本当にありがたいです。
実際の対応手順
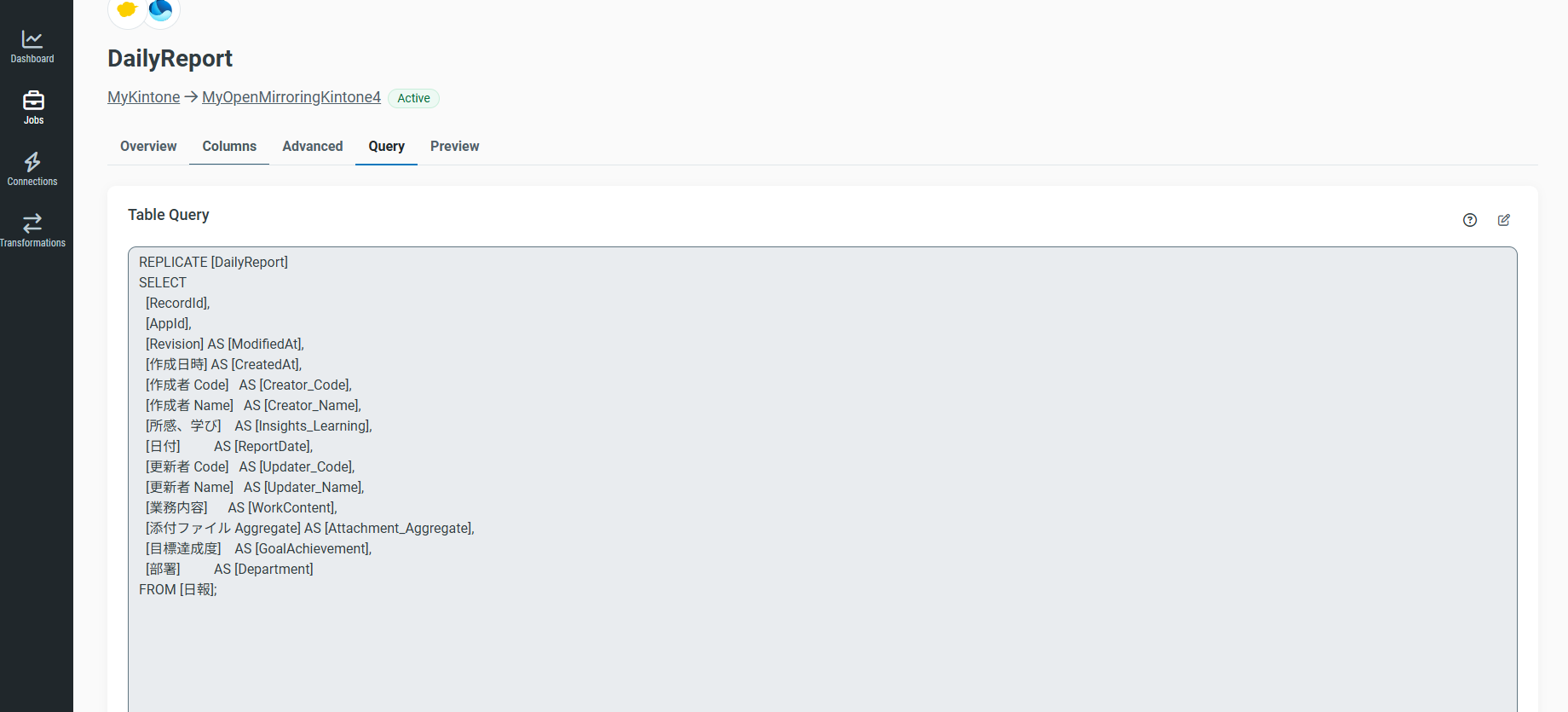
CData syncの対象のジョブの[Task]から対象のテーブルをクリックします。

[Query]からSQLを編集し、AS句を使って英語列名を付与していきます。
💡その他注意点
-
空白を含む列名(例:
[作成者 Name])は CData 側でエラーになります。
→[作成者_Name]のようにアンダースコアなどで空白を避ける必要があります。
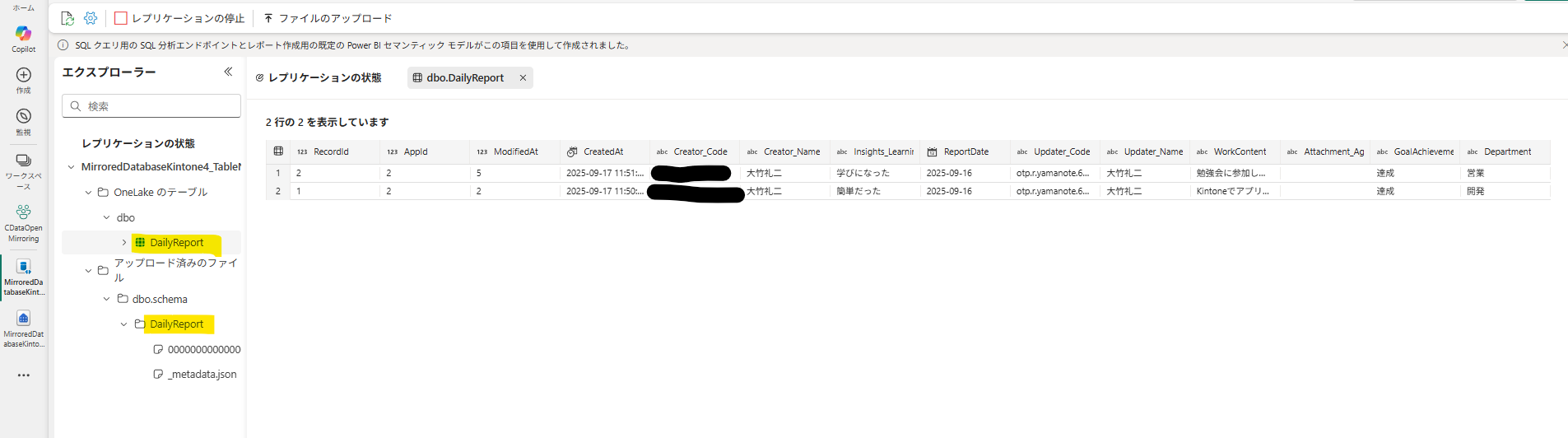
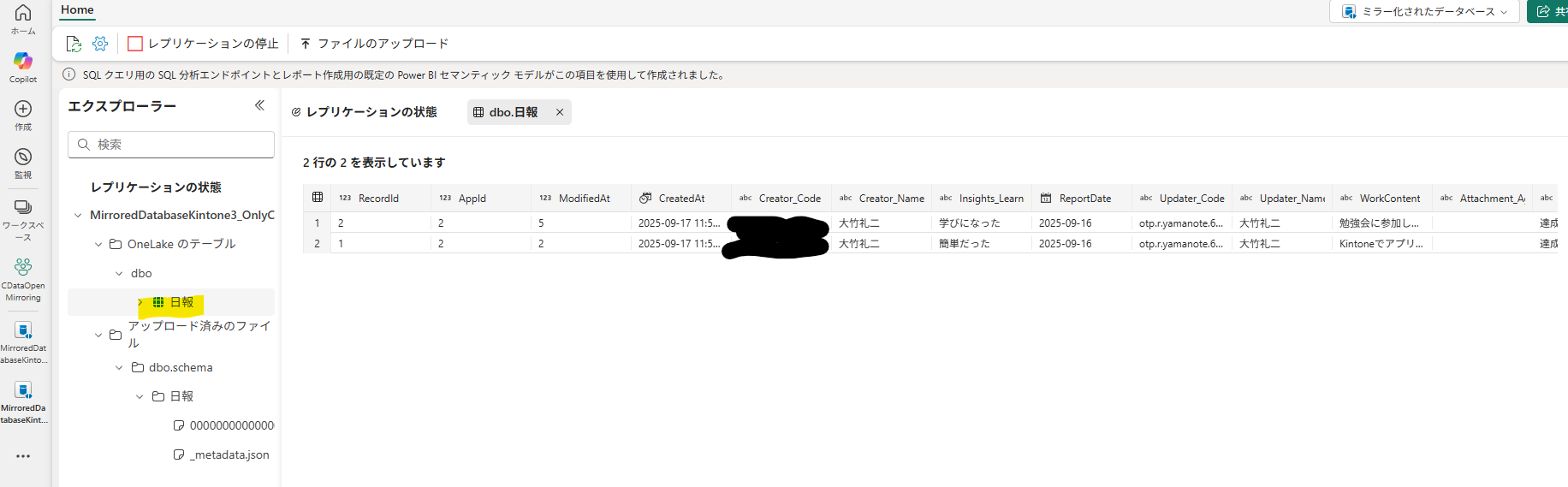
対策後の挙動:無事にテーブルが同期された
CData で再実行したところ、無事に [OneLake のテーブル] 領域に「日報」テーブルが同期されました。
レプリケーションの速度について
今回の場合、
- ファイル領域への反映 → 即時
- テーブル領域への反映 → 約 2 分
さらに、列名を英語にしておけば、テーブル名は日本語のままでも問題なく反映されます。
おわりに
Fabric と CData を組み合わせたミラーリングは、本当に強力で魅力的な仕組みです。
「データを取り込むために複雑な ETL を組む必要があるのでは?」と思われがちですが、CData を使えば GUI ベースの設定だけで SaaS やオンプレ DB から簡単に Fabric へ連携できます。
特に、今回のように ソースシステムの列名を直接変更できないケースでも、CData 側で柔軟に変換・調整が可能です。これにより、現場の運用を止めずに Fabric のミラー化データベースへスムーズに連携できます。
👉 「データをもっと簡単につなぎたい」「業務データをすぐに分析できるようにしたい」と思っている方は、ぜひ一度 CData × Fabric ミラーリングを試してみてください!
関連記事もあわせてどうぞ:
Youtubeもやっているので見ていただけると嬉しいです!
FabricやDatabricksについて学べる勉強会を毎月開催しています!
次回イベント欄から直近のMicrosoft Data Analytics Day(Online) 勉強会ページ移動後、申し込み可能です!