諸事情でperfのソースコードを読んだのでせっかくなので簡単に解説。
今回はperfの中でもイベントの記録を担当するperf recordコマンドの処理を見ていく。特に近年はCPUがトレース機構を持っておりperfもその恩恵に預かっているため、本記事ではperf recordの中でもCPUのプロセッサトレース機構との連携部分に注目したい。
本音を言えば、perfよりIntel Processor Trace(Intel PT)やARM CoreSightといったプロセッサトレース自体に興味があるのだが、これらはLinux上ではperfイベントとして実装されているためperfコマンドの実装を皮切りに解析する腹づもりだ。
1. Perf アーキテクチャ
元々perfはPerformance counters for Linux (PCL)という名前の前身が存在しており、CPUの提供するパフォーマンスカウンタ(PMC)へのインターフェースツールとして提供されていた。今ではパフォーマンスカウンタ以外にも様々なソースへアクセスが可能であり、より汎用的なトレースツールとなっている。
下図にアーキテクチャの概要を載せる。今時のperfはPMC以外にもk/uprobeといったトレース、Linuxカーネル内の各種イベントやハイパーバイザ上のゲストOSの情報(perf kvm)までアクセス可能となっている。
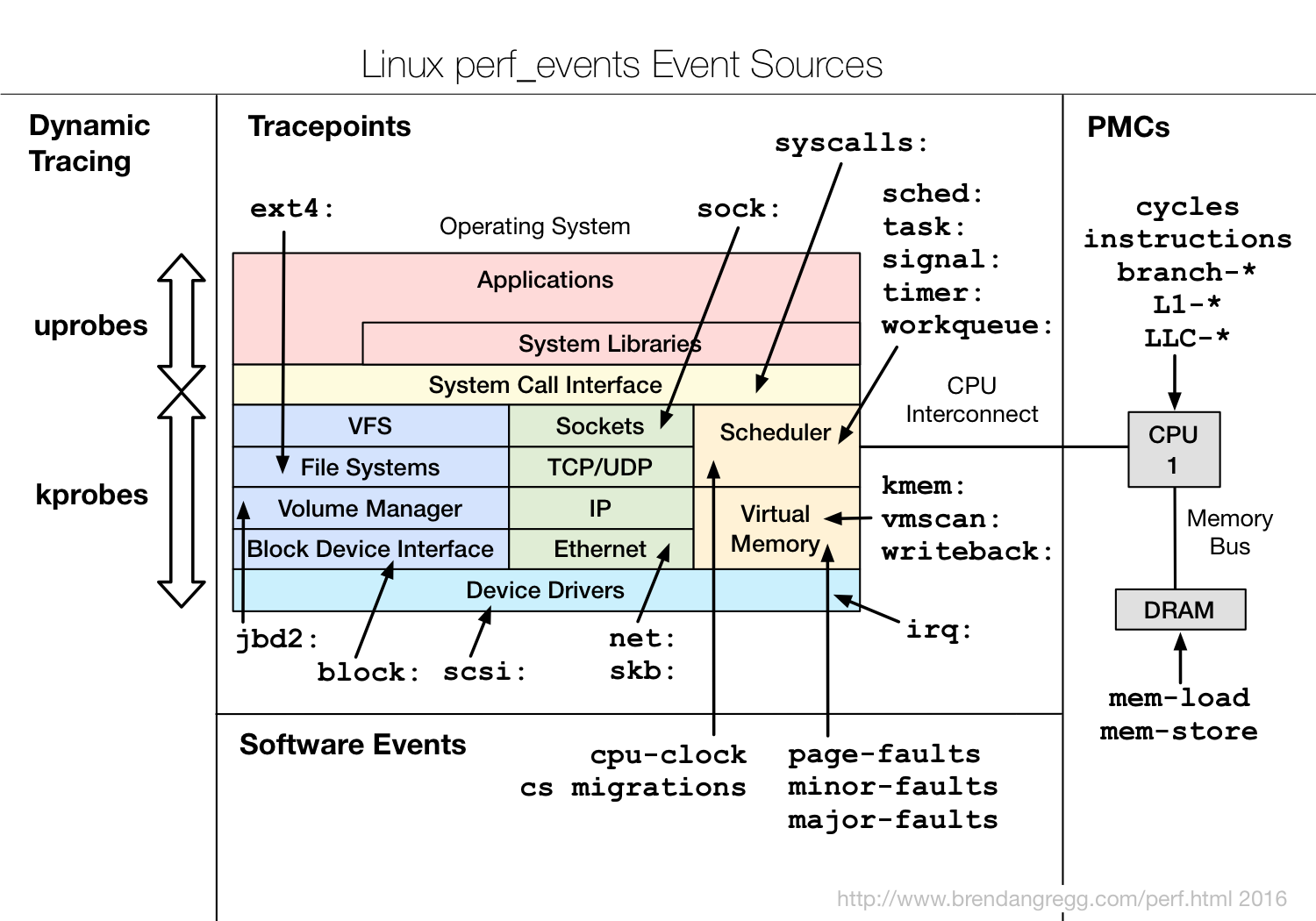 [^4]より引用
[^4]より引用
アクセス可能なソースはsudo perf listで表示可能だ。
$ sudo perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
これらのソースはperf内部でPERF_TYPE_HARDWAREやPERF_TYPE_SOFTWAREのようにソフトウェア|ハードウェアによるソースの種類の違いやイベントで分類されている。
perfコマンドからソースを指定するには**-eオプション**を使用すれば良い。例えば/bin/lsのページフォルトに関するイベントを記録したい場合は以下のようにする。
$ sudo perf record -vv -e page-faults /bin/ls
$ perf report
サードパーティなプログラムからperfのイベントを取得するためにはperf_event_open(2)にソースのタイプをPERF_TYPE_XXXXで指定すればよい。
(そういえば昔perf_event_open(2)で特権昇格できる脆弱性あったね)
2. Perf recordの仕組み
まずはperf recordのメイン処理であるイベント取得ループについて説明する。
perfはrecordの他にもreportやstatといった複数のコマンドをサポートしているため、ソースコード内では関数ポインタとして抽象化されコマンドごとの処理が定義されている。実際にはmain関数からrun_argv(&argc, &argv);が呼ばれrun_builtin()を通してコマンドごとの関数ポインタが呼ばれる仕組みだ。
recordコマンドに対応する処理はcmd_record()であり、ここから呼ばれる__cmd_recordがイベント取得のためのメインループとなっている。
さて、このメインループ処理の説明に入る前に先に__cmd_recordの引数に渡されているrecord構造体を見ておこう。
struct record {
...
struct perf_data data; // 外部ストレージとのインターフェース
struct auxtrace_record *itr; // AUX APIへのインターフェース
struct evlist *evlist; // 各イベントごとのring buffer
struct perf_session *session;
...
};
構造体のインスタンスは同コード内で定義されている。
このrecord構造体が以降recordコマンド処理内でコンテキストを保存するための中心的な役割を担う。
上には主要なメンバだけ載せた。perfで取得可能なイベントは、イベントの種類ごとにリングバッファに保存されるが、perfはこれらの各リングバッファにstruct evlistでアクセスする。その後evlistを使って読み取ったデータを外部ストレージにperf_dataとして保存するために使用するのがstruct perf_dataだ。リングバッファは次のイベントが発生すると上書きされてしまうため、一定の間隔でデータを外部ストレージのファイルに吐き出す必要があるわけだ。
イベントソース --> リングバッファ --(evlist)--> perf --(perf_data)--> 外部ストレージ
ただし、イベントのソースがCPUの持つプロセッサトレースという機構の場合はstruct evlistに加えてstruct auxtrace_recordというインターフェースを使ってイベント取得を行う。これに関しては次節で詳しく扱う。
プロセッサトレース --> AUXバッファ --(evlist + auxtrace_record)--> perf --(perf_data)--> 外部ストレージ
さてperf recordのメイン処理である__cmd_recordは今説明した一連の処理を無限ループで実行し続けるものだ。
以下が主要部分のソースコードである。
static int __cmd_record(struct record *rec, int argc, const char **argv)
{
struct perf_tool *tool = &rec->tool;
struct record_opts *opts = &rec->opts;
struct perf_data *data = &rec->data;
struct perf_session *session;
int fd;
...
// イベントデータ(perf_data)を定期的に吐き出すための外部ストレージfd
fd = perf_data__fd(data);
rec->session = session;
...
//
if (record__open(rec) != 0) {
err = -1;
goto out_child;
}
trigger_ready(&auxtrace_snapshot_trigger);
trigger_ready(&switch_output_trigger);
perf_hooks__invoke_record_start();
for (;;) {
unsigned long long hits = rec->samples;
// リングバッファ(evlist)へのイベント記録を一旦止める
if (trigger_is_hit(&switch_output_trigger) || done || draining)
perf_evlist__toggle_bkw_mmap(rec->evlist, BKW_MMAP_DATA_PENDING);
// リングバッファ(evlist)からデータを読み出す。一定のデータサイズごとに外部ストレージへの書き出しも行う
if (record__mmap_read_all(rec, false) < 0) {
trigger_error(&auxtrace_snapshot_trigger);
trigger_error(&switch_output_trigger);
err = -1;
goto out_child;
}
if (trigger_is_hit(&switch_output_trigger)) {
if (rec->evlist->bkw_mmap_state == BKW_MMAP_RUNNING)
continue;
trigger_ready(&switch_output_trigger);
/*
* Reenable events in overwrite ring buffer after
* record__mmap_read_all(): we should have collected
* data from it.
*/
//再びリングバッファ(evlist)へのイベント記録を許可
perf_evlist__toggle_bkw_mmap(rec->evlist, BKW_MMAP_RUNNING);
fd = record__switch_output(rec, false);
/* re-arm the alarm */
if (rec->switch_output.time)
alarm(rec->switch_output.time);
}
if (hits == rec->samples) {
if (done || draining)
break;
// 次のイベントが到着しring bufferから読み込めるようになるまでpollで待機
err = evlist__poll(rec->evlist, -1);
if (evlist__filter_pollfd(rec->evlist, POLLERR | POLLHUP) == 0)
draining = true;
}
}
}
主要な処理を行っている部分にコメントを入れた。for(;;)内がメインループだがやっている事は非常にシンプルだ。
一定のタイミング trigger_is_hit(&switch_output_trigger)で、リングバッファへのイベント記録を一旦止め(BKW_MMAP_DATA_PENDING)、その間にリングバッファ上のデータをさっさとrecord__mmap_read_all(rec, false)で外部ストレージに吐き出す。その後再びリングバッファへのイベント記録を有効化する(BKW_MMAP_RUNNING) これだけだ
この一連の書き出しの処理はalarm(rec->switch_output.time);で一定間隔ごとに発生する。
余談だが新しいイベントが到着したタイミングはソースへpollすると分かる仕組みになっている。上記のループではイベント書き出しが終了した後、rec->samplesごとにevlist__poll(rec->evlist, -1);で次のイベントが来るまで待機する仕組みになっている。
このrec->samplesはperf recordの**-cオプション**で調整可能だ。
3. PerfとAUXバッファ
さて、本記事のメインテーマであるCPUのプロセッサトレースとの連携部分を見ていこう。
前節でも少し述べたようにperf recordはプロセッサトレースからイベントを取得する場合struct auxtrace_recordというインターフェースを使用する。
struct auxtrace_record {
int (*recording_options)(struct auxtrace_record *itr,
struct evlist *evlist,
struct record_opts *opts);
size_t (*info_priv_size)(struct auxtrace_record *itr,
struct evlist *evlist);
int (*info_fill)(struct auxtrace_record *itr,
struct perf_session *session,
struct perf_record_auxtrace_info *auxtrace_info,
size_t priv_size);
void (*free)(struct auxtrace_record *itr);
int (*snapshot_start)(struct auxtrace_record *itr);
int (*snapshot_finish)(struct auxtrace_record *itr);
int (*find_snapshot)(struct auxtrace_record *itr, int idx,
struct auxtrace_mmap *mm, unsigned char *data,
u64 *head, u64 *old);
int (*parse_snapshot_options)(struct auxtrace_record *itr,
struct record_opts *opts,
const char *str);
u64 (*reference)(struct auxtrace_record *itr);
int (*read_finish)(struct auxtrace_record *itr, int idx);
unsigned int alignment;
unsigned int default_aux_sample_size;
};
このauxtrace_recordはAuxiliary (AUX)バッファというプロセッサトレースのイベント記録のために用意されたバッファへアクセスするためのインターフェースである。HAVE_AUXTRACE_SUPPORTコンフィグで有効化出来る。
3.1 AUXバッファとは
元々このAUXバッファはIntel PTのイベント記録のためにIntelの技術者達がperfコマンドへのパッチおよびLinuxカーネルへのパッチとして実装した物で、今ではARM CoreSightもAUXバッファを使用している。詳しくは後述する。
余談だがAUXバッファはLinuxへのIntel PTサポート追加のパッチよりも後に追加されている事から当初は想定していなかったインターフェースの実装だと思われる。
AUXというevlistと独立したリングバッファが必要になったのはIntel PTのトレースのデコード処理をユーザー空間に移譲する目的である。上記のLinuxカーネルへのAUXパッチのリンク先に以下のようにコメントがある。
The single most notable thing is that while PT outputs trace data in a compressed binary format,
it will still generate hundreds of megabytes of trace data per second per core.
Decoding this binary stream takes 2-3 orders of magnitude the cpu time that it takes to generate it.
These considerations make it impossible to carry out decoding in kernel space.
Therefore, the trace data is exported to userspace as a zero-copy mapping that userspace
can collect and store for later decoding.
To address this, this patchset extends perf ring buffer with an "AUX space"
Intel PTは毎秒メガバイト単位のトレースを取得するため、これらをカーネル空間でデコードしてからユーザーに渡すのはオーバヘッドが大きすぎる。そこでユーザー、カーネルモード間で共有可能なAUXバッファを作成し、デコードはユーザー空間側に任せる事でカーネルはトレースに注力するというわけだ。
このユーザー空間側、perfコマンドからのAUXバッファへのアクセスインターフェースがauxtrace_recordというわけだ。
auxtrace_recordはAUXバッファへのアクセスを抽象化したもので、auxtrace_record__initで初期化される。
static int record__auxtrace_init(struct record *rec)
{
if (!rec->itr) {
rec->itr = auxtrace_record__init(rec->evlist, &err);
if (err)
return err;
}
}
このauxtrace_record__initは__weakオプションを用いて定義されており、Intel PTとARM CoreSight用のコード内に同名の関数が定義されている。コンフィグで有効にしたプロセッサトレースのほうがリンクされる仕組みだ。
これによってどのプロセッサトレース機能を使っているかを意識する事なく、全ての操作はauxtrace_recordの関数ポインタとして抽象化される。
3.2 AUXバッファ読み込みとperf_dataヘッダの生成
AUXバッファに記録されたトレースはperf recordメインループ中のrecord__mmap_read_allからrecord__mmap_read_evlistを通してauxtrace_mmap__readで読み込みが行われる
static int record__mmap_read_evlist(struct record *rec, struct evlist *evlist,
bool overwrite, bool synch)
{
if (map->auxtrace_mmap.base && !rec->opts.auxtrace_snapshot_mode &&
!rec->opts.auxtrace_sample_mode &&
record__auxtrace_mmap_read(rec, map) != 0) {
rc = -1;
goto out;
}
}
static int record__mmap_read_all(struct record *rec, bool synch)
{
int err;
err = record__mmap_read_evlist(rec, rec->evlist, false, synch);
if (err)
return err;
return record__mmap_read_evlist(rec, rec->evlist, true, synch);
}
LinuxカーネルのマッピングしたAUXバッファのアドレスはauxtrace_mmap.baseであり、そこからauxtrace_mmap__readで読み込みを行う。
さてイベントループではrecord__mmap_read_allでの読み込が完了した後、record__switch_outputでこれらのデータをperf_dataとして外部ストレージに保存する。
perf_dataは取得したトレースの生情報の他にもヘッダ領域を持っており、様々なメタ情報を書き込んで保存する。例えばIntel PTはトレースの際さまざまなオプション(config)が設定可能だが、実際に使用したオプションの組み合わせもperf_datanヘッダに保存される。こういったメタデータはperf reportといったperf_dataパースツールがあとで使用するわけだ。
perf_dataヘッダの生成はrecord__synthesizeが行う。
static int record__synthesize(struct record *rec, bool tail)
{
if (rec->opts.full_auxtrace) {
err = perf_event__synthesize_auxtrace_info(rec->itr, tool,
session, process_synthesized_event);
if (err)
goto out;
}
}
perf_event__synthesize_auxtrace_info が呼ばれる。
int auxtrace_record__info_fill(struct auxtrace_record *itr,
struct perf_session *session,
struct perf_record_auxtrace_info *auxtrace_info,
size_t priv_size)
{
if (itr)
return itr->info_fill(itr, session, auxtrace_info, priv_size);
return auxtrace_not_supported();
}
int perf_event__synthesize_auxtrace_info(struct auxtrace_record *itr,
struct perf_tool *tool,
struct perf_session *session,
perf_event__handler_t process)
{
pr_debug2("Synthesizing auxtrace information\n");
err = auxtrace_record__info_fill(itr, session, &ev->auxtrace_info,
priv_size); // AUXバッファのperf_dataへの変換
err = process(tool, ev, NULL, NULL); // 外部ストレージへの書き出し
}
実際のヘッダ生成はauxtrace_record__info_fillで先程のstruct auxtrace_recordに登録された関数ポインタ、info_fillが担当する。このinfo_fillはIntel PT、ARM CoreSightそれぞれに実装がある。
ちなみにprocessはprocess_synthesized_eventで、perf_eventを外部ストレージのファイルに書き出す処理だ。
3.3 Intel Processor Trace (PT)
struct auxtrace_recordの関数ポインタの実装例として前節で挙げたヘッダ生成の役割を担うinfo_fillのIntel PTの実装を見てみよう。
Intel PT用のauxtrace_record初期化コードauxtrace_record__initはintel_pt_recording_initで初期化を実行する。
struct auxtrace_record *intel_pt_recording_init(int *err)
{
...
ptr->itr.info_priv_size = intel_pt_info_priv_size;
ptr->itr.info_fill = intel_pt_info_fill;
ptr->itr.snapshot_start = intel_pt_snapshot_start;
ptr->itr.snapshot_finish = intel_pt_snapshot_finish;
...
ptr->itr.read_finish = intel_pt_read_finish;
return &ptr->itr;
}
Intel PTのinfo_fillを担当するintel_pt_info_fillの実装を見てみよう。
static int intel_pt_info_fill(struct auxtrace_record *itr,
struct perf_session *session,
struct perf_record_auxtrace_info *auxtrace_info,
size_t priv_size)
{
...
intel_pt_parse_terms(&intel_pt_pmu->format, "tsc", &tsc_bit);
intel_pt_parse_terms(&intel_pt_pmu->format, "noretcomp",
&noretcomp_bit);
intel_pt_parse_terms(&intel_pt_pmu->format, "mtc", &mtc_bit);
mtc_freq_bits = perf_pmu__format_bits(&intel_pt_pmu->format,
"mtc_period");
intel_pt_parse_terms(&intel_pt_pmu->format, "cyc", &cyc_bit);
intel_pt_tsc_ctc_ratio(&tsc_ctc_ratio_n, &tsc_ctc_ratio_d);
if (perf_pmu__scan_file(intel_pt_pmu, "max_nonturbo_ratio",
"%lu", &max_non_turbo_ratio) != 1)
max_non_turbo_ratio = 0;
filter = intel_pt_find_filter(session->evlist, ptr->intel_pt_pmu);
filter_str_len = filter ? strlen(filter) : 0;
...
auxtrace_info->priv[INTEL_PT_TSC_BIT] = tsc_bit;
auxtrace_info->priv[INTEL_PT_NORETCOMP_BIT] = noretcomp_bit;
auxtrace_info->priv[INTEL_PT_HAVE_SCHED_SWITCH] = ptr->have_sched_switch;
auxtrace_info->priv[INTEL_PT_SNAPSHOT_MODE] = ptr->snapshot_mode;
auxtrace_info->priv[INTEL_PT_PER_CPU_MMAPS] = per_cpu_mmaps;
auxtrace_info->priv[INTEL_PT_MTC_BIT] = mtc_bit;
auxtrace_info->priv[INTEL_PT_MTC_FREQ_BITS] = mtc_freq_bits;
auxtrace_info->priv[INTEL_PT_TSC_CTC_N] = tsc_ctc_ratio_n;
auxtrace_info->priv[INTEL_PT_TSC_CTC_D] = tsc_ctc_ratio_d;
auxtrace_info->priv[INTEL_PT_CYC_BIT] = cyc_bit;
auxtrace_info->priv[INTEL_PT_MAX_NONTURBO_RATIO] = max_non_turbo_ratio;
auxtrace_info->priv[INTEL_PT_FILTER_STR_LEN] = filter_str_len;
info = &auxtrace_info->priv[INTEL_PT_FILTER_STR_LEN] + 1;
}
intel_pt_parse_terms で各オプションを取得し、ヘッダであるauxtrace_info->privに設定しているだけだ。
4. LinuxカーネルとAUXバッファ (PMUドライバ)
Intel PTやARM CoreSightはLinuxカーネル内ではPerformance Monitor Unit(PMU)と呼ばれ、ユーザー空間からPMUへアクセスするためにLinuxは専用のドライバを実装している。
4.1. Intel Processor Trace (PT)
ドライバへのインターフェースは/sys/bus/event_source/devices/intel_pt/だ。
これらのドライバは初期化コードでperf_pmu_registerによりPMUドライバとして登録されている。
Intel PTもCoreSightのドライバもLinuxカーネル内ではstruct pmuの関数ポインタとして抽象化されている。
Intel PTの場合実装は以下のようになる。
static struct pt_pmu pt_pmu;
static __init int pt_init(void)
{
pt_pmu.pmu.capabilities |= PERF_PMU_CAP_EXCLUSIVE | PERF_PMU_CAP_ITRACE;
pt_pmu.pmu.attr_groups = pt_attr_groups;
pt_pmu.pmu.task_ctx_nr = perf_sw_context;
pt_pmu.pmu.event_init = pt_event_init;
pt_pmu.pmu.add = pt_event_add;
pt_pmu.pmu.del = pt_event_del;
pt_pmu.pmu.start = pt_event_start;
pt_pmu.pmu.stop = pt_event_stop;
pt_pmu.pmu.snapshot_aux = pt_event_snapshot_aux;
pt_pmu.pmu.read = pt_event_read;
pt_pmu.pmu.setup_aux = pt_buffer_setup_aux;
pt_pmu.pmu.free_aux = pt_buffer_free_aux;
pt_pmu.pmu.addr_filters_sync = pt_event_addr_filters_sync;
pt_pmu.pmu.addr_filters_validate = pt_event_addr_filters_validate;
pt_pmu.pmu.nr_addr_filters =
intel_pt_validate_hw_cap(PT_CAP_num_address_ranges);
ret = perf_pmu_register(&pt_pmu.pmu, "intel_pt", -1);
return ret;
4.1.1. AUXバッファの確保
トレースの開始、終了がpmu.start/stopで実装されている事は直感的にも明らかだと思うが面白いのがAUXバッファの確保/解法までpmu.setup_aux/free_auxとして関数ポインタになっている事だ。
AUXはユーザー、カーネル間で共有されるただのメモリ空間のはずで、わざわざIntel PTやCoreSightごとにこのような操作が実装されているのはなぜだろう。
Intel PTに関する資料を見ればその答えが分かる。このスライドの13p-15pを見てみよう。
(スライド13p)
• Different kinds of trace filtering:
1. Current Privilege Level (CPL) – used to trace all of user or kernel
2. PML4 Page Table – used to trace a single process
3. Instruction Pointer – used to trace a particular slice of code (or module)
• Two types of output logging:
1. Single Range
2. Table of Physical Addresses
前者はトレースを取る際のフィルタリング、後者は取得済みのトレース情報を吐き出すためのアウトプット手法について書かれている。
perf上ではトレースはAUXバッファに書き込むモデルとして抽象化されているが、実際にIntel PTはトレース情報を書き込む方法を「Single Range」と「Table of Physical Address(ToPA)」で2つ持っている。
前者のSingle Range(スライド14p)は予めOSが確保した連続する物理アドレス領域にトレース情報を吐き出す物で、
後者のToPA(スライド15p)は非連続な物理アドレス領域でも、ToPAというテーブルに設定すればトレース情報を吐き出せるという物だ。
実際に上でpmu.setup_auxに設定されたpt_buffer_setup_auxの実装を見てみると2つのアウトプットモデルを採用している事が分かる。
static void *
pt_buffer_setup_aux(struct perf_event *event, void **pages,
int nr_pages, bool snapshot)
{
buf = kzalloc_node(sizeof(struct pt_buffer), GFP_KERNEL, node);
INIT_LIST_HEAD(&buf->tables);
ret = pt_buffer_try_single(buf, nr_pages); // bufをSingle Rangeモデルとして登録
ret = pt_buffer_init_topa(buf, cpu, nr_pages, GFP_KERNEL); // bufをToPAモデルとして登録
return buf;
}
4.1.2 トレース開始
さて、前節の方法で確保したAUXバッファにIntel PTのトレース情報を書き込んでいるのがpmu.startに設定されたpt_event_startだ。
static void pt_event_start(struct perf_event *event, int mode)
{
struct hw_perf_event *hwc = &event->hw;
struct pt *pt = this_cpu_ptr(&pt_ctx);
struct pt_buffer *buf;
buf = perf_aux_output_begin(&pt->handle, event); // aux_setupで確保したAUXバッファのアドレスを取得
pt_config_buffer(buf); // Intel PTの出力先として設定
pt_config(event); // アドレスフィルター等その他の設定
return;
}
先程aux_setupで確保したAUXバッファ(buf)をpt_config_buffer(buf)で出力先として設定しているだけだ。
pt_config_bufferの処理は以下のようになっている。
static void pt_config_buffer(struct pt_buffer *buf)
{
struct pt *pt = this_cpu_ptr(&pt_ctx);
u64 reg, mask;
void *base;
// AUXバッファはSingle RangeがToPAのいずれかのフォーマット
if (buf->single) {
base = buf->data_pages[0];
mask = (buf->nr_pages * PAGE_SIZE - 1) >> 7;
} else {
base = topa_to_page(buf->cur)->table;
mask = (u64)buf->cur_idx;
}
// AUXバッファのアドレスを物理アドレスに変換
reg = virt_to_phys(base);
if (pt->output_base != reg) {
// AUXバッファの物理アドレスをIntel PTの出力先(MSR_IA32_RTIT_OUTPUT_BASE)に設定
pt->output_base = reg;
wrmsrl(MSR_IA32_RTIT_OUTPUT_BASE, reg);
}
}
Intel PTのトレース出力先アドレスはMSR_IA32_RTIT_OUTPUT_BASEで設定できる。
4.2. ARM CoreSight
ドライバへのインターフェースは/sys/bus/event_source/devices/cs_etm/だ。
CoreSightのドライバに関してはLinaroの公式ブログやスライド[^8]にも記述があるので興味のある人は読んでみると良い。
ARM CoreSightというのはIntel PTと同じくCPU内に搭載されたトレース機構だ。以下が概略図になる。
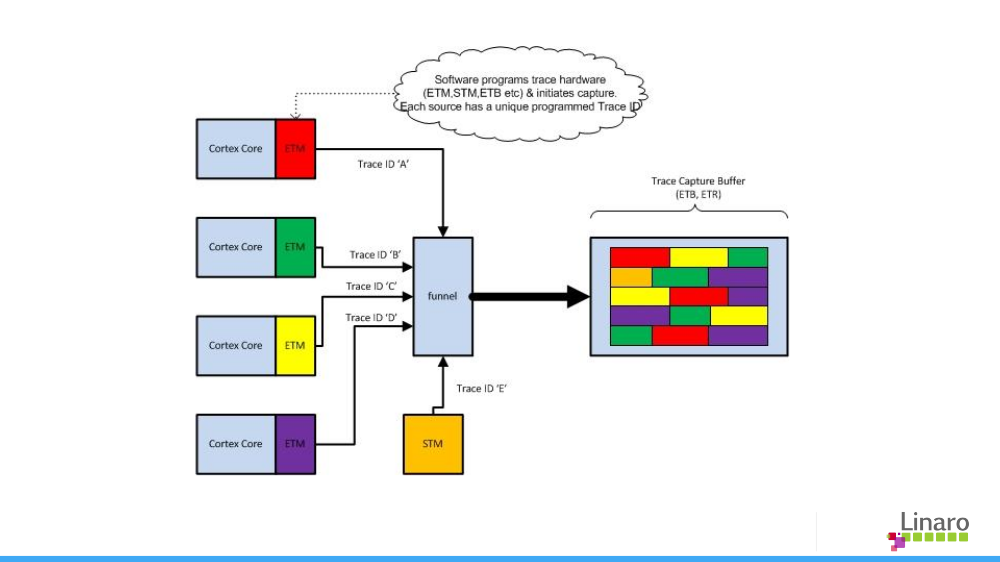
[^8]より引用
各プロセッサ内にEmbedded Trace Macrocell (ETM)と呼ばれるトレース専用のチップが設置されており、これら複数コアから取得したトレース情報をfunnelとよばれるチップが**Embedded Trace Buffer(ETB)**というバッファにまとめる形になっている。最近のARMプロセッサはETBを拡張したTrace Memory Controller (TMC)が使われている。ETBはこのTMCの中の1つのトレースアーキテクチャとして定義されるようになったが、今回はTMCは使わず以前のARMプロセッサのようにETBに直接トレース情報がまとめられていた時のアーキテクチャを前提とする。
Linuxカーネルのドライバは初期化コードでperf_pmu_registerによりPMUドライバとして登録されている。
static int __init etm_perf_init(void)
{
int ret;
etm_pmu.capabilities = (PERF_PMU_CAP_EXCLUSIVE |
PERF_PMU_CAP_ITRACE);
etm_pmu.attr_groups = etm_pmu_attr_groups;
etm_pmu.task_ctx_nr = perf_sw_context;
etm_pmu.read = etm_event_read;
etm_pmu.event_init = etm_event_init;
etm_pmu.setup_aux = etm_setup_aux;
etm_pmu.free_aux = etm_free_aux;
etm_pmu.start = etm_event_start;
etm_pmu.stop = etm_event_stop;
etm_pmu.add = etm_event_add;
etm_pmu.del = etm_event_del;
etm_pmu.addr_filters_sync = etm_addr_filters_sync;
etm_pmu.addr_filters_validate = etm_addr_filters_validate;
etm_pmu.nr_addr_filters = ETM_ADDR_CMP_MAX;
ret = perf_pmu_register(&etm_pmu, CORESIGHT_ETM_PMU_NAME, -1);
if (ret == 0)
etm_perf_up = true;
return ret;
}
4.2.1 AUXバッファの確保
例によってまずAUXバッファの確保/解法を行うpmu.setup_aux/free_auxの実装を見てみよう。
etm_setup_auxはsink_ops(sink)->alloc_bufferでAUXバッファを確保している。
static void *etm_setup_aux(struct perf_event *event, void **pages,
int nr_pages, bool overwrite)
{
if (!sink_ops(sink)->alloc_buffer || !sink_ops(sink)->free_buffer)
goto err;
/* Allocate the sink buffer for this session */
event_data->snk_config =
sink_ops(sink)->alloc_buffer(sink, event, pages,
nr_pages, overwrite);
return event_data;
}
SinkというのはCoreSight用語で、トレースを取得するソースの事だ。以下のコマンドでSink一覧が取得できる。
linaro@linaro-nano:~$ ls /sys/bus/coresight/devices/
20010000.etf 20040000.main-funnel 22040000.etm 22140000.etm
230c0000.cluster1-funnel 23240000.etm coresight-replicator 20030000.tpiu
20070000.etr 220c0000.cluster0-funnel 23040000.etm 23140000.etm
23340000.etm
ETM、ETR(TMCの一種)やfunnelなど様々なSinkが存在する。
perfには以下のように設定すれば良い。
./perf record -e cs_etm/@20070000.etr/ --perf-thread ./main
どのSinkを指定したかでsink_ops(sink)が変わってくるわけだが、今回は古き良きETBをSinkとして使用すると仮定する。
この場合sink_opsはetb_sink_opsになる。
static void *etb_alloc_buffer(struct coresight_device *csdev,
struct perf_event *event, void **pages,
int nr_pages, bool overwrite)
{
int node;
struct cs_buffers *buf;
node = (event->cpu == -1) ? NUMA_NO_NODE : cpu_to_node(event->cpu);
buf = kzalloc_node(sizeof(struct cs_buffers), GFP_KERNEL, node);
if (!buf)
return NULL;
buf->snapshot = overwrite;
buf->nr_pages = nr_pages;
buf->data_pages = pages;
return buf;
}
static const struct coresight_ops_sink etb_sink_ops = {
.enable = etb_enable,
.disable = etb_disable,
.alloc_buffer = etb_alloc_buffer,
.free_buffer = etb_free_buffer,
.update_buffer = etb_update_buffer,
};
AUXバッファ確保に使用されていたalloc_bufferはetb_alloc_bufferが指定されており、中身はただのkzallocだ。
これがETBとしてCoreSight側に設定される。
4.2.2. トレース開始
さて、後はトレース開始のetm_pmu.startのetm_event_startだがこれもIntel PTの時同様非常にシンプルだ。
static void etm_event_start(struct perf_event *event, int flags)
{
/*
* Deal with the ring buffer API and get a handle on the
* session's information.
*/
event_data = perf_aux_output_begin(handle, event); // AUXバッファのアドレス取得
path = etm_event_cpu_path(event_data, cpu);
/* We need a sink, no need to continue without one */
sink = coresight_get_sink(path);
/* Finally enable the tracer */
if (source_ops(csdev)->enable(csdev, event, CS_MODE_PERF)) //トレース開始
goto fail_disable_path;
out:
return;
AUXバッファのアドレスを取得してトレースを開始するだけ。
5. アドレスフィルター
さて前節まではプロセッサトレースを使用してトレースを記録し読み出す処理を解説したが、パフォーマンスモニターツールには他にも重要な要素がある。トレースのフィルタリングだ。
プロセッサトレースはアプリケーションからカーネルまでCPU上で実行される全ての処理のトレースを取得するが、多くの場合ユーザーはこれら全てのトレースを要求しているわけではない。特定のプロセスのトレースであったり、一部のカーネルイベントに関する統計が欲しいのだ。これらの情報はプロセッサトレースで全てトレースした後にperfコマンドで必要な情報を抜き出す事も可能だが、毎秒数メガバイト単位で生成されるトレース情報を全て取得するのは流石に筋が悪い。
5.1. Intel Processor Trace (PT)
Intel PTはフィルター機能を持っており、Model Specific Register (MSR)を通じて設定すれば特定の範囲しかトレースしないようにできる。
前節で示したスライドを再掲する。
(スライド13p)
• Different kinds of trace filtering:
1. Current Privilege Level (CPL) – used to trace all of user or kernel
2. PML4 Page Table – used to trace a single process
3. Instruction Pointer – used to trace a particular slice of code (or module)
• Two types of output logging:
1. Single Range
2. Table of Physical Addresses
どうやらDifferent kinds of trace filteringが3種類あるようだ。詳細はIntel SDM Vol 3 36.2.4 Trace Filteringを参照されたい。
現在Linuxカーネルがサポートしているのは3つめのInstruction Pointer(IP)で指定した領域のみをトレースするフィルターのみである(パッチ)
さて、このIPフィルタの設定は前節で登場したpt_event_startから呼ばれるpt_config、pt_config_filtersが行う。
static u64 pt_config_filters(struct perf_event *event)
{
struct pt_filters *filters = event->hw.addr_filters;
struct pt *pt = this_cpu_ptr(&pt_ctx);
unsigned int range = 0;
u64 rtit_ctl = 0;
perf_event_addr_filters_sync(event); //最新のフィルター情報をeventに設定
for (range = 0; range < filters->nr_filters; range++) {
struct pt_filter *filter = &filters->filter[range];
/* avoid redundant msr writes */
if (pt->filters.filter[range].msr_a != filter->msr_a) {
//フィルターする領域の開始アドレスを(IA32_RTIT_ADDRn_A)に設定
wrmsrl(pt_address_ranges[range].msr_a, filter->msr_a);
pt->filters.filter[range].msr_a = filter->msr_a;
}
if (pt->filters.filter[range].msr_b != filter->msr_b) {
//フィルターする領域のサイズを(IA32_RTIT_ADDRn_A)に設定
wrmsrl(pt_address_ranges[range].msr_b, filter->msr_b);
pt->filters.filter[range].msr_b = filter->msr_b;
}
rtit_ctl |= filter->config << pt_address_ranges[range].reg_off;
}
return rtit_ctl;
}
IPフィルターは4つ設定ができる。IA32_RTIT_ADDRn_Aに開始アドレス、IA32_RTIT_ADDRn_Bにサイズを設定するだけだ(n=0-3)
gdbのハードウェアブレークポイント設定もそうだが、この手の数が限られたハードウェアレジスタへの設定はまず初めにユーザーがソフトウェア上で設定した値(これは動的に変わりうる)をsyncし、その後実際のレジスタへ書き込みを行うという実装パターンだ。
親の顔より見た。
5.2. ARM CoreSight
Intel PTがフィルタ範囲の設定にMSRを使っていたのに対して、CoreSightは自身で確保したメモリ領域をインターフェースとしてCoreSightに登録し、以降やりとりはこの領域上で行うようになっている(Memory Mapped Interface)。
etm4_enable_perfからetm4_enable_hwでインターフェース用のメモリ領域を設定している。
static int etm4_enable_hw(struct etmv4_drvdata *drvdata)
{
rc = coresight_claim_device_unlocked(drvdata->base);
/* Disable the trace unit before programming trace registers */
writel_relaxed(0, drvdata->base + TRCPRGCTLR);
/* wait for TRCSTATR.IDLE to go up */
if (coresight_timeout(drvdata->base, TRCSTATR, TRCSTATR_IDLE_BIT, 1))
dev_err(etm_dev,
"timeout while waiting for Idle Trace Status\n");
writel_relaxed(config->pe_sel, drvdata->base + TRCPROCSELR);
writel_relaxed(config->cfg, drvdata->base + TRCCONFIGR);
...
}
writel_relaxed(val, addr)はアドレス(addr)に値(val)を書き込むstr命令のマクロだ。
さてCoreSight上でのアドレスフィルタはAddress comparatorsと呼ばれ、なんとこの機能はチップの実装依存とされているため実機によってアクセス方法が異なるのだと思われる。
これに関しては後日加筆する。
comparatorはetm4_set_event_filtersで設定される。
static int etm4_set_event_filters(struct etmv4_drvdata *drvdata,
struct perf_event *event)
{
/* Sync events with what Perf got */
perf_event_addr_filters_sync(event);
for (i = 0; i < filters->nr_filters; i++) {
struct etm_filter *filter = &filters->etm_filter[i];
enum etm_addr_type type = filter->type;
/* See if a comparator is free. */
comparator = etm4_get_next_comparator(drvdata, type);//現在利用可能なcomparatorを取得する
switch (type) { //comparatorのタイプごとにフィルターを設定する。
case ETM_ADDR_TYPE_RANGE:
etm4_set_comparator_filter(config,
filter->start_addr,
filter->stop_addr,
comparator);
break;
case ETM_ADDR_TYPE_START:
case ETM_ADDR_TYPE_STOP:
/* Get the right start or stop address */
address = (type == ETM_ADDR_TYPE_START ?
filter->start_addr :
filter->stop_addr);
/* Configure comparator */
etm4_set_start_stop_filter(config, address,
comparator, type);
break;
default:
ret = -EINVAL;
goto out;
}
}
}
6. おわりに
CPUの持つプロセッサトレースは、特にサイバーセキュリティの世界でリバースエンジニアリングや脆弱性解析などに幅広く応用されており避けては通れない機能だ。 今回はperfイベントとしてLinuxに組み込まれているプロセッサトレースの処理を読み解いた。
特にARMのCoreSightは非常に新しい技術であるため、現状資料がほとんどない。コミュニティのこれからに期待したい。
俺の三が日は記事執筆で終わった。
Reference
[^1] Linux Perf Tools Overview and Current Developments
[^2] CoreSight, Perf and the OpenCSD Library
[^3] perf, ftraceのしくみ
[^4] perf Examples
[^5] Programming and Performance Visualization Tools
[^6] Enhance performance analysis with Intel Processor Trace.
[^7] Harnessing Intel Processor Trace on Windows for Vulnerability Discovery (HITB17)
[^8] Hardware Assisted Tracing on ARM with CoreSight and OpenCSD