はじめに
RNNでの自然言語処理のための Word Embeddings(Embedding Matrix = 埋め込み行列)を、GloVe: Gloval Vectors for Word Representation を使って自作した過程の備忘録。
目的
生成型チャットボットに Word Embeddings が必要であることから作成。一般には、訓練済みのものを利用する Transfer Learning が実際的だと考えられている。
今回は、単語同士の関係を線形空間でベクトル化することによって「類推」を可能にする「埋め込み行列」について、理解を深めるために自作した。
word2vecではなくGloVeを選んだ主な理由として、後者が「教師なし学習」であること、アルゴリズムがシンプルであること、コーパスの統計情報を活かせること、などが挙げられる。
環境
データ前処理
- macOS Catalina 10.15.5
- Python 3.7
- MeCab (日本語形態素解析ツール)
- WikiExtractor
訓練
- Google Colaboratory
参考情報
GloVe論文と解説ページ(Stanford University)
訓練済みパラメータ、辞書データ、使ったPythonモジュール(GitHub)
日本語テキストデータと前処理
日本語テキストデータ
Wikipediaのデータダンプを、日本語テキストデータとして使用。全体の大きさは約13GB。そのままではXMLのタグなどが付いているため、”WikiExtractor”を使って訓練に用いたい部分を抽出。
日本語の分かち書き
形態素解析ツールの MeCab を使い、日本語テキストを意味の単位で分かち書きする。
直面した課題
巨大なデータ量とRAMの限界
まずは試験的な作成を目指し、WikiExtractorでファイル化された100MB分だけを使おうとした。
- 行数: 254,103行
- 語彙数: 218,438語

各行にひと続きの文章が入っている。前処理の済んだ100MBのデータを渡したところ、RAMの限界に達してセッションがクラッシュしてしまった。
Colabで使用可能なRAMは約12GBあり、メモリプレッシャーが急激に増加したのは、単語同士の共起頻度情報を格納した行列を使う箇所だった。使われる箇所は主に次の3箇所。
- 行列作成時
- 共起頻度計算時
- パラメータ訓練時
単純に、語彙数 x 語彙数(218,438x218,438)の配列を使うため、扱うには大きすぎた。
代わりに取った方法
約25万行あるテキストを小分けにして訓練を行った。1つのデータセットの訓練が終わるごとに、パラメータのみを保存し、共起頻度を計算した行列は引き継がずにリセット(初期化)した。これにより、使用できるメモリの範囲内におさめたまま、パラメータの訓練をデータセット全体にわたって実行。
問題点
GloVeの長所は、単語同士の共起頻度という統計情報を学習に活用している点にあるので、それを最大限に活かせていない分、単語の類推タスクの精度が低下していると推測される。
コード
テキストデータ全体から辞書を作成
1回あたりの訓練用のデータは分割するが、パラメータと辞書はデータセット全体で共有する必要があるため、先に生成する。
from collections import Counter
with open('preprocessed.txt') as f:
preprocessed_text = f.readlines()
corpus = []
for line in preprocessed_text:
line_lower = line.lower()
corpus.append(line_lower)
vocab = Counter()
for line in corpus:
tokens = line.strip().split()
vocab.update(tokens)
vocab = {word: (i, freq) for i, (word, freq) in enumerate(vocab.items())}
id2word = dict((i, word) for word, (i, _) in vocab.items())
Counter()は、要素をカウントしながら追加してゆくコンテナデータ型クラス。これで単語の出現回数の情報を含んだ辞書を作成。
そこから、単語に数字を割り当てた(トークン)辞書と、KeyとValueを入れかえた辞書を作成。
訓練データの分割
import math
split_size = math.floor(len(corpus)/25)
start = split_size - 1000
end = split_size * 2
split_corpus = corpus[start:end]
print('\nLength of split_corpus: ', len(split_corpus))
# 11,000行程度
訓練に使うテキストの行数が約25万行あり、クラッシュさせることなく処理できる大きさとして、わかりやすく25分割する。
各データセットごとの訓練時に、区切り目付近の共起頻度情報が本来より少なくなると考えられるので、インデックスの始まりを区切り目から1000行ちいさくして、区切りめ付近のデータにまとまりを作っている。
共起行列の生成と共起頻度の計算
from scipy import sparse
window_size = 10
min_count = None
vocab_size = len(vocab)
cooccurrences = sparse.lil_matrix((vocab_size, vocab_size), dtype=np.float64)
for i, line in enumerate(split_corpus):
if i % 1000 == 0:
logger.info('Building cooccurrence matrix: on line %i', i)
tokens = line.strip().split()
token_ids = [vocab[word][0] for word in tokens]
for center_i, center_id in enumerate(token_ids):
context_ids = token_ids[max(0, center_i - window_size):center_i]
contexts_len = len(context_ids)
for left_i, left_id in enumerate(context_ids):
distance = contexts_len - left_i
increment = 1.0 / float(distance)
cooccurrences[center_id, left_id] += increment
cooccurrences[left_id, center_id] += increment
for i, (row, data) in enumerate(zip(cooccurrences.row, cooccurrences.data)):
if i % 50000 == 0:
logger.info('yield cooccurrence matrix: on line %i', i)
if min_count is not None and vocab[id2word[i]][1] < min_count:
continue
for data_idx, j in enumerate(row):
if min_count is not None and vocab[id2word[j]][1] < min_count:
continue
yield i, j, data[data_idx]
# 戻り値は、functools.wraps を使ってデコレートし、リストにして返す。
メモリを節約するため、非ゼロ要素の値のみを保持する仕組みをもつscipyのsparse.lil_matrixで共起行列(cooccurrences)を作成する。Numpyで行列を作成しようとすると、それだけでメモリが圧迫されてクラッシュが起こる。
また、sparse.lil_matrix()であっても、3万行分のテキストデータに差し掛かったあたりで非ゼロ要素が多くなり、メモリ圧迫の結果クラッシュした。
パラメータの訓練
Gloveの計算式の一部 : f(x_ij)((theta_i^t e_j) + b_i + b_j - log(X_ij))
(詳細は論文を参照)
iとjはvocabularyの要素数に対応しており、パラメータのうちウェイトとバイアスそれぞれがシンメトリーな関係にある。また、theta_iとe_jの演算はドット積(内積)でおこなう。
import numpy as np
import h5py
from random import shuffle
# パラメータの初期化。
# 最初だけ行い、あとはHDF5形式に保存しながらリレーする。
# W = (np.random.rand(vocab_size * 2) - 0.5) / float(vector_size + 1)
# biases = (np.random.rand(vocab_size * 2) - 0.5 / float(vector_size + 1)
# gradient_squared = np.ones((vocab_size * 2, vector_size), dtype=np.float64)
# gradient_squared_biases = np.ones(vocab_size * 2, dtype=np.float64)
with h5py.File('glove_weight_relay.h5', 'r') as f:
W = f['glove']['weights'][...]
biases = f['glove']['biases'][...]
gradient_squared = f['glove']['gradient_squared'][...]
gradient_squared_biases = f['glove']['gradient_squared_biases'][...]
# 計算した共起行列の情報とパラメータを、タプルでまとめる。
data = [(W[i_target],
W[i_context + vocab_size],
biases[i_target : i_target + 1],
biases[i_context + vocab_size : i_context + vocab_size + 1],
gradient_squared[i_target],
gradient_squared[i_context + vocab_size],
gradient_squared_biases[i_target : i_target + 1],
gradient_squared_biases[i_context + vocab_size : i_context + vocab_size + 1],
cooccurrence)
for i_target, i_context, cooccurrence in cooccurrences]
iterations = 7
learning_rate = 0.05
x_max = 100
alpha = 0.75
for i in range(iterations):
shuffle(data)
for (v_target, v_context, b_target, b_context, gradsq_W_target, gradsq_W_context, gradsq_b_target, gradsq_b_context, cooccurrence) in data:
# f(X_ij)の部分
weight = (cooccurrence / x_max) ** alpha if cooccurrence < x_max else 1
# ウェイトの内積、バイアス加算、logによる減算の部分
cost_inner = (v_target.dot(v_context) + b_target[0] + b_context[0] - log(cooccurrence))
cost = weight * (cost_innner ** 2)
#1iterationあたりのコストを把握する際に使うコード
#global_cost += 0.5 * cost_inner
# 偏微分の計算
grad_target = weight * cost_inner * v_context
grad_context = weight * cost_inner * v_target
grad_bias_target = weight * cost_inner
grad_bias_context = weight * cost_inner
# 勾配のアップデート=学習過程
v_target -= (learning_rate * grad_target / np.sqrt(gradsq_W_target))
v_context -= (learning_rate * grad_context / np.sqrt(gradsq_W_context))
b_target -= (learning_rate * grad_bias_target / np.sqrt(gradsq_b_target))
b_context -= (learning_rate * grad_bias_context / np.sqrt(gradsq_b_context))
# 次のアップデート時の除算に使う値を計算
gradsq_W_target += np.square(grad_target)
gradsq_W_context += np.square(grad_context)
gradsq_b_target += grad_bias_target ** 2
gradsq_b_context += grad_bias_context ** 2
# パラメータの保存
with h5py.File('glove_weight_relay.h5', 'a') as f:
f['glove']['weights'][...] = W
f['glove']['biases'][...] = biases
f['glove']['gradient_squared'][...] = gradient_squared
f['glove']['gradient_squared_biases'][...] = gradient_squared_biases
ウェイトやバイアスなどのパラメータは訓練全体を通して同じものなので、初期化を最初の1回だけ行う。あとは保存と読み出しを繰り返す。
訓練の繰り返し回数を7に設定。より多く繰り返したほうがパラメータはよりよくなるが、1回あたりに長い時間を要すること、試験的に作成していることを考慮して少なくした。
勾配のアップデートのおいて、二乗したものの平方根によって除算しているのは、GloVeで使われている学習プロセス”Adaptive gradient descent”によるもの。確率的勾配降下法と似た方法。
訓練結果の確認
# シンメトリーなパラメータを合計して平均を計算する。
vocab_size = int(len(W) / 2)
for i, row in enumerate(W[:vocab_size]):
merged = merge_fun(row, W[i + vocab_size])
if normalize:
merged /= np.linalg.norm(merged)
W[i, :] = merged
merge_W = W[:vocab_size]
# 類似したベクトルをもつ単語の上位15個を探す。
word = '言葉'
n = 15
word_id = vocab[word][0]
dists = np.dot(merge_W, W[word_id])
top_ids = np.argsort(dists)[::-1][:n + 1]
similar = [id2word[id] for id in to_ids if id!= word_id][:n]
numpy.argsort()は、昇順でソートしたあとインデックスを返す。降順にするには、[::-1]でインデックスを参照する。

「言葉」に近いベクトルをもつ15個の単語。意味論と統語論の面で似た使われ方をすると考えられる単語がリストアップされた。
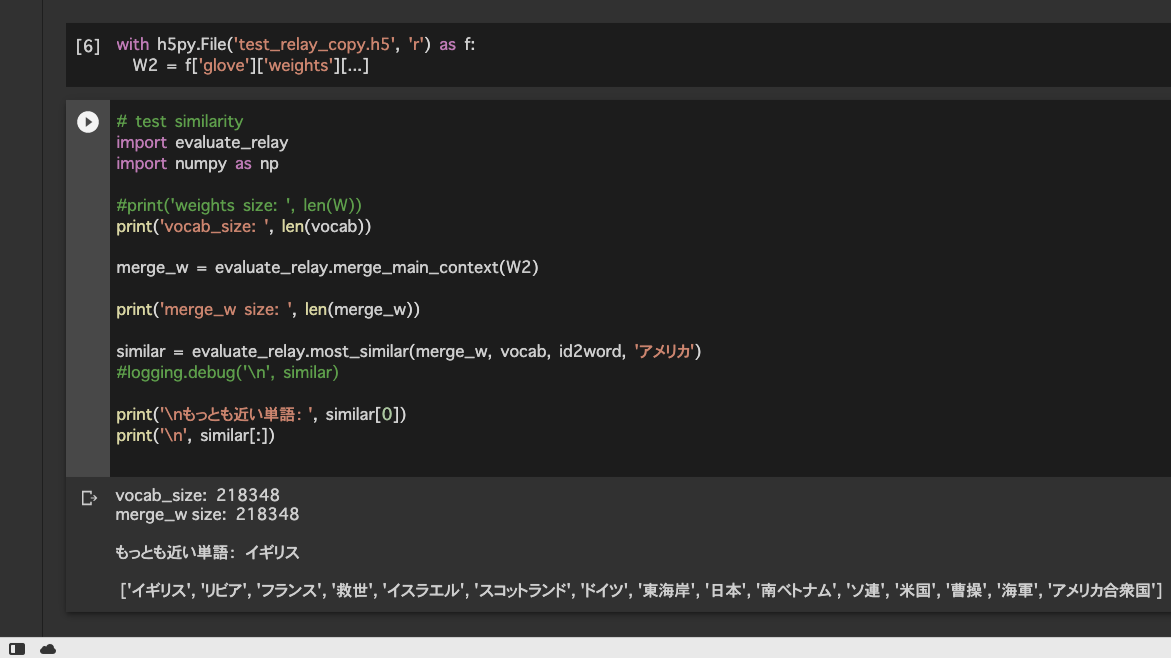
「アメリカ」と似たベクトルをもつ単語を探すと、国名を中心にリストアップされた。
単語ベクトルの視覚化
Embedding projector を利用して、訓練したパラメータを PCA:Principle Component Analysis(主成分分析)によって3次元の近似値でプロットしたもの。メタデータとして単語データを渡したが、上手く機能しなかったのでインデックスによる検索のみ。