ローカルでLM Studioやllama.cppを使って生成AIを動かしていたら、使っていた RTX2060(VRAM12GB)では非力に思えてきた
それで「RTX2080Ti」(VRAM22GB)を買ってしまった
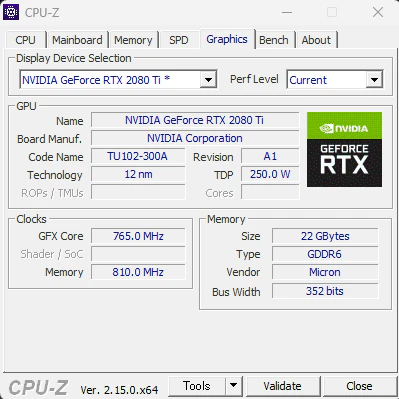
これはちょっと変わったGPUで、RTX2080Ti 11GBをベースにメモリーを22GBを増強した改造版だ
これでQwen3.6 27BのMTPあり/なしの速度を測ってみた
まず結論
私の環境と用途では以下が良さそう
プログラミング優先時(23.79トークン/秒)
- 27B:Q4_K_M
- MTP:オフ
- KVキャッシュ:q4_0
非プログラミング時(36.87トークン/秒)
- 27B:Q4_K_S
- MTP:オン
- KVキャッシュ:q4_0
VRAM使用量の測定方法
以下のように llama-server を起動するときに「-lv 4」を指定して詳細ログを出すと「projected to use 」を含む行でVRAM使用量を見ることができる
llama-server -lv 4 ……
Qwen3.6-27B のトークン速度の測定
以前のGPU(VRAM12GB)では、Qwen3.6-27B は2~4トークン/秒でまともに動かなかった
GPUのVRAMが22GBに増えたので llama.cpp に27Bを載せて実験してみた
ただし条件として「コンテキスト長:128000」、「Vision有効」にしている
これらを減らせばメモリ消費量はもちろん減るが、ツールの利用上ほしいのでこの設定で計測した
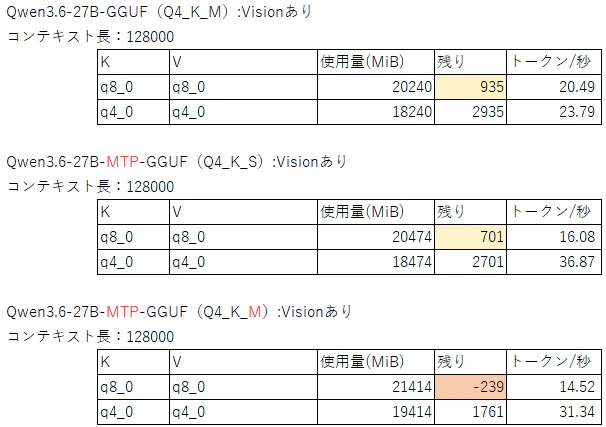
分かったこと1:MTP ON でトークン速度向上。でも……
上記の結果より、MTPを有効にすると早くなることがわかる(アタリマエ!)
しかし、仕組み上、最初からトークン速度が早いかというとそうではない
最初は遅い速度で、生成が進むにしたがってじわじわとトークン速度の表示が上がっていく

一方、MTPをオフにすると最初から上記のトークン速度が出る
また、MTPなし「23.79トークン/秒」とMTPあり「31.34トークン/秒」と、30%程度の速度向上だった
この30%を大きいとみるか小さいとみるか……
おそらく、使っているGPUが古いRTX2080Tiなので、メモリの帯域幅がボトルネックになって思ったより速度が改善しなかったのだろう
分かったこと2:MTP ONでVRAM消費UP
MTPを有効にすると +1.2G程度のVRAMを消費する
(例えば上記の例だと 20240 -> 21414、18240 -> 19414 など)
まぁ、これもあたりまえだけど
分かったこと3:MTP ONで精度が?
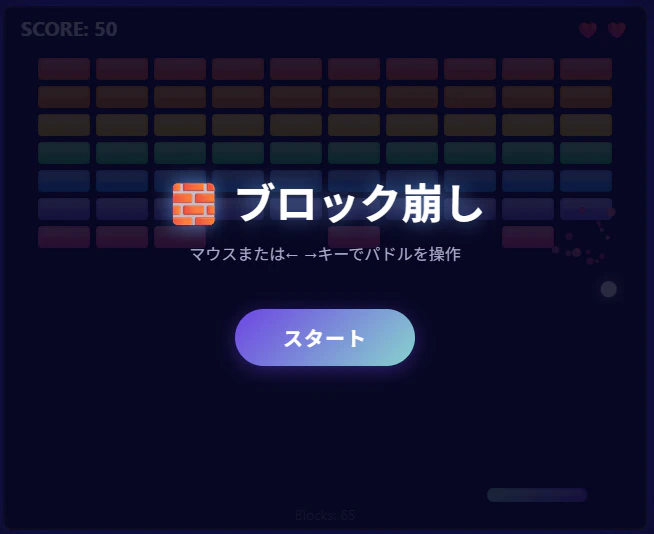
1回しか試験していないので有意とは言い難いが「K Q8、V Q8、MTPあり」の条件で作ったブロック崩しに不具合があった。スタート画面が出た後でゲームを始めると、スタート画面のレイヤーが消えずに残ったままプレイが始まってしまった。
↓オープニング画面が消えずその後ろでゲームをプレイしている
あれ?と思って同じプロンプトを投げると、今度は最初のブロックにボールが当たった段階でフリーズしてしまった。
↓この状態で止まってしまう
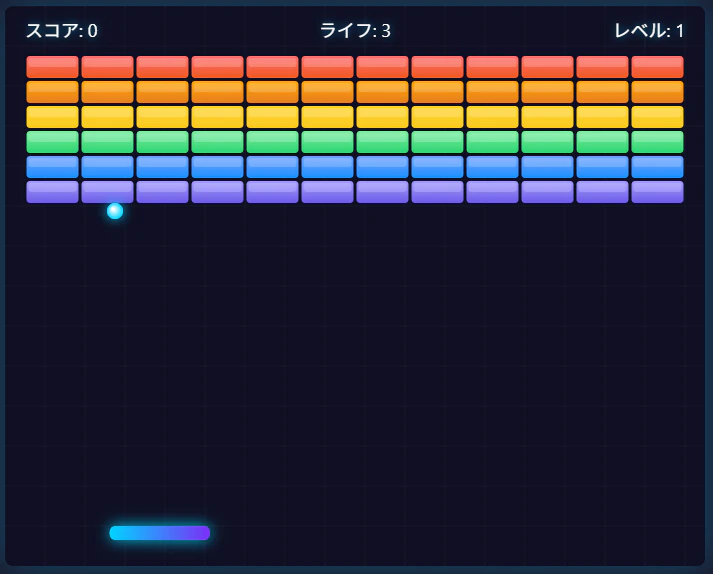
プログラミング用途だと文脈の自然さだけではなく、厳密な順序などの正確さや整合性が必要なのでMTPと相性が悪いかもしれない
結論
私の用途と環境では、MTPしなくてよいかな
30%の速度向上は嬉しいけど、品質の低下の可能性が痛い
これがもっと良いGPUで劇的に速度があがるのであれば、仮に品質が多少 落ちてもツール側の反復処理でデバッグできるはずなので、MTPオンの価値があるかも
私の環境では、KVキャッシュを削ったり、コンテキスト長を変えたりしてGPUに収まるように調整するほうが優先かな、という印象でした。