顔のランドマーク検出は、多くのコンピュータビジョンアプリケーションにとって必要です。例えば、顔認識、頭部姿勢推定、顔の再現、および3D顔面再構成を含む多種多様なタスクに適用することができます。このブログは昔から最近までの顔ランドマーク検出の論文をいつくかピックアップして、紹介していきます。
はじめに
このブログの構成ですが、まずはランドマークの問題設定、次によく使われているデータセットとモデルの評価指標、最後に7本の論文紹介、というふうになっています。
問題設定
入力と出力
顔ランドマーク検出という問題では、入力が画像で、出力は顔のランドマーク座標です。ランドマークというのは顔の各パーツのキーポイント、例えば鼻先、顎、右目の瞳とかはキーポイントと言います。
入力: 出力:
出力: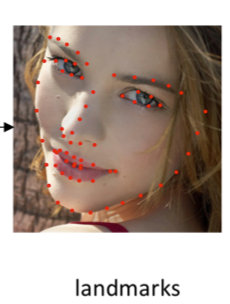 [1]
[1]
出力の形式
1 ベクトル: つまりモデルが直接座標のベクトルを出力します。例えば検出したいランドマークの数は全部68個あるとすると、モデルが136次元のベクトルを出力することになります。
[x1, y1, x2, y2, ..., x68, y68]
2 ヒットマップ
モデルがランドマークごとに、そのランドマークの信頼度マップを出します。例えば、サイズが256*256の画像が入力されると、モデルがnumpy.random.random((68, 256, 256))と同じshapeのテンソルを出力します。各ピクセルの値はランドマークがこのピクセルにある確率という意味合いを持っています。モデルのテンソルをmatplotlibで可視化すると、以下のようなものになります。
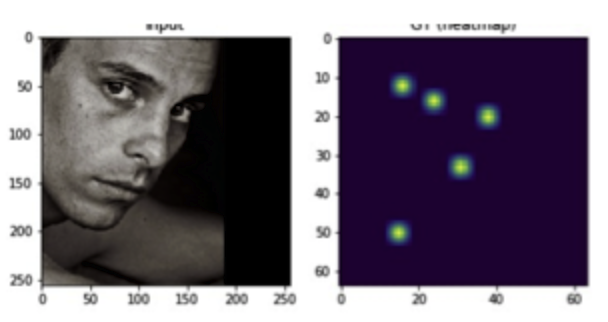
各ランドマークに対してスコア(確率)が一番高いピクセルの座標がランドマークの座標になります。
データセット&評価指標
データセット
顔ランドマークのデータセットは多数あります。主に使われているデータセットは以下の表にまとめました。
| データセット | 画像枚数(Train/Test) | 概要 |
|---|---|---|
| AFLW [2] | 20000/4386 | ランドマーク点数21点 |
| 300W [3] | 3148/689 | ランドマーク点数68点 |
| CelebA [4] | 182631/19926 | ランドマーク点数5点 |
| データセットによって、アノテーションがつくランドマークの点数と位置が違うので、複数のデータセットを使いたい場合はうまくこの差異を吸収する必要があります。 | ||
| 例えば68点と21点それぞれランドマークのアノテーションの手と番号の対応表は以下になります。 | ||
68点 
|
||
21点 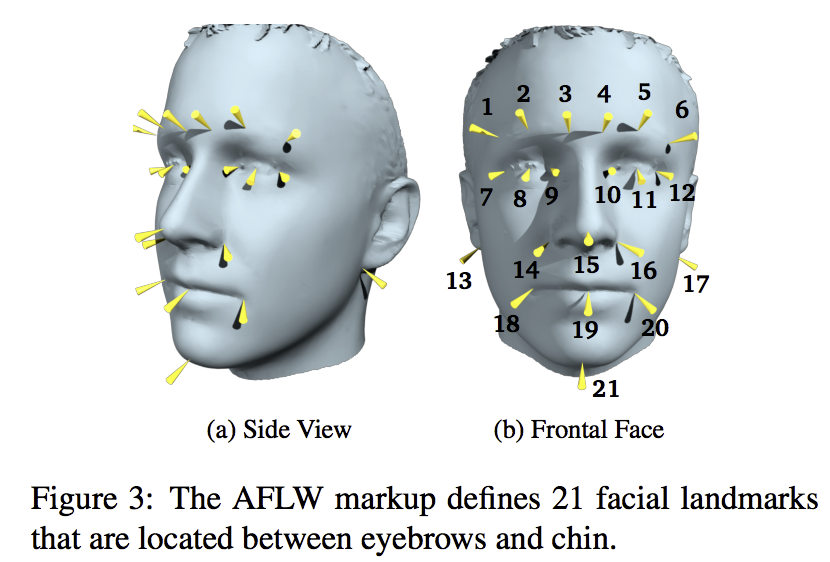
|
評価指標
モデルの性能はランドマーク誤差で測ります。 誤差の式は以下のようになります。
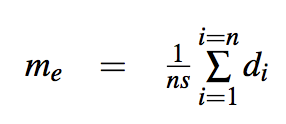 [5]
[5]
di: ground truthのランドマーク座標と予測のランドマーク座標のユークリッド距離。
n: アノテーションが付いていいるランドマーク数。データセットによって違います。
s: 正則項。よく使われているのは顔領域のbox boundingの対角距離です、両目の瞳の距離を使う場合もあります。
データセット全体の精度を見る場合、Cumulative Error Distribution(CED)カーブを使うと便利です。
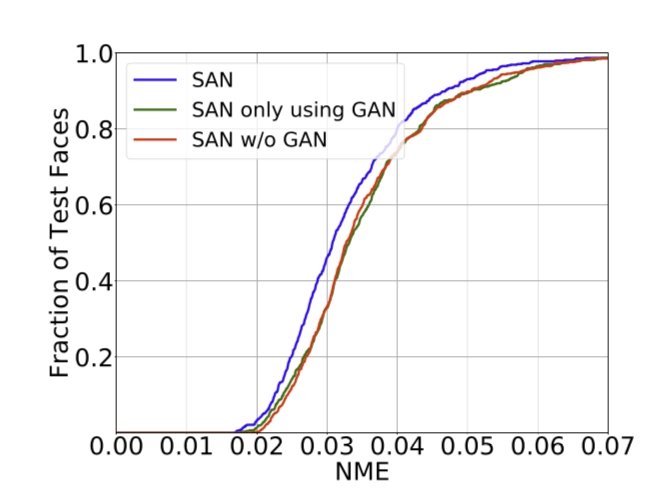 [6]
[6]
横軸はランドマークエラーで、縦軸はpercentageです。つまり、横軸の数字よりランドマークエアーが小さいデータの数は全体に占める割合は縦軸の数字の意味です。カーブは外側のモデルの方が精度が高いです。
論文紹介
1 Deep Convolutional Network Cascade for Facial Point Detection (CVPR2013)[7]
この論文の手法としては多段階でランドマークを検出、つまり、まず最初の段階でランドマークの大まかな位置を検出してから、次の段階で前の出力を徐々にrefineするという手法です。この論文の検出対象は顔の5点のみです。(Left Eye Center, Right Eye Center, Nose, Left Mouth Corner, Right Mouth Corner)
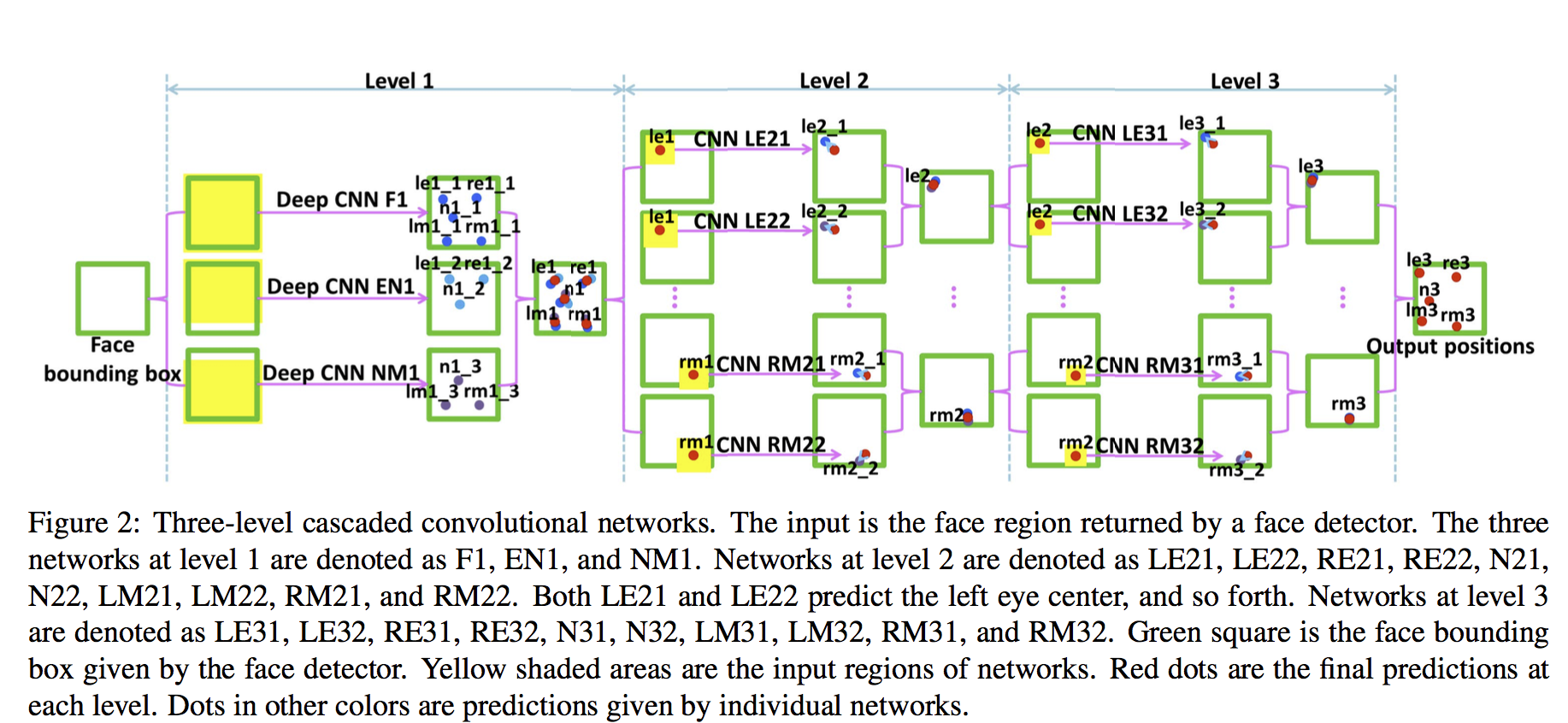
- 最初のステップではネットワークが三つあって、一つ目は五つのランドマークを検出するネットワークで、二つ目は目と鼻だけを検出するネットワーク、三つ目は口と鼻だけを検出するネットワーウです。この三つのネットワークの出力の平均を取って、一段階目の出力とする。この段階では顔領域が入力で、ランドマークの点の絶対座標が出力されます。
- 次に各のランドマークに対して、二つのネットワークを用意します。入力は顔領域ではなく、対象となるランドマークの点のground truthの位置を中心に、切り取った一定の範囲の領域です。 出力はランドマークの点の絶対座標ではなく、一段階目の出力との相対位置です。
- 三段階目も同じ感じで、相対座標を出力します。
この手法の特徴はランドマークごとに、専用のモデルが用意されているという点です。全部合わせて20個以上のモデルが使われています。なお、この論文は初めてDeep Learningの手法をランドマーク検出に導入した論文です。
2 Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade(ICCV2013)[8]
概要
この論文も多段階で顔ランドマークを検出する手法で、ただし、検出するランドマークの数は5点ではなく、68点です。点数がかなり増えたので、[7]の手法のように点ごとにネットワークを用意するわけには行かないので、顔のパーツごとにネットワークを用意するという手法になります。また、検出したい68点は顔の輪郭の17点と各パーツの51点に分かれていて、それぞれ別のアプローチで検出することになっています。
輪郭の部分では、輪郭をギリギリ含む矩形を検出するネットワークと矩形を入力として輪郭のランドマークを出力するネットワーク二つあります。
パーツ検出の部分も前半は輪郭検出のアプローチと似ていて、後半にさらにパーツをrefineするネットワークが用意されています。

実験
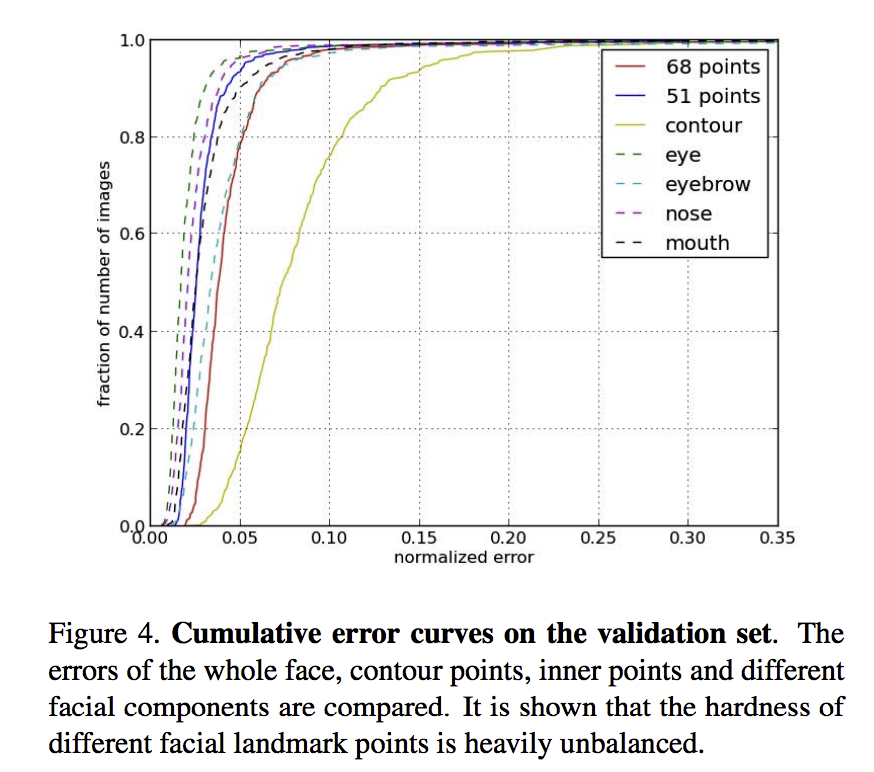
以下はパーツごとのランドマークエラーのCEDカーブです。この図を見ると、輪郭の曲線は一番内側で、輪郭を除く他のランドマーク、つまり51点のランドマークの曲線はより外側にあります。これは輪郭の点と顔のパーツの点を分けて検出するモチベーションです。
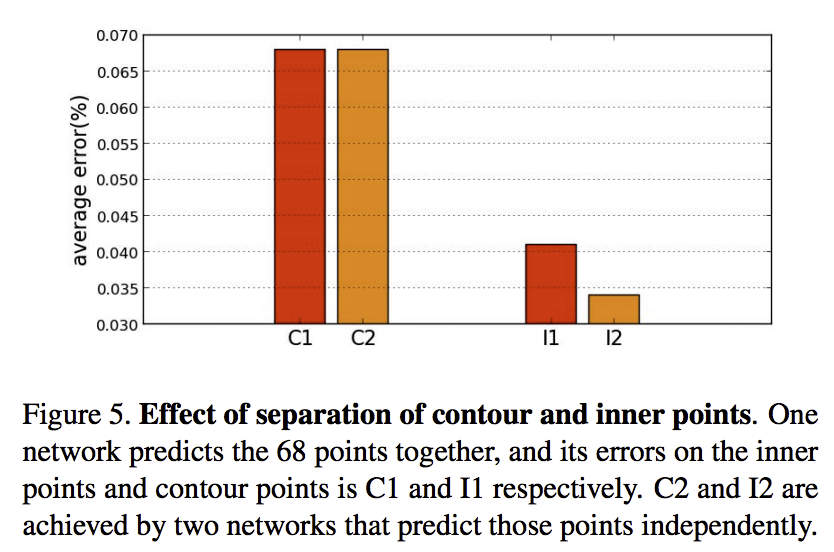
以下の図は、輪郭とパーツを一緒に検出するときに、輪郭の点と顔のパーツの点のエラーと分けて検出するときに、輪郭とパーツのエラーです。分けてやると、輪郭の方はそんなに変わらないですが、顔パーツの方がより精度がいいです。
3 Facial Landmark Detection by Deep Multi-task Learning (ECCV2014)[9]
概要
ランドマーク検出の精度向上に寄与するようなタスクを一緒にやるというのはここの論文の趣旨です。この論文では、メガネをかけるかどうかの検出、笑っているかどうかの検出、性別の分類、head poseの検出といった四つのタウs区をランドマーク検出と一緒に学習します。
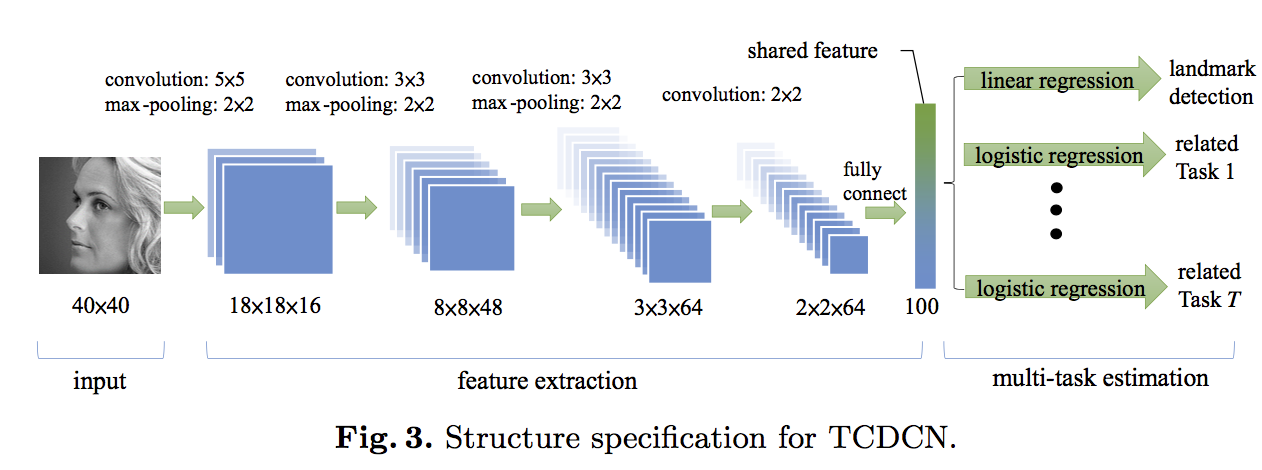
Task-wise early stop
個人的にはこの論文の新しいところはtask-wise early stopというところです。この四つのタスクの学習目的はタスク自体を高精度でやるというより、メインのタスクであるランドマーク検出の精度向上にあるので、四つのサブタスクを過学習すると、ランドマーク検出の精度に向上に寄与できなくなる、それどころか、精度を下げる可能性もありうるので、学習を止めるタイミングを見つける必要があります。また、四つのタスクはそれぞれメインタスクに寄与する度合いも学習難易度も違うので、止めるタイミングもそれぞれ違います。
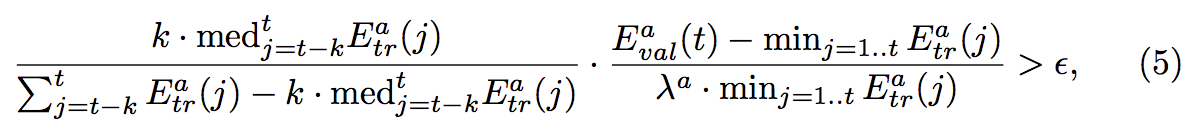
学習を止める条件は上の式にあります。一個目の部分は学習ロスの代わり具合を表しています。もし、直近のk iterationの中で、ロスが急速に下がる状態だったら、この値は小さい値になります。逆に直近のk iterationの中で、ロスがあまり変わらないなら、この値は大きい値になります。2個目の部分はvalidationデータのロスの比で、モデルの汎化能力を表しています。この二つの部分の掛け算が一定の閾値を超えたら、タスクの学習が止まるという仕組みになっています。
実験
1 下の図はマルチタスクで学習する時と、ランドマーク検出を単独で学習する時のランドマークエラーの図です。全部のタスクを一緒に学習という設定では一番エラーが低いことがわかります(図の水色のバー)。また、メインタスクと一つのサブタスクを同時に学習すると、サブタスクの種類によって、メインタスクの精度向上に寄与する度合いも変わります。
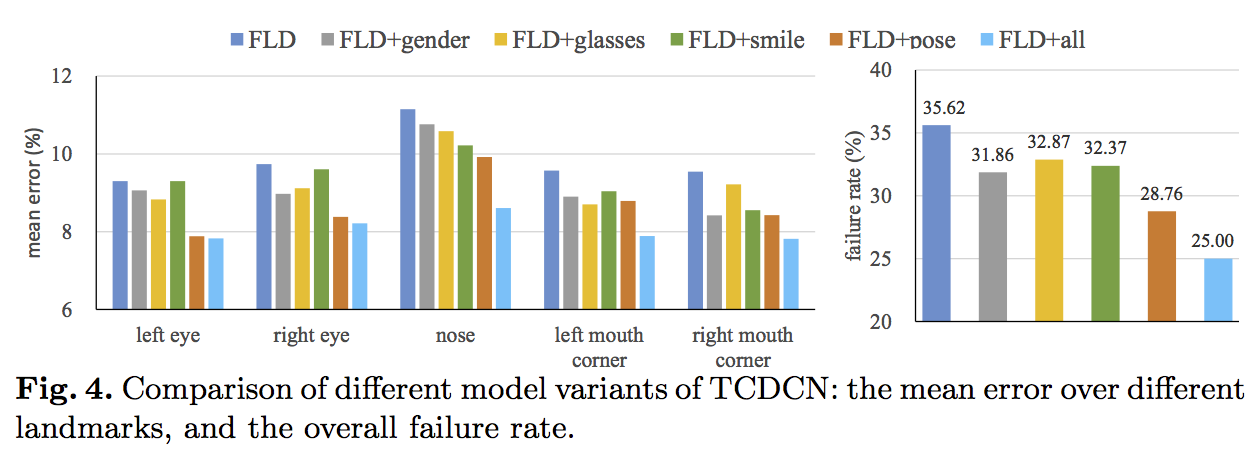
2 下の図はtask-wise early stopの有効性を示す図で、左の部分では、early-stopした方が精度がいいということが示されます。右の部分では、実際にどのiterationでどのタスクを止めるかというようなの情報が書いてあります。最初はまず、メガネ検出のタスクを止めて、次に性別分類のタスクを止めます、次に表情分析のタスクを止めて、最後にhead poseの学習を止めます。Head poseの学習が止まった時点で、validationデータのロスがグッと下がったことが分かります。

4 Deep Alignment Network: A convolutional neural network for robust face alignment (CVPR2017)[10]
顔のパーツごとにそのパーツ専用のネットワークを学習する、またネットワークに入れる画像は顔全体ではなく、パーツの領域のみと言うようなやり方だと、 頭部の姿勢の変化が大きい顔画像を扱うのは難しくなると言うのがこの論文の提案手法のモチベーションです。
 上記の図はモデルのアーキテクチャーの全体像です。マルチstageのようなアーキテクチャで、まずランドマークの大まかの位置を出してから、徐々にrefineしていく、と言うようなアルゴリズムです。
上記の図はモデルのアーキテクチャーの全体像です。マルチstageのようなアーキテクチャで、まずランドマークの大まかの位置を出してから、徐々にrefineしていく、と言うようなアルゴリズムです。
一つのstageには3つの入力があります。一つは正規化された後の顔画像で、もう一つは正規化されたランドマークのheatmapで、最後は一個前のstageのfeature mapにFC層かけたものです。出力は正規化された後のランドマークの差分の情報です。(論文ではface shapeと呼んでいます)。
今の差分と一つ前のstageの正規化された後のランドマークを足し合わせて、正規化変換の逆変換をかけて、正規化される前、つまりオリジナル画像の座標系におけるランドマークを算出する。それを用いて、、次のステージの入力を算出します。その仕組みはconnection layerです。(図で言うと、connection layer)。
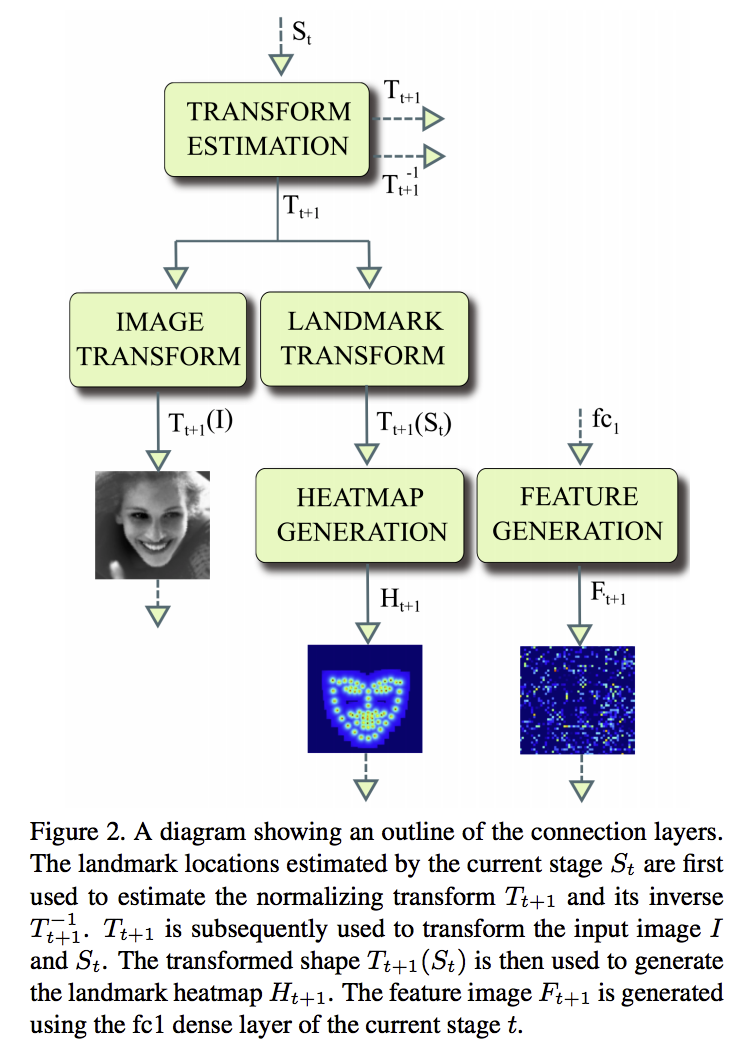 <--Connection Layer
<--Connection Layer
このconnection layerをもうちょっと詳しくみてみますと、入力は元画像におけるランドマークの情報です。この情報から、画像を正規化するためのの変換パラメーターTと逆変換パラメーターT’を算出します。
次に元画像に変換パラメータによって、変換をかけて、正規化された画像を算出します。 また、元画像におけるランドマークに変換パラメーターをかけて、正規化された画像におけるランドマークを算出し、headmapも出します。
最後にfeature generation部分の入力は一個前stageのfeed forward nnの出力になります。
学習の手順ですが、まず、stage1のconnection layer以外の部分を学習する。ロスが収束すると、stage1のconnnection layerとstage 2のconnection layer以外の部分を学習すると言うような感じになります。 実験では2stageのモデルが使われています。
コードも公開されているので、下記のリンクから辿れます。
https://github.com/MarekKowalski/DeepAlignmentNetwork
5 Robust Facial Landmark Detection via a Fully-Convolutional Local-Global Context Network (CVPR2018)[11]
FCNを用いるランドマーク検出の論文です。全部畳み込み層のモデルのメッリトは入力画像のサイズに関係なく、検出性能は保たれること、顔のbounding boxを必要としないこと、同時に複数の顔のランドマーク検出が検出できること、一方で欠点はグローバルな情報をうまく獲得できないということです。
この論文では、dilated 畳み込み層から構成されたグローバルsubnetを設けることで、 グローバルな情報も獲得できるようにする。

ネットワークの構造を見ていくと、入力データはまずlocal subnetを通して、次にkernel convolutionに通します。 Kernal convolutionはfilterごとに、畳み込み計算を行っていて、smoothingのようなことをします。最後にdilated 畳み込み層から構成されたグローバル subnetを通して、ランドマークのheatmapを出力します。 最終の出力heatmapはglobal networkの出力とlocal networkの出力を足し合わせたものになります。

上はHeatmapの図です。上の行はlocal subnetの出力で、下の行はlocal subnetとglobal subnetの出力を足し合わせたものです。グローバルな情報を持つglobal subnetの出力によって、local subnetの間違っている出力は修正されたことが分かります。

全部畳み込み層のモデルのメッリトの一つ、同時に複数の顔のランドマーク検出が検出できることを説明します。 上の図では、左側が検出の仕組みです。入力画像をいくつかの解像度にresizeして、それぞれモデルに入力します。 それぞれのheatmapをマージします。Combinedの方は最終結果です。このような手法を右の三つの画像に適用した結果は右の方の2行目のheatmapです。 たくさんの顔が同時に検出されたことがわかります。
6 Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors (CVPR2018)[12]
以下のリンクに本論文のデモが見れます。
https://github.com/facebookresearch/supervision-by-registration
デモの左の図は既存の手法で検出された結果、右はこの論文で提案された手法の結果です。デモを見ればわかるように、 提案手法の結果の方が安定していて、左は揺らぎが相対的に激しいです。この論文はアノテーションなしのビデオをモデル学習に使うことで、ランドマーク精度の向上と検出結果の安定化を実現させました。

どうやってアノテーションなしの動画を使うかというと、動画の連続の2フレームを考えます。base-detectorを用いてフレーム1から検出したランドマークとlucas-kanadeトラッキング手法から算出したランドマークの変化量を足し合わせて、フレーム2のランドマークを算出します。 それをbase-detectorを用いてフレーム2から検出したランドマークとの差分を教師信号として トラッキングのパラメーターとbase detectorのパラメーターを学習します。
 全体の流れを見ていくと、まずアノテーション付きの画像データでbase-detectorを学習します。ある程度精度が出る段階で、アノテーションなしの動画でlucas-kanade手法を使って、base-detectorを再学習します。 テスト時はbase-detectorのみを使って精度評価します。 という流れになります。
全体の流れを見ていくと、まずアノテーション付きの画像データでbase-detectorを学習します。ある程度精度が出る段階で、アノテーションなしの動画でlucas-kanade手法を使って、base-detectorを再学習します。 テスト時はbase-detectorのみを使って精度評価します。 という流れになります。
上の図の3 Testing procedureの中の右下の方はビデオを入力としたランドマークエラーの時系列の変化図です。 青い線は提案手法の結果で、赤い線は既存手法の結果です。 提案手法の方はエラーが小さいだけじゃんくて、 揺らぎもそんなに激しくないことがわかります。
7 Look at Boundary: A Boundary-Aware Face Alignment Algorithm(CVPR2018)[13]

この論文では、boundaryという概念があります。顔の各パーツのランドマークを線で繋いで、それを各パーツの境界線boundaryと呼びます。 ランドマークを推定する前に、一回boundaryのheatmapを生成します。次に、入力画像と先ほど生成したheatmapの情報を融合してランドマーク推定の入力とします。また、 GANを使って、生成したboundaryのheatmapの質をよくします。
そもそも、なぜ境界線を使うかというと、ランドマークのアノテーションは顔のポーズの変化が大きいことやオクルージョンによって、曖昧性が生じます。 特に、顔の輪郭の部分のランドマークはannotatorによって、同じ点に対してつけた位置は微妙に変化します。なので、より正確に定義できるランドマークの
境界線を推定することによって、ランドマークを精度を高めるのはモチベーションになります。
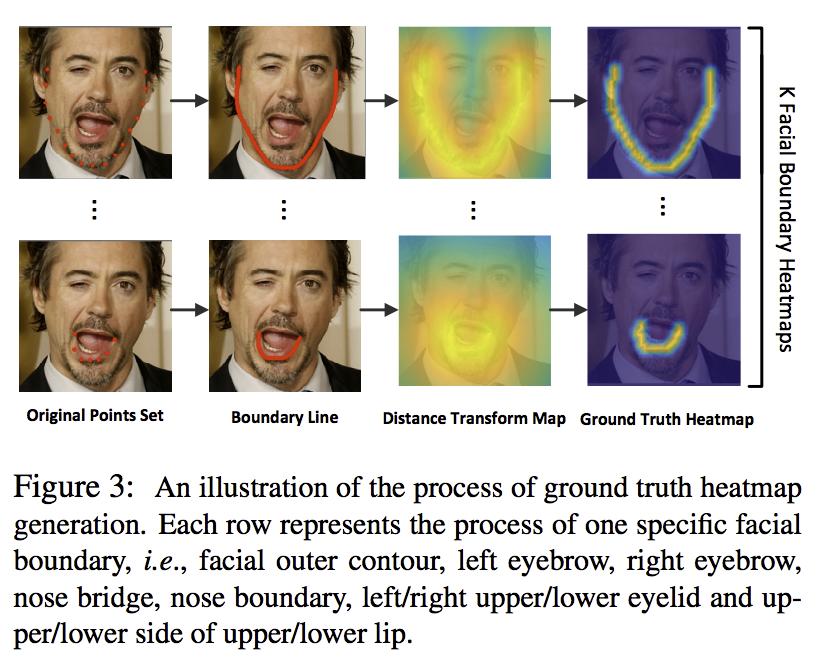
具体的に、顔の境界線を説明します。 顔のパーツごとに、境界線を定義します。例えば、顔の輪郭の境界線、下の唇の境界線など。次に、distance mapを定義します。各ピクセルの位置から境界線の距離をピクセルの値とする距離マップです。その距離マップにgaussianフィルタをかけて、実際の境界線heatmapを作ります。
モデルの学習の流れですが、まずは境界線のheatmapを予測するネットワークを学習します。Ground truthから算出したheatmapとネットワーク出力の二乗誤差はロスになリます。それに加えて、ganの仕組みを導入して、heatmapのgeneratorとdiscriminatorを学習することで、生成したheatmapを質を高めます。最後に、heatmapと画像をregressorに入力して、実際にランマークの座標を予測します。

まとめ
この記事は顔ランドマークの問題設定、データセット、評価指標、最近の手法について話しました。 ランドマーク検出手法は2013年あたりの直接ランドマーク座標を回帰する方法から、ランドマークのheatmapにシフトしていることがわかります。また、最近流行っているGANとの組み合わせ([13])も注目して行く必要があります。
Reference
- Direct Shape Regression Networks for End-to-End Face Alignment https://xinxinmiao.github.io/pdfs/1607.pdf
- Annotated Facial Landmarks in the Wild: A Large-scale, Real-world Database
for Facial Landmark Localization http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.384.2988&rep=rep1&type=pdf - 300 faces in-the-wild challenge: The first facial landmark localization challenge. https://ibug.doc.ic.ac.uk/media/uploads/documents/sagonas_iccv_2013_300_w.pdf
- Deep learning face attributes in the wild. https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Liu_Deep_Learning_Face_ICCV_2015_paper.pdf
- Feature Detection and Tracking with Constrained Local Models https://pdfs.semanticscholar.org/c2a3/850becae2799b0e591e7ab1008b84897d6e9.pdf
- Style Aggregated Network for Facial Landmark Detection http://openaccess.thecvf.com/content_cvpr_2018/papers/Dong_Style_Aggregated_Network_CVPR_2018_paper.pdf
- Deep Convolutional Network Cascade for Facial Point Detection(CVPR2013)
- Extensive Facial Landmark Localization with Coarse-to-fine Convolutional Network Cascade(ICCV2013)http://openaccess.thecvf.com/content_iccv_workshops_2013/W11/papers/Zhou_Extensive_Facial_Landmark_2013_ICCV_paper.pdf
- Facial Landmark Detection by Deep Multi-task Learning (ECCV2014)
- Deep Alignment Network: A convolutional neural network for robust face alignment (CVPR2017)
- Robust Facial Landmark Detection via a Fully-Convolutional Local-Global Context Network (CVPR2018)
- Supervision-by-Registration: An Unsupervised Approach to Improve the
Precision of Facial Landmark Detectors (CVPR2018) - Look at Boundary: A Boundary-Aware Face Alignment Algorithm(CVPR2018)