みなさん、こんにちは!
多くのビジネス現場における生成AI導入において、PoCを実施する一方で実運用を考えた際にはデータサイロやレガシーシステムの技術的負債、運用の負荷増大といった課題が多く残されています。現場のエンジニアがそういった過去の遺産に対するトラブルシューティングに追われ、データドリブンな意思決定を支える基盤づくりが遅れるケースも見られます。
本記事では、Google Cloud Next 2026で発表されたデータエンジニアリング領域の最新動向から、これらの課題に対する現実的なアプローチを考察します
セッション・ハイライト
セッション①「What’s new in BigQuery: The data platform for agentic AI」
すごく大きな会場でのセッションでした。やはりBigQueryは注目度が高いですね。
BigQueryのアーキテクチャの変更と、AIエージェントを支えるデータプラットフォームとしての役割が解説されました。過去1年でパフォーマンスが35%向上し、流動的スケーリングによりSLAとコストのトレードオフが解消されたことが強調されていました。また、非構造化データを統合する「Object ref」や、AWS S3上のデータを直接クエリできる「CrossCloud Lakehouse」の一般提供が発表されました。MercadoLibre社の事例では、350ペタバイトのデータ基盤構築とセマンティックレイヤーの役割が語られていました。

セッション②「Data Engineering Agent: Your partner for BigQuery and the open lakehouse」
データパイプラインの構築・近代化・修復を自律的に行う「Data Engineering Agent」の一般提供開始が発表されました。ガートナー社の予測を引き合いに出し、リアクティブな運用からプロアクティブなアクションへの移行について語られていました。Vodafone社の事例では既存のストアドプロシージャをDataformパイプラインへ自動変換し、実行速度を2倍に向上、コストを30%削減した実績が示されました。また、複数エージェントが連携するA2Aプロトコルのデモも披露されました。
▼Data Engineering Agentに関してGoogle公式ブログにも記事があがっていました。
BigQuery の新しいデータ エンジニアリング エージェントでデータ パイプラインを自動化

横断的考察:両セッションから浮かび上がる共通の論点
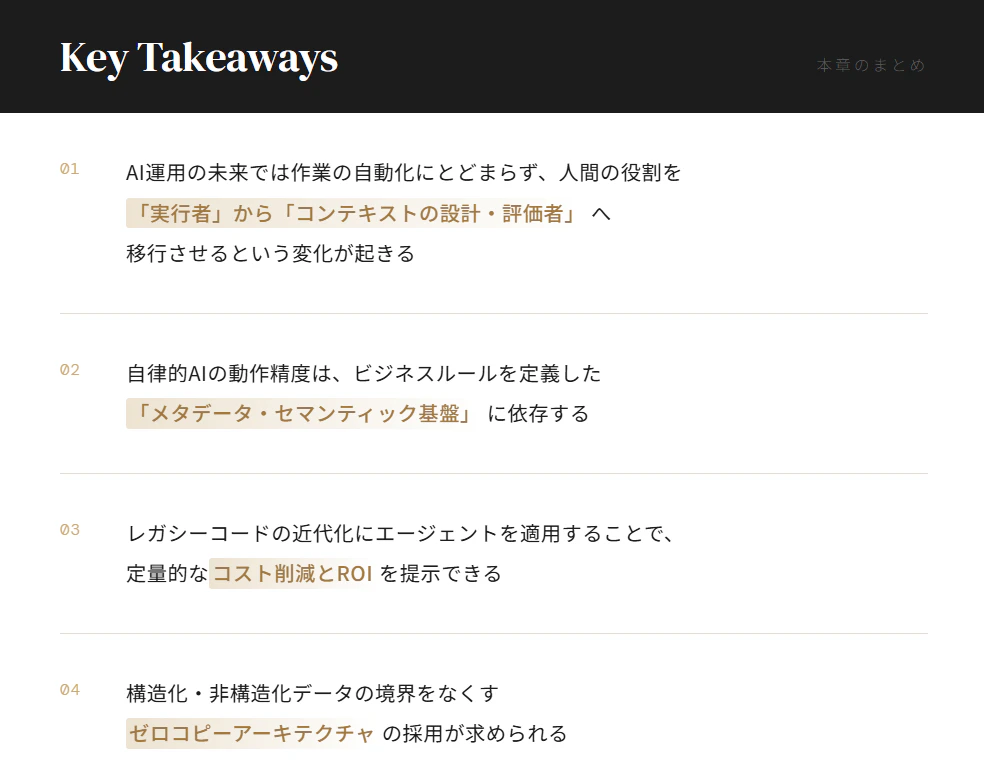
考察1:ツールから「自律型同僚」への変化
【セッションで語られた実態】
データ運用において、AIは人間の指示に従うツールから、自律的に推論し行動する「同僚のうよな存在」へと位置づけが変わりつつあります。セッション②では、パイプラインの実行が失敗した際にエージェントが自動的に根本原因分析を行い、修正案のプルリクエストを作成するデモが公開されました。また、A2A(Agent-to-Agent)プロトコルによりローカルのCLIエージェントとサーバー側エージェントが連携し、変換タスクを並列処理する機能も実装されています。セッション①でも、静的なダッシュボードから自律型エージェントへの移行が分析の次の形として語られました。
【現場が取るべきアプローチ】
IT部門は、これまで通りのエンジニアの業務設計を見直す時期に来ています。定型的なコードの記述やエラーの一次対応はエージェントに委譲し、人間はエージェントが提示したプランのレビューやビジネスロジックの設計に注力するといった未来がすぐそこまで来ています。「AIが業務を代替する」という捉え方ではなく、「エージェントをマネジメントする役割を人間が担う」ものとして組織全体の認識を合わせることが重要だと感じました。
考察2:精度を左右する「コンテキスト基盤」の整備
【セッションで語られた実態】
エージェントが実際の業務要件に適合して機能するためには、「正確なコンテキスト(文脈・意味論)」の提供が不可欠であると両セッションで言及されました。セッション①では、Mercado Libre社が「セマンティックレイヤー」を構築し、正確な環境で情報を提供することでモデルデータの精度を維持している事例が紹介されました。セッション②においては、「アクティブな自社顧客の定義」といった自社のビジネス固有の意味を保持する「ナレッジ・カタログ」がエージェントの根拠として機能し、自律的なパイプライン生成を支えていると説明されています。
【現場が取るべきアプローチ】
エージェントに自社固有のタスクを処理させるためには、社内に散在する業務知識をシステムが参照できる形式(カタログやセマンティックレイヤー)に整理する必要があります。アーキテクト部門はデータを一ヶ所に集めるだけでなく、「そのデータがビジネス上何を意味するのか」を定義するメタデータ管理にリソースを割り当てるべきです。データ品質要件とビジネスルールの文書化が、自動運用の前提条件となります。
考察3:モダナイゼーションを通じた利益の獲得
【セッションで語られた実態】
AIは新規機能の追加だけでなく、既存の技術的負債を解消する用途においても費用対効果を示しています。セッション②のVodafone社は、5万本に及ぶパイプラインの移行課題に対しエージェントを活用しました。古いストアドプロシージャをDataformによるモジュール構成へ変換した結果、実行速度が2倍に向上し運用コストの30%削減を達成したそうです。セッション①でも、BigQueryの流動的スケーリングにより、リソース確保とコスト管理の課題が解消されたことが報告されました。
【現場が取るべきアプローチ】
AI投資の社内承認を得るプロセスにおいて、「既存システムの維持コスト削減」を初期のビジネスケースに据えるアプローチは有効な手段の1つです。古いETLツールや複雑化したストアドプロシージャの解析・移行は工数がかかりますが、AIエージェントが適性を持つ領域です。既存資産の刷新プロジェクトにエージェントを適用し、定量的なコスト削減効果を示すことで段階的な投資の妥当性を説明しやすくなります。
考察4:構造化・非構造化データの統合的アプローチ
【セッションで語られた実態】
AIがビジネスデータを横断的に処理するためには、データベース上の数値(構造化データ)と、文書ファイル(非構造化データ)を統合して扱う仕組みが必要です。セッション①では、データ型「Object ref」が一般提供され、個別のパイプラインを用意せずに両者を結合できるようになったことが説明されました。デモでは、取引データとPDFの欠陥情報を統合し、影響を受ける顧客とサポート予算を特定する流れが示されました。また、他クラウドのデータを移動させずに扱えるCrossCloud Lakehouseの機能も発表されました。
【現場が取るべきアプローチ】
データ管理者は、「非構造化データ」と「構造化データ」で分断されている基盤設計の統合を検討する必要があります。プラットフォーム間でデータをコピーするETL処理は、運用負荷とコストの増加につながります。オープンフォーマット(Apache Icebergなど)を活用し、データを移動させずに横断検索・処理を行うゼロコピーアーキテクチャの導入が、運用を効率化する選択肢となります。
この章のポイント
Q&Aから見えてくるもの
本章では、質疑応答が行われた「Data Engineering Agent」セッションのQ&Aを取り上げます。新技術を既存のエンタープライズ環境にどう組み込むかという、現場の実務的な課題感が表れていました。
既存のCI/CDやカスタムコードとの連携
「既存のGitHubリポジトリと連携できるか」「Python等のカスタムスクリプトを考慮できるか」「独自のCI/CDライフサイクルに合わせてカスタムスキルを追加できるか」といった、現在の運用フローへの組み込みに関する質問。
【登壇者の回答】
Google側はこれらの質問に対し、サポートされていると回答しました。エージェントは抽象化パイプライン・フレームワークを備えており、カスタムスクリプトやアクションをサポートできると説明しています。
他社製ETL資産からの移行
「Ab Initio等の他社ETLツールからの変換はサポートしているか」「Teradata等のストアドプロシージャのままではなく、Dataformへ移行する利点は何か」という、モダナイゼーションの実務的な意義を問う質問が出ました。
【登壇者の回答】
他社ツールからの移行について、登壇者はプレビュー顧客がSASやDataStage等からの移行に成功していると回答しました。また、Dataformへ移行する理由についてVodafoneの担当者は、「レガシーコードは巨大で複雑かつドキュメント化されていない」という実態を指摘し、変換によってコードがモジュール化され読みやすくなる点が利点であると述べていました。
非標準フォーマットデータの処理
「GCSに保存されている複数のXMLファイルを処理させるには、どのようなアプローチが最適か」という質問が投げかけられました。
【登壇者の回答】
登壇者は、Data Engineering AgentとBigQuery内のカスタムXMLパーサー関数を組み合わせることで対応可能であり、並列処理ができると回答しました。
この章のポイント

おわりに
2つのセッションから、データ基盤とデータ運用の双方が、プロアクティブなエージェントの活用を前提としたフェーズへ移行しつつあることが確認できました。
AI活用推進者やDX推進担当者が検討すべき初期のアクションは、組織内のビジネスルールやデータ定義の棚卸しであるという結論に至りました。エージェントを有効に機能させるためには、やはり適切な「コンテキスト」の提供が必要です。データカタログやセマンティック層の整備を進めることが、自律型運用を定着させるための必須要件と言えそうです。