はじめに
NW-JAWSで発表させていただいたグレー障害に備えるためのベストプラクティスとApplication Recovery Controller Zonal Shiftについて解説していきます。
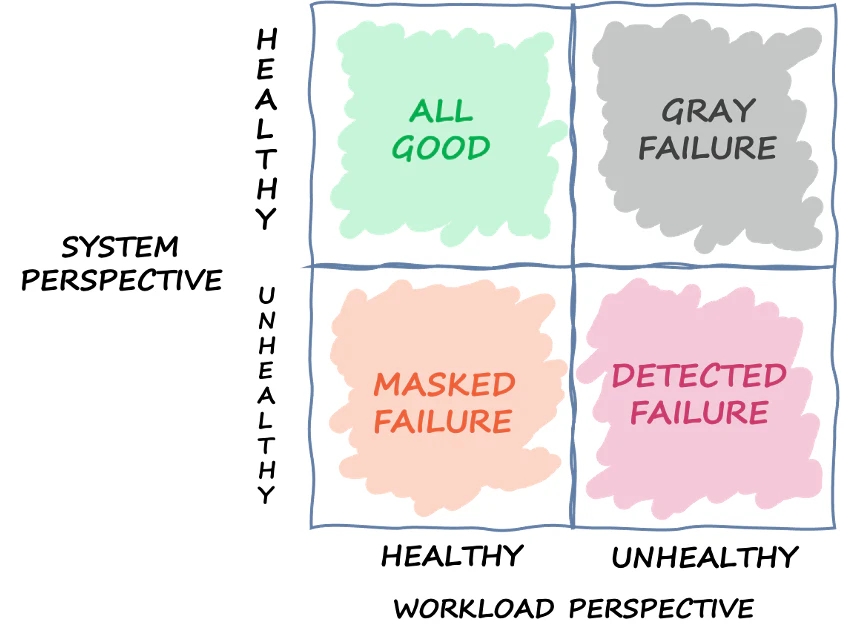
グレー障害とは?
まずは定義です。
グレー障害は、視点別のオブザーバビリティという特性によって定義されます。
これは、異なるエンティティは異なる視点で障害を観測することを意味します。
視点別のオブザーバビリティとは、システムコンシューマーの 1 つがシステムの異常を検出しても、システム自体の監視では問題が検出されないか、影響がアラームのしきい値を超えない状況のことです。
つまりグレー障害とは、システム全体で見た場合に障害とは定義されず検出されないものの、単体レベルで見た場合になんらかの異常が発生しているグレーな状況です。
こういったことは結構あるのではないでしょうか。ユーザからなんかわからないけど遅いとか、繋がらないと思ってステータスを見ると異常はないように見えるという状態です。
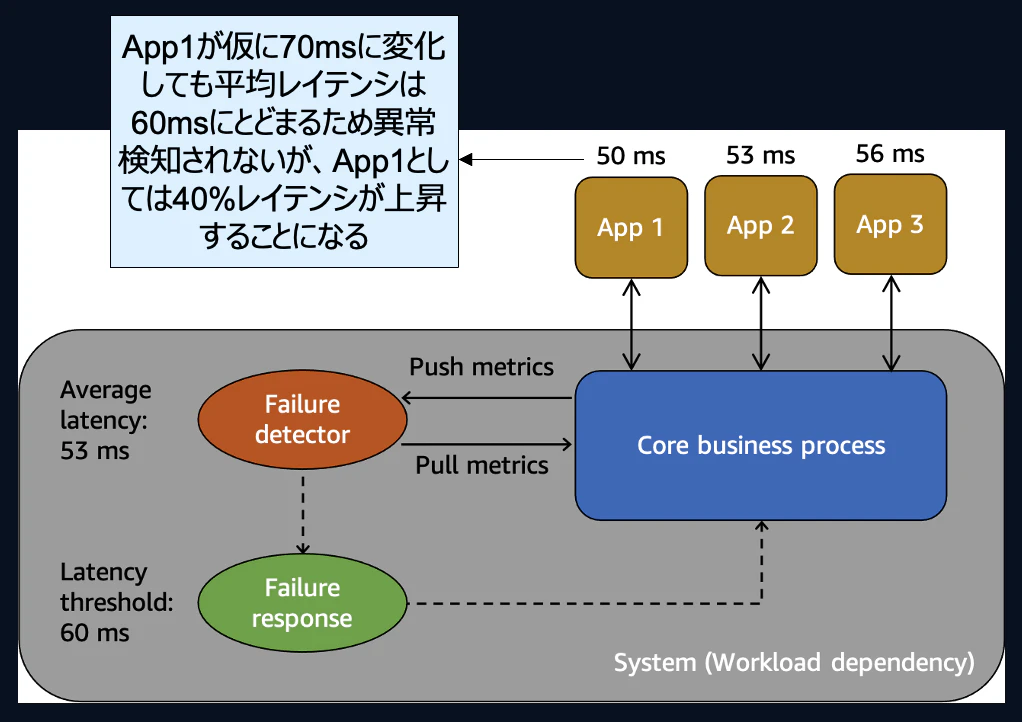
以下の図を見てみましょう。
3つのAppで構成されたビジネスロジックに対し、障害検知は平均60msで行う仕組みとなっています。
仮にそのうち1つのAppがレイテンシ70msに変化したと仮定します。その場合、平均レイテンシは、60ms以下です。そのため、障害検知はされませんが、App1を利用しているユーザからすると通常より40%もレイテンシが上昇し、ユーザ体験上異常とみなされるかもしれません。
グレー障害の例
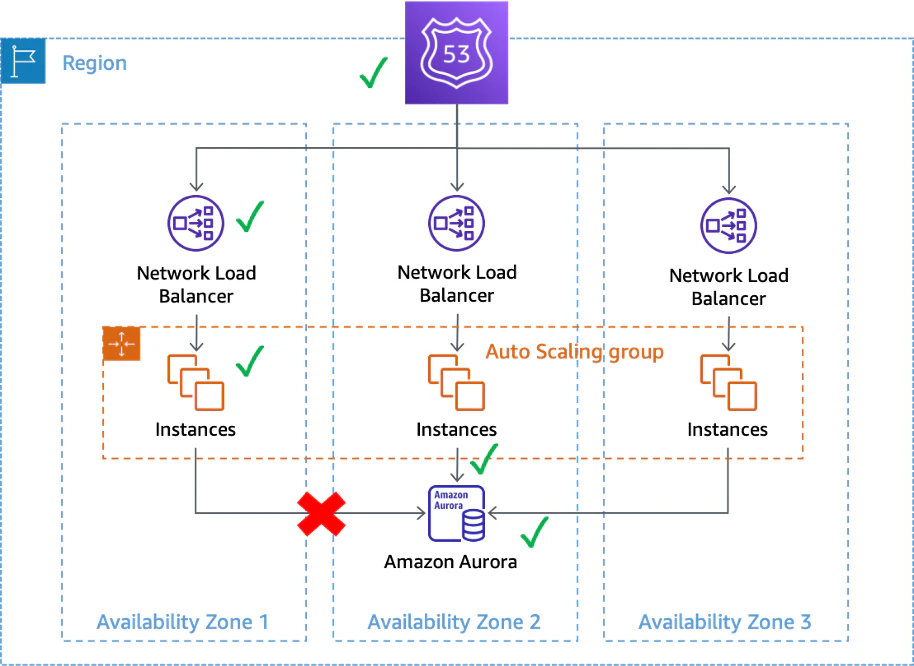
上記の例は、マルチAZ構成における1AZからのDB接続が失敗している例です。
この場合、NLBからインスタンスへのヘルスチェックは問題ないが実際には、特定のAZからインスタンスからDBへの接続ができないため、ユーザによっては正常に利用できません。また、先程の図でも解説しましたが、システムとして定義した異常とはみなされなくても、ユーザから観測した際に振る舞い上異常があれば、それはグレー障害と呼べるでしょう。
グレー障害の発生箇所
その他にも様々なグレー障害が考えられます。
障害は、以下のような障害分離境界によって発生しうるので、障害分離境界点を明確にすることが重要です。
リージョン
アベイラビリティゾーン
インスタンス、コンテナ
ソフトウェア
実例
2019年8月に発生したAWSの障害を覚えていますか?
東京リージョンの1AZで冷却システムが停止したことにより、EC2などの複数のサービスに障害が発生した事例です。ポイントは、個別のケースのいくつかで、複数のアベイラビリティゾーンで稼働していたお客様のアプリケーションにも、予期せぬ影響が観測されていたことです。当時マルチAZ構成だったとしても、観測異常とはみなされず、切り離されないこともあるのです。
きれいに、異常となってくれればよいのかもしれませんが、大抵のケースにおいて、つながったり繋がらなくなったりと、システムが異常と判断しにくい状態が、グレー障害とも呼べるのではないかと思います。


https://aws.amazon.com/jp/message/56489/
Application Recovery Controller Zonasl Shiftとは?
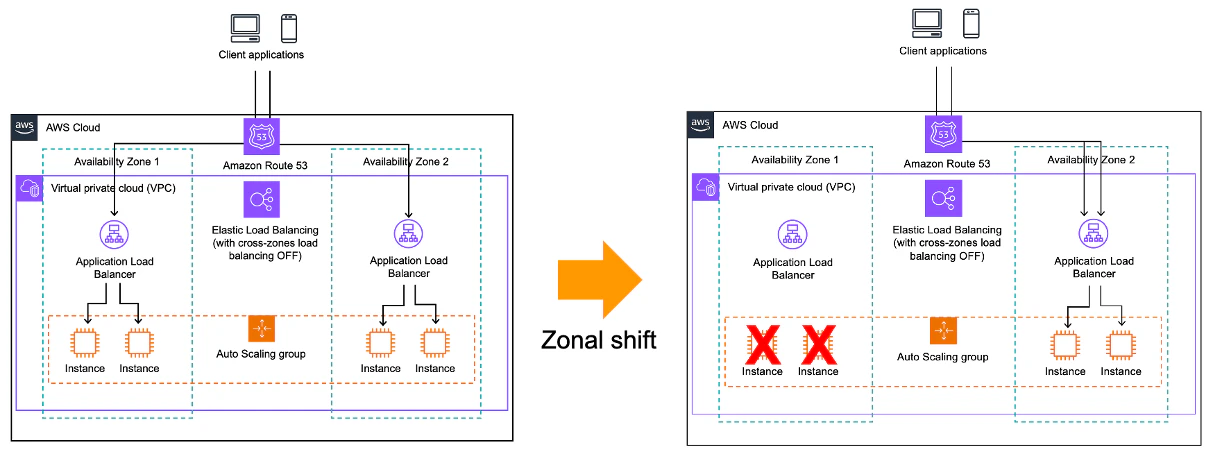
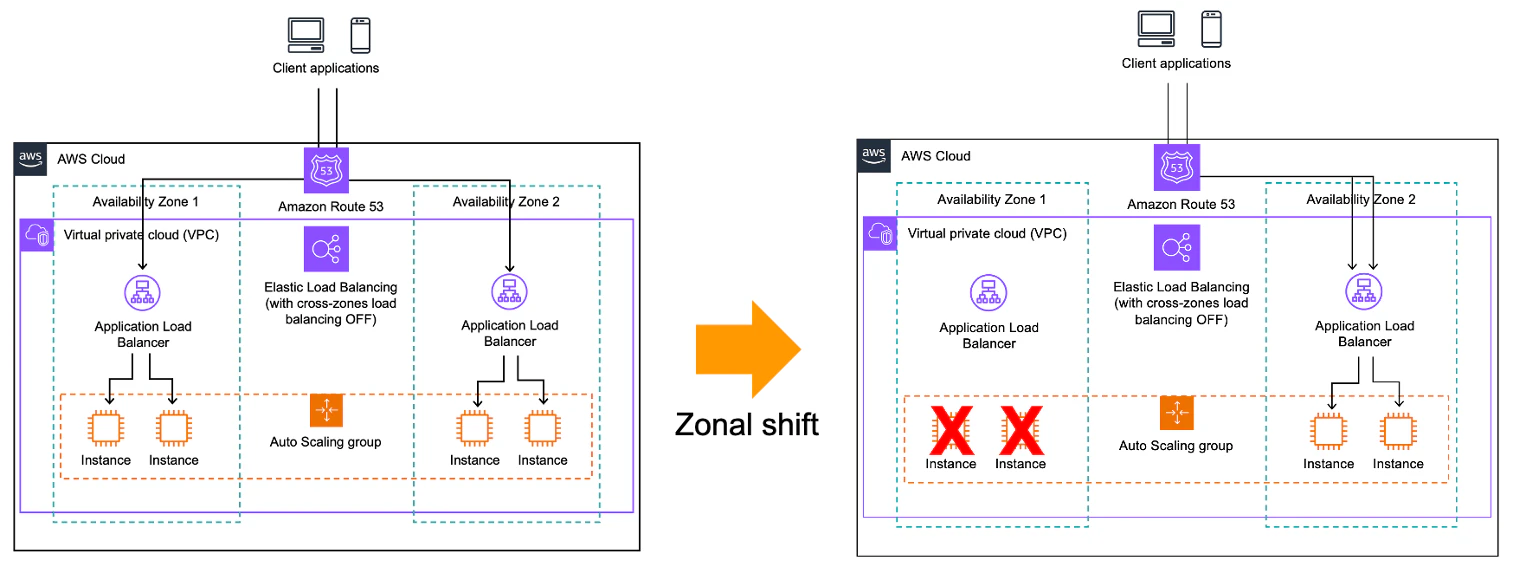
ELBの特定のAZを無効化する機能です。
以下の様に手動、自動のシフトが利用でき、アベイラビリティゾーン内のサービスを起因とした、グレー障害、障害時に有効名サービスです。
- 手動(ゾーンシフト) re:invent 2022でリリース
特定のAZの一部のインスタンスやELBなどでエラーレートや遅延が大きい等の場合に、ユーザ側起因でZonalShiftにより、特定のAZを切り離すことが可能な機能です。
実際の動作としては以下のように名前解決の仕組みを使います。
自動、手動ともに、通常時は、任意のAZに紐づくIPアドレスを返却しますが、ZonalShiftが発動すると、対象AZを排除した名前解決が行われます。

https://aws.amazon.com/jp/blogs/networking-and-content-delivery/rapidly-recover-from-application-failures-in-a-single-az/
手動の場合以下のようなコマンドを実行します。
# aws arc-zonal-shift update-zonal-shift --zonal-shift-id <zonal-shift-id> --expires-in 4h
本機能は、主にユーザ側(AWS責任外)起因のエラーに有効です。
単一AZでのグレー障害(遅延やエラーレートの上昇など)やグレー障害時の一時的な切り分け操作や調査に利用可能です。
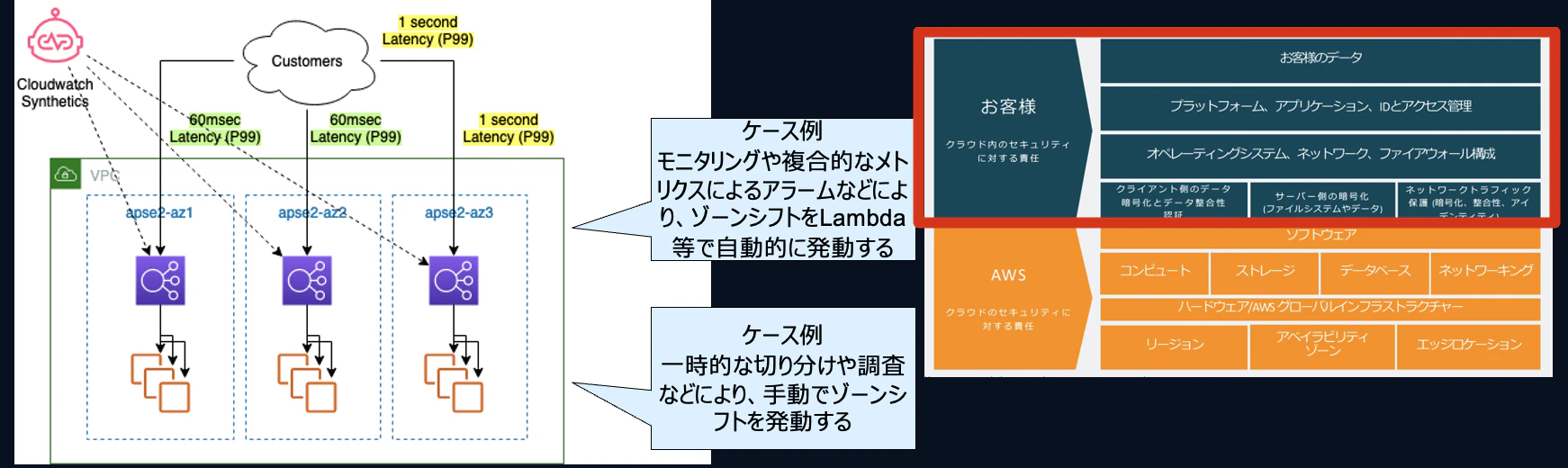
- 自動(ゾーンオートシフト) re:invent2023でリリース
AWS がそのアベイラビリティーゾーンに影響する潜在的な障害を特定したときに、自動的にゾーンシフトを行う機能です。
本機能は、AWS側起因のエラーに有効です。AWSが障害を検知した場合にAWSの判断で特定AZを切り離します。
どちらをつかえばよいか
結論:どちらを使えばいいということではなく、ターゲットが違います。
手動ゾーンシフト:ユーザ側起因のエラーに有効なので、AZごとのエラーレートなどのモニタリングとセットでゾーンシフトを発動するような仕組みを用意しておくと有用です。
ゾーン自動シフト:AWS側起因のエラーに有効なので、これを有効化しただけでは、ユーザ側起因のエラーには対応できない、とはいえ、AWS側起因のエラー時に自動的に発動するため、有効化しておくとよいです。
ゾーンシフトにおけるベストプラクティスと留意事項
ゾーンシフトが発動すると当たり前ですが、対象AZのリソースが利用できなくなります。
利用できなくなってもサービスが安定稼働できるかを事前に確認しておく必要があります。ZonalShiftを利用するには、静的安定性の確保が必須です。これはコストとトレードオフを側面を持つため、注意しましょう。
-
ゾーンオートシフトを利用するには毎週30分間練習実行が必要
-
AZを無効化するので、1AZ分のキャパシティがない状態で動作させても問題ない状態としておく (必要に応じてスケーリング)
-
事前のテスト
-
切り替えのシナリオを明確にする(可能な場合自動化する)
-
ユーザから対象リソースへの接続時間を制限する
-
切り替えは一時的なものであることを意識し原則としてなるべく早く元の構成にもどす
-
フェイルオーバーメカニズムにおいてデータプレーンのAPIを利用する(zonal shift actions)
グレー障害に備えるためのベストプラクティス
以下のようなベストプラクティスを参考にしましょう。
-
静的安定性の確保(W-A 信頼性の柱 REL1-BP05)
- 障害が発生する前に障害に供えること→障害が発生した場合になにか対応行うのではなく、障害が発生しても継続したサービス提供が可能な状態としておくこと障害境界点の独立性に応じた設計
-
可観測性をもたせること(W−A 信頼性の柱 REL06〜REL07)
- 障害境界点に応じたメトリクスの取得(視点別のオブザーバビリティの確保)
- サーバサイドのモニタリングと、ユーザサイドでのモニタリング
- 外れ値によるモニタリング
- モニタリングの組み合わせ等によるグレー障害の検出
-
可能な限り内部構造が複雑なコントロールプレーン(リソースの作成更新などサービスの管理機能)ではなく比較的単純なデータプレーン(サービス自体の主要機能)を利用した復旧方法の実装(W−A 信頼性の柱 REL11-BP04)
- DNSレコードの追加、変更などDNSレコードの変更、スケーリング操作等のコントロールプレーンに依存した復旧方法ではなく、ARCによるDNSトラフィックのシフトやルーティングポリシー設定などデータプレーンによる復旧方法を設計する
- 可能な限り自動化
まとめ
グレー障害や障害発生時の対応として、AWSの提供するApplication Recovery Controller (ARC) Zonal Shiftを活用することは非常に有用です。特に、システム全体の安定性とユーザ体験の向上に寄与します。本記事では以下のポイントを整理しました:
1. グレー障害の本質
- 視点別オブザーバビリティによる検出困難な障害。
- ユーザ視点では異常でも、システム監視では検知されないケースが存在。
2. Zonal Shiftの種類と特性
-
手動ゾーンシフト
- ユーザ側起因のエラーに対応し、柔軟な操作で特定AZの切り離しが可能。
-
自動ゾーンシフト
- AWS側の障害を自動で検知・対応する機能。
3. Zonal Shift活用のベストプラクティス
- 静的安定性の確保。
- 可観測性の向上とモニタリング戦略の強化。
- データプレーンを活用した復旧方法の設計。
4. 具体的な留意事項
- キャパシティの余裕確保や事前テストの実施。
- 切り替えの一時性を意識し、迅速に元の構成へ戻す。
AWSのARC Zonal Shiftを活用することで、予測困難なグレー障害や障害時の迅速な対応が可能となり、信頼性の高いシステム運用が実現します。ベストプラクティスを踏まえた設計と運用を行い、サービスの安定性を高めることが重要です。ただし、利用にはコストと性能における制約事項があるので、注意しましょう。
参考
ゾーンシフトとゾーンオートシフトを使用して でアプリケーションを復旧する ARC
https://docs.aws.amazon.com/ja_jp/r53recovery/latest/dg/multi-az.html
Rapidly recover from application failures in a single AZ
https://aws.amazon.com/jp/blogs/networking-and-content-delivery/rapidly-recover-from-application-failures-in-a-single-az/
アベイラビリティーゾーンを使用した静的安定性
https://aws.amazon.com/jp/builders-library/static-stability-using-availability-zones/
AWS re:Invent 2023 - グレー障害の検出と軽減 (ARC310)
https://youtu.be/LzIZ-dEzgEw?si=q8I5cye7A3nuBS6t
マルチAZの高度なレジリエンスパターン グレー障害の検出と軽減
https://docs.aws.amazon.com/ja_jp/whitepapers/latest/advanced-multi-az-resilience-patterns/gray-failures.html