外部と通信せずに使えるローカル生成AI「LM Studio」を使っている。
会社によってルールは違うが、パソコンの中で見ても良い資料でも、外部(インターネット)に送信が禁止されている資料があるかもしれない。
ローカル生成AIに資料を読ませて、そのデータから回答させる「RAG」をやってみた。
これなら、データを外部に送信しないで生成AIを活用することができる。
(もちろん、こうした行為も禁止している会社ならダメです。あくまで自分個人で責任が取れる範囲でやりましょう)
基本方針(仕様)
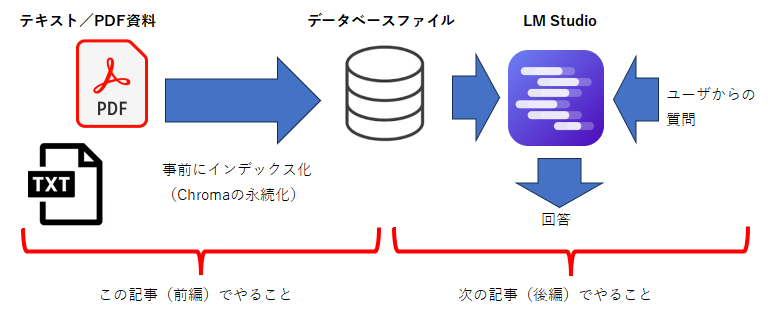
1.読み込める資料はテキストファイルかPDFファイルとする。
2.事前にテキストファイルやPDFを読み込んで、データベースを作っておく(この記事:前編)
3.LM Studioに問い合わせてデータベースから回答させる(次の記事:後編)
2と3を同時に、同じスクリプトですることもできるけど、そうすると読み込ませる資料の量によって起動や処理に時間がかかってしまう。
私の場合は2000個以上のファイルを横断的に読ませたかったので、2と3の処理を分離してみた。
作成したスクリプト
例のごとく、生成AIに協力してもらって(というか、私が生成AIに色々とお願いをして)作ったスクリプトは以下
import os
import sys
import sqlite3
from datetime import datetime
import fitz
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
CHROMA_ROOT = "./chroma"
DB_PATH = "./doc_index.db"
# =====================
# SQLite
# =====================
def init_db():
conn = sqlite3.connect(DB_PATH)
conn.execute("""
CREATE TABLE IF NOT EXISTS doc_index (
file_path TEXT PRIMARY KEY,
file_mtime REAL,
file_size INTEGER,
updated_at TEXT
)
""")
conn.commit()
return conn
def needs_reindex(conn, path):
stat = os.stat(path)
cur = conn.cursor()
cur.execute(
"SELECT file_mtime, file_size FROM doc_index WHERE file_path=?",
(path,)
)
row = cur.fetchone()
return row is None or row != (stat.st_mtime, stat.st_size)
def update_index(conn, path):
stat = os.stat(path)
conn.execute(
"INSERT OR REPLACE INTO doc_index VALUES (?, ?, ?, ?)",
(path, stat.st_mtime, stat.st_size, datetime.now().isoformat())
)
conn.commit()
# =====================
# 読み込み
# =====================
def load_pdf(path):
pdf = fitz.open(path)
name = os.path.basename(path)
docs = []
for i in range(pdf.page_count):
text = pdf.load_page(i).get_text("text").strip()
if text:
docs.append(Document(
page_content="passage: " + text,
metadata={
"source": name,
"path": path,
"page": i + 1
}
))
pdf.close()
return docs
def load_text(path):
name = os.path.basename(path)
with open(path, "r", encoding="utf-8", errors="ignore") as f:
text = f.read().strip()
return [Document(
page_content="passage: " + text,
metadata={
"source": name,
"path": path,
"page": None
}
)]
# =====================
# main
# =====================
def main():
if len(sys.argv) != 3:
print("使い方: python index_documents.py <資料ディレクトリ> <chroma名>")
return
source_dir = sys.argv[1]
chroma_name = sys.argv[2]
persist_dir = os.path.join(CHROMA_ROOT, chroma_name)
os.makedirs(persist_dir, exist_ok=True)
embeddings = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-base",
model_kwargs={"device": "cuda"}
)
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=100
)
conn = init_db()
vs = Chroma(
persist_directory=persist_dir,
embedding_function=embeddings
)
for root, _, files in os.walk(source_dir):
for f in files:
if not f.lower().endswith((".pdf", ".txt")):
continue
path = os.path.join(root, f)
if not needs_reindex(conn, path):
continue
print(f"[INDEX] {path}")
if f.lower().endswith(".pdf"):
docs = load_pdf(path)
else:
docs = load_text(path)
splits = splitter.split_documents(docs)
vs.add_documents(splits)
update_index(conn, path)
print("インデックス完了")
if __name__ == "__main__":
main()
スクリプトの使い方
以下のように呼び出す
python index_documents.py [資料ディレクトリ] [chroma名]
例えば以下のような感じ。
python index_documents.py C:\pdf_dir\ work
引数は以下の2つ。
-
資料ディレクトリ(読み込みたいファイルがあるディレクトリ)
ここで指定されたディレクトリ、および下部のディレクトリにあるテキストファイルかPDFファイルを順に読み込んでデータベース化する -
chroma名(任意の名称)
データベースを複数作れるように、名前を自由に付けられるようにした。
例えば「仕事用」「趣味用」など、名前を付けておくことができる。
(仕事のプロジェクト名とかにすれば便利かも)
スクリプトの実行結果
実行すると以下のものが生成される
-
「doc_index.db」
どのファイルをインデックス化したか「タイムスタンプ」と「ファイルサイズ」を保存しているデータベース。同じファイルを何度もインデックス化しないようにしている。
この「doc_index.db」を消せば、すべてのファイルのインデクスが未作成と判断されて、すべてのインデックスが作り直される。 -
「任意の名称」で指定した名前のフォルダ
このフォルダの中に検索用のデータベースが生成される。
このフォルダの中にできるファイルの名前は「chroma.sqlite3」
もう1つ「21534994-385d-40f7-8c33-46b21a45cf31」のようなIDの名前のフォルダができるが無視して良い
スクリプトの調整
上記のスクリプトは無調整で動くはずだが、環境によっては以下を変えることができる。
CPU利用/GPU利用
107行目:model_kwargs={"device": "cuda"}
ここの「cuda」を「cpu」に変えると、GPUを使わなくなる。
GPUが利用できるか確認する場合は、以下のようなスクリプトを作って実行してみれば良い
TrueとかGPU名が出ればOKだ。
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))
もし上記のスクリプトの結果がFalseで、GPUを使えるようにしたい場合、CUDA未対応のPyTorchをアンインストールしてCUDA対応に入れなおす必要がある。
以下のようにアンインストール、消えたことを確認、CUDA対応のPyTorchのインストール、をする。
pip uninstall torch torchvision torchaudio -y
pip list | findstr torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
chunk_size/chunk_overlap
-
111行目:chunk_size=800
チャンクサイズは小さい方がピンポイント検索に強くなる(FAQや箇条書きなど文章が短い場合)。大きくすると文脈を保持しやすくなる(長文の資料など文章量が多い場合)。
使っている「intfloat/multilingual-e5-base」だと800くらいが良いらしい(と、ChatGPTが教えてくれた) -
112行目:chunk_overlap=100
オーバーラップはその名前の通り、文章をオーバラップさせる範囲。chunk_size の10~20%くらいが良いらしい。
後編、発展編に続きます