本記事は「データ収集の悩みを一気に解決!Bright Dataの次世代Webスクレイピングにチャレンジ」キャンペーンへの参加記事です。
https://qiita.com/official-events/1edc21144733ca1cd2bd
はじめに
「GitHub Trendingを見て技術キャッチアップしたいけど、毎日見るのは大変…」
「スクレイピングでデータを集めたいけど、すぐにアクセスブロックされてしまう…」
そんな悩みを解決するために、「安定して取得できるようにするスクレイピング」 と 「AIによる自動トレンド分析」 を組み合わせた、自分専用の技術トレンド発掘ツールを作ってみました。
作ったもの
ボタン一つでGitHubのトレンドを取得し、グラフで可視化し、さらにGemini Proが「今週のトレンド」を技術者目線で解説してくれるWPFアプリです。
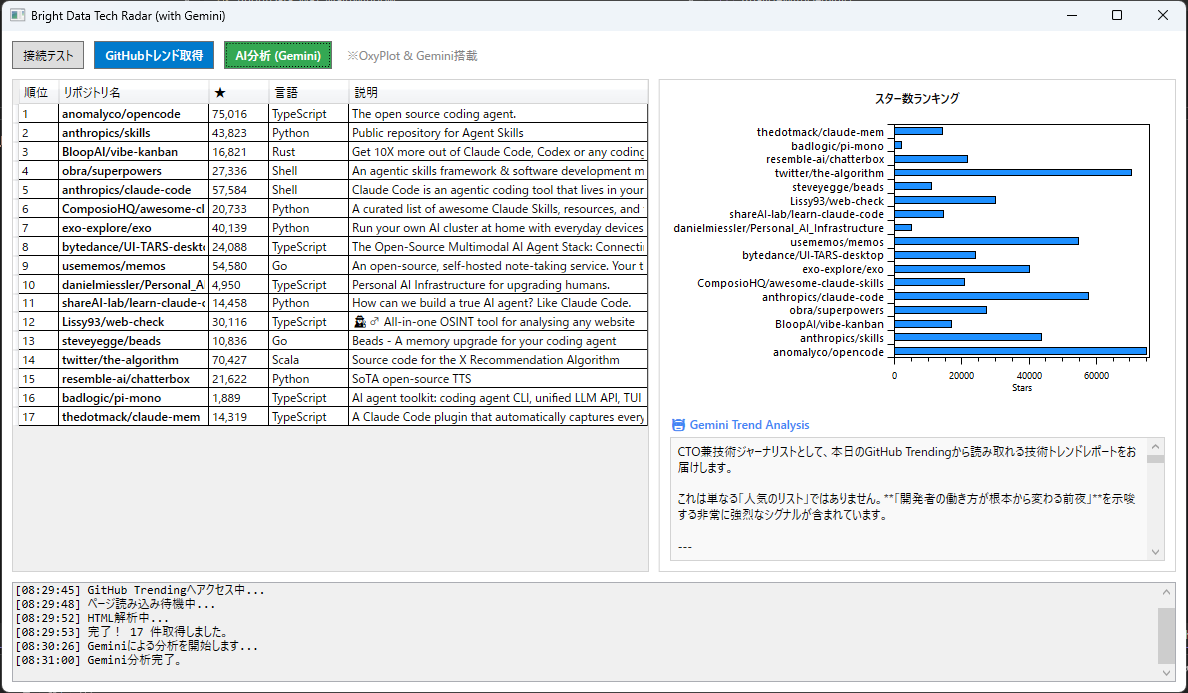
技術スタック
今回は「Windowsアプリとしてサクサク動くもの」を目指して、以下の構成で開発しました。
- 言語/FW: C# (WPF, .NET 8)
- スクレイピング: Microsoft Playwright
- プロキシ: Bright Data (ISP Proxy) ← 今回の要!
- グラフ描画: OxyPlot
- AI分析: Google Gemini API (gemini-3-pro-preview)
技術スタック選定:なぜPythonではなくC# (WPF) なのか?
WebスクレイピングやAI分析といえばPythonが定番ですが、今回はあえて C# (.NET 8) と WPF を採用しました。
「Windowsでサクサク動く自分専用ツール」を作る上で、C#にはスクリプト言語にはない強力なメリットがあるからです。
1. LINQによるデータ操作と将来のDB連携
スクレイピングで取得したデータは、フィルタリングや並び替えなどの加工が欠かせません。C#には LINQ (Language Integrated Query) という、SQLのような記述でメモリ内のオブジェクトを自在に操作できる強力な機能があります。
さらに、今回はリスト(メモリ上)で管理していますが、データ量が増えて SQLiteなどのデータベースで履歴管理 したくなった場合でも、C#なら Entity Framework を使うことでスムーズに移行できます。将来的な拡張性が非常に高いのが強みです。
2. Async/Await による快適なUI体験
スクレイピングやAI分析は、ネットワーク通信待ちが発生する重い処理です。C#の async/await パターンを利用すれば、複雑なマルチスレッド処理を書かなくても、「処理中も画面がフリーズしない」 モダンなGUIアプリが簡単に実装できます。
3. 静的型付けによる「壊れにくさ」
Webスクレイピングは、サイト側の仕様変更や想定外のデータで容易にエラーになります。動的型付け言語では実行するまで気づけないエラーも、C#ならコンパイル時点で型チェックが働くため、「運用中に突然落ちる」リスクを減らせます。この堅牢性が開発効率を大きく支えてくれました。
課題:なぜBright Dataなのか?
Webスクレイピング開発において、避けて通れない技術的課題が 「アクセス制限(IPブロック)」 です。
GitHubなどの大手サイトはセキュリティ対策として、AWSやAzureといった「データセンターのIPアドレス帯域」からのアクセスを一律で制限しているケースが多くあります。コードが正しくても、ネットワーク元の信頼性が理由で 403 Forbidden となってしまうのです。
そこで採用したのが、Bright Dataの「ISPプロキシ」 です。
- 特徴: データセンターではなく、実在するプロバイダ(ISP)と契約されたIPアドレスを使用できる。
- メリット: 一般的なユーザーと同じネットワーク環境からのアクセスとして扱われるため、IPレピュテーション(信頼スコア)が高く、安定した接続が可能になる。
今回は、C#のPlaywrightとこの高品質なプロキシを組み合わせることで、「実際のユーザーと同じブラウザ環境を再現し、安定してデータを取得する」 設計を行いました。
実装ステップ
1. Bright Dataでプロキシを用意する
まず、Bright Dataのダッシュボードから「ISPプロキシ」の利用設定を行います。
Bright Data 公式サイトはこちら
驚いたのはその手軽さです。数クリックで「日本の住宅用IP」の接続情報(ホスト、ユーザー名、パスワード)が手に入りました。
 [ISPモード設定画面]
[ISPモード設定画面]
登録が完了したらダッシュボードが作られ、そこに接続先ポート情報、パスワード等が書かれているのでそれらの情報を使用して作業を行っていきます。
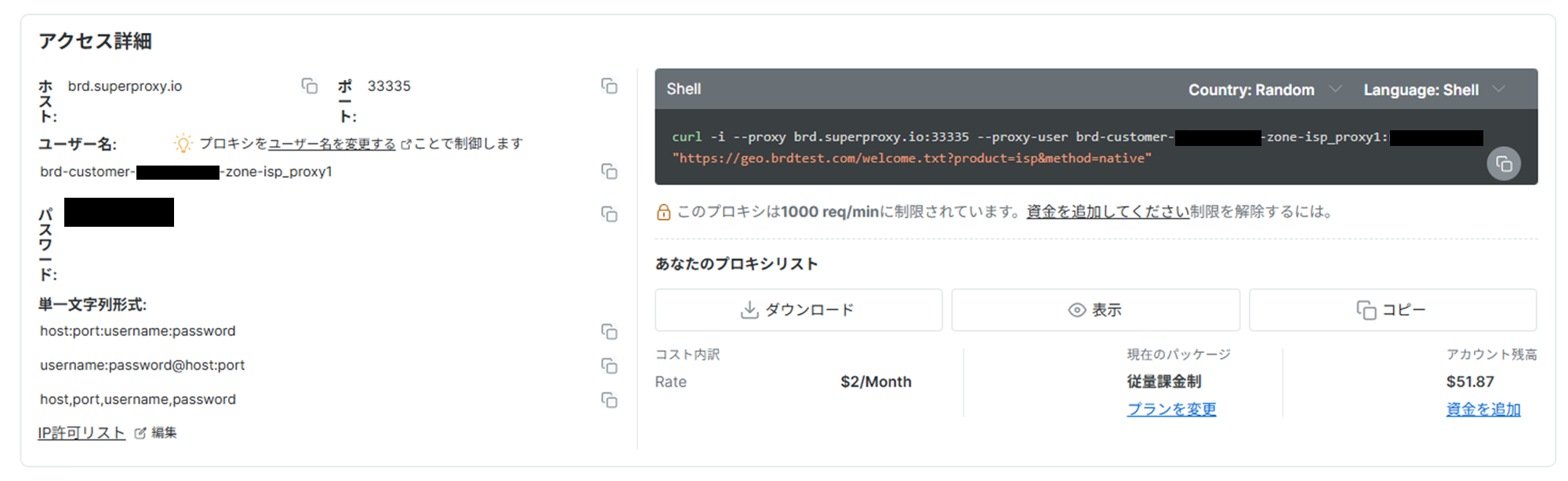 [ダッシュボード画面]
[ダッシュボード画面]
2. Playwrightでの接続設定 (C#)
ここが実装のキモです。Playwrightのブラウザ起動オプションに、取得したプロキシ情報をセットします。これだけで、全ての通信がプロキシ経由になります。
// ブラウザ起動用ヘルパーメソッド
private async Task<IBrowser> LaunchBrowser(IPlaywright playwright)
{
// Bright Data設定 (ご自身の情報に置き換えてください)
const string ProxyHost = "brd.superproxy.io:33335";
const string Username = "brd-customer-hl_xxxx-zone-isp_proxy1";
const string Password = "your_password";
return await playwright.Chromium.LaunchAsync(new BrowserTypeLaunchOptions
{
// 動作確認のため、あえてブラウザを表示する
Headless = false,
// ▼ ここでプロキシを設定! ▼
Proxy = new Proxy { Server = $"http://{ProxyHost}", Username = Username, Password = Password }
});
}
3. 【検証】まずは「接続テスト」でプロキシの威力を確認
いきなりGitHubへ行く前に、「本当にプロキシ経由で接続できているか?」 を確認します。Bright Dataが提供するデバッグ用ページにアクセスし、認識されているIP情報を取得するコードです。
private async Task RunTestConnection()
{
using var playwright = await Playwright.CreateAsync();
// 先ほど定義したプロキシ設定付きのブラウザを起動
var browser = await LaunchBrowser(playwright);
var page = await browser.NewPageAsync();
Log("接続テストページへアクセス中...");
// Bright Dataの接続確認ページへ
await page.GotoAsync("https://geo.brdtest.com/welcome.txt?product=isp&method=native");
var content = await page.Locator("body").InnerTextAsync();
Log($"結果:\n{content}");
await browser.CloseAsync();
}
実行結果(ログ):
[07:06:34] 結果:
Welcome to Bright Data!
Country: JP
City: Kawasaki
...
ASN Organization name: Hydra Communications Ltd
IP version: IPv4
ログのCountry: JP (日本) などが想定通りで、IPがプロキシ経由に切り替わっていればまず成功です。
※ASN名などはネットワーク条件によって表示が変わる場合があります。
4. スクレイピングの実装(本質部分)
いよいよ本丸、GitHub Trendingからのデータ取得です。
プロキシ経由でのアクセスは通常より時間がかかることがあるため、タイムアウト設定や待機処理を丁寧に行うのがコツです。
以下は、実際に動作している様子の動画と、スクレイピングの中核となるコードです。
(動作デモ動画)
※ 動画では動作の流れを分かりやすくするためにブラウザを表示(Headless = false)していますが、コード内の設定を Headless = true に変更することで、ブラウザを非表示(バックグラウンド)にして実行することも可能です。
スクレイピング核心部のコード:
private async Task RunGitHubScraping()
{
using var playwright = await Playwright.CreateAsync();
var browser = await LaunchBrowser(playwright);
var page = await browser.NewPageAsync();
// 【重要】PC画面として認識させる(スマホ表示回避)
await page.SetViewportSizeAsync(1920, 1080);
Log("GitHub Trendingへアクセス中...");
// 【重要】タイムアウトを延長し、読み込み完了条件を緩和する
await page.GotoAsync("https://github.com/trending?since=monthly", new PageGotoOptions
{
Timeout = 120000, // 120秒まで待つ
WaitUntil = WaitUntilState.DOMContentLoaded // HTML構造が来ればOKとする
});
Log("ページ読み込み待機中...");
// 念のためネットワークが落ち着くまで待ち、最下部までスクロールして遅延ロードを誘発
await page.WaitForLoadStateAsync(LoadState.NetworkIdle);
await page.EvaluateAsync("window.scrollTo(0, document.body.scrollHeight)");
await Task.Delay(2000); // 少し休憩
Log("HTML解析中...");
// リポジトリの各行要素を取得
var rows = await page.Locator("article.Box-row").AllAsync();
// 各行からデータを抽出するループ
foreach (var row in rows)
{
// Playwrightのロケーターを使って要素を特定し、テキストを取得
var name = await row.Locator("h2 a").InnerTextAsync();
// 説明文(ない場合もあるのでチェック)
var descLocator = row.Locator("p");
var description = (await descLocator.CountAsync() > 0) ? await descLocator.InnerTextAsync() : "";
// 言語
var langLocator = row.Locator("[itemprop='programmingLanguage']");
var language = (await langLocator.CountAsync() > 0) ? await langLocator.InnerTextAsync() : "-";
// スター数 ("12.5k" などの文字列)
var starText = await row.Locator("div.f6 a").First.InnerTextAsync();
// (以下、取得したデータをUIに表示する処理へ続く...)
}
await browser.CloseAsync();
}
このコードにより、プロキシ経由でも安定しやすい条件を整えつつ、データを抽出することが可能になりました。
※アクセス制限はサイト側の仕様変更等で変動するため、状況に応じて待機時間や取得頻度は調整してください。
5. グラフ化とAI分析 (Geminiで要約・分析(プロンプトへデータ埋め込み))
取得したデータは OxyPlot で可視化し、さらに Gemini API に投げてトレンド分析を行います。単なるデータリストが、AIの力で「意味のあるレポート」に変わります。
Gemini分析コード(抜粋):
private async Task AnalyzeWithGemini()
{
// 1. 取得したリポジトリデータを元に、AIへの指示書(プロンプト)を作成
var sb = new StringBuilder();
sb.AppendLine("あなたはベテランの技術ジャーナリスト兼CTOです。");
sb.AppendLine("以下のGitHubトレンドリストを分析し、専門的なレポートを作成してください。");
// ... (分析の指針などを記述) ...
sb.AppendLine("【入力データ】");
foreach (var repo in Repositories)
{
// 取得した生データをプロンプトに埋め込む
sb.AppendLine($"- 名前: {repo.Name} | 言語: {repo.Language} | 説明: {repo.Description}");
}
// 2. Gemini API へ送信 (HttpClientを使用)
var url = $"https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent?key={GeminiApiKey}";
// ... (JSONボディの作成とPostAsyncによる送信処理) ...
// 3. 結果を受け取り、UIに表示
// ...
}
実行結果 (AI分析例)
ボタンを押すと、データ取得からAI分析までが自動で行われます。
Geminiからの出力例:
市場の潮流:
現在、単なるチャットボットを超えた「自律型エージェント」の開発ツール(claude-codeなど)が急増しています。開発プロセスの自動化への関心が非常に高いです。
注目のHidden Gem:
Personal_AI_Infrastructureに注目です。ローカルLLMを個人で運用するための基盤作りがトレンドになりつつあります。
ソースコード公開
今回作成したアプリケーションの全ソースコードはGitHubで公開しています。
ぜひ手元で試してみてください。
⚠️ スクレイピングを行う際の技術的・倫理的配慮
本記事では技術的な検証としてスクレイピングを行っていますが、実運用においては相手先サーバーへの配慮とルールの遵守が不可欠です。Bright Dataのような強力なツールを使うからこそ、以下の点には特に注意しましょう。
1. サイトの利用規約 (ToS) の確認
Webサイトによっては、利用規約でスクレイピングを明示的に禁止している場合があります。データを取得する前に、必ず対象サイトの Terms of Service を確認し、許容される範囲内で行ってください。
※GitHubはAPI提供があり、可能な限りAPI利用が推奨されています。
2. サーバー負荷への配慮 (アクセス頻度)
プロキシを使ってブロックを回避できるからといって、短時間に大量のリクエストを送る(DoS攻撃のような)行為は絶対に行ってはいけません。
今回のコードでは、await Task.Delay(2000); などを挟んで意図的に処理を遅らせていますが、大量のデータを取得する際は、必ず十分な待機時間(インターバル) を設けて、相手サーバーに負荷をかけない設計を心がけましょう。
3. robots.txt の確認
サイトのルートにある robots.txt ファイルを確認し、クローラーのアクセスが許可されているパスかどうかを確認するのがマナーです。
4. 取得したデータの取り扱い
取得したデータを自分の分析用に使うことは問題ありませんが、それを「自分のコンテンツ」として無断で再配布したり販売したりすることは、著作権法に触れる可能性があります。
まとめ:C# × Bright Data で広がる「自分だけの情報収集ツール」
今回作成したツールを通じて、Bright Data (ISPプロキシ) があれば、スクレイピングの最大の障壁である「接続エラー」を大幅に減らし、安定性を大きく改善できたことが実証できました。
最後に、この構成のポテンシャルについて振り返ります。
今回の構成の汎用性
この「プロキシ × スクレイピング × AI要約」のトライアングルは、GitHub以外にもあらゆる場面で応用可能です。
- ECサイトの価格調査: 競合製品の価格変動を監視し、安値になったら通知する。
- ニュース・SNS分析: 特定のキーワードに関する記事を集め、AIにポジティブ/ネガティブ判定をさせる。
- SEO順位計測: 自社サイトの検索順位を、IPによる地域指定(ジオターゲティング)を使って正確に計測する。
「データが取れない」という悩みがなくなった今、アイデア次第でどんなデータも価値に変えられます。
なぜ C# (Windowsアプリ) なのか?
PythonではなくC#を選択したメリットは、開発が進むにつれて強く感じられました。
-
デスクトップとの強力な統合:
Webアプリとは違い、タスクトレイへの常駐や、OSネイティブな通知(Toast通知)の実装が容易です。「異常値を検知したら即デスクトップに通知」といった機能も数行で追加できます。 -
堅牢なデータ管理:
今回はリストで簡易管理しましたが、C#には Entity Framework という強力な武器があります。これをSQLiteやSQL Serverと繋げば、数年分のトレンドデータを蓄積し、より高度な分析を行う「本格的なBIツール」へとスムーズに進化させられます。 -
企業導入のしやすさ:
多くのWindows環境の企業において、C# (.NET) 製のツールは配布・導入が容易です。社内用の自動収集ツールとして展開する場合、この堅牢性は大きな武器になります。
結び
「スクレイピングはブロックとの戦い」という常識は、Bright Dataのようなサービスを使うことで変わりました。
インフラの心配から解放され、「データをどう活用するか」「どうAIで付加価値をつけるか」 という本質的なクリエイティブに集中できる環境は、開発者にとって非常に快適です。