1.はじめに:なぜRAG 2.0なのか、そして何が変わったのか?
1.1 RAGの台頭とその構造的な欠陥
Retrieval-Augmented Generation(RAG)は、生成AIの進化において強力なアーキテクチャとして急速に台頭しています。外部データでLLMを拡張することにより、RAGは事前学習済みの知識のみに依存する固有の制限を克服するのに役立ちます。代わりに、リアルタイムで取得したドキュメントやデータベースレコードをプロンプトに直接注入し、応答の精度と鮮度の両方を劇的に向上させます。その結果、GPT-4、Claude、Geminiのような洗練されたモデルでさえ、静的なトレーニングコーパスだけでは不可能だった企業固有の質問に対して、非常に適切で正確な回答を生成できるようになりました。
しかし、このアーキテクチャの飛躍は、新しいクラスのセキュリティ脅威をもたらします。マルチテナント環境では、複数のユーザーが同じベクトルインフラストラクチャやプロンプトチェーンを共有する場合、ユーザーのアクセス権限を超えるドキュメントがプロンプトに注入され、機密データが不正な関係者に公開される可能性があります。これは単純なプロンプト設計の問題ではなく、LLM自体よりも前の段階で取得および注入パイプラインが制御される方法における構造的な失敗です[1]。
ベクトルインフラストラクチャ
埋め込みを通じて非構造化データ(ドキュメント、ログ、知識)をベクトル形式で保存するシステム。 RAGでは、セマンティクス的に類似したコンテンツを取得するために、ユーザーのクエリがこのベクトル空間と照合されます。 一般的なツールには、Pinecone、Weaviate、Qdrant、FAISSが含まれます。
プロンプトチェーン
取得したコンテンツをLLMに供給するエンドツーエンドのパイプライン。 これには、ユーザーのクエリ → ドキュメントの取得 → プロンプトの注入 → 応答の生成という完全なフローが含まれます。 LangChain、LlamaIndex、AutoGenなどのフレームワークによって管理されることがよくあります。
従来のIdentity and Access Management(IAM)およびRole-Based Access Control(RBAC)システムでは、このフローを制御するには十分ではありません。ベクトル検索は、構造化クエリではなくセマンティックな類似性に基づいているため、結果が本質的に予測不可能になります。メタデータフィルタリングが不完全な場合、それ以外はアクセス制御されているドキュメント(ACL経由)が依然として表面化および注入され、意図しないデータ漏洩につながる可能性があります。これにより、これらの構造的リスクを軽減するために、基本的なドキュメント隔離を超えたRAGにおけるランタイムセキュリティ制御の必要性が高まっています[2]。
1.2 内部テストによる脅威シナリオ:Kennyケース
QueryPieは、RAGパイプラインにおける構造的なセキュリティ脆弱性を検証するために内部実験を実施しました。明らかになった最も代表的な脅威シナリオは、「Kennyケース」として知られています。
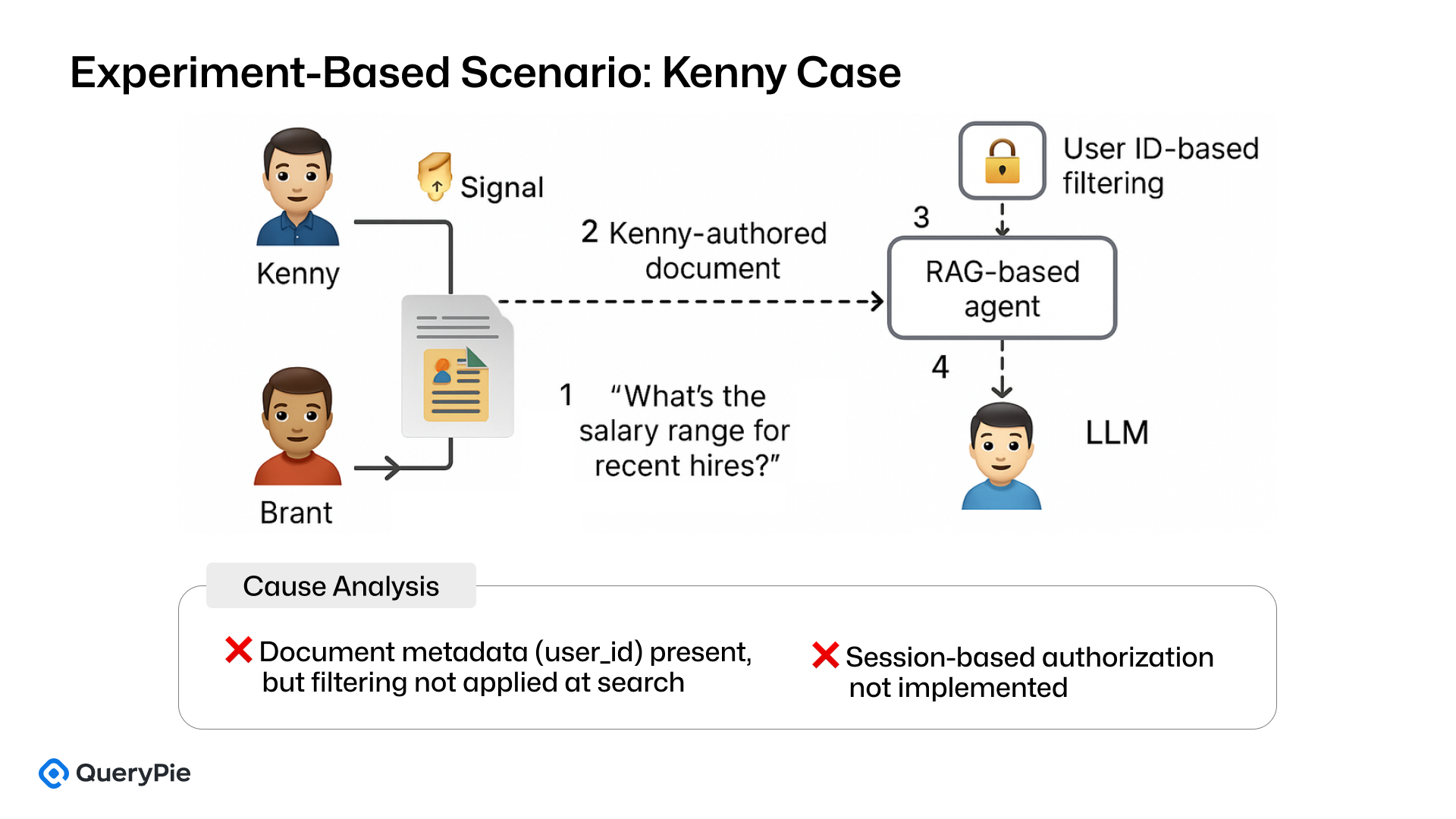
実験シナリオ:KennyとBrant間の給与データ漏洩
シナリオ設定
- Kenny:プロジェクト会議のメモと給与の詳細を含む社内Confluenceドキュメントをアップロードしたセキュリティチームのメンバー。
- Brant:「最近採用された人の給与範囲は?」という質問を会社のRAGベースの社内エージェントに問い合わせた開発者。
- システムコンテキスト:認証は有効でしたが、ベクトル検索レイヤーにはuser_idベースのメタデータフィルタリングがありませんでした。
脅威パス
- Brantの質問により、ベクトルデータベースでのセマンティック検索がトリガーされました。
- Kennyのドキュメントの1つが、Brantのアクセス範囲外であるにもかかわらず、類似性に基づいて選択されました。
- そのドキュメントのコンテンツ(要約された給与データを含む)がプロンプトに注入されました。
- LLMが応答を生成し、Brantに返却され、機密情報が知らされました。
根本原因分析
- user_idメタデータは存在しましたが、ベクトル検索中のAPIレベルではフィルターとして適用されませんでした。
- セッションベースのアクセス制御は実装されていませんでした。
- プロンプト注入前にコンテキスト検証やフィルタリングはありませんでした。
ベクトルデータベースへの情報の格納方法:インデックス化と埋め込みのフロー
1.ドキュメントチャンク
長いドキュメントは、より小さな意味的にまとまったチャンクに分割されます(例:500〜1000トークン)。 このケースでは、KennyのConfluenceファイルが複数の断片に分割されました。
2.埋め込みの生成
各チャンクは、OpenAI、Cohere、BGEなどの埋め込みモデルを使用して高次元ベクトルに変換されます。
例:vector = embed("ドキュメントチャンクのコンテンツ")
3.メタデータの添付と格納
各ベクトルは、関連するメタデータと一緒にJSON形式で格納されます。
# JSON
{
"vector": [0.12, -0.45, ..., 0.33],
"metadata": {
"doc_id": "CONF-2024-001",
"user_id": "kenny",
"department": "security",
"upload_time": "2024-03-11T08:15:00Z",
"sensitivity": "confidential"
}
}
4.ベクトルデータベースストレージ
- これらの結合されたベクトルとメタデータは、Pinecone、Weaviate、Qdrant、FAISSなどのベクトルデータベースに格納されます。
メタデータのリンク方法:結合された構造
ほとんどのベクトルデータベースは、ベクトルとメタデータを単一の結合オブジェクトとして扱います。
例:
- Weaviateはオブジェクトを使用します。
- Pineconeはアイテムを使用します。
- Qdrantはポイントを使用します。
これは、メタデータが個別に格納されているわけではなく、取得時にフィルタリング条件で直接活用できることを意味します。
例 – Kennyのドキュメントレコード構造
| フィールド | 値 |
|---|---|
| vector | [0.12, -0.45, ...] |
| user_id | "kenny" |
| doc_id | "CONF-2024-001" |
| department | "security" |
| sensitivity | "confidential" |
検索のしくみ – Brantのクエリの処理
- ユーザー入力 → 「最近採用された人の給与範囲は?」
- 埋め込み生成 -> クエリベクトルが作成されます。
- ベクトル類似度検索
- フィルタリングが適用されない → Kennyのドキュメントが結果に含まれます。
- Top-Kドキュメントが選択される → プロンプトに注入されます。
- LLM応答が生成される → 機密データがBrantに返却されます。
核心的な問題:フィルター条件の欠落
理想的な設計では、クエリは次のようなセッションベースの動的フィルターを適用します。
# Python
results = vector_db.search(
vector=query_vector,
top_k=5, # 上位5つの最も類似するベクトル
filter={
"user_id": {"$eq": "brant"},
"sensitivity": {"$ne": "confidential"}
}
)
代わりに、Brantはアクセス制御フィルタリングなしに、ベクトル類似度のみに基づいてKennyのドキュメントを受け取ります。
このシナリオは、セキュリティの失敗がLLM応答段階ではなく、それよりも前のベクトル検索およびドキュメント注入段階で発生することを明確に示しています。モデルは機密データをハルシネーションしたのではなく、システムが不正なコンテンツをプロンプトに許可したためです[2]。
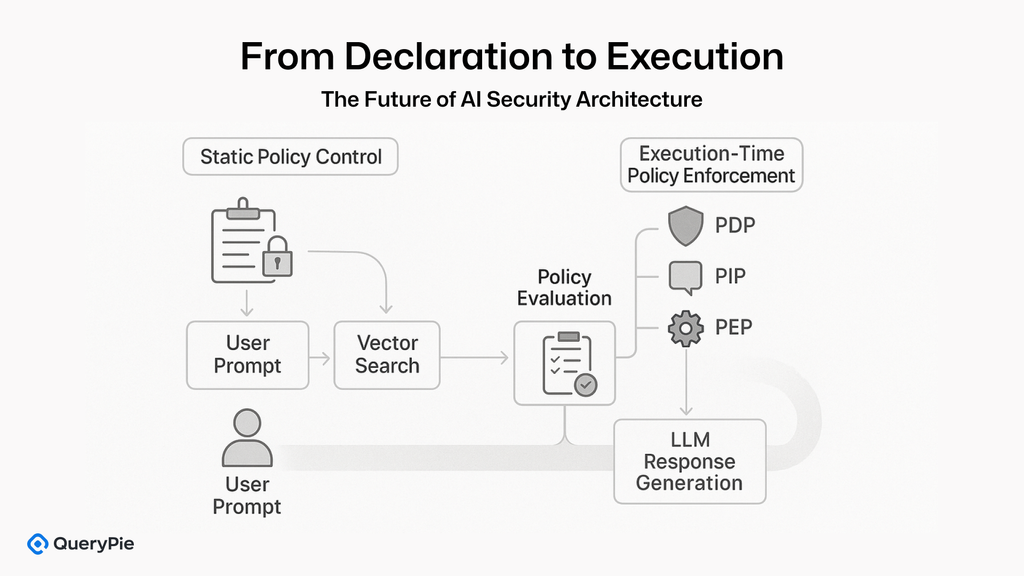
1.3 RAG 2.0の台頭:静的取得からランタイムセキュリティ制御へ
この新たなセキュリティ課題により、RAG 2.0が進化しました。RAG 1.0が埋め込み → 取得 → 注入 → 応答という固定された4段階のパイプラインに従っていたのに対し、RAG 2.0は構造的なリスクを軽減するために設計された、新しい実行認識型でセキュリティ中心のフローを導入しています。RAG 2.0セキュリティモデルの主要コンポーネントには以下が含まれます。
- セッションベースのポリシー評価
- プロンプト注入前のメタデータフィルタリング
- フロー途中での権限分岐およびブロック
- 説明可能なプロセスの追跡
- ユーザー、ドキュメント、コンテキストにわたる統一されたACL管理
これらの制御は、LLMスタックの外部で実装されるわけではありません。代わりに、LLM呼び出しの直前および直後というリアルタイムで動作する必要があり、真のデータセキュリティとコンテンツ隔離を可能にします。RAG 2.0の背後にある核心的な考え方は、取得と応答の間でのポリシーロジックの統合であり、従来のアクセス制御を超えて、分岐ロジックとプロンプト構成の認可を含みます[3]。
1.4 なぜランタイムセキュリティ制御が不可欠なのか:誰が何に、そしていつアクセスできるのか?
前述のように、従来の静的フィルタリングとユーザー認証は、RAG 2.0環境を保護するには十分ではありません。ユーザーが尋ねていることだけでなく、どのドキュメントがいつ、誰によってプロンプトに注入されるかも重要です。これこそが、ランタイムセキュリティ制御が不可欠になっている理由です。
Microsoft、Meta、QueryPieなどの主要組織は、それぞれ異なるアーキテクチャ的アプローチでこの問題に取り組んでいますが、共通の哲学を持っています。
** 「モデルが応答を生成する前に、システムはどの情報を含めることができるかを評価する必要があります。」 **
| 会社 | ポリシー評価が行われる場所 | 適用方法の概要 |
|---|---|---|
| Microsoft | Copilot APIレイヤー(PDPとして機能) | プロンプト注入を許可する前にMicrosoft Graph経由でドキュメント権限を確認 |
| Meta | オーケストレーターレイヤー内 | ドキュメントメタデータとセッションコンテキストに基づいて注入ルールを適用 |
| QueryPie | MCP Agent PAMプロキシでのフルフロー評価 | ユーザー、ドキュメント、時間、およびリスクのコンテキストを使用してOPAベースのポリシーチェックを実行。ランタイム実行制御を適用 |
これらの戦略的な方向性と実装の違いについては、セクション5で詳細に分析します。このホワイトペーパーの後半では、統一されたポリシー制御レイヤーを構築するための技術的なアプローチと、リアルタイムの実行フローを管理するために必要な具体的なポリシー構造を紹介します。
2.マルチテナント環境でのセキュアなRAGアーキテクチャの実装
2.1 実行ベースのセキュリティ障害:マルチテナントRAGにおける隔離の破壊
標準的なRAGパイプラインは通常、ドキュメントの埋め込み → ベクトル検索 → プロンプト注入 → 応答生成というステップに従います。これらのうち、ベクトル検索とプロンプト注入の段階は、データ漏洩のリスクが最も高いです。特に外部ソースから取得したドキュメントが関係する場合です。
このリスクは、複数の組織またはユーザーのドキュメントが同じベクトルデータベースおよびインフラストラクチャ内に共存するマルチテナントSaaS環境で特に深刻です。ベクトル検索中にランタイム承認が実施されない場合、不正なドキュメントが取得され、誤ったユーザーセッションのプロンプトに注入される可能性があります。
このアーキテクチャにおける核心的な問題は、ユーザーレベルの承認の欠如です。ドキュメントの選択が、セッションベースのアクセスフィルターを適用せずにベクトル類似度のみによって行われる場合、プロンプトにユーザーがアクセスを許可されていないデータが含まれる可能性があります。その結果、RAGセキュリティは、LLM応答生成から応答前適用(特に取得およびドキュメント注入レイヤー)に焦点を移す必要があります。これを達成するには、静的なフィルターやアイデンティティ検証だけでは不可能な、セッションベースのユーザー隔離が必要です。
以下は、実際の企業やオープンソースプロジェクトがこの課題に構造的にどのように取り組んでいるかを示すアーキテクチャ的アプローチです。
2.2 Microsoft:APIゲートウェイによるテナント認識ルーティングとメタデータフィルタリング
Azure OpenAI上に構築されたMicrosoftのマルチテナントRAGアーキテクチャは、認証とドキュメントアクセス制御をAPIゲートウェイレイヤーに直接組み込んでいます。このアーキテクチャは、単にクエリを中継するだけではありません。ランタイム時にセッションコンテキストに基づいてベクトル検索のターゲットと結果を動的にフィルタリングします。
ユーザーがRAGリクエストを送信すると、APIゲートウェイはまずユーザーのOAuthトークンを検証し、関連するテナントを特定した後、そのテナント専用のベクトルストアにリクエストをルーティングします。共有ベクトルストアにアクセスする場合でも、システムはメタデータフィルター(例:user_id、tenant_id、access_scope)を適用して、機密性の高いドキュメントがプロンプト注入から除外されるようにします。選択されたすべてのドキュメントと生成された応答はログに記録され、セキュリティ監視と監査可能性を可能にします[7]。
このアーキテクチャ(APIゲートウェイ → オーケストレーター → ベクトルDB → LLM → ロギングにまたがる)は、本番RAG環境におけるランタイムポリシー強制の強力な例を示しています。
ダイアグラム:Microsoft RAGセキュリティフロー
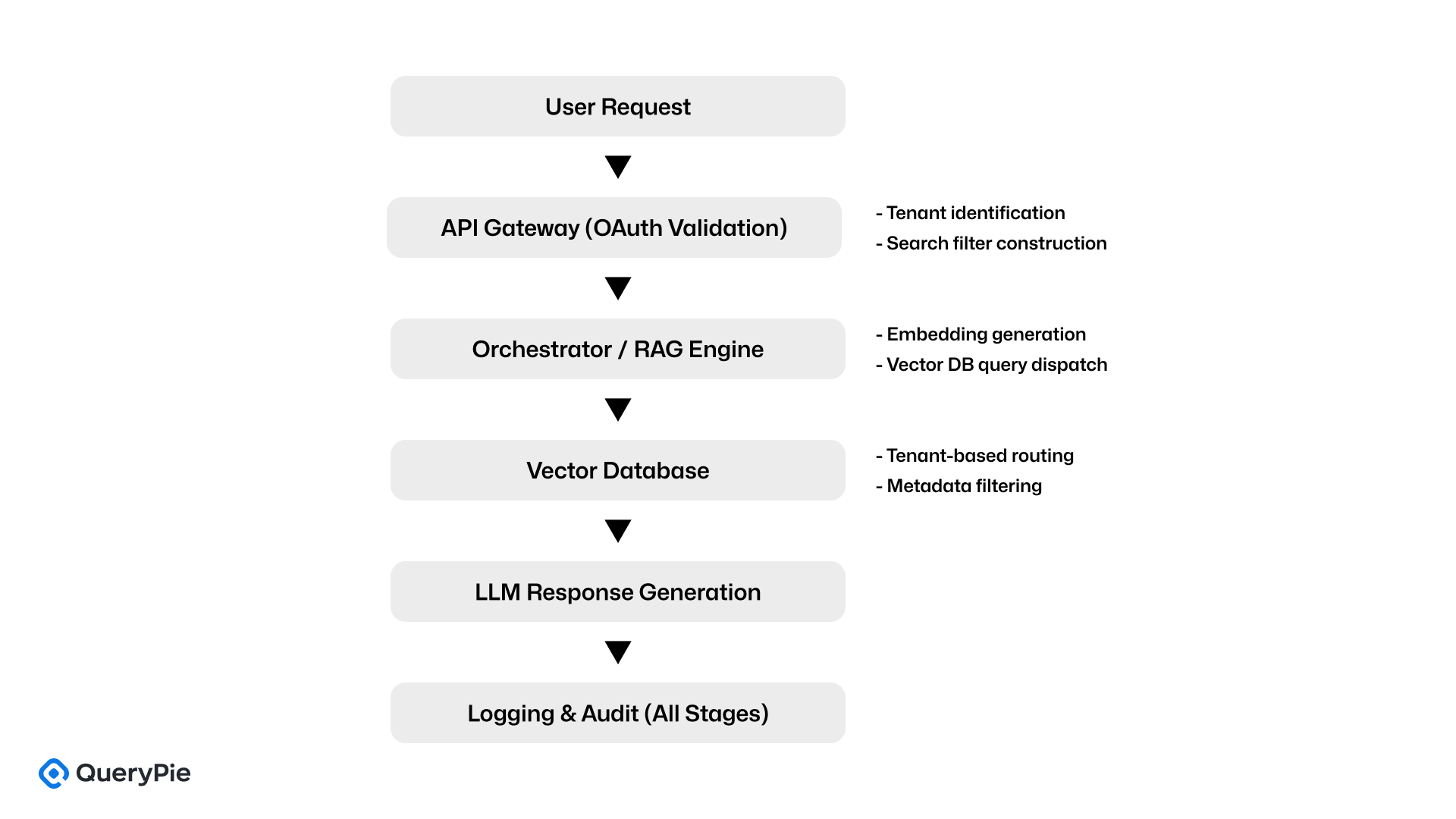
主要制御機能
| 制御項目 | 実装の説明 |
|---|---|
| ユーザー認証 | OAuthベースの認証とセッション抽出 |
| テナント分離 | APIゲートウェイで実行されるテナントレベルのルーティング |
| ドキュメントアクセス制御 | user_id、tenant_idなどを使用したメタデータフィルタリング |
| ランタイムポリシー評価 | 各ベクトルクエリで適用される動的フィルター |
| 監査可能性 | 選択されたドキュメント、生成された応答、およびクエリログが監査システムに記録される |
2.3 AWS:S3ベースのナレッジベースにおけるメタデータフィルタリングと論理的分離
AWS環境では、マルチテナントRAGシステムはS3上の中央集約型ナレッジベースを中心に構築されることが多く、メタデータに基づいたフィルタリングと論理的なパーティショニングによってテナント固有のセキュリティ境界が定義されます。
S3に保存されたドキュメントには、tenant_id、access_level、classificationなどの属性を含むx-amz-meta-*形式のカスタムメタデータを使用してタグが付けられます。RAGクエリが送信されると、SageMakerまたはBedrockを搭載したオーケストレーションレイヤーがIAMクレデンシャルまたはJWTを抽出し、ドキュメントメタデータと照合して、認証されたレコードのみに取得を制限します。
共有ベクトルストア(例:Amazon OpenSearchまたはAmazon Kendra)を使用する場合でも、アクセスは依然としてメタデータに基づいて動的にフィルタリングされます。これにより、共有インフラストラクチャ内での論理的なテナント分離が可能になります。つまり、ユーザーまたは組織は、アクセスを許可されたコンテンツのみをクエリおよび注入できます[8]。
このアプローチは、物理的にインフラストラクチャを分離せずにマルチテナントセキュリティを実現するLabel-Based Access Control(LBAC)の一種と見なされます。
ダイアグラム:S3を使用したAWSマルチテナントRAGアーキテクチャ

主要制御機能
|制御項目|実装の説明|
|認証情報の転送|IAMロールまたはJWTを介してユーザーが識別される|
|ドキュメントメタデータ分類|x-amz-meta.tenant_id、access_levelなどでタグ付けされる|
|ベクトルクエリフィルタリング|メタデータに基づいて動的に適用されるフィルター|
|論理的なテナント分離|メタデータとベクトルストアフィルタリングにより効果的な隔離が実現される|
|応答セキュリティ|許可されたドキュメントフラグメントのみがプロンプトに注入されるように制限される|
2.4 LlamaIndex:メタデータに基づくフィルタリングへの軽量なアプローチ
LlamaIndexは、Search-to-Generateアーキテクチャの上に構築された、シンプルで直感的な設計を通じてメタデータ駆動型アクセス制御を実装しています。各ドキュメントチャンクは、metadata={"user_id": ..., "department": ..., "access_level": ...}のようなキーバリューメタデータ構造を使用してインデックス化されます。取得中、これらのフィールドは動的フィルター条件を構築するために使用されます。
この構造により、複雑なIAMシステムや外部ポリシーエンジンを必要とせずに、単一のPythonアプリケーション内で効果的なランタイムアクセス制御が可能になります。フィルターは、現在のセッションのuser_idまたはロールに基づいてオンザフライで生成され、これらの条件に一致するチャンクのみがLLMに渡されます。
LlamaIndexはまた、FAISS、Weaviate、またはQdrantのようなベクトル検索エンジンと柔軟に統合し、検索結果を関連するメタデータと既に結合して返します。これにより、クリーンでコンパクトなフィルタリングロジックが可能になります。
公式デモでは、同じプロンプトを発行したユーザーでも、彼らがアップロードしたドキュメントに限定された異なる応答を受け取ります。不正なコンテンツはベクトル検索フェーズ中に除外されます。このモデルはプロンプト注入前にアクセス制御を強制し、ランタイムセキュリティ強制のクリーンで最小限の実装を表しています[9]。
ダイアグラム:LlamaIndexにおけるメタデータに基づくフィルタリング
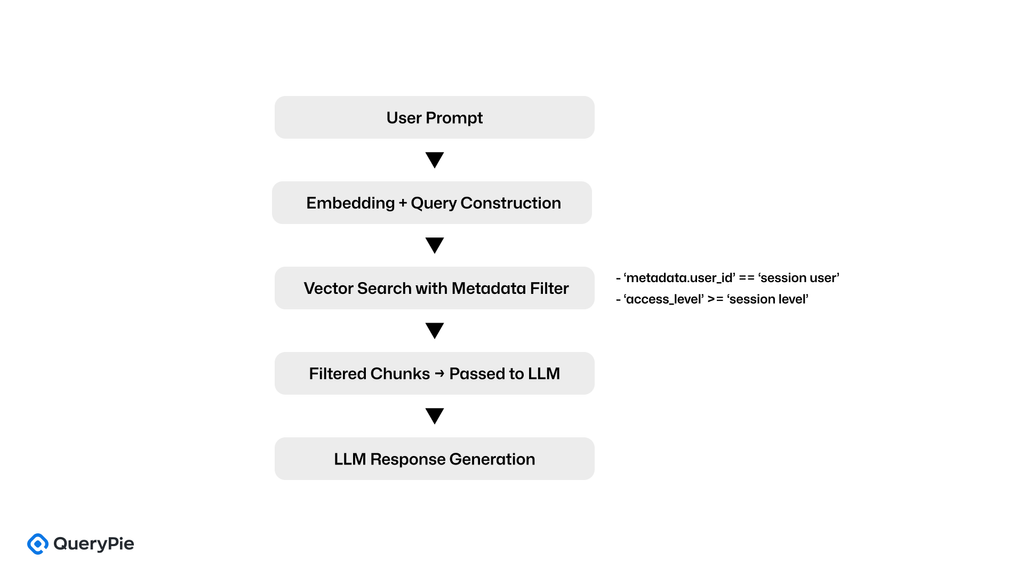
主要制御機能
| 制御項目 | 実装の説明 |
|---|---|
| ドキュメントインデックス化 | 各チャンクは関連するメタデータフィールドとともに格納される |
| セッションベースの評価 | user_id、department、access_levelを使用してフィルターを生成 |
| 検索フィルタリング | ランタイム時のメタデータフィルタリングとベクトル検索を組み合わせる |
| 構造のシンプルさ | Python内で完全に管理され、外部認証システムは不要 |
| バックエンドの柔軟性 | FAISS、Weaviate、Qdrantなどと互換性がある |
2.5 PineconeとWeaviate:ベクトルインフラストラクチャレイヤーでの構造的隔離
PineconeやWeaviateなどの商用ベクトルデータベースは、マルチテナントセキュリティを確保するために、ベクトルインフラストラクチャレイヤーで構造的隔離戦略を採用しています。このアーキテクチャにより、ベクトル検索中に明示的なポリシー強制がなくても、データ間の事前分離が可能になります。
Pineconeは、単一のインデックス内に名前空間を定義することでこれを実現しています。それぞれが、特定の顧客または組織向けに論理的に隔離されたスペースとして機能します。ベクトル検索中、クライアントはターゲットの名前空間を指定する必要があり、他の名前空間へのアクセスは厳密に拒否されます。これにより、ストレージレベルでのハード隔離が提供されます。
Weaviateは、シャードベースのストレージを使用して同様のアプローチを採用しています。各テナントのデータは別々のシャードに配置され、クエリはそのシャード専用にルーティングされるように構成されています[10]。
これにより、集中管理されたセキュリティ設定を必要とせずに、物理的な隔離と同等の論理的な分離が作成されます。これらのインフラストラクチャレベルの隔離モデルにより、プロバイダーは別のポリシーエンジンを必要とせずにデータの境界を強制できるため、何千もの同時テナントを抱えるSaaS環境で拡張性が高くなります。
ダイアグラム:PineconeとWeaviateにおけるベクトルベースマルチテナンシー
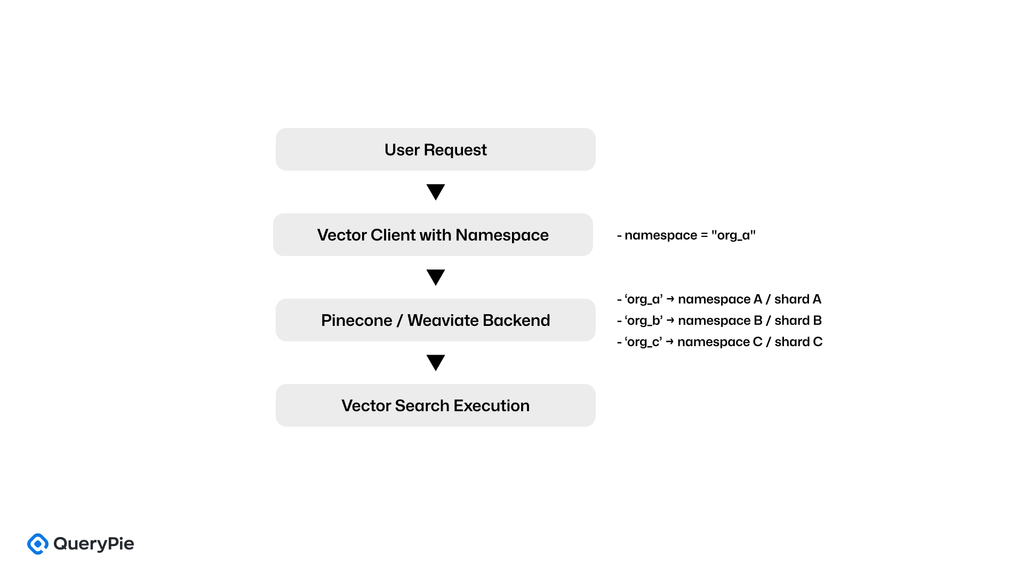
主要制御機能
| 制御項目 | 実装の説明 |
|---|---|
| ストレージの分離 | Pineconeは名前空間を使用。Weaviateはシャードを使用してテナントデータを分離。 |
| 外部アクセス隔離 | リクエストは、割り当てられた名前空間またはシャード外のデータにアクセスできません。 |
| ランタイム強制の不要性 | 隔離はポリシーエンジンなしで検索レイヤーで強制されます |
| 運用上の拡張性 | 論理的な分離により、何千ものテナントがいてもパフォーマンスが維持されます |
| インフラストラクチャレベルのセキュリティ | テナント隔離は、インデックスまたはシャード構成を通じて達成され、多層セキュリティシステムは不要 |
2.6 Meta:プロンプト注入前のコンテキスト認識フィルタリング|
Metaは、内部LLM実験とオープンリサーチを通じて、プロンプト注入フェーズでのランタイムポリシー強制を積極的に模索してきました。このアプローチは、セッションメタデータとドキュメントコンテキストの両方を評価することにより、基本的なベクトル類似度検索を超え、Purpose-Based Access Control(PBAC)モデルに非常によく似ています。
Metaは完全な実装を公開していませんが、プレゼンテーションや公開されたリサーチは、次のアーキテクチャを示唆しています。
ドキュメントの保存中、access_scope、confidentiality、created_atなどのメタデータフィールドが適用されます。
LLMプロンプトを生成する前に、システムはセッション情報(ユーザー、ロール、クエリコンテキスト)とこれらのメタデータ条件を比較し、どのドキュメントを注入できるかを決定します。
LLM応答にはドキュメントIDまたはサマリーハッシュへの参照が含まれており、実行後の監査を可能にします。
このアーキテクチャは、MicrosoftとQueryPieのRAGセキュリティ設計と概念的な類似点を共有しています。特に、Metaは機密データ漏洩を防ぐために事前実行フィルタリングを強化しており、LLMが応答を生成する前にポリシーを評価します。この予防的な設計により、応答後のフィルタリングの必要がなくなり、リスクが軽減され、より高いポリシー準拠が保証されます[11]。
ダイアグラム:MetaのコンテキストベースPBACフロー
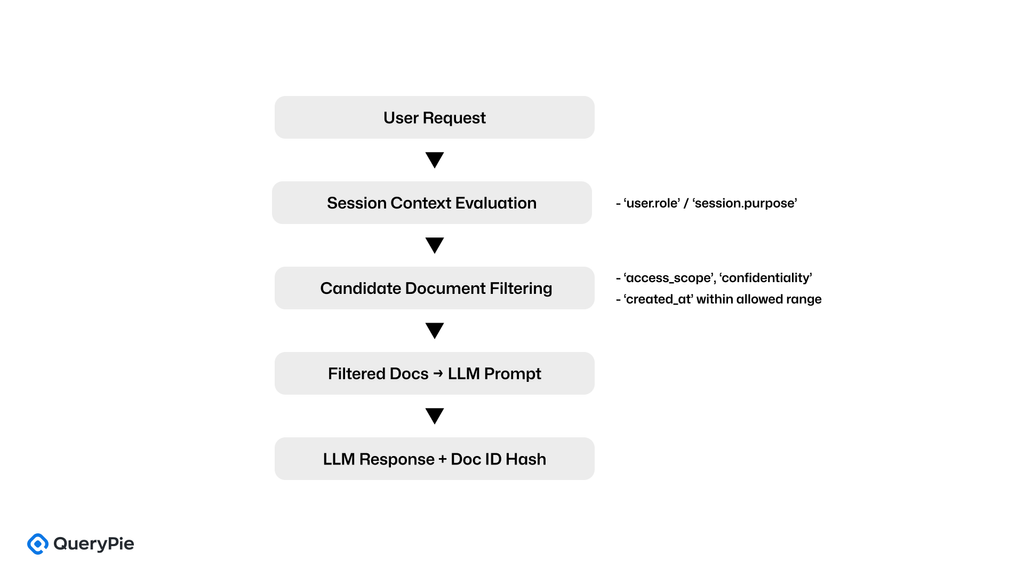
主要制御機能
|制御項目|実装の説明|
|コンテキストベースのポリシーフィールド|access_scope、confidentiality、created_atなどでタグ付けされたドキュメント|
|ユーザーセッション評価|user.role、セッション目的、およびクエリコンテキストによってアクセスが決定される|
|事前プロンプトフィルタリング|ポリシールールは、ドキュメントがLLMに渡される前に強制されます|
|応答の追跡可能性|監査のためにドキュメントIDまたはハッシュ参照を含むLLM応答|
|PBAC強制構造|目的、ユーザー属性、およびドキュメントコンテキストを統一されたポリシーフィルターに結合|
2.7 実践的な意味合いと技術的課題
Microsoft、AWS、Meta、LlamaIndex、Pinecone、およびWeaviateのケーススタディは、一貫した戦略的方向性を強調しています。RAGセキュリティは、プロンプト注入前の実行フローの制御に依存します。インフラストラクチャは異なりますが、すべてがランタイム強制を強調しており、RAG 2.0環境では従来のアクセス制御だけでは不十分であることを認識しています。
これらのアーキテクチャでは、セキュリティポリシーはクエリからドキュメント、応答までの動的なフロー全体にわたってリアルタイムで適用される必要があります。
実践的な意味合い
-
プロンプト注入が最終的なセキュリティバリア
- ほとんどのLLMは、与えられたドキュメントのみに基づいて応答を生成します。したがって、どのドキュメントをプロンプトに注入するかを制御することが、最終的かつ最も重要な防御レイヤーです。MicrosoftとMetaは、この段階でPBAC(Purpose-Based Access Control)を実装しています。プロンプト構築前に、ユーザーの意図、セッションメタデータ、およびドキュメント属性を評価します。
-
実行フローには多層強制が必要
- 一般的なRAGシステムは、クエリの埋め込み → ベクトル検索 → ドキュメントフィルタリング → プロンプト構成 → 応答生成というフローに従います。各ステップは異なるシステムレイヤーで動作するため、セキュリティ強制は分散的かつ累積的である必要があります。たとえば、LlamaIndexは取得時にフィルタリングを行い、Metaはプロンプト組み立て直前にポリシーを強制します。
-
ベクトルインフラストラクチャレベルの隔離も効果的
- PineconeやWeaviateなどのプラットフォームは、名前空間やシャードを使用してテナントデータを分離し、ランタイムポリシーエンジンなしで論理的な分離を実現しています。これは、動的なポリシー強制が複雑な大規模SaaS環境で特に役立ちます。
-
ポリシー表現はACLを超えて拡張する必要がある
- 単純なACL(Access Control Lists)だけでは、実行フローを保護するには不十分です。ユーザーセッション属性、クエリ意図、要求タイミング、およびドキュメントの状態を評価するには、CBAC(Context-Based Access Control)およびPBACモデルが必要です。これはMetaのアーキテクチャで示されているようにです。
-
重要なのはポリシーの反映であり、定義だけではない
- 多くの組織は正式なセキュリティポリシーを持っていますが、それらのポリシーを実際の実行フローに組み込むことに失敗しています。
真の強制とは、文書化することではなく、ランタイムでのライブポリシー反映です。
技術的課題
セキュアな実行ベースワークフローを実装するには、いくつかの技術的なハードルを克服する必要があります。
| 課題項目 | 説明 |
|---|---|
| 分散ポリシー強制 | ポリシーは、検索、フィルター、注入、応答など、分散されたレイヤー全体で一貫性を維持する必要があります。 |
| フィルター条件の欠落 | user_idやaccess_scopeなどのフィルターを省略すると、機密性の高いコンテンツが公開される可能性があります。 |
| セッションコンテキストの切り離し | セッションメタデータがポリシーエンジンに到達しない場合、強制は失敗します。 |
| 監査可能性の欠如 | どのプロンプトにどのドキュメントが注入されたかを追跡できないシステムには、説明責任がありません。 |
戦略的なポイント
この分析から、いくつかの戦略的なポイントが浮上します。
- プロンプトレベルの制御は、RAG実行セキュリティの重要なボトルネックです。
- リアルタイムのポリシー強制は、セッションメタデータとドキュメント属性の両方を考慮する必要があります。
- PBAC、CBAC、およびACLモデルは、代替として扱われるのではなく、統合されるべきです。
- ポリシーは静的に文書化されるだけでなく、実行時に動的に反映される必要があります。
3.実行フロー制御のためのセキュリティ戦略の設計
3.1 基本的な前提:実行フロー制御なしではセキュリティは効果がない
Microsoft、Meta、AWS、LlamaIndex、およびQueryPieの多様な実装が示すように、組織はマルチテナントRAGシステムを保護するためにさまざまなアーキテクチャアプローチを採用しています。しかし、それらはすべて1つの重要な洞察に集約されます。セキュリティは、モデルが応答を生成する前に、実行フロー全体にわたって強制される必要があります。
RAGでは、実行パスは埋め込み → 取得 → プロンプト構成 → モデル呼び出し → 応答生成にまたがります。いずれかの段階が制御されないままになると、ACLやアクセスポリシーは意味をなさなくなります。LLMは意図しないコンテンツを暗黙的に応答に含める可能性があるため、プロンプト注入段階が制御を強制する最後の機会です。
したがって、フロー認識型セキュリティ戦略は、リアルタイムで3つの本質的な質問に答える必要があります。
- 誰が尋ねているのか?(セッションベースのユーザーコンテキスト)
- 目的とコンテキストは何か?(クエリの意図、時間、およびリソースの範囲)
- どのドキュメントを注入できるか?(メタデータベースの制約)
3.2 実行フローセキュリティのための5つのコア原則
基盤となるプラットフォームやフレームワークに関係なく、RAG実行パイプラインを保護するために、次の5つの原則がRAG 2.0セキュリティアーキテクチャのベースラインを形成します。
原則1:セッションベースのポリシー評価
認証トークンやセッションIDは、アクセスのみに使用されるのではなく、ポリシー評価の中心的なコンテキスト入力として機能する必要があります。プロンプト構成前に、ユーザーの役割、権限、属性をリアルタイムで評価し、どのドキュメントが注入に適格であるかを判断する必要があります。このモデルは、Microsoft、Meta、およびQueryPieによって実装または採用されています。
原則2:メタデータに基づくドキュメントフィルタリング
すべての埋め込みドキュメントには豊富なメタデータ(例:user_id、tenant_id、security_level、document_type)が含まれている必要があり、ベクトル検索ではこれらのフィールドをフィルター条件として適用する必要があります。このステップは開発中に見落とされやすいため、コンプライアンスを確保するために、ポリシー抽象化レイヤーを通じて強制するか、APIプロキシでラップする必要があります。
原則3:パイプライン途中での分岐と制御
ドキュメントがプロンプトに注入される前に、ランタイムポリシーによって条件付きの分岐またはブロックが可能である必要があります。たとえば、ユーザーが機密性の高いカテゴリ(例:「業績評価」)を照会したり、許可されていない時間帯に要求を送信したりした場合、システムはドキュメントの注入を動的に拒否する必要があります。これにより、柔軟でコンテキスト認識型の強制がサポートされます。
原則4:追跡可能な実行パス
フロー全体は、単なる生ログではなく、追跡可能なセッションとしてログに記録する必要があります。セキュリティログには、どのポリシー条件(合格または不合格)の下で、どのドキュメントがどのクエリに注入されたかを視覚化する必要があります。これは、特に金融、医療、公共部門での監査と説明可能性にとって重要です。
原則5:入力と出力間のプロベナンス結合
LLM応答は、どのドキュメントに基づいているかを明示的に参照する必要があります。これは通常、出力内にドキュメントIDまたは暗号化署名を埋め込むことによって行われます。これにより、信頼性、透明性、および事後監査可能性が向上し、意図しない開示やポリシー違反の調査が容易になります。
3.3 実行フローセキュリティのアーキテクチャの概要
次の図は、前述の5つのコア原則に基づいて構築されたランタイムセキュリティ制御の概念アーキテクチャをまとめたものです。

3.4 セキュリティアーキテクチャバイパスの実現可能性
上記の5つの原則はRAGセキュリティ設計の強固な基盤を提供しますが、現実世界のシステムは設計上の欠陥だけでなく、バイパスの試みにも積極的にさらされています。
これらの脅威は単なる技術的な脆弱性ではなく、プロンプト注入アーキテクチャとポリシー評価フロー間の切断を悪用します。そのため、セキュリティ設計は「許可されていること」を宣言するだけでなく、「それらの許可が実際に強制されているかどうか」を証明することに焦点を当てる必要があります。
このホワイトペーパーの次のセクションでは、セキュリティアーキテクチャを侵害する可能性のある現実的な攻撃シナリオを探ります。Kennyのケースに加えて、次の5つの実行可能な攻撃パスを検討します。
- 給与情報などの人事データ漏洩
- LLM応答における不正なドキュメントの概要の包含
- ユーザーのチーム外のドキュメントに基づく捏造された回答
- セッション共有による特権昇格
- ポリシーチェックの欠落による期限切れまたは非推奨コンテンツの開示
4.セキュリティアーキテクチャをバイパスする脅威シナリオの分析
4.1 シナリオベースの脅威モデリングが重要な理由
前述の実行フローに基づいたセキュリティ戦略は、原則として強力な基盤を提供しますが、設計と実装の間のギャップや、未処理のエッジケースにより、現実世界での展開ではそれらの戦略が不完全な保護策になる可能性があります。RAGシステムは、ベクトル検索 → ドキュメント注入 → プロンプト構成 → 応答生成というパイプラインを通じて動作します。これらは多くの場合、個別のコンポーネントとして管理されるため、ポリシー適用レイヤー間のセキュリティの盲点のリスクが高まります。
このセクションでは、攻撃者や設定ミスが、適切に設計されたアーキテクチャをどのようにバイパスできるかを示す5つの脅威シナリオについて概説します。これらのシナリオは、企業の内部テスト、実際の運用、およびセキュリティコミュニティによって提起された構造的な脆弱性から引き出されています。これらは純粋な技術的な欠陥から発生するのではなく、ポリシーの盲点を反映しており、インフラストラクチャが表面上安全に見えても情報漏洩が発生する可能性があることを示しています。
4.2 シナリオ1:メタデータフィルターの欠落による給与データの露出
概要
- 内部RAGエージェントに「最近採用された人の給与範囲は?」とユーザーが問い合わせます。
- ユーザーのセッションは認証されましたが、ベクトル検索でuser_idフィルターが省略されたため、別の部署の機密性の高いドキュメントがプロンプトに注入されました。
- モデルは、機密性の高い給与情報を含む要約された応答を返します。
違反原則
- 原則2:メタデータに基づくフィルタリングの欠落
- 原則3:パイプライン途中の分岐なし
実現可能性
- ベクトルDBフィルターがコードレベルで手動で適用される場合、人的エラーが発生しやすくなります。
- ポリシーエンジンやAPIレベルでの強制がない場合、このような省略を検出またはリカバリーすることは困難です。
4.3 シナリオ2:許可なく別のチームのドキュメントを引用
概要
- 開発者が「新製品の設計思想は何でしたか?」と問い合わせます。
- LLMは、設計チームが作成したドキュメントからの抜粋を含めます。
- ドキュメントは技術的には公開されていますが、問い合わせ元のユーザーはそのドキュメントにセッション属性に基づいてコンテキストアクセス権限がありません。
違反原則
- 原則1:セッションベースのポリシー評価の欠落
- 原則5:応答元への追跡可能性なし
実現可能性
- 多くのシステムは、ドキュメントの「公開」状態のみに基づいてアクセスを許可します。
- しかし、RAGでは、コンテキストセッション評価が注入の適格性を管理する必要があります。公開ドキュメントの場合でもです。
4.4 シナリオ3:セッション共有またはエージェントクローンによる特権昇格
概要
- ユーザーAは承認されたセッショントークンをユーザーBと共有するか、内部RAGエージェントを個人ワークスペースにクローンします。
- クローンされたエージェントには統合されたポリシー強制機能(例:PDP)はありませんが、元の構成を使用して検索を実行し、Bの範囲外のドキュメントにアクセスします。
違反原則
- 原則1:セッションベースの制御なし
- 原則4:実行パス監査なし
実現可能性
- クローンされたワークフローにPDPモジュールが転送されない場合、すべてのセキュリティロジックがバイパスされます。
- LangChainやLlamaIndexのようなエージェントフレームワークは、そのモジュール式で複製しやすい構造のため、特に脆弱です。
4.5 シナリオ4:期限切れまたは機密性の高いドキュメントが強制されない
概要
3年前の役員の退職に関するドキュメントがベクトルDBに残っています。非推奨とマークされているにもかかわらず、新しいクエリとのセマンティック類似性が高いため取得されます。ベクトル埋め込みにTTLまたは有効期限ポリシーが割り当てられていなかったため、モデルは古い、誤解を招く応答を生成します。
違反原則
- 原則2:有効期限/分類のメタデータフィルターが適用されない
- 原則3:注入前にポリシーベースのフィルタリングなし
実現可能性
- ほとんどのベクトルDBは、埋め込みに対するTTL(Time-to-Live)または有効期限強制をネイティブでサポートしていません。ライフサイクル認識埋め込みがない場合、古いコンテンツがひっそりと再導入されます[15]。
4.6 シナリオの概要
| シナリオ | 脅威の種類 | 違反原則 | 主要な脆弱性のポイント |
|---|---|---|---|
| 4.2 | フィルター省略による情報漏洩 | 2、3 | ベクトル検索前 |
| 4.3 | コンテキスト無視応答の注入 | 1、5 | プロンプト構成フェーズ |
| 4.4 | クローンベースのアクセス昇格 | 1、4 | クローンでの認証/監査の欠落 |
| 4.5 | 期限切れまたは機密性の高いドキュメントの露出 | 2、3 | 埋め込みの有効期限制御なし |
4.7実行フローバイパスの脅威によって明らかになった課題
上記のシナリオは、ポリシー宣言や認証メカニズムだけではセキュリティが確保できないことを明確に示しています。いずれの場合も、セキュリティポリシーが実際の実行フローに適用されなかったか、プロンプト構成パスに正しく統合されなかった場合に脅威が発生しました。
これらの調査結果は、重要な要件を示しています。組織は、RAG実行パイプラインの各段階にポリシー強制を直接組み込む必要があります。単に「誰が何にアクセスできるか」を定義するだけではもはや十分ではありません。代わりに、ポリシーロジックはランタイムコンテキスト内で動作し、どのコンテンツを注入、フィルタリング、または拒否するかをリアルタイムで決定する必要があります。
Microsoft、Meta、QueryPieなどの主要プラットフォームは、すでにこの方向に進んでいます。宣言型セキュリティモデルのみに依存するのではなく、PBAC(Purpose-Based Access Control)、CBAC(Context-Based Access Control)、ACL(Access Control Lists)、およびPDP(Policy Decision Points)を運用アーキテクチャに統合し、ポリシーを実行に連携させています。
次のセクションでは、これら3社がアーキテクチャレベルと強制レベルの両方でRAG 2.0セキュリティにどのように取り組んだかの比較分析を示します。
5.実行フロー制御戦略の比較:Microsoft、Meta、QueryPie
5.1 目的:宣言型ポリシーから実行統合型強制へ
前述の脅威シナリオは、重要な洞察を強調しています。セキュリティの失敗はポリシーの不在からではなく、定義されたポリシーを実行フローに統合することの失敗から生じます。RAG(Retrieval-Augmented Generation)環境では、重要なセキュリティポイントは、誰がドキュメントにアクセスできるかということだけではなく、いつ、どのようなコンテキストで、誰によってドキュメントがプロンプトに注入されるかということです。従来のRBACだけではこれを強制するには不十分です。
Microsoft、Meta、QueryPieは、それぞれ異なる方法でこの課題に取り組んでいます。
- Microsoftは、Graph APIとCopilot Gatewayを介してAPIレベルでポリシー評価を適用しています。
- Metaは、セッションコンテキストに紐付けられたContext-Based Access Control(CBAC)を使用して、プロンプト構築の直前にドキュメント注入を評価します。
- QueryPieは、独自のRAGシステムは提供していませんが、外部LLMまたはRAGシステムの前段に位置し、実行フローを管理するポリシー強制レイヤー(MCP Agent PAM)を提供しています。
QueryPieのモデルは、特定のベクトルDBやエージェントフレームワークに縛られない、モジュール式で拡張可能なセキュリティアーキテクチャを提供するという点で、MicrosoftやMetaとは異なります。ポリシー評価(PDP; Policy Decision Point)、強制(PEP; Policy Enforcement Point)、およびコンテキストソーシング(PIP; Policy Information Point)を提供し、さまざまなマルチテナント実行フローにわたるセキュリティレイヤーリングを可能にします。
この章では、次の5つの主要な側面でそれらの戦略を比較します。
- PBACポリシーアプリケーションレイヤー
- CBAC実装モデル
- ACL統合範囲と柔軟性
- PDP/PIP/PEPアーキテクチャ配置
- 実行フロー制御のスケーラビリティと広さ
目的は機能を比較することではなく、ポリシーがランタイムフローにどのように、どこに埋め込まれるかを評価することです。ポリシーの価値は文書化にあるのではなく、実際の実行パス内で評価および強制されるかどうかにあります。
5.2 Microsoft:Graphベースのポリシー条件とAPIレベルのPDP
マルチテナントAzure OpenAI環境では、MicrosoftはGraph APIを使用して、ユーザー権限、ドキュメントメタデータ、およびコラボレーションコンテキストを一元的に管理します。これらの要素は、Copilot API Gatewayに組み込まれたPDPモジュールによってリアルタイムで評価され、特定のドキュメントがプロンプトに注入されるかどうかを管理します[18]。
このアーキテクチャは、次の実行フロー制御プロセスに従います。
- ユーザーがCopilot APIを通じてクエリを送信すると、システムはMicrosoft Graphを使用して、ユーザーの組織内の役割、協力者、タスク関連の意図などのコンテキスト情報を取得します。
- API Gatewayはこのコンテキストを活用してクエリの目的を推論し、関連するドキュメントがアクセスに適格かどうかを評価します。
- 承認されたドキュメントのみがプロンプトに注入され、注入の詳細と結果として得られるLLM応答は監査システムに記録されます。
Microsoftのアプローチは、PBAC(Purpose-Based Access Control) モデルを最も明確に実装した例の1つであり、組織の役割とタスクの目的に基づいてドキュメントの公開を動的に調整します。 CBAC(Context-Based Access Control) の場合、Microsoftはデバイス、時間、場所などのセッション属性をポリシー評価に含めます。
ACL統合の場合、MicrosoftはSharePoint、OneDrive、Teamsのネイティブ権限構造を使用して、既存のM365エコシステムに直接連携します。
そのPDPアーキテクチャはAPI Gateway内に集中化されており、内部システムには効果的ですが、Microsoft環境外のサードパーティRAGエージェントやLLMパイプラインを統合するには柔軟性が劣ります。
Microsoftの実行フロー制御の概要
| 側面 | 説明 |
|---|---|
| PBAC適用レイヤー | プロンプト構築前にGraphとAPI Gatewayがクエリの目的を評価 |
| CBAC実装 | セッションコンテキストベース(ユーザー、デバイス、時間、呼び出し元ID) |
| ACL統合 | M365権限(SharePoint、OneDrive、Teams)とのシームレスな連携 |
| PDPアーキテクチャ | Copilot API Gateway内の中央集約型PDP |
| 制御範囲 | Copilot内では効果的。異種外部ワークフローには限定的 |
Microsoftのアーキテクチャは、企業資産とポリシー強制の厳密な連携を提供し、M365中心の組織内で非常に効果的です。ただし、サードパーティのRAG/LLMワークフローとの統合には追加のカスタマイズが必要であり、そのままでは直接適用できません。
5.3 Meta:LLMプロンプト前のドキュメント注入に組み込まれたCBAC
MetaのLLMインフラストラクチャは、プロンプト構築の直前のドキュメント注入段階でのポリシー評価を重視しています。単純な認証ベースのアクセス制御とは異なり、Metaはセッションコンテキスト(セッションメタデータ)とドキュメント属性(コンテキストメタデータ)を統合して、実行時にドキュメントをプロンプトに含めることができるかどうかを動的に判断します[11]。
Metaは通常、次の実行フローに従います。
- ユーザーがクエリを送信すると、セッションID、ユーザーロール、目的などのセッションレベルのメタデータが内部ポリシー評価エンジンに渡されます。
- 取得されたドキュメントには、access_scope、confidentiality、created_atなどのメタデータが含まれており、これらはセッション属性と比較されます。
- この比較に基づいてポリシー条件を満たすドキュメントのみがプロンプトに転送されます。
- LLM生成された応答には、後続の監査と追跡可能性を可能にするために、参照ハッシュまたはドキュメントIDが含まれます。
これは、コンテキストベースのアクセス制御(CBAC)の教科書的な実装であり、ランタイム実行コンテキストに基づいてドキュメントの適格性を動的に判断します。ドキュメントに目的タグや分類フィールドが含まれている場合、MetaはPBAC(Purpose-Based Access Control)拡張機能もサポートします。
システムは独自のACLモデルを使用して、ユーザーとドキュメントのアクセス権限マッピングを事前に定義します。実行時に、CBACポリシーエンジンはドキュメント注入条件を再評価し、現在の実行コンテキストと一貫していることを確認します。
MetaのアプローチはMicrosoftのアーキテクチャと概念的な類似点を共有していますが、ポリシー評価がプロンプト組み立ての直前のオーケストレーションレイヤーで行われるという点で異なります。これにより、よりきめ細かなリアルタイム制御が可能になります。
ただし、Metaのポリシーエンジンは独自のインフラストラクチャに深く組み込まれており、外部SaaSツールや異種RAGコンポーネントとの統合のための汎用APIを公開していません。これにより、その柔軟性と相互運用性は制限されます。
Metaの実行フロー制御の概要
|側面|説明|
|PBAC適用レイヤー|メタデータ内のドキュメント目的フィールドに基づく|
|CBAC実装|ランタイム評価:セッションコンテキストとドキュメントメタデータの比較|
|ACL統合|ユーザーとドキュメントのマッピングのための独自の内部ACLモデル|
|PDPアーキテクチャ|オーケストレーターに埋め込み(プロンプト構築直前)|
|制御範囲|Metaの内部LLM内での厳密なランタイム制御。外部統合は限定的|
Metaの戦略は、モデルが応答を生成する前に注入を制御することで、文書濫用のリスクを大幅に低減する強力な事前プロンプト強制機能を提供します。ただし、このアーキテクチャは内部利用向けに最適化されており、大幅な適応なしに外部エージェントプラットフォームやマルチクラウド環境で再現するのは困難な可能性があります[20]。
5.4 QueryPie:階層化されたOPAベースのポリシーモデルによるフル実行パス制御
MicrosoftやMetaとは異なり、QueryPieは独自のRAG(Retrieval-Augmented Generation)エンジンを提供していませんが、代わりに さまざまなLLM、ベクトルDB、およびプロンプトオーケストレーションチェーンの上流に位置するセキュリティ強制レイヤーであるMCP Agent PAM を提供しています。これは、QueryPieが単なるアイデンティティまたはアクセスツールではなく、フルスタックのポリシーベース実行セキュリティアーキテクチャであることを区別します [21]。
核心的には、QueryPieはOpen Policy Agent(OPA)フレームワークを中心に構築されており、PDP(Policy Decision Point)、PEP(Policy Enforcement Point)、およびPIP(Policy Information Point)をモジュール式で階層化されたコンポーネントとして実装しています。
実行フロー制御モデル
- ユーザーのクエリは、MCP Agent PAMプロキシ(PEP)レイヤーによって傍受されます。
- プロキシは、セッションの詳細(ユーザーロール、クエリの目的、タイムスタンプ、リスクスコア)を抽出し、それらをPDPに送信します。
- PDPは、ポリシーファイル(例:ai-policy.yaml、JSON)に基づいてリクエストを評価します。これらのファイルは、PBAC、CBAC、およびACLルールを複合オブジェクトモデルで組み合わせたものです。
- リクエストがポリシー検証に失敗した場合、ドキュメントは注入がブロックされます。すべての実行パスは、構造化されたトレースとしてログに記録されます。
QueryPieは、さまざまなアクセス制御タイプを統合する 統一されたセキュリティモデル をサポートしています。
- ABAC(属性ベースのアクセス制御):ドキュメント/ユーザーメタデータに基づく
- ReBAC(関係ベースのアクセス制御):組織レベルのマッピングに基づく
- RiskBAC(リスクベースのアクセス制御):時間、場所、セッションリスクなどの動的条件
重要なのは、QueryPieがポリシーを評価するだけでなく、それらのポリシーが実行フロー内で積極的に強制されることを保証し、ポリシー認識ランタイム制御システムにしていることです。
MetaやMicrosoftとは異なり、QueryPieは 単一のエージェントやバックエンドに縛られておらず 、多くのRAGシステム全体でユニバーサル制御レイヤー として機能します。スタックにLangChain、LlamaIndex、AutoGenが含まれているかどうかにかかわらず、QueryPieはそのプロキシモデルを介して一貫したポリシーを強制できます。
QueryPieの実行フロー制御の概要
| 側面 | 説明 |
|---|---|
| PBAC適用レイヤー | ai-policy.yamlの目的フィールドがランタイム時に評価される |
| CBAC実装 | 複合評価:ユーザー/リソース/時間/リスク/メタデータ |
| ACL統合 | OPAベース。ABAC、ReBAC、RiskBACをサポート |
| PDPアーキテクチャ | プロキシレイヤー内の分散型PDP/PEP/PIP構造 |
| 制御範囲 | ベンダーニュートラルなRAGサポート。フルスタック実行パス制御 |
QueryPieは、実行パイプライン内での強制の深さとアーキテクチャの柔軟性の最も堅牢な組み合わせを提供し、マルチエージェント、マルチバックエンド環境全体で中心的なランタイム制御レイヤーとして機能します。また、ポリシー競合検出、管理者承認注入、ガバナンス駆動型バージョン管理などの高度な機能も含まれており、組織が単一のRAGベンダーに縛られない完全に独立したポリシーを構築できます[22]。
実行フロー比較:Microsoft vs Meta vs QueryPie

5.5 比較概要:実行フロー制御戦略マトリックス
以下の表は、Microsoft、Meta、QueryPieがRAG実行フロー全体でセキュリティポリシーをどのように強制するかを比較したものです。主要な基準には、PBAC、CBAC、およびACL強制の配置、ポリシー決定ロジック(PDP/PEP/PIP)のアーキテクチャ上の場所、プロンプトレベルの制御の粒度、およびクロスシステム拡張性があります。
実行フロー制御戦略比較:Microsoft vs Meta vs QueryPie
| カテゴリ | Microsoft | Meta | QueryPie |
|---|---|---|---|
| PBAC強制ポイント | Microsoft Graphベースの権限評価 | ドキュメントメタデータ内の目的タグ評価 | ai-policy.yaml駆動のクエリ目的評価 |
| CBAC実装 | 部分的なセッションコンテキスト(API呼び出し元、タイムスタンプ) | 完全なセッションコンテキスト+ドキュメントメタデータの比較 | 複合コンテキスト:ユーザー、リソース、時間、リスク、メタデータ |
| ACL統合 | Microsoft 365 ACLシステムと統合 | 内部ACLマッピングモデル | OPAベース。ABAC、ReBAC、RiskBACをサポート |
| PDPアーキテクチャ | Copilot API Gatewayで集中管理 | Orchestratorに組み込み(プロンプト前レイヤー) | モジュール式PDP/PEP/PIP分離による外部プロキシレイヤー |
| ポリシーの柔軟性 | Graphポリシーによる限定的な拡張性 | 内部システム。内部スコープ | JSON/YAMLオブジェクトポリシーによる拡張可能。API対応 |
| プロンプト挿入制御 | フィルター適用後の注入のみ | ポリシー適用後の注入のみ | ポリシー結果に基づく動的な許可/拒否とハードゲート |
| スケーラビリティ | Microsoftエコシステムと密結合 | 企業内部での最適化 | 多様なLLM/RAG環境全体での幅広い適用性 |
| 実行制御の強度 | 中程度(静的強制に焦点) | 高(プロンプト前強制) | 非常に高(包括的なリアルタイムフロー制御) |
QueryPieは、実行パイプライン内でのアーキテクチャの独立性とポリシー統合の柔軟性において最も堅牢な組み合わせを提供します。PBAC、CBAC、およびACLを統合ポリシー スキーマとしてサポートし、リクエスト評価から監査ログ記録およびバージョン管理までの完全なライフサイクル制御を可能にすることにより、QueryPieはマルチエージェントRAGシステムにおけるランタイムセキュリティの最も重要な要件に対応します[23]。
5.6 QueryPieの役割:RAGシステムではなく、RAG保護のための統合制御ソリューション
QueryPieは独自のRetrieval-Augmented Generation(RAG)エンジンを提供していませんが、代わりにLLMベースのRAG環境を保護するために特別に構築された実行レイヤー制御プラットフォームとして設計されています。この理由から、本ホワイトペーパーではQueryPieをRAGプロバイダーとしてではなく、マルチRAGインフラストラクチャに適用可能なユニバーサルポリシー強制ソリューションとして位置付け、MicrosoftおよびMetaと並行してその戦略を比較しています。
MCP Agent PAM を通じて、QueryPieは プロンプト注入に先立つ すべてのステップを制御する構造化された PDP(Policy Decision Point)、PEP(Policy Enforcement Point) 、および PIP(Policy Information Point) アーキテクチャを実装しています。そのポリシー実行は、次のメカニズムに基づいています。
- Policy as Code(PaC) :ai-policy.yamlまたはJSONベースのポリシーファイルを通じて実行条件が定義されます。
- PBAC(目的ベースのアクセス制御) :ユーザーのリクエストの宣言された目的に基づいて、ドキュメントの注入が許可または拒否されます。
- CBAC(コンテキストベースのアクセス制御):ポリシーは、セッション属性、デバイスの種類、タイムスタンプ、およびリスクコンテキストに基づいて動的に評価されます。
重要な構造的要件は、QueryPie MCP Agent PAMが、user_id、doc_type、access_scope、または機密情報などのメタデータを渡すために外部RAGソリューションに依存することです。LangChain、LlamaIndex、AutoGenなどのフレームワークは、そのようなメタデータを転送できる必要があり、これによりQueryPieはACLポリシーレイヤーを通じてポリシーを独立して評価できます。
したがって、QueryPieは、基盤となるRAGベンダーまたはアーキテクチャに依存しない、分離されたポリシー強制レイヤーとして機能します。ベクトルデータベースとプロンプト構築の間のフローをラップし、実行レイヤーで不正なドキュメント注入やデータ漏洩をブロックします。
さらに、QueryPieはポリシー駆動型強制を通じて次の機能を保証します。
- マルチテナント隔離:namespace、user_id、ロール、doc_type、および機密性フィールドを使用したポリシーによるベクトルデータの論理的なパーティショニング。
- 競合検出と動的承認:競合するポリシーの特定と、高リスクアクションに対する管理者承認フローの挿入。
- ポリシートレース可能性と監査対応ロギング :事後フォレンジックとコンプライアンスのために、実行時にすべてのリクエストコンテキストとポリシー結果がログに記録されます。
最終的に、QueryPieは単なるポリシー定義ユーティリティではありません。異種RAG環境とエージェントアーキテクチャ全体でACL、PBAC、およびCBACポリシーを強制するプラットフォーム独立型セキュリティレイヤーです[24]。
5.7 統一された実行フロー可視性:単純なガードレールを超えた構造的制御の必要性
最新のAI駆動情報システムは、単一の言語モデル(LLM)呼び出しを中心に構築されなくなりました。ほとんどのエンタープライズ設定では、LLMはより大きなエコシステムの一部であり、AIエージェント、ベクトル検索エンジン、外部API、ドキュメントプリプロセッサー、およびMCP(Model Context Protocol)サーバーと並行して動作します。このアーキテクチャは、複数の実行コンポーネントが協力して応答を生成する分散ポリシーフローを構成します。
このようなアーキテクチャ内では、プロンプト入力制限や出力フィルタリングなどの従来のガードレールは不十分です。次のシナリオは、これらの制限を明確に示しています。
AIエージェントが不完全にフィルタリングされたドキュメントをLLMに配信して応答を生成する。
MCPサーバーがリクエストを書き換えるかリダイレクトし、予期されるポリシーロジックをバイパスする。
不正なエージェントがAgent-to-Agent(A2A)通信フロー内で実行をトリガーする。
これらの複雑な多層呼び出し構造では、真のセキュリティは、実行パス全体にわたってランタイムでポリシーを強制することによってのみ実現できます。これは静的な宣言以上のものであり、実行時ポリシー強制を要求します。
QueryPieのMCP Agent PAMは、この課題に正確に対応するために設計されています。 単一のLLMを監視するだけでなく、AIエージェントからMCPサーバー、LLMまでの呼び出しチェーン全体を、統一されたポリシー認識プロキシレイヤー内にラップし、次の機能を提供します。
- PDP(ポリシー決定ポイント):セッション属性、実行目的、およびリクエストメタデータに基づいてポリシーを評価します。
- PEP(ポリシー強制ポイント):ポリシー結果を許可、変更、または拒否することによって、プロンプトの組み立てとドキュメントの注入を制御します。
- PIP(ポリシー情報ポイント):正確なポリシー評価に必要な外部コンテキスト(例:ユーザーロール、ドキュメント分類)を動的に取得します。
この設計は、ドキュメントレベル(ACL)でのアクセス制御を超え、AIシステム全体を「ポリシー優先アーキテクチャ」に再構築します。 QueryPieが公式ホワイトペーパーで概説しているように、QueryPieは次の原則を表明しています。
- 「ポリシーはプロンプトの外に存在するだけでなく、実行パスの中に適用されなければならない。」 — 実行優先の哲学[25]
- 「AIエージェントによって開始されたフローでさえ、ポリシー評価の対象となる必要があり、必要な場合はリアルタイムで承認の挿入または介入が可能である必要がある。」 — 実行レイヤー制御戦略[26]
- 「MCP PAMは単なるアクセス制御コントローラーではなく、AIアーキテクチャ全体を保護および視覚化するための中心的なポリシー強制レイヤーである。」 — アーキテクチャセキュリティミッション[27]
この構造的制御モデルは、セキュリティを強化するだけでなく、 説明可能性、規制コンプライアンス、およびユーザーの信頼性をサポートします。
要約すると、AIセキュリティ戦略の未来は、静的なガードレールではなく、 実行パスの動的な、ポリシーが強制されたオーケストレーションにあります。QueryPieのアーキテクチャは、 次世代AIシステムを保護するための最も現実的かつ将来互換性のあるモデル の1つを提供します。
6.結論 – 実行フロー制御がRAG 2.0セキュリティの中心である理由
6.1 静的ポリシー宣言はもはや十分ではない
RAG(Retrieval-Augmented Generation)2.0パラダイムでは、AIシステムは静的なデータセットのみに依存するのではなく、ランタイム時に外部知識を動的に取得および組み込み、応答を生成します。プロンプトに挿入されるドキュメントは、ベクトル類似度検索に基づいて選択されます。このプロセス中に、ユーザーアクセス権限やドキュメントの機密性などのセキュリティ条件が適切に強制されない場合、不正な情報がLLMの応答を通じて公開される可能性があります[28]。
その結果、次のような従来の二項対立のセキュリティ質問:
「ユーザーXはリソースYにアクセスできますか?」
は、次のようなコンテキスト認識評価に進化する必要があります。
「セッションTおよび目的Zの下で、ユーザーXがドキュメントYをプロンプトに注入し、LLM生成応答に使用することは適切ですか?」
ドキュメント使用のコンテキストとタイミングを考慮するセキュリティ評価は、ACL(Access Control List)やRBAC(Role-Based Access Control)のような従来のモデルだけでは適切に処理できません。代わりに、PBAC(目的ベースのアクセス制御)、CBAC(コンテキストベースのアクセス制御)、およびRiskBAC(リスクベースのアクセス制御)を組み合わせて全体的に適用する必要があります[29]。
典型的なRAGシステムには、次の順次実行段階が含まれます。
- ユーザー要求の受信
- ベクトルベースの取得の実行
- ドキュメントのフィルタリングと選択
- プロンプトの作成
- LLMの呼び出しと応答の返却
この複数ステップの実行フローのいずれかの時点でポリシー評価が省略された場合、システムは事前定義されたアクセス制御をバイパスする不正な実行パスを生成する可能性があります。このため、セキュリティポリシーは静的な宣言や事前設定されたルールを超えて、実行ベースのセキュリティアーキテクチャの必要性を示し、プロンプト構成の時点で動的に強制される必要があります。
6.2 ランタイム認識セキュリティアーキテクチャの3つの柱
効果的なRAGセキュリティを実装するには、ポリシー評価自体が実行フロー内で発生する必要があります。これには、3つの重要なコンポーネントの協調的なフレームワークが必要です。
|コンポーネント|役割|
|PDP(ポリシー決定ポイント)|セッションコンテキストと定義されたポリシーに基づいて、ユーザーのリクエストを許可するかどうかを評価する|
|PIP(ポリシー情報ポイント)|ポリシー評価で使用するためのコンテキストメタデータ(ユーザー属性、ドキュメントタグ、タイムスタンプ、リスクレベルなど)を提供する|
|PEP(ポリシー強制ポイント)|実行フロー(ドキュメント注入、リクエストのブロック、または承認プロセスのトリガーなど)を制御することにより、ポリシー決定を強制する|
このアーキテクチャにより、組織はポリシーのライフサイクル全体(宣言から強制まで)をライブデータフロー内に組み込むことができます。現在、主要なプラットフォームはこの構造を異なる方法で採用しています。
- Microsoft は、CopilotのAPI GatewayでMicrosoft Graphを介してアクセス権を評価します。プロンプト構築前に役割ベースのアクセスを適用しますが、ポリシー制御は静的であり、ランタイムフローへの影響は限定的です。
- Meta は、そのオーケストレーションレイヤー内でランタイムコンテキスト認識型のCBAC/PBAC評価を実装しています。プロンプト構築の直前に、ユーザーセッション属性とドキュメントコンテキストに基づいてドキュメントがフィルタリングされます。このモデルはランタイム強制を保証しますが、拡張性と外部相互運用性は限定的です。
- QueryPie は対照的に、MCP Agent PAM構造を通じてPDP、PIP、およびPEPを分離して外部に展開します。この設計は、ベクトル取得からドキュメント注入およびモデル呼び出しまでの実行パス全体をラップし、ポリシーロジックをすべての重要な接合点で適用できるようにします。ポリシー評価の結果に基づいて、実行パスを動的に再ルーティング、ブロック、またはエスカレーションできます。QueryPieはセッション全体のポリシーガバナンスをサポートしており、プロンプト → モデル呼び出し → 応答 → 監査という完全な対話シーケンスにわたる追跡可能な制御を可能にしています。
要するに、実行ベースのセキュリティとは、ポリシーを宣言することではなく、ランタイムでポリシーが積極的に強制されることを保証することです。次のセクションでは、PBAC、CBAC、およびACLなどのモデルを通じてこれらのランタイム制御がどのように構造化され、調和されるかを探ります。
6.3 PBAC、CBAC、ACLは統合されている場合にのみ機能する
RAG環境で意味のあるセキュリティを実装するには、目的ベースのアクセス制御(PBAC)、コンテキストベースのアクセス制御(CBAC)、およびアクセス制御リスト(ACL)をサイロで運用することはできません。これらのモデルは、統合された評価レイヤーとして機能する必要があります。各モデルは重要な役割を果たしますが、特定の制限もあります。
-
PBAC(目的ベースのアクセス制御)
- 要求の目的(例:ユーザーが業績評価のためにアクセスを要求しているかどうか)に基づいてポリシーを評価します。
- それ自体では、完全な実行コンテキストを考慮しません。
-
CBAC(コンテキストベースのアクセス制御)
- セッションの時間、ユーザーの役割、デバイス、リスクスコアなどの動的なランタイムコンテキストを評価します。
- ドキュメントレベルの権限は評価しません。
-
ACL(アクセス制御リスト)
- 事前定義された静的なドキュメント/リソース権限を適用します。
- ランタイムコンテキストを無視し、実行中に簡単にバイパスされます。
これらのモデルは補完的であり、RAGのようなフローベースのシステムでは、それらを分離すると、ポリシーの競合、盲点、監査のギャップなどの問題が発生します[33]。
これを解決するには、統一されたポリシー戦略に以下を含める必要があります。
- PBAC :リクエストの目的、部門、ビジネス意図に基づいてドキュメント注入の適格性を判断します。
- CBAC :セッションメタデータ(例:デバイス、時間、リスクスコア)を動的に評価し、ポリシー実行を許可またはブロックします。
- ACL :ドキュメント属性(例:所有者、機密レベル、作成日)を使用してアクセスを検証します。
これらは競合するモデルではなく、実行時に一緒に評価する必要のあるランタイムポリシーロジックの異なる側面です。
QueryPieのランタイムポリシー統合アーキテクチャ
QueryPieのMCP Agent PAMは、これらのアクセスモデルを実行時に統合および強制するように設計されています。そのアプローチには以下が含まれます。
1.ポリシーモデルの収束
ai-policy.yamlまたはJSONのポリシー定義により、PBAC、CBAC、およびACLロジックを一緒に表現できます。 例:
# YAML
allow_if:
purpose: "hr.audit"
session.role: "manager"
doc.confidentiality: "low"
session.risk_score: < 3
2.オブジェクト中心評価(OPAベース)
Open Policy Agent(OPA)を活用し、QueryPieは、ユーザー、ドキュメント、セッションなどの統一されたオブジェクトモデルを中心にすべてのポリシー評価を構造化し、複雑な多次元ロジックとネストされた条件を可能にします。
3.ReBACおよびRiskBACへの拡張可能
単純なユーザーとドキュメントのマッピングを超えて、QueryPieはReBAC(関係ベースのアクセス制御)およびRiskBAC(リスクベースのアクセス制御)もサポートしています。これにより、組織内の関係(報告ラインやチーム所属など)や、ログイン場所や脅威インジケーターなどのセッションレベルのリスク要因を考慮するポリシーが可能になります。
4.マルチフレームワーク統合
QueryPie自体はRAGエンジンとして動作せず、外部システム全体で制御レイヤーとして機能します。これにより、LangChain、LlamaIndex、AutoGen、Weaviate、Pineconeなど、メタデータ駆動型ポリシー強制が可能になります。
この統一された強制レイヤーにより、ACL + PBAC + CBAC + ReBAC + RiskBACが同じポリシー ストリーム内で連携して動作し、リアルタイムのコンテキストリッチなアクセス制御が保証されます。
QueryPieは、ポリシーモデルを概念的に統合するだけでなく、ランタイム時にそれらを動的に評価し、ドキュメントの挿入、拒否、エスカレーション、または監査ログ記録に必要な決定を適用します。これにより、アクセス制御はポリシー宣言からポリシー強制に移行し、セキュリティは実行可能かつ観察可能になります。
6.4 実行時セキュリティのためのアーキテクチャ上の推奨事項
RAG 2.0時代のセキュリティ戦略は、宣言型ポリシーや静的な権限だけに依存することはできません。ポリシーは、プロンプト、エージェント、LLM呼び出しなどのシステムコンポーネントがポリシー強制アーキテクチャ内に組み込まれた実際の実行フローに厳密に統合される必要があります。これをサポートするために、セキュアなRAG展開のための次の4つのアーキテクチャ原則を提案します。
1.プロンプト注入前にポリシーベースの分岐を設計する
ベクトル検索結果がプロンプトに注入される前に、システムはセッションコンテキストとドキュメント属性に対してそれらを評価する必要があります。このポリシーチェックは、特定の要求でドキュメントを使用することが許可されているかどうかを判断する必要があります。
例:ドキュメントの機密性が高とマークされ、要求元のリスクスコアが4以上の場合、ドキュメントの注入をブロックします。
2.宣言型ポリシーを実行認識型強制に変換する
JSONまたはYAMLで記述されたポリシーは、静的な宣言にとどまってはなりません。実行時に動的に評価される必要があります。これを達成するには、システムはポリシーエンジンをランタイム操作にリンクする必要があります。
OPA(Open Policy Agent)、Cedar、Regoなどのポリシーフレームワークは、この実行ベースのポリシー統合をサポートしています[36]。
3.PDP / PIP / PEP構造の分離と階層構成
ポリシー評価(PDP)、情報提供(PIP)、およびポリシー強制(PEP)を別々の独立したレイヤーに分離する必要があります。これらのコンポーネントは、リアルタイムポリシー仲介を確保するために、実行フローの前面または中間で仲介制御として機能する必要があります。
QueryPieは、プロキシベースの実装を通じてこれらのレイヤーを分離し、Metaは内部オーケストレーションレイヤー内でPDPとPEP機能を組み合わせています。
4.ポリシーフローを視覚化し、実行ログを構造化する
セキュリティチームとシステムユーザーの両方にとって、各ポリシーが特定のリクエストにどのように適用されたかを明確に理解できる必要があります。実行トレースには、リクエスト、ポリシー条件、決定結果、およびドキュメント注入ステータスを含める必要があります。これらは、構造化されたログ形式で保存する必要があります。
このアプローチは、監査可能性、説明可能性、およびコンプライアンス対応性の主要な要件を満たしています[37]。
これらの戦略は、アクセス制御を適用するだけではありません。セキュリティアーキテクチャの パラダイムシフト を反映しています。リソース中心のルールから、データとロジックがAIシステムをどのように通過するかを管理するフロー中心のポリシー 強制へと移行します。
6.5 結論
RAG 2.0時代では、セキュリティはもはやドキュメントを制限または隠蔽するだけでは信頼できません。代わりに、組織はより重要かつニュアンスのある質問に答えることができる必要があります。
誰がいつ、どのようなコンテキストと目的で、どのドキュメントにアクセスし、AI応答で使用されたか?
この答えは、静的な権限リストではなく、 実行フローに組み込まれたポリシー評価 にあります。セキュリティの焦点は、宣言的な制御からリアルタイムの強制へ、静的なアクセス管理から統合されたポリシーオーケストレーションへと移行する必要があります。この変革をリードできるアーキテクチャは、アクセス制御エンジンを超えたものである必要があります。ポリシー注入と評価から強制と追跡可能性まで、包括的な実行認識型制御を提供する必要があります。QueryPieのMCP Agent PAMは、このモデルの実用的で堅牢な実装として際立っています。このホワイトペーパーは、単なる孤立したLLMガードレールを超えて、 MCP、AIエージェント、LLM にまたがる 完全に統合された実行フローアーキテクチャ を採用し、AIセキュリティの中心にポリシー強制を配置するという戦略的なパラダイムシフトを提案します。
付録. 実行フローベースポリシー設計のための高度な概念:PBACとCBAC
A.1 目的ベースアクセス制御(PBAC)
PBACは、どのリソースに誰がアクセスを要求しているかだけでなく、なぜアクセスが要求されているかという理由も考慮してアクセス制御を拡張します。要求元のアイデンティティや役割ではなく、ユーザーの意図と要求の宣言された目的に基づいてポリシーロジックを集中させます[38]。
コアコンポーネント
| コンポーネント | 説明 |
|---|---|
| subject.purpose | ユーザーの要求の理由または意図(例:”hr.audit”、”incident.response”)。 |
| resource.usage_context | リソースに対して定義された許可される使用コンテキスト(例:"training only")。 |
| session.intent_type | 要求をトリガーするセッションフローのタイプ(例:手動リクエスト対エージェントチェーン実行)。 |
PBACは、これらの目的関連フィールドが一致するか、許可された範囲内で整合しているかを評価してからアクセスを許可します。
実装の特徴
- PBACは通常、ポリシー定義内で目的を認識可能な文字列またはタグとして表現します。
- 評価は、ポリシー決定ポイント(PDP)を介して、プロンプト前またはAPI前段階で行われます。
- たとえば、OPA(Rego)を使用すると、次のようにポリシーを定義できます。
allow {
input.subject.purpose == "hr.audit"
input.resource.purpose == "hr.audit"
}
制限と拡張
- PBAC単独では、セッションのリスクレベルやコンテキスト状態を考慮しません。 目的が誤って表現または虚偽で宣言された場合、PBACには組み込みのクロス検証メカニズムがありません。
- これを軽減するには、PBACを CBAC(コンテキストベースアクセス制御)またはRiskBACと組み合わせて、 リアルタイム実行フロー内でより堅牢な意思決定モデルを形成する必要があります。
A.2 コンテキストベースアクセス制御(CBAC)
CBACは、要求が発生する実行コンテキストを動的に評価してアクセス適格性を判断します。静的なルールに依存するのではなく、CBACは時間、場所、デバイス、動的なリスクスコアなどのリアルタイムのセッションレベル条件を適用します。これにより、実行フローセキュリティの基礎的なコンポーネントとなっています。
主要なコンテキスト要素
|属性|説明|
|session.time|要求のタイムスタンプまたはタイムゾーン(例:営業時間中対時間外)。|
|session.risk_score|リアルタイムのリスクスコア(例:MFA失敗、異常な地理位置情報から導出)。|
|device.type, ip.geo_location|デバイスおよびアクセス場所の物理的なプロパティ。|
|user.role|ロールベースの機能制限(例:表示のみアクセス、編集制限)。|
ポリシー評価ロジック
CBACは、PEP(ポリシー強制ポイント)がリアルタイムのセッションコンテキストをPDP(ポリシー決定ポイント)に転送し、PDPがそれに応じてアクセスポリシーを評価することで機能します。OPA、Cedar、Regoベースのシステムでは、CBACポリシーは次のようになります。
allow {
input.session.risk_score < 3
input.session.time >= "09:00:00"
input.device.type == "trusted"
}
アーキテクチャのスケーラビリティとフロー認識制御
- CBACは、実行フローセキュリティにおいていくつかの構造的な利点を提供します。
- セッションコンテキストとドキュメント属性をまとめて評価することにより、プロンプト注入に関する動的な決定を可能にします。
- CBACは、LLM呼び出し前、取得またはドキュメント注入段階で動作するため、応答後のフィルタリングのみに依存するのではなく、予防的な制御をサポートします。
多要素評価用に本質的に設計されており、PBAC、ACL、RiskBACと組み合わせて統一された複合セキュリティポリシーを作成できます。
A.3 統合設計の考慮事項
PBACとCBACは補完的な役割を果たし、特にRAGパイプラインとAIエージェントが並行して動作する環境では組み合わせて設計する必要があります。次の設計戦略は、統一されたポリシー強制を実現する方法を示しています。
| 統合焦点 | 設計戦略 |
|---|---|
| 目的+コンテキスト統合 | input.purpose == "incident.response" AND input.session.risk_score < 3 |
| リソースメタデータ+実行コンテキスト | doc.confidentiality == "low" AND device.type == "trusted" |
| 実行フロー競合マッピング | ユーザーの目的とドキュメントの使用タグが競合する場合、ドキュメントの注入をブロックする(purpose mismatch)。 |
QueryPie MCP Agent PAMは、オブジェクトベースのポリシー評価構造を通じてこの統合ロジックをサポートし、すべてのポリシー条件が実行時に強制されることを保証します。プロキシレイヤーは、統一された実行パスでルーティング、ポリシー強制、およびロギングを処理します。
A.4 結論
PBACとCBACは単なる概念モデルを超え、AI実行パイプライン内に強制可能なセキュリティロジックを構築するためのコア設計フレームワークとして機能します。宣言型ポリシーモデルからランタイム強制可能なポリシーアーキテクチャに移行するには、これらのモデルを多条件、オブジェクトベースのポリシー構造に統合し、完全なポリシーライフサイクルを追跡できる実行エンジンによってサポートされる必要があります。
QueryPieは、OPAベースのポリシーモデリング、プロキシルーティング、実行分岐と拒否、承認挿入、構造化された監査ログ記録など、ランタイムポリシー強制に必要なすべての重要な要件をサポートするようにアーキテクチャされています。これらの機能は、RAG 2.0アーキテクチャでセキュリティを実装するために必要な構造的な基盤を形成します[27]。
参考文献
[1] Microsoft, “Design a Secure Multitenant RAG Inferencing Solution – Azure Architecture Center,” Microsoft Learn, 2025. [Online]. Available: https://learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/secure-multitenant-rag
[2] Polymer, “Introducing Polymer’s SecureRAG,” Polymer Blog, 2025. [Online]. Available: https://www.polymerhq.io/blog/introducing-polymers-securerag-ai-powered-data-security
[3] Weaviate, “Multi-Tenancy Vector Search with millions of tenants,” Weaviate Blog, 2023. [Online]. Available: https://weaviate.io/blog/multi-tenancy-vector-search
[4] Amazon Web Services, “Multi-tenancy in RAG applications in a single Amazon Bedrock knowledge base,” AWS ML Blog, 2024. [Online]. Available: https://aws.amazon.com/blogs/machine-learning/multi-tenancy-in-rag-applications-in-a-single-amazon-bedrock-knowledge-base-with-metadata-filtering
[5] R. Theja, “Building Multi-Tenancy RAG System with LlamaIndex,” Medium, 2024. [Online]. Available: https://medium.com/llamaindex-blog/building-multi-tenancy-rag-system-with-llamaindex-0d6ab4e0c44b
[6] QueryPie, “Redefining PAM for the MCP Era,” White Paper, 2025. [Online]. Available: https://www.querypie.com/resources/discover/white-paper/15/redefining-pam-for-the-mcp-era
[7] QueryPie, “MCP PAM as the Next Step Beyond Guardrails,” White Paper, 2025. [Online]. Available: https://www.querypie.com/resources/discover/white-paper/16/next-step-mcp-pam
[8] Amazon Web Services, “Multi-tenancy in RAG applications in a single Amazon Bedrock knowledge base,” AWS ML Blog, 2024. [Online]. Available: https://aws.amazon.com/blogs/machine-learning/multi-tenancy-in-rag-applications-in-a-single-amazon-bedrock-knowledge-base-with-metadata-filtering
[9] QueryPie, “Uncovering MCP Security,” White Paper, 2025. [Online]. Available: https://www.querypie.com/resources/discover/white-paper/18/uncovering-mcp-security
[10] QueryPie, “Google Agentspace Gets Things Done—QueryPie MCP PAM Keeps Them Safe,” White Paper, 2025. [Online]. Available: https://www.querypie.com/resources/discover/white-paper/19/google-agentspace-vs-querypie-mcp-pam
[11] Meta Engineering, “Privacy-aware infrastructure and purpose limitation at Meta,” Meta Engineering Blog, Aug. 27, 2024. [Online]. Available: https://engineering.fb.com/2024/08/27/security/privacy-aware-infrastructure-purpose-limitation-meta/
[12] Polymer, “Generative AI Security: Preparing for 2025,” Polymer Blog, 2023. [Online]. Available: https://www.polymerhq.io/blog/generative-ai-security-preparing-for-2025
[13] Microsoft, “Multitenant RAG Security Model,” Azure Architecture Center, 2024. [Online]. Available: https://learn.microsoft.com/en-us/azure/architecture/ai-ml/guide/secure-multitenant-rag
[14] LangChain, “Agent and Workflow Cloning Scenarios,” GitHub Docs, 2024. [Online]. Available: https://github.com/langchain-ai/langchain
[15] Weaviate, “Document Expiry and Vector TTL Policies,” Weaviate Docs, 2023. [Online]. Available: https://weaviate.io/developers/weaviate
[16] Microsoft Graph Team, “Data, Privacy, and Security for Microsoft 365 Copilot,” Microsoft Learn, 2023. [Online]. Available:
https://learn.microsoft.com/en-us/copilot/microsoft-365/microsoft-365-copilot-privacy
[17] Amazon Web Services, “Create a Generative AI Gateway to allow secure and compliant consumption of foundation models,” AWS Machine Learning Blog, 2023. [Online]. Available:
https://aws.amazon.com/blogs/machine-learning/create-a-generative-ai-gateway-to-allow-secure-and-compliant-consumption-of-foundation-models/
[18] AWS, “Implementing a PDP,” AWS Prescriptive Guidance, 2023. [Online]. Available:
https://docs.aws.amazon.com/prescriptive-guidance/latest/saas-multitenant-api-access-authorization/pdp.html
[19] Microsoft, “Build Microsoft Graph Connectors for 365 Copilot,” Microsoft Learn, 2023. [Online]. Available: https://learn.microsoft.com/en-us/microsoft-365-copilot/extensibility/overview-graph-connector
[20] Amazon Web Services, “Metadata-based document filtering in OpenSearch,” AWS Docs, 2024. [Online]. Available: https://docs.aws.amazon.com/opensearch-service/latest/developerguide/document-level-security.html
[21] Kong Inc., “How to Manage Your API Policies with OPA (Open Policy Agent),” Kong Blog, 2024. [Online]. Available: https://konghq.com/blog/engineering/how-to-manage-your-api-policies-with-opa-open-policy-agent
[22] Open Policy Agent, “OPA Philosophy – Offload Policy Decisions,” OPA Docs, 2023. [Online]. Available: https://www.openpolicyagent.org/docs/latest/philosophy/
[23] NIST, “Zero Trust Architecture,” Special Publication 800-207, 2020. [Online]. Available: https://doi.org/10.6028/NIST.SP.800-207
[24] Microsoft, “Tutorial: Build a RAG app with the Copilot SDK,” Microsoft Learn, 2024. [Online]. Available: https://learn.microsoft.com/en-us/azure/ai-foundry/tutorials/copilot-sdk-build-rag
[25] Cloudflare, “Take Control of Public AI Application Security with Firewall for AI,” Cloudflare Blog, 2023. [Online]. Available: https://blog.cloudflare.com/take-control-of-public-ai-application-security-with-cloudflare-firewall-for-ai/
[26] PwC, “Unlocking value with AI agents: A responsible approach,” PwC Tech Effect, 2023. [Online]. Available: https://www.pwc.com/us/en/tech-effect/ai-analytics/responsible-ai-agents.html
[27] Open Policy Agent, “OPA: Policy Engine for Cloud Native Environments,” CNCF, 2021. [Online]. Available: https://www.openpolicyagent.org
[28] Business Insider, “Samsung bans employees from using AI tools like ChatGPT after an accidental data leak,” Business Insider, May 2023. [Online]. Available: https://www.businessinsider.com/samsung-chatgpt-bard-data-leak-bans-employee-use-report-2023-5
[29] H.F. Atlam et al., “Risk-Based Access Control Model: A Systematic Literature Review,” Future Internet, vol. 12, no. 6, p. 103, Jun. 2020. [Online]. Available: https://doi.org/10.3390/fi12060103
[30] Microsoft, “Azure OpenAI content filtering,” Microsoft Learn, 2025. [Online]. Available: https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/content-filter
[31] OWASP, “LLM01: Prompt Injection,” OWASP Top 10 for LLM Applications, 2024. [Online]. Available: https://genai.owasp.org/llmrisk/llm01-prompt-injection/
[32] Open Policy Agent, “OPA Use Cases – Approval Workflow,” OPA Docs, 2023. [Online]. Available: https://www.openpolicyagent.org/docs/latest/policy-reference/#approval-workflow
[33] European Commission, “Proposal for a Regulation on AI (AI Act),” Article 12 – Record Keeping, 2021. [Online]. Available: https://artificialintelligenceact.eu/the-act/
[34] Aserto, “OPA vs. Zanzibar: Relationship-Based Access Control,” Aserto Blog, 2022. [Online]. Available: https://www.aserto.com/blog/opa-zanzibar-soap-rest
[35] NIST, “Guide to Attribute Based Access Control (ABAC),” NIST SP 800-162, Jan. 2014. [Online]. Available: https://doi.org/10.6028/NIST.SP.800-162
[36] CNCF, “Love, Hate, and Policy Languages: An Introduction to Decision-Making Engines,” CNCF Blog, May 2024. [Online]. Available: https://www.cncf.io/blog/2024/05/21/love-hate-and-policy-languages-an-introduction-to-decision-making-engines/
[37] NIST, “AI Risk Management Framework 1.0,” NIST, Jan. 2023. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
[38] J. Byun and N. Li, “Purpose based access control for privacy protection in relational database systems,” VLDB J., vol. 17, no. 4, pp. 603–619, 2008. [Online]. Available: https://doi.org/10.1007/s00778-006-0023-0
[39] SSH Communications Security, “What is CARTA (Continuous Adaptive Risk and Trust Assessment)?,” SSH Academy, 2024. [Online]. Available: https://www.ssh.com/academy/iam/carta