みなさん、こんにちは!
Amazon SageMaker では、Icebergテーブルを読み書きすることができます。
本記事では Amazon SageMaker でのIcebergテーブル作成、各種テーブル操作に加えて、VACUUMやOPTIMIZEによるテーブル最適化までを実際の例とともにご紹介します。
事前準備
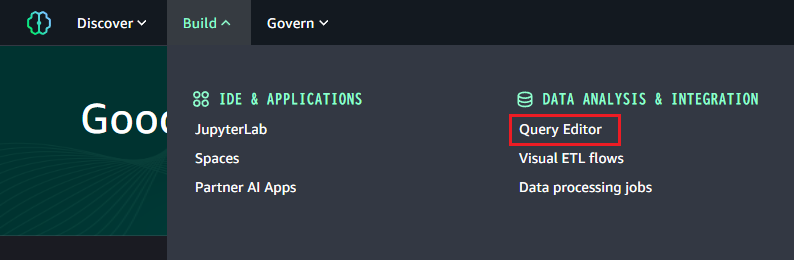
SageMaker を開き、「Build」→「Query Editor」でクエリエディタを開きます。
以降のSQL実行はノートブックで行います。
ノートブックでは右上のドロップダウンからSQL実行対象のデータベースを選択します。
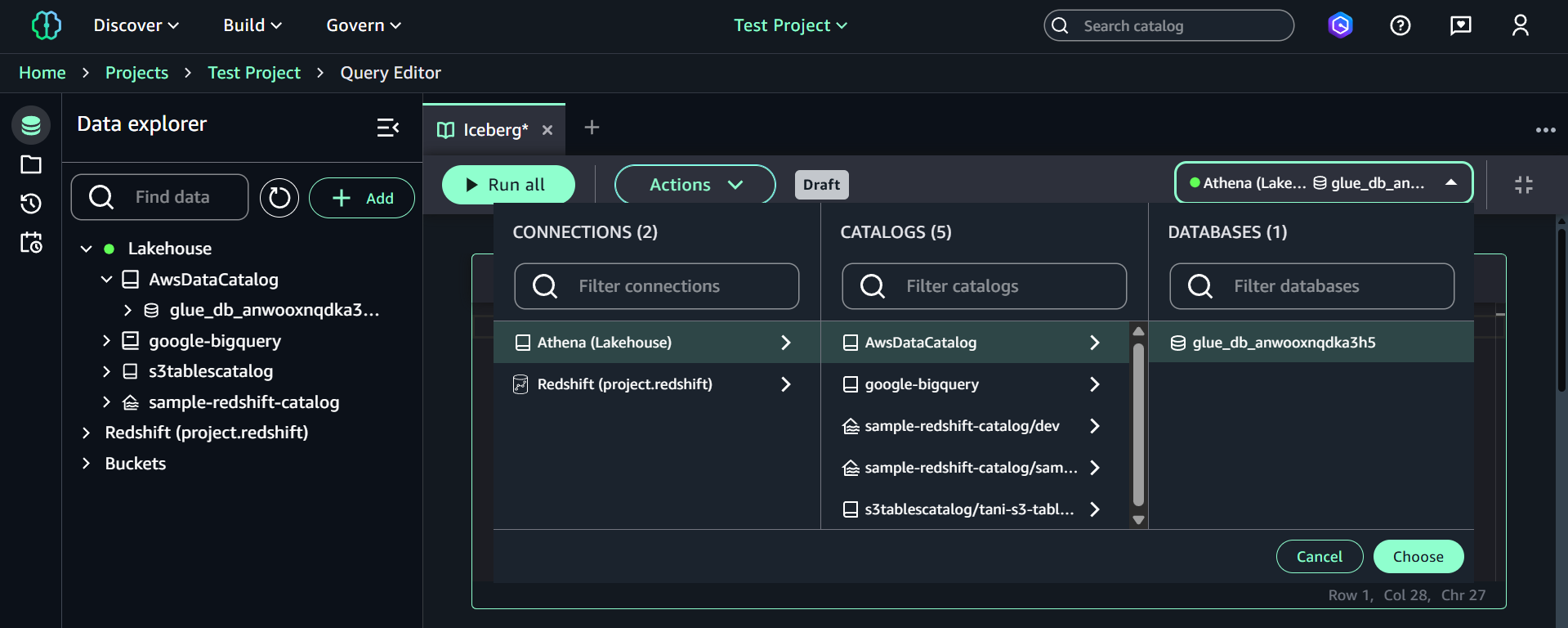
今回はすでに作成済みの gluedb を選択し、以下のSQLを実行して新しいデータベース icebergdb を作成します。
CREATE DATABASE iceberg_db;
作成後、iceberg_db を対象データベースに変更します。
テーブル作成
S3にテーブルデータ格納用のバケットとフォルダ(今回はsales/)を作成しておきます。
以下のSQLを実行し、Icebergテーブルを作成します。
CREATE TABLE sales (
id int,
sales_at timestamp,
product_name string,
unit_price int,
quantity int
)
LOCATION 's3://req-iceberg-demo-bucket/iceberg_database/sales/'
TBLPROPERTIES ('table_type' = 'ICEBERG');
INSERT INTO sales VALUES
(1, timestamp'2024-01-15 09:00:00', 'Laptop', 500, 2),
(2, timestamp'2024-01-15 10:00:00', 'Monitor', 200, 3),
(3, timestamp'2024-01-16 15:00:00', 'Desktop', 1000, 1);
テーブルが作成されると、LOCATIONに指定したS3フォルダにテーブルのデータが格納されます。
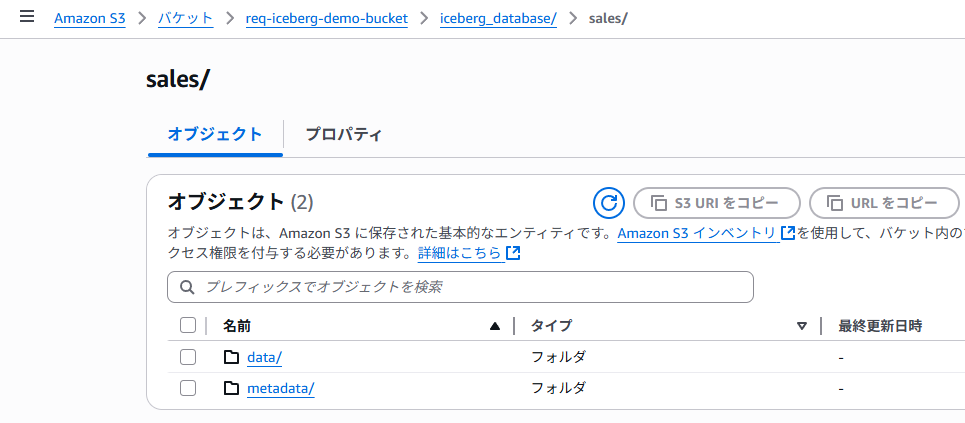
テーブル操作
各種テーブル操作は以下の通りです。
SELECT
SELECT * FROM sales
ORDER BY id;

INSERT
INSERT INTO sales VALUES (4, timestamp'2024-02-01 11:00:00', 'Monitor', 300, 1);

UPDATE
UPDATE sales SET unit_price = 800
WHERE id = 3;

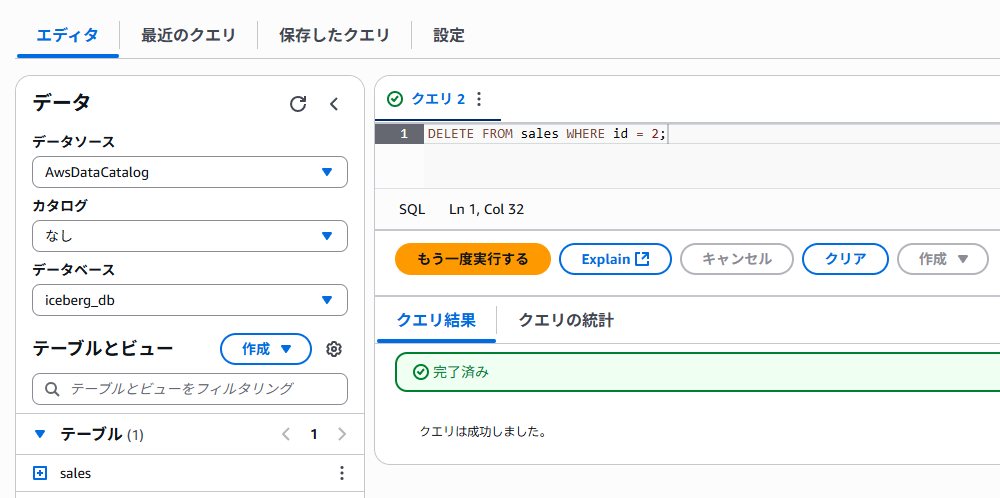
DELETE
DELETE FROM sales WHERE id = 2;
SageMakerから実行しようとしたところ、クエリがサポートされていないというエラーが発生しました。
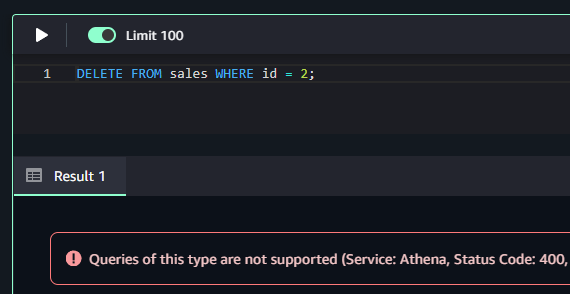
Athenaのクエリエディタからは問題なく実行可能です。
スキーマ進化
Icebergテーブルはスキーマ進化をサポートしており、以下のSQLでtotal_amount列を追加できます。
ALTER TABLE sales ADD COLUMNS (
total_amount int
);

total_amount列に値をセットします。
UPDATE sales SET total_amount = unit_price * quantity;

列の削除、型の変更、名称変更や並び替えも可能です。
隠しパーティショニング
Icebergテーブルでは、パーティション専用の列を作る必要なくパーティションを設定することができます。パーティション変換関数により、タイムスタンプ型の列から日付や年月単位でのパーティションを作成することも可能です。
以下のSQLを実行し、日単位でパーティショニングされたテーブル sales_partition を作成します。
CREATE TABLE sales_partition (
id int,
sales_at timestamp,
product_name string,
unit_price int,
quantity int
)
PARTITIONED BY (day(sales_at))
LOCATION 's3://req-iceberg-demo-bucket/iceberg_database/sales/'
TBLPROPERTIES ('table_type' = 'ICEBERG');
INSERT INTO sales_partition VALUES
(1, timestamp'2024-01-14 09:00:00', 'Laptop', 500, 2),
(2, timestamp'2024-01-15 10:00:00', 'Monitor', 200, 3),
(3, timestamp'2024-01-16 15:00:00', 'Desktop', 1000, 1),
(4, timestamp'2024-02-01 11:00:00', 'Monitor', 300, 1),
(5, timestamp'2024-02-01 11:00:00', 'Desktop', 800, 2);
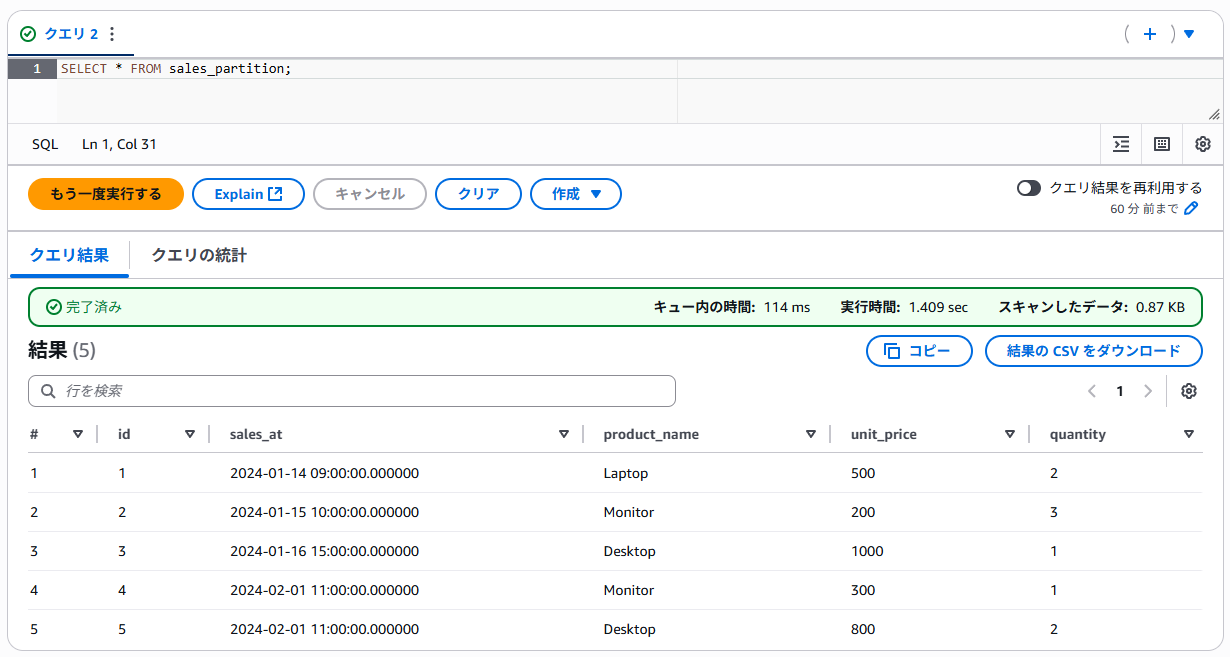
パーティション情報は以下のSQLで確認可能です。
SELECT * FROM "sales_partition$partitions"
ORDER BY partition;

日付ごとにパーティションが作成され、各パーティションに属するデータの情報が格納されていることが確認できます。
フルスキャンの場合:
フィルターした場合:
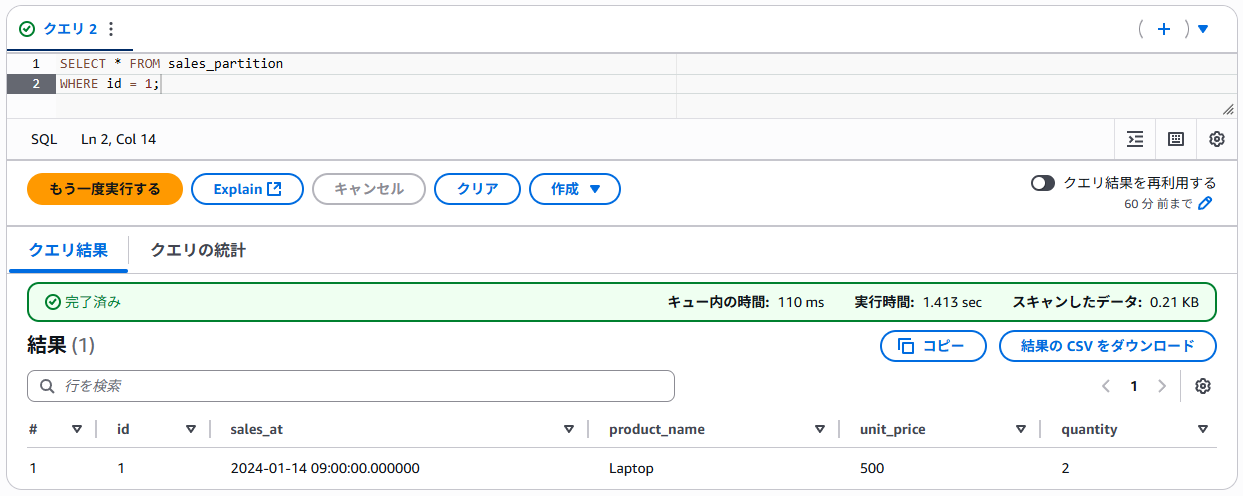
フィルしたーした場合、パーティショニングによりスキャンデータ量が減少していることが確認できます。
タイムトラベルとロールバック
以下のSQLで、テーブルの変更履歴を確認できます。
SELECT * FROM "sales$history";
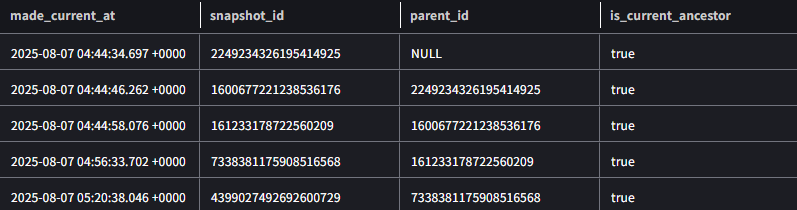
タイムトラベル機能により、タイムスタンプを指定してSQLを実行することで、total_amount列追加前の状態を参照することができます。
SELECT * FROM sales FOR TIMESTAMP AS OF timestamp'2025-08-07 05:00:00 UTC';

データ圧縮
テーブル更新操作によりスナップショットのデータが増加すると、クエリ効率低下や追加の計算コスト発生に繋がる。
AthenaではVACUUM処理とOPTIMIZE処理が用意されており、テーブルを構成するデータを最適化することができます。
VACUUM
以下のSQLで、スナップショットを確認します。
SELECT * FROM "sales$snapshots";

スナップショットは5つ存在している状態です。
検証のため、スナップショットの有効期限を短い値(3時間(10800秒))に設定します。
ALTER TABLE sales SET TBLPROPERTIES (
'vacuum_max_snapshot_age_seconds' = '10800'
);
VACUUMを実行します。
VACUUM sales;
再度スナップショットの状態を確認します。
SELECT * FROM "sales$snapshots";

最新のスナップショットのみになっていることが確認できます。
OPTIMIZE
OPTIMIZEを使用すると、テーブルのデータファイルのレイアウトを最適化することができます。
以下のSQLで、現在のデータファイルの状態を確認します。
SELECT * FROM "sales$files";

データファイルは4つ存在している状態です。
OPTIMIZEを実行します。
OPTIMIZE sales REWRITE DATA USING BIN_PACK;
再度データファイルの状態を確認します。
SELECT * FROM "sales$files";

データファイルが1つになっていることが確認できます。
まとめ
SageMaker におけるIcebergテーブルの操作方法についてご紹介しました。
SageMaker でも、エラーとなったDELETEを除いてほぼすべての操作をIcebergテーブルに対して実行することができます。
今回はクエリエディタから通常のSQLで実行しましたが、ノートブックでPySparkを利用して処理を実行することも可能です。
ご利用のシーンに合わせて、効果的に使い分けてみてください。