こんにちは!any 株式会社でプロダクトチームに所属しているエンジニアの田中(@Rasukarusan)です!
この記事は、any Product Team Advent Calendar2024 10 日目の記事になります。
この記事では 「oVice上の会議を文字起こしする」 手順をご紹介します。
下記のように音声がリアルタイムにテキスト化され、ミーティングを終えて画面を閉じると要約されます。楽しいですね!
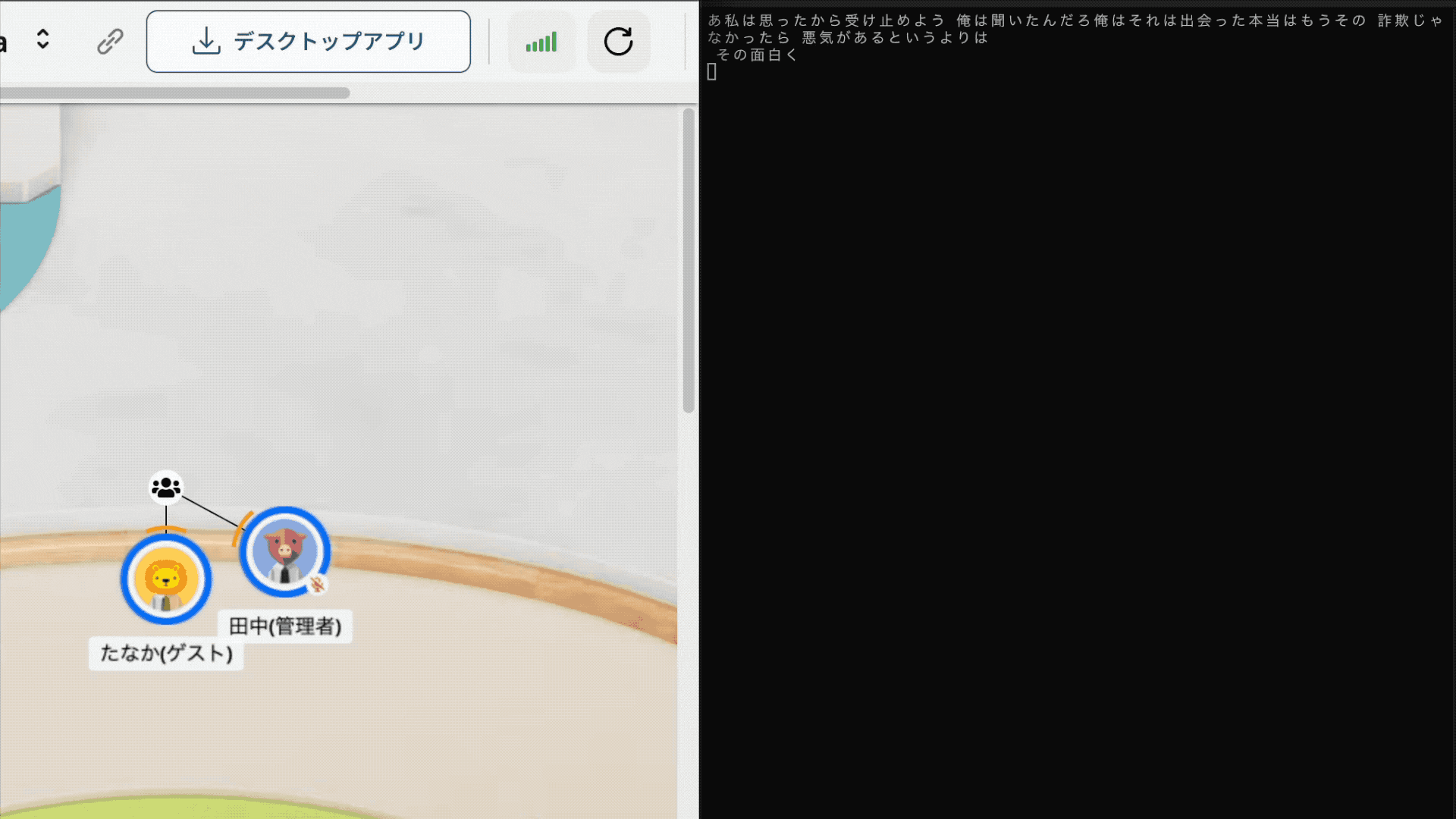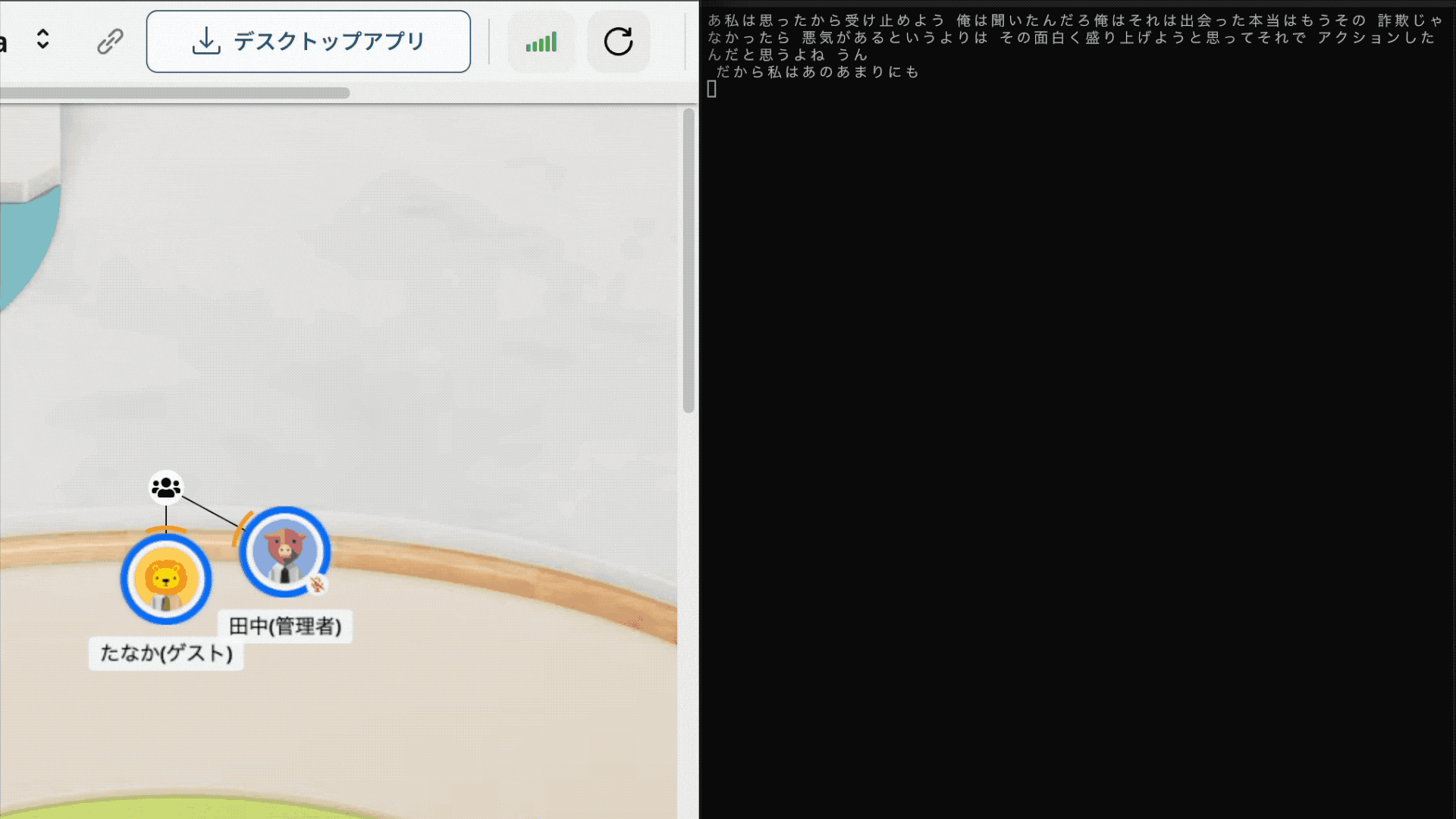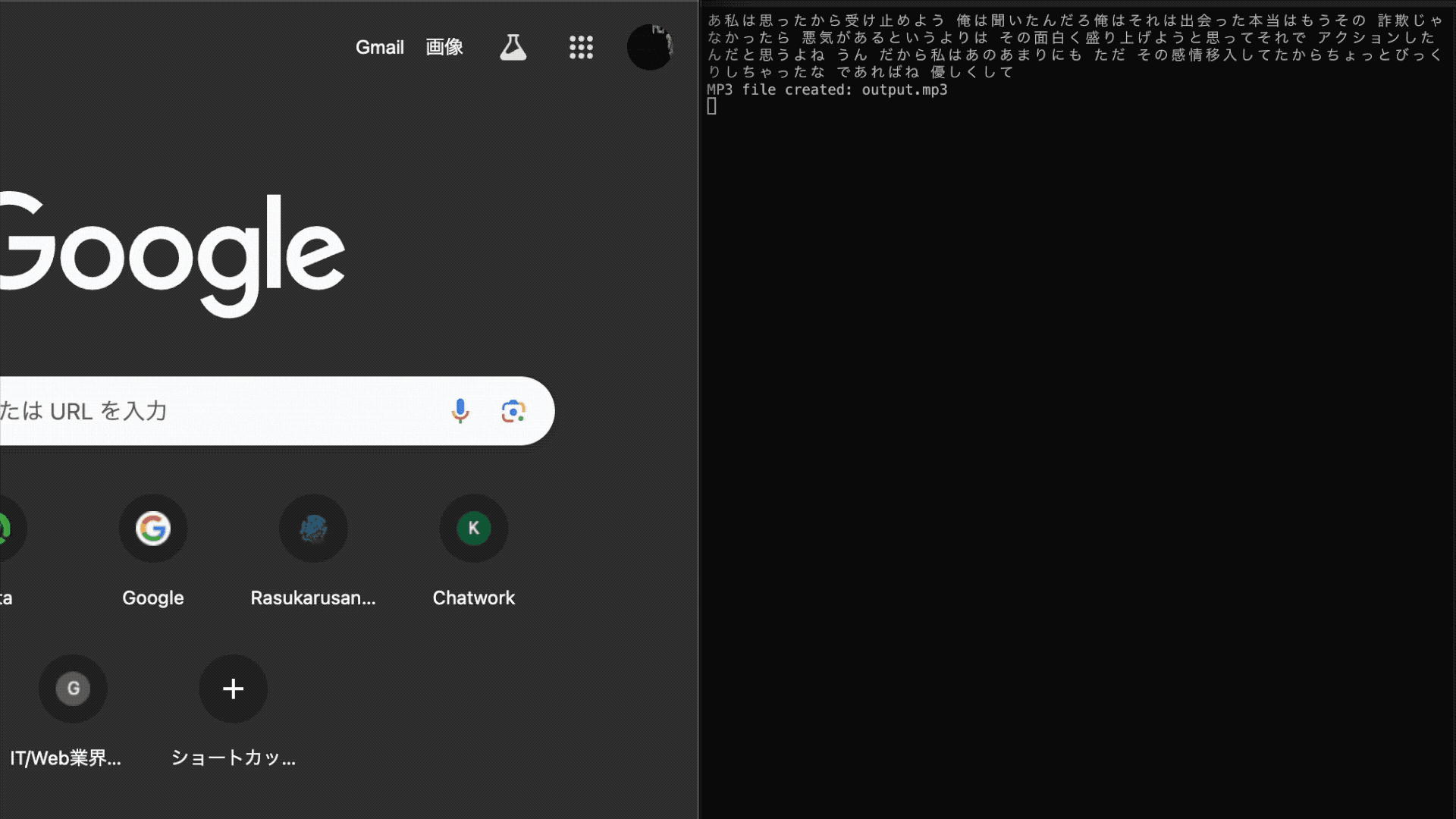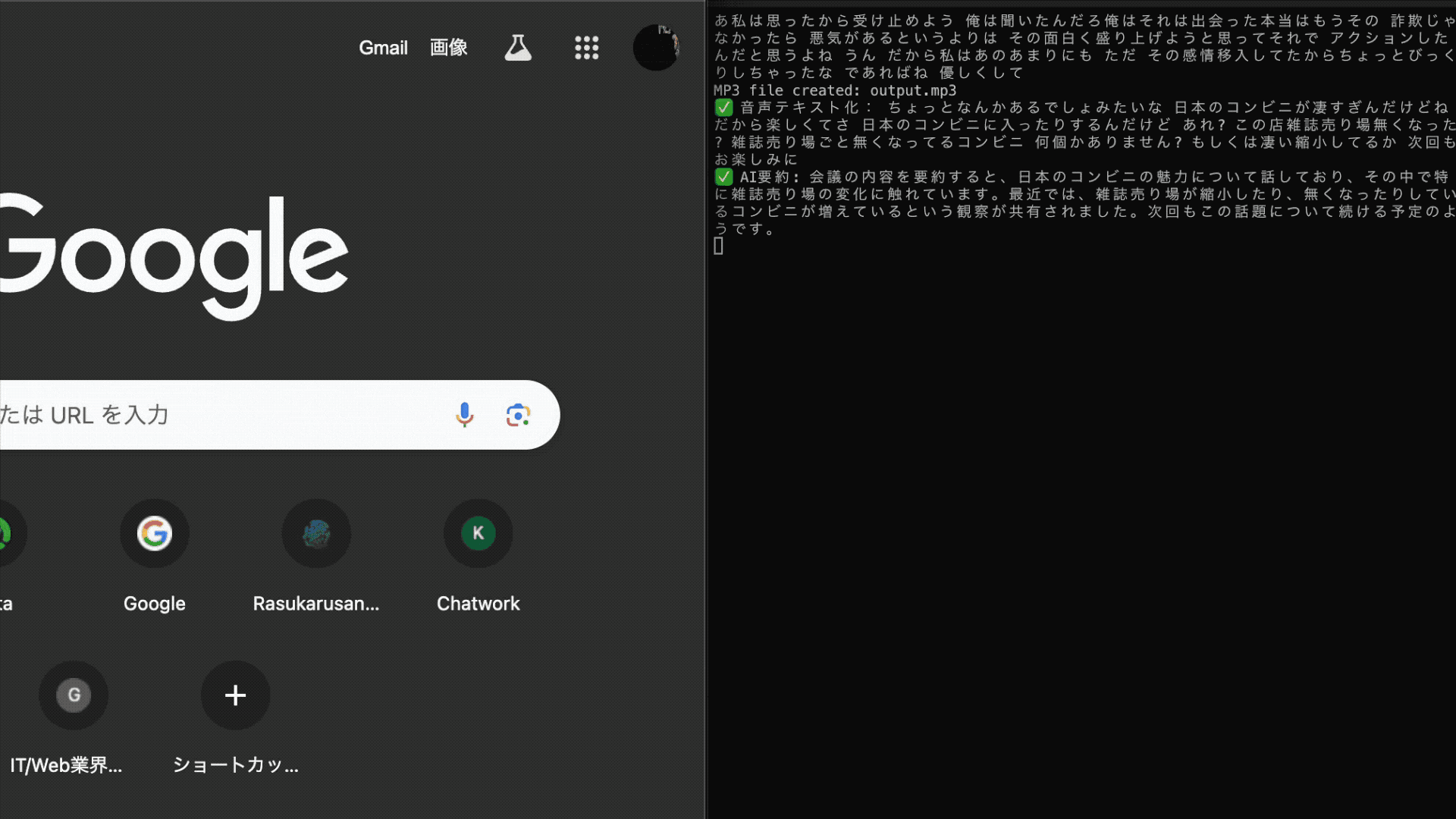
また、今回紹介するコードは以下のリポジトリで公開しています。
本記事でご紹介する内容は、WebRTC や AI を活用した文字起こしの技術的な実装例を共有することを目的としています。oVice の有償オプションである録音・文字起こし機能を代替する意図は一切ありません。
oVice が提供する公式の録音・文字起こし機能は、品質やサポートが保証されており、特に業務で利用する際には非常に便利なオプションです。正確性や効率性を重視する場合には、公式の有償機能を活用することを強くおすすめします。
公式機能の詳細はこちら
oVice とは
oVice は、ブラウザ上で仮想オフィスを構築できるバーチャルオフィスツールの一つです。
ユーザーはアバターを使って仮想空間に「出勤」し、画面共有やチャット機能を活用して、気軽にコミュニケーションを取ることができます。
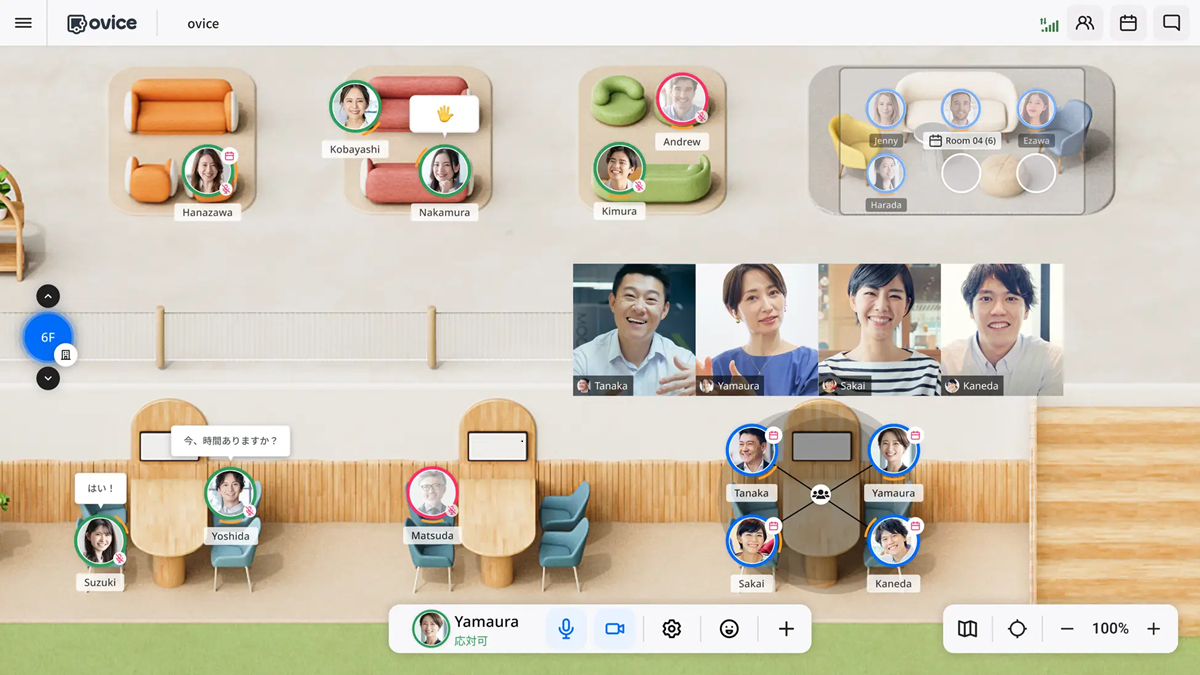
出典: https://www.ovice.com/ja/blog-jp/guide-to-start-ovice
例えば、週次ミーティングや朝会、月次の締め会などを oVice 上で実施することで、物理的な制約を超えたスムーズなコミュニケーションが可能です。
私たち プロダクトチームでも、毎朝 oVice 上で朝会を実施しています。
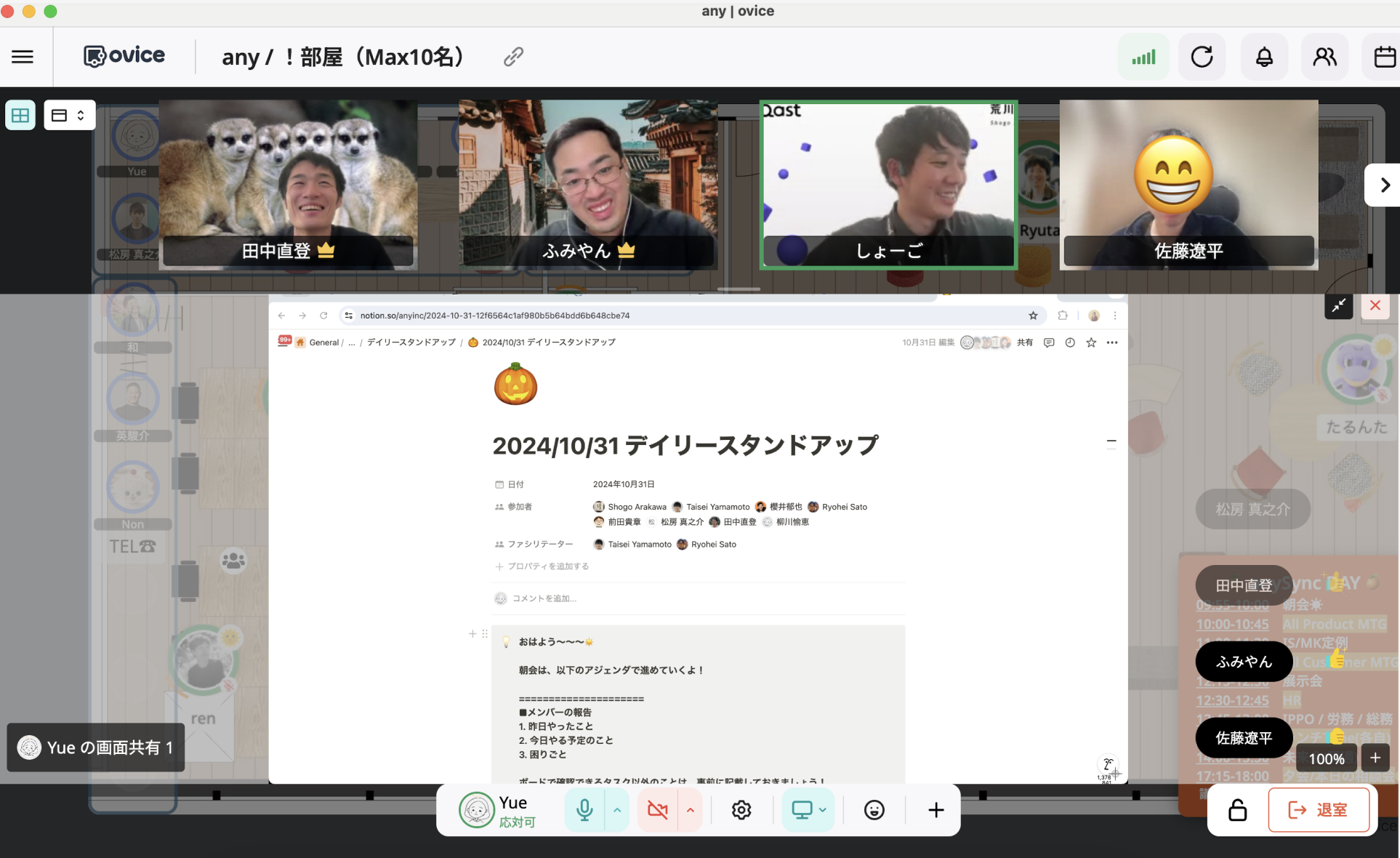
anyプロダクトチームの朝会の様子
本記事では、oVice に限らず、このようなミーティングの音声を取得し、テキスト化する方法を解説します。
oVice の音声技術
oVice では、音声通信に WebRTC が使用されています。
WebRTC を使うことで、ブラウザ間で音声や映像データをリアルタイムにやり取りすることが可能になります。
oVice で WebRTC が使用されているかどうかは、以下の手順で簡単に確認できます:
-
Chrome のアドレスバーに以下を入力し、アクセスします。
chrome://webrtc-internals/ -
現在開いているタブで WebRTC を利用しているサービスが一覧表示されます。
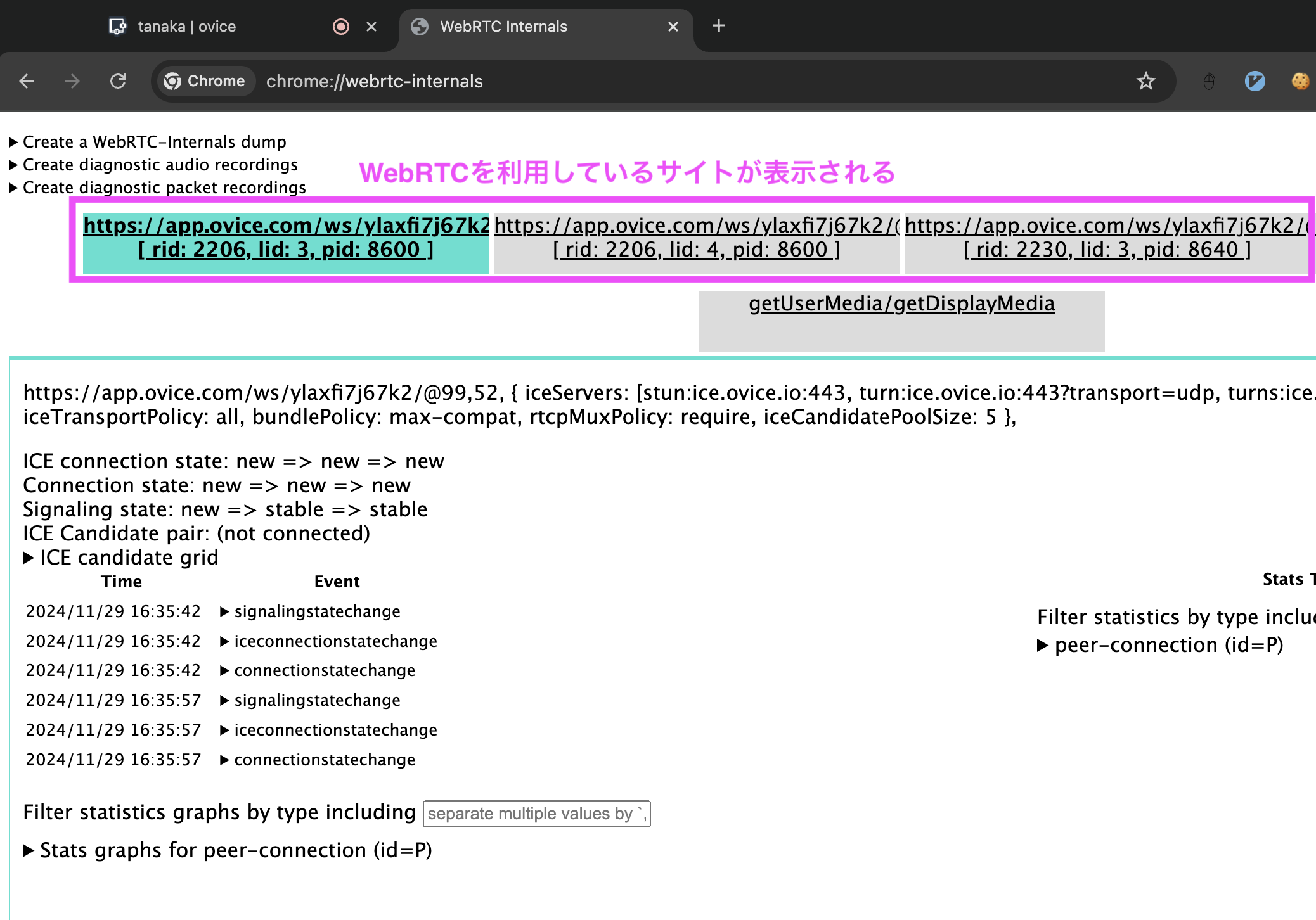
WebRTC を利用中のサイト一覧
この方法は oVice に限らず、Google Meet など他の Web 会議サービスにも共通しています。
また、別の方法として、対象のサービスのヘルプページを検索するのもおすすめです。例えば oVice のヘルプページで「音声」と検索すると、以下のような記事が見つかります:
toB 向けサービスのヘルプページには、このように利用技術が記載されている場合があるため、検索してみる価値があります。
音声を取得し、AI を用いて文字起こし・要約するまでの流れ
それでは実際にコードを書いていきます。おおまかな実装の流れは以下です。
- ブラウザで音声データを取得する
- 音声データをサーバーに送信し、MP3 に変換する
- MP3 の文字起こし、AI で要約する(Whisper, GPT)
- (おまけ)リアルタイム文字起こし(Google-Speech-To-Text)
1, 2 番がメインです。音声データを MP3 として保存できれば、あとはいかようにもなると思うので 💪
1. WebRTC の音声データを取得する(クライアント)
それでは音声データを取得していきましょう。今回はブラウザ上で Javascript を動かすのに、 Chrome 拡張の「User Javascript and CSS」を使用します。
似たような Chrome 拡張に「Tampermonkey」がありますが、個人的にUser Javascript and CSSは UI がかなり整っていて使いやすいです。機能ごとにトグルで ON/OFF ができたり、クラウド上に設定をエクスポートできたり、エディタも Vim モードがあったりしてかなり作り込まれている印象です。

User Javascript and CSS のエディタ、非常に綺麗
少し話が逸れました。それでは実際に oVice の音声を取得していきましょう。
処理の流れとしては以下の通りです
-
navigator.mediaDevices.getUserMediaでマイク音声を取得 -
AudioContextでリアルタイムに音声を処理する
クリックしてコード全体を見る
/**
* このスクリプトをUser Javascript and CSSに貼り付ける
*/
// 音声取得とサーバーへの送信
async function startAudioCapture() {
try {
// マイク音声を取得
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
console.log("Audio stream acquired:", stream);
// AudioContextで音声データを処理
const audioContext = new AudioContext();
const mediaStreamSource = audioContext.createMediaStreamSource(stream);
const scriptProcessor = audioContext.createScriptProcessor(4096, 1, 1);
// WebSocketサーバーに接続
const socket = new WebSocket("ws://localhost:9999");
socket.onopen = () => console.log("WebSocket connection established");
socket.onclose = () => console.log("WebSocket connection closed");
socket.onerror = (error) => console.error("WebSocket error:", error);
// 音声データをWebSocketで送信
scriptProcessor.onaudioprocess = (event) => {
const audioData = event.inputBuffer.getChannelData(0); // PCM形式のデータ
const int16Array = float32ToInt16(audioData); // Int16に変換
if (socket.readyState === WebSocket.OPEN) {
socket.send(int16Array.buffer); // バッファとして送信
}
};
// AudioContextの接続
mediaStreamSource.connect(scriptProcessor);
scriptProcessor.connect(audioContext.destination);
console.log("Audio processing started...");
} catch (error) {
console.error("Error capturing audio:", error);
}
}
// Float32データをInt16データに変換する関数
function float32ToInt16(float32Array) {
const int16Array = new Int16Array(float32Array.length);
for (let i = 0; i < float32Array.length; i++) {
int16Array[i] = Math.min(1, Math.max(-1, float32Array[i])) * 0x7fff;
}
return int16Array;
}
// 処理開始
startAudioCapture();
try {
// マイク音声を取得
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
// AudioContextで音声データを処理
const audioContext = new AudioContext();
const mediaStreamSource = audioContext.createMediaStreamSource(stream);
const scriptProcessor = audioContext.createScriptProcessor(4096, 1, 1);
// 音声データを取得
scriptProcessor.onaudioprocess = (event) => {
const audioData = event.inputBuffer.getChannelData(0); // PCM形式のデータ
/*** TODO: 取得した音声データを使って何かする ***/
};
// AudioContextの接続
mediaStreamSource.connect(scriptProcessor);
scriptProcessor.connect(audioContext.destination);
} catch (error) {
console.error("Error capturing audio:", error);
}
これだけです、非常に簡単ですね!
WebRTC の音声取得には色々手法がありますが、今回は網羅的な場面で使える、かつリアルタイムに処理がしたかったのでgetUserMediaによるマイク音声取得とAudioContextによるリアルタイム処理をできるようにしました。
あとは取得した音声をサーバーに送信すればクライアント側の処理は終了です。今回サーバーへの送信は WebSocket を使用しました。
ここまででコンソールで音声データを取得できていることを確認できます。

音声データをINT型配列で取得
2. 音声データをサーバーに送信し、MP3 に変換する(サーバー)
続いて、音声データのストリームを受信し、サーバー側で加工して MP3 に変換する仕組みを解説します。この章では、特に音声ストリーム周りの処理について説明します。
ここからはサーバー側の処理で、Node.jsの世界です。
クリックしてコード全体を見る
// server.ts
import { WebSocketServer, WebSocket } from "ws";
import { Writable } from "stream";
import * as fs from "fs";
import * as ffmpeg from "fluent-ffmpeg";
const PORT = process.env.PORT ?? 9999;
const TEMP_FILE = "temp.raw";
const OUTPUT_MP3_FILE = "output.mp3";
// WebSocketサーバーをセットアップ
const wss = new WebSocketServer({ port: Number(PORT) });
console.log(`WebSocket server running on ws://localhost:${PORT}`);
wss.on("connection", (ws: WebSocket) => {
console.log("Client connected");
// 一時ファイルへの書き込みストリームを作成
const tempFileStream = fs.createWriteStream(TEMP_FILE);
const audioStream = new Writable({
write(chunk: Buffer, encoding: string, callback: () => void) {
tempFileStream.write(chunk); // TEMP_FILEに書き込む
callback();
},
});
// WebSocketで受信したデータをaudioStreamに流す
ws.on("message", (message) => {
if (Buffer.isBuffer(message)) {
audioStream.write(message);
}
});
ws.on("close", () => {
console.log("Client disconnected");
audioStream.end();
tempFileStream.end(); // TEMP_FILEの書き込みを終了
});
ws.on("error", (error) => {
console.error("WebSocket error:", error);
});
// TEMP_FILEの書き込み終了後にMP3変換を開始
tempFileStream.on("finish", () => {
console.log("TEMP_FILE write completed. Starting MP3 conversion...");
encodeToMp3(TEMP_FILE, OUTPUT_MP3_FILE);
});
});
/**
* rawファイルをmp3に変換
*/
const encodeToMp3 = (rawPath: string, outputPath: string) => {
ffmpeg(rawPath)
.inputOptions("-f s16le") // PCM形式(16ビットリトルエンディアン)
.inputOptions("-ar 44100") // サンプリングレート 44.1kHz
.inputOptions("-ac 1") // モノラル
.audioCodec("libmp3lame") // MP3エンコード
.audioBitrate("192k") // 推奨値: 128k以上
.output(outputPath)
.on("end", () => {
console.log(`MP3 file created: ${outputPath}`);
// 元データを削除
// fs.unlinkSync(rawPath);
})
.on("error", (err) => {
console.error("Error during MP3 conversion:", err);
})
.run();
};
-
WebSocket から音声データを受信
クライアントから送られてくる音声データ(Buffer型)をWritableストリームを通じて一時ファイル(temp.raw)に保存します。一時ファイルは後で MP3 に変換するための元データとして使用します。const TEMP_FILE = "temp.raw"; // 一時ファイルへの書き込みストリームを作成 const tempFileStream = fs.createWriteStream(TEMP_FILE); // リアルタイムに音声を処理するためのストリームを作成 const audioStream = new Writable({ write(chunk: Buffer, encoding: string, callback: () => void) { tempFileStream.write(chunk); // TEMP_FILE にデータを書き込む callback(); }, }); // WebSocketで受信したデータをaudioStreamに流す ws.on("message", (message) => { audioStream.write(message); }); -
データの書き込み完了処理&MP3 変換
クライアントが接続を閉じたタイミングでストリームの終了処理を行い、一時ファイル(temp.raw)を MP3 に 変換します。変換にはfluent-ffmpegを使用します。yarn add fluent-ffmpegimport * as ffmpeg from "fluent-ffmpeg"; ws.on("close", () => { // ストリームを閉じる audioStream.end(); tempFileStream.end(); }); // ストリームが閉じられると下記が発火 tempFileStream.on("finish", () => { // 一時ファイルをMP3へ変換 ffmpeg(TEMP_FILE) .inputOptions("-f s16le") // PCM形式(16ビットリトルエンディアン) .inputOptions("-ar 44100") // サンプリングレート 44.1kHz .inputOptions("-ac 1") // モノラル .audioCodec("libmp3lame") // MP3エンコード .audioBitrate("192k") // 推奨値: 128k以上 .output("output.mp3") .on("end", () => { console.log(`MP3 file created`); }) .on("error", (err) => { console.error("Error during MP3 conversion:", err); }) .run(); });
少し長くなってしまいましたがサーバー側のコードはこれで完成です。実行してみると一時ファイルtemp.rawに音声が溜まっていき、ブラウザを閉じると MP3 への変換を開始します。

画面右下、一時ファイルの作成 →MP3 変換
3. 音声を文字起こし&要約
最後は文字起こしです。これは OpenAI の Whisper と GPT を使うだけで完了です。
クリックしてコード全体を見る
import { OpenAI } from "openai";
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
// ...省略
// TEMP_FILEの書き込み終了後にMP3変換を開始
tempFileStream.on("finish", () => {
// MP3変換
encodeToMp3(TEMP_FILE, OUTPUT_MP3_FILE);
// 文字起こし&要約
const text = audioToText(OUTPUT_MP3_FILE);
summarize(text);
});
// 文字起こし
const audioToText = async (audioPath: string) => {
try {
const response = await openai.audio.transcriptions.create({
model: "whisper-1",
file: fs.createReadStream(audioPath),
language: "ja",
response_format: "verbose_json",
});
console.log("✅ 音声テキスト化:", response.text);
return response.text;
} catch (error) {
console.error(
"Error during transcription:",
error.response?.data || error.message
);
}
};
// 要約
const summarize = async (content: string) => {
try {
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{
role: "system",
content: "以下の会議の音声を要約してください。",
},
{ role: "user", content: content },
],
max_tokens: 500,
temperature: 0.7,
});
console.log("✅ AI要約:", response.choices[0].message.content);
} catch (error) {
console.error("エラー:", error.response?.data || error.message);
}
};
yarn add openai
import { OpenAI } from "openai";
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
});
// 文字起こし
const response = await openai.audio.transcriptions.create({
model: "whisper-1",
file: fs.createReadStream(audioPath),
language: "ja",
response_format: "verbose_json",
});
// 要約
const response = await openai.chat.completions.create({
model: "gpt-4o",
messages: [
{
role: "system",
content: "以下の会議の音声を要約してください。",
},
{ role: "user", content: content },
],
max_tokens: 500,
temperature: 0.7,
});
以下のような感じで文字起こしと要約ができます。ヤッタネ!
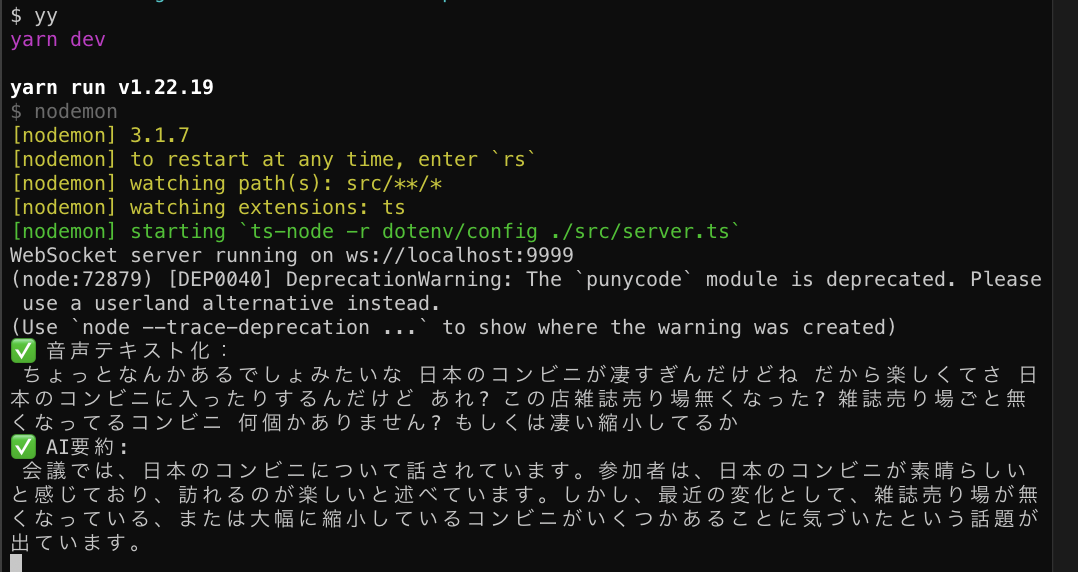
このあとはSlackに投げるなりNotionにまとめるなり、好きな方法で議事録として記録すると良いと思います。
4. (おまけ)リアルタイムに文字起こしする
せっかくリアルタイムに音声を取得しているので、最後にまとめて文字起こしするのではなく、リアルタイムに文字起こししたいです。リアルタイム文字起こしはGoogle Speech To Textが精度・速度ともに申し分ないのでおすすめです。60 分/月の無料枠もあります。
処理の流れとしてはSpeech-to-Textのストリームを作成して、一時ファイルの書き込み処理をしていたところに差し込むだけです。
yarn add @google-cloud/speech
import { SpeechClient } from "@google-cloud/speech";
wss.on("connection", (ws: WebSocket) => {
console.log("Client connected");
// Speech-to-Textのストリーミングリクエストを作成
const request = {
config: {
encoding: "LINEAR16" as const, // PCM形式
sampleRateHertz: 44100, // サンプリングレート (クライアントが送信する音声に合わせる)
languageCode: "ja-JP",
},
interimResults: true, // 中間結果を取得するかどうか
};
const recognizeStream = speechClient
.streamingRecognize(request)
.on("data", (data) => {
const transcription = data.results
?.map((result) => result.alternatives?.[0].transcript)
.join("\n");
// テキストを出力
console.log(`Transcription: ${transcription}`);
})
.on("error", (error) => {
console.error("Speech-to-Text error:", error);
});
// audioストリームのWriteにGoogle Speech To Textを差し込む
const audioStream = new Writable({
write(chunk: Buffer, encoding: string, callback: () => void) {
recognizeStream.write(chunk);
callback();
},
});
注意点としてはsampleRateHertz: 44100で指定するサンプリングレートは、クライアント側と合わせておく必要があります。クライアント側でconsole.log(audioContext.sampleRate)をすれば値が取得できます。ここを合わせておかないと処理が始まらないので注意してください。
実行すると以下の感じです。リアルタイムに文字起こしがされていってますね!

リアルタイム文字起こし
終わりに
今回ご紹介したコード全体はこちらです。
oVice 上の音声を取得し、文字起こしをしていきました。朝会やちょっとした雑談なども文字起こしをして要約したテキストを残しておくと、ふいに役立つことが多々あります。
今回の技術は oVice に限らず GoogleMeet などにも適用可能だと思うので、ぜひ遊んでみましょう。
最後までお読みいただきありがとうございました〜!
any株式会社ではナレッジ経営クラウドQastのエンジニアを絶賛募集中です。
是非採用ページをご覧ください!
興味がある方は、こちらよりご応募お待ちしております。
エンジニア組織/文化について詳しく知りたい方はこちら