はじめに
最近Kaggleでよく使われるXGBoostについてまとめました。
一体どのような学習法であり、どのような特徴があるのかを紹介していきます。
XGBoostとは ?
- Gradient Boosting(勾配ブースティング)とRandom Forestを組み合わせたアンサンブル学習(複数の分類器を集めて構成される分類器)
- 勾配ブースティングをC++で実装し高速化したものであり、Gradient Boosted Tree(GBT)より10倍くらいは高速に処理すると言われている。
- 複数のパラメータ調整によるチューニングが必要であり,最適化はグリッドサーチやCross Validationを複数行う
- 汎化能力を上げるために,学習率(XGBoostパッケージではパラメータeta)を下げていき,その都度最適化を行う
Gradient Boosting(勾配ブースティング)とは?
- 弱学習器を1つずつ順番に構築していく手法。新しい弱学習器を構築する際に,それまでに構築されたすべての弱学習器の結果を利用する。
- すべての弱学習器が独立に学習されるバギングと比べ,計算を並列化できず学習に時間がかかる。
※バギングとは、ブートストラップサンプリングで得られた学習データを使って、識別器を複数作り、それらの識別器の多数決をとることによって、一つの識別器よりも性能の高いモデルを作ること。
Random Forest(ランダムフォレスト)とは?
- アンサンブル学習法の一つ。
- 決定木を複数集めて使うので、木が集まってフォレスト(森)と言われている。
- 複数集めた各決定木の予測結果を多数決することによって結果を得る。
Random Forestのアルゴリズム
1. ランダムにデータを抽出する
2. 決定木を成長させる
3. 1,2ステップを指定回繰り返す
4. 予測結果を多数決することによって分類閾値(ラベル)を決定する
Random Forestのメリット
- 特徴量のスケーリングが必要ない(SVMなどの分類手法では必要になる)
- 考慮するパラメータが少ない
- 並列化が容易
- どの特徴量が重要かを知ることができる
Random Forestのデメリット
- 複雑なデータではSVM(サポートベクターマシン)などの分類手法に比べて汎化性能が下がる
XGBoostのメリット
- 欠損値が多いなどのスパースなデータに対して、事前に木の分岐の方向を決めるアルゴリズムを採用している。
- 並列分散処理により、モデルの探索を高速化している。
- CPU外でも学習が回せるため、大規模なデータも処理できる。
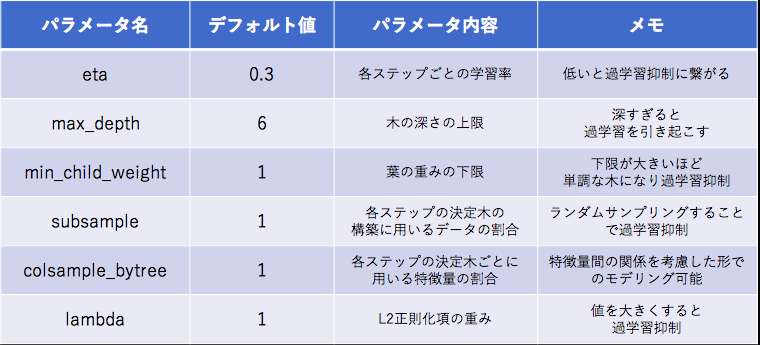
XGBoostのハイパーパラメタ
XGBoostの公式ドキュメントから、チューニングすべきであろう主なハイパーパラメータは以下のとおりです。
参考文献
Kaggleで大人気!XGBoostに関する備忘録
xgboost公式ドキュメント
機械学習アルゴリズム〜XGboost〜
決定木とランダムフォレスト
XGBoostの主な特徴と理論の概要