完全にローカルで動く生成AIアプリ「LM Studio」を使っている
今までよく使ってきた「openai/gpt-oss-20b」と、最近話題の「qwen/qwen3.5-35b-a3b」を自分の環境でより早く使えるように、パラメータを調整してみた。
結果、Qwen3.5-35b-a3bで291%の速度向上(28.85トークン/秒)が実現できた。
※「補足2」に追記しましたが、同じ手法でQwen3.6-35b-a3bもトークン速度の向上ができました。
やりたいこと
生成AIを読み込むときに「モデル読み込みパラメータを手動で選択」を選ぶと詳細設定ができる
(モデルの一覧からも設定可能です)
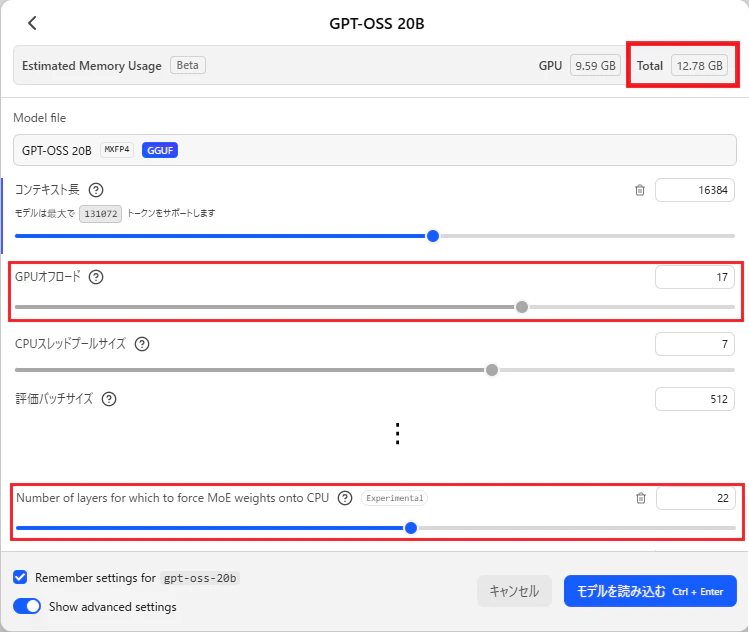
設定を調整したのは以下の2項目
【GPUオフロード】
GPUを使用するモデルレイヤー数
【Number of layers for which to force MoE weight onto CPU】
CPUに強制的に割り当てるレイヤー数。モデル全体がVRAMに入る場合は「0」推奨
以降は「CPUに載せるレイヤ数」と呼んでいる。
この2つは似た設定だが意味が違う様子なので、この2つの値を調整して最速のトークン速度になる値を探してみた
検証環境
私の検証環境は以下。2019年発売のGPUだが頑張ってくれている
CPU:Core i5 14500
メモリ:64GB
GPU:NVIDIA GeForce RTX 2060(VRAM 12.0GB)
私の結論
【使用する生成AIがGPUのVRAMにほぼ乗る場合】
・「GPUオフロード」:GPUにギリギリ乗る値の前後でベストを探す
・「CPUに載せるレイヤ数」:0にする
【使用する生成AIがGPUに明らかに乗らない場合】
・「GPUオフロード」:最大にする
・「CPUに載せるレイヤ数」:レイヤ数を最大からさげて、ベストを探す
openai/gpt-oss-20b 158%向上
LM Studio上で見ると「12.78GB」が必要。私の環境ではVRAMが「12GB」なのでギリギリ乗らない
測定結果は以下(ハイフンは未測定)
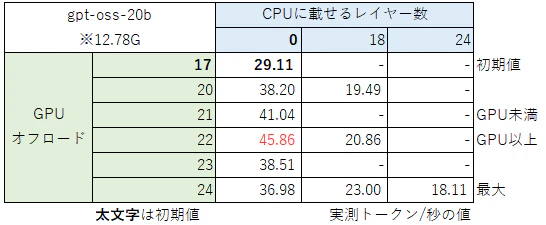
初期値のGPUオフロード「17」、CPUに載せるレイヤ数が「0」で「29.11トークン/秒」
↓
GPUオフロード「22」、CPUに載せるレイヤ数が「0」で「45.86トークン/秒」に向上した
パーセントで言えば158%の向上になった
実測からの推測
GPUオフロードをVRAMにギリギリ収まる「21」にするより、ギリギリ収まらない「22」にしたほうがなぜか早かった
GPUに乗らなかったレイヤーがCPUで実行されるはずなので、メモリ圧縮などで表示と実際に使われるメモリ量が違うのかもしれない
このケースは以下のように最適値を探すと良さそう
1.「CPUに載せるレイヤ数」は0にする
2.生成AIのロード画面で「GPUオフロード」を変更するとGPUの表示値が変わるので、環境のVRAMに近い値を中心として前後で最速になる値を探す
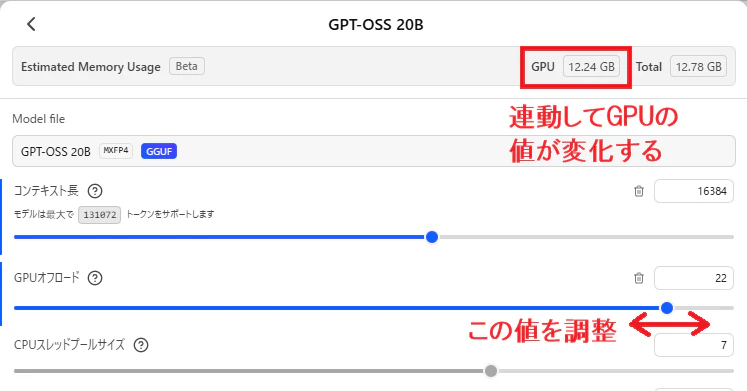
qwen/qwen3.5-35b-a3b 291%向上
LM Studio上で見ると「22.67GB」が必要。私の環境ではVRAMが「12GB」なので、明らかにVRAMに乗らない
測定結果は以下

初期値のGPUオフロード「16」、CPUに載せるレイヤ数が「0」で「9.93トークン/秒」
↓
GPUオフロード「40」(MAX)、CPUに載せるレイヤ数が「22」で「28.85トークン/秒」に向上
パーセントで言えば291%の向上になった
実測からの推測
最初は12GB付近になるようにGPUオフロードを下げてみたが、12トークン/秒程度にしかならなかった(元々が9.93だったので向上はしているけど)
GPUオフロードを最大にして、CPUに強制するレイヤ数をちょっとずつ変えていくことで最適値を探した
面白いのがCPUレイヤー数を「20」にしたときと「21」にしたときで、急激に速度が変わるところ
この値を境界としてGPUに乗りきらなくなった処理が出て、CPUとGPUの間の往復が頻発するようになったものと思われる
このケースは以下のように最適値を探すと良さそう
1.「GPUオフロード」は最大にする
2.生成AIのロード画面で「Number of …… weights onto CPU」の値を大きい値から始めて調整しつつベストを探す
補足:コンテキスト長の変更
LMStudio(Qwen3.5-35b-a3b) + Cline + VSCode をするにはコンテキスト長が必要な様子だったので、コンテキスト長を「128000」に増やしました
結果、容量がさらに増えたので上述の手順で値を確認して、以下で安定しました。
コンテキスト長:128000
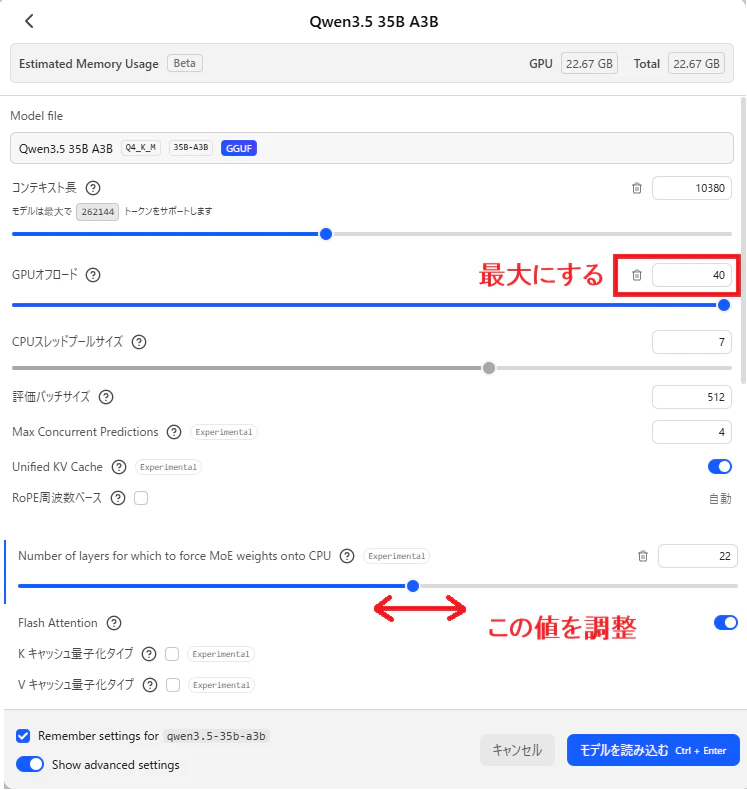
GPUオフロード:40(最大)
Number of …(CPUに載せるレイヤ数):27
設定後の速度:27.26トークン/秒
ポイントは、CPUに載せるレイヤ数を下げていくと、どこかでトークン速度がガクっと急に落ちる。そのレイヤ数+1か2くらいが最速になる。
レイヤー「30」で試す → 速度OK。すこし数を減らそう
レイヤー「25」で試す → 遅い。減らしすぎたので値を増やそう
レイヤー「27」で試す → 速度OK。もうちょっと減らせるかな?
レイヤー「26」で試す → 遅い。さっきの「27」が速度OKの最小値っぽい
という具合にCPUに載せるレイヤ数をどれだけ下げられるかを試していくと、最適値が見つかります。
補足2:Qwen3.6で検証
Qwen3.6(unsloth/qwen3.6-35b-a3b)でも同じように調整した
私の環境では「CPUに載せるレイヤ数」を小さくすると、モデルのロードに失敗した
上述の方法でロードが成功する範囲を探して最速トークンになる値を探した
最終的には以下で安定動作した
コンテキスト長:128000
GPUオフロード:40(最大)
Number of …(CPUに載せるレイヤ数):30
設定後の速度:30.89トークン/秒