外部と通信せずにローカルで生成AIを使える LM Studioを使っている。
これを「llama-cpp-turboquant」に置き換えてみた。
経緯
LM Studioは新しく出た生成AIもどんどん使えるし、細かいパラメータも変えられるし、大満足で使っている。
しかし、困ったことが1つ。
LM StudioとClaude Codeを連携させてプログラムを自動生成していると、パソコンの処理が追い付かないのか、パソコン操作が難しくなる。
具体的に言うと、マウスカーソルを動かしてもカクカクしたり、ボタンをクリックしても反応するまでに数秒かかったりする。
LM Studioが重たい原因を無くそうと、GPUを2枚刺して生成AI用と画面出力用に分けてみたり、「CPUスレッドプールサイズ」の値を下げてみたり、いろいろ試してみたが状況は変わらなかった。
そこで、LM StudioでやっているAPI呼び出しを「llama-cpp-turboquant」でみることにしてみた。
llama-cpp-turboquant とは
ローカルで生成AIをGUIで使うとすると有名なのはOllamaやLMStudioだ(個人的にはLM Studioが気に入っている)
コマンドベースになるが「llama.cpp」も有名。そのフォーク版として作られたのが「llama-cpp-turboquant」だ。
メモリ節約ができるなど評判が良さそうなので使うことにした。
この記事の結論
結果、32トークン/秒で unsloth/Qwen3.6-35B-A3B が動いた。
LM Studioでは課題だったパソコンの処理が重たくなる現象も解消した。
ここまで動かすのに「CMake Error at ggml/CMakeLists.txt:9」とか「sets additional params for the json template parser, must be a valid json object string」とか色々なエラーが出たので、対処した方法を手順と共に以下に解説していきます。
llama-cpp-turboquant の実行ファイルを作る
まず、以下のようにllama-cpp-turboquantを GitHubからダウンロードする
※Gitが必要なので、無ければ入れておく必要があります
https://gitforwindows.org/
git clone https://github.com/TheTom/llama-cpp-turboquant
cd llama-cpp-turboquant
x64 Native Tools Command Prompt for VS 2022でビルドを試みる。
※CUDA Toolkitが必要なのでなければ入れておく必要があります
https://developer.nvidia.com/cuda-downloads
が、ここでハマった。
以下のようなエラーが出た
cmake -B build -DGGML_CUDA=ON
CMAKE_BUILD_TYPE= -- Found Git: C:/Program Files/Git/cmd/git.exe (found version "2.52.0.windows.1")
-- The ASM compiler identification is unknown
-- Didn't find assembler
CMake Error at ggml/CMakeLists.txt:9 (project): No CMAKE_ASM_COMPILER could be found.
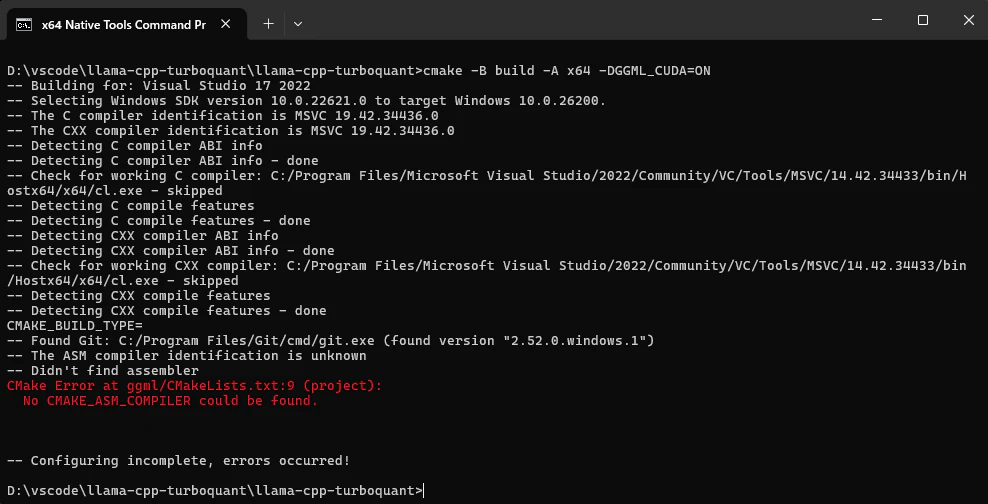
No CMAKE_ASM_COMPILER could be found. というエラーは、その名の通りASMコンパイラが見つからないというもの。
色々試行錯誤したが何故かうまくいかない
しかたないので、ASMを無効にした
ggml\CMakeLists.txt の9行目はもともとこうなっている
project("ggml" C CXX ASM)
このASMを消した
project("ggml" C CXX)
ビルドに失敗している「build」フォルダを消して以下のようにやり直すと、無事にビルドが通り「Build files have been written to:」の行で正常に終わった
cmake -B build -A x64 -DGGML_CUDA=ON

続けて「cmake --build build --config Release」を実行する
かなり時間がかかったが、気長に待つ
cmake --build build --config Release
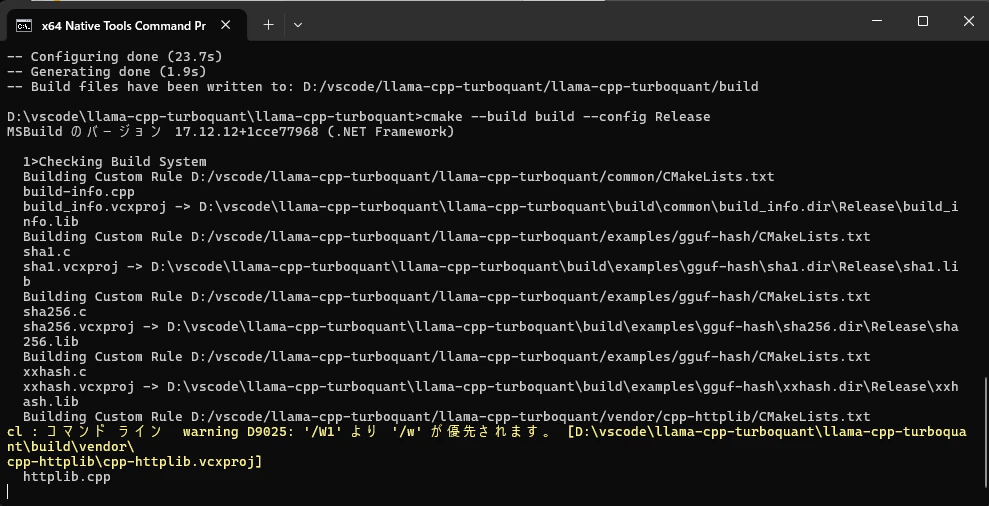
「build\bin\Release\」フォルダに「llama-server.exe」を含む exeやdllがたくさんできていればOKだ。
llama-server.exe を使えば LM Studioと同じようにサーバとして起動させることができる。
llama-cpp-turboquant のコマンド
色々調整して今は以下のコマンドを使っている
llama-server --port 1234 --host 0.0.0.0 --parallel 1 --threads 4 --jinja --n-cpu-moe 24 -ngl 40 --cache-type-k q8_0 --cache-type-v turbo3 -c 128000 --temp 0.6 --top-p 0.9 --repeat-penalty 1.1 -sm none -mg 0 --device CUDA0 --chat-template-kwargs "{\"preserve_thinking\":\"true\"}" -m "C:\Users\【ユーザ名】\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-GGUF\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf"
オプションを説明すると以下。
-
port
待ち受けするポート番号。LM Studioの代わりに使うなら同じポート番号にしても良い。LM Studioと同時に起動するならカブらないポート番号にする -
host
バインドするIPアドレス。同一LAN内の他のパソコンからアクセスさせたかったので「0.0.0.0」にした -
parallel
並列して処理するリクエストの数。私のパソコンは非力なので「1」にして、同時処理できなくした -
threads
CPUのスレッド数。もうちょっと大きな値にしたほうが良さそうだが、今回はパソコンの処理が重たくなることを避けることが主目的なので小さめにした -
jinja
jinjaテンプレートによるプロンプトの整形をする -
n-cpu-moe
これが最大のポイント。MoE(Mixture of Experts)モデルでCPU側で処理するエキスパート数なので、この値は 小さければ小さいほうが良いが、小さすぎるとVRAMにモデルが載らなくなって起動しなくなる
順に値を小さくして行って、llama-cpp-turboquant が起動するギリギリの値を探す。私のVRAM12Gの環境では「23」が最小の起動できる値でした
数時間、Claude Codeで動かしていると「out of memory」というエラーが出る現象が起きました。n-cpu-moeの値がギリギリ過ぎた様子です。しばらく稼働して「out of memory」が出たら、n-cpu-moeの値を +1してみると良さそうです。
-
ngl
GPUにオフロードするレイヤー数。全て載せたければ「99」でも良い -
cache-type-k
Kキャッシュ(attention key)の量子化形式は「q8_0」にした -
cache-type-v
Vキャッシュ(attention value)の保存形式は「turbo3」にした
Kキャッシュと違う非対称にしたほうが品質が良くなる、と llama-cpp-turboquant の製作者が言っていたので。 -
c
コンテキスト長。Claude Codeを使うには 128000くらいほしいかな。 -
temp
プログラミング用途なので大きくないほうが良いかな。0.6にしてみた -
top-p
サンプリングは0.9にしてみた -
repeat-penalty
繰り返し抑制は1.1にしてみた。 -
sm
スケジューリングなしにした -
mg
マルチGPUは無しにした -
device CUDA0
私の環境ではGPUが2枚あるが、1枚は画面表示などに使う用で生成AIには使わない。それで、CUDA0だけを使うように指定した。 -
chat-template-kwargs
生成AIに別途与える指示。preserve_thinkingをtrueにすると会話のたびにゼロから考え直すのではなく、思考過程を維持したまま会話を継続できるというQwen3.6で追加された機能。Windowsではダブルクォーテーションをエスケープして渡す必要がある。
エスケープしていないと以下のように「sets additional params for the json template parser, must be a valid json object string」というエラーが画面に表示された。
--chat-template-kwargs STRING sets additional params for the json template parser, must be a valid json object string, e.g. '{"key1":"value1","key2":"value2"}' (env: LLAMA_CHAT_TEMPLATE_KWARGS)
- m
GGUF形式のモデルファイルを指定する。LM Studioで既にダウンロードしたモデルがあったので、それを指定した。
結果
上述の通りQwen3.6-35B-A3Bが32トークン/秒で動作した
「HTML 1ファイルで動作するブロック崩しを作って」で、私はトークン速度をよく測るができたゲームは以下のようなかんじ。
アクションのアニメーションがあるなど、なかなかよくできている。
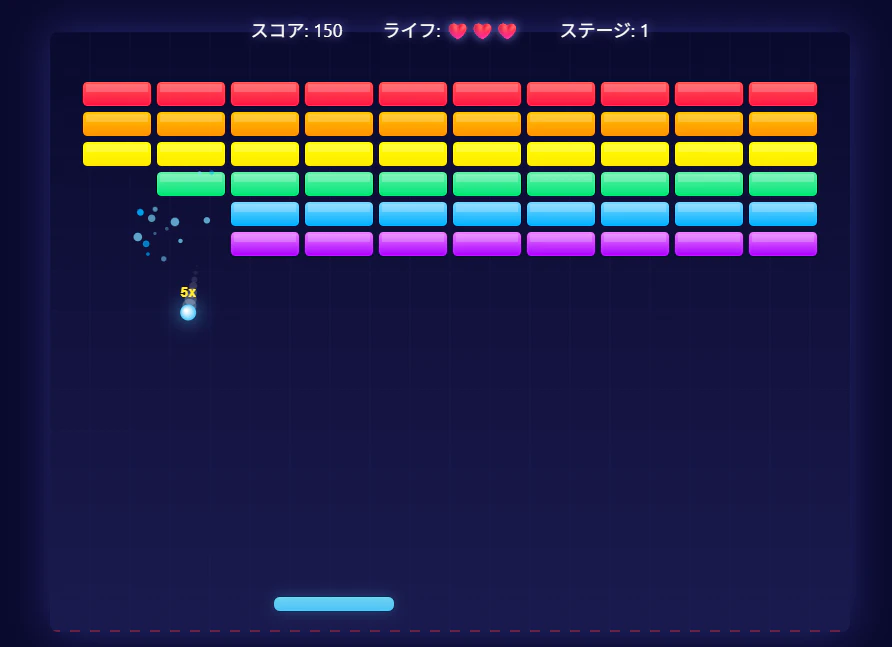
Claude Codeとの連携もスムーズにできた
(LM Studioで起動するか、llama-cpp-turboquantを使って起動するかが違うだけで、Claude Codeの設定は変えていないから当たり前だけど)
