前の記事でVSCode+CLINEでプログラムを作成した。
以前、Claude Code+LM Studioでは思ったように動作させられなかったのでCLINEにしたことがあったが、Qwen3.5 や Gemma4 などでClaude CodeもローカルAIで実用的に動くと聞いたので入れてみた。
問題は、Claude Codeでどんなモデルを使うのが良さそうかということ。
残念ながら私はQwen3.5 27Bや、Gemma4 31Bが動くような性能のパソコンは持っていない。
それで、私の限られた性能のパソコンで"マシ"なモデルを以下の6つから比較してみた。
※Q4_K_MとかBF16とか、量子化の条件がそろっていないのは私のパソコンで動くサイズにするためにやむなくそうしています
- unsloth/gemma-4-26b-a4b-it ※Q4_K_M
https://huggingface.co/unsloth/gemma-4-26B-A4B-it - noctrex/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-MXFP4_MOE-GGUF ※BF16
https://huggingface.co/noctrex/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-MXFP4_MOE-GGUF - mradermacher/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-i1-GGUF ※Q4_K_M
https://huggingface.co/mradermacher/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-i1-GGUF - unsloth/Qwen3.5-35B-A3B-GGUF ※Q4_K_M
https://huggingface.co/unsloth/Qwen3.5-35B-A3B-GGUF - unsloth/Qwen3.5-9B-GGUF ※Q4_K_XL
https://huggingface.co/unsloth/Qwen3.5-9B-GGUF - lmstudio-community/gpt-oss-20b-GGUF ※MXFP4
https://huggingface.co/lmstudio-community/gpt-oss-20b-GGUF
(追記)後日、Qwen3.6が出たので追加検証しました。「補足」をご覧ください。
- unsloth/Qwen3.6-35B-A3B-GGUF ※Q4_K_S
https://huggingface.co/unsloth/Qwen3.6-35B-A3B-GGUF
検証条件
環境は以下
- Core i5 14500
- メモリ 64GB
- RTX2060 12GB
※VSCode+Claude Codeは、VMWare上に入れた仮想環境上で実行
検証方法
マインスイーパーをHTMLで実装させる
上記のモデルに共通で与えた指示書は以下
与えたプロンプトは以下
あなたは自律型ソフトウェア開発エージェントです。
mdファイルに記載された設計と方針に従い、TDD(テスト駆動開発)でアプリを作成してください。
以下を人間の介入なしに完了してください:
- タスク分割
- 詳細設計
- テスト設計(最初に実施)
- テスト作成(実装前に作成)
- 実装
- テスト実行
- エラー修正
- リファクタリング
- README作成
TDDルール(厳守):
- 必ず「テスト→実装」の順で進めること
- 実装前にテストコードを作成すること
- まず失敗するテスト(Red)を作ること
- 次にテストを通す最小限の実装(Green)を行うこと
- その後リファクタリング(Refactor)を行うこと
- このサイクルを機能単位で繰り返すこと
追加ルール:
- ユーザーに質問せず、自分で仮定して進める
- 必要なファイルはすべて自動作成する
- コマンドは自動で実行する
- テストが失敗した場合は修正して再実行する
- 全テストが成功するまで繰り返す
- 完了するまで止まらない
完了条件:
- 全テストが成功
- コードがリファクタリングされている
- アプリが起動可能
今すぐ開始してください。
上記以上の情報は与えない条件でテストした。
生成AIが「完成した」と報告するか、同じ操作を延々と繰り返してループし始めるまで放置して、出来上がったソースを見て評価する。
ただし、もしツールの使用で失敗するなど止まってしまった場合は「作業を続けてください」など簡単な指示だけして再開させた。
私は、デバッグしたり生成AIにヒントを出さず、生成AIが自力でどこまで頑張れるかで比較した。
検証結果
生成されたプログラムの見た目と、ChatGPTのCodexに比較させた点数とでランキングにしてみた。
詳細な検証結果は以下。

試した中で結果「1位」になったのは以下のモデルだった
※後日、Qwen3.6が出たので順位が変わりました。この記事の「補足」をご覧ください。
noctrex/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-MXFP4_MOE-GGUF
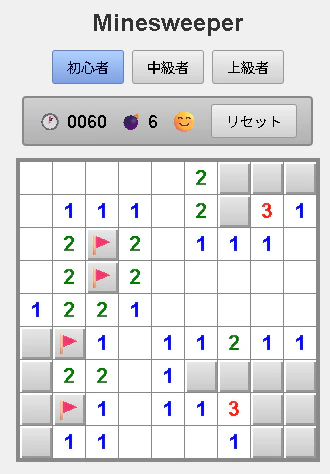
途中でClaude Codeが数回止まってしまったものの、プログラム作成完了まで完走することができた
起動するとこんな感じでちゃんと動く。旗の動きとか怪しい部分が残っているが、ちゃんと実装できている。

Gemma4 はモデルによっては「unused24」という出力を出し続けてしまった。(llama.cppの今後のバージョンアップで直るかな?)
結局、未完成で終わってしまった(同じ操作を何度も繰り返すだけになったので中止した)ので点数が低くなっている。
今までお世話になった「gpt-oss-20b」はプレイ可能なものを作れた。がChatGPTのCodexに「最小実装です」と酷評されてしまった。確かにmdファイルに書いていた仕様を無視している部分が多い。
実は、上述以外のいろいろなモデルも試してみました
qwopus3.5-9b-v3とか、Gemma4の他のシリーズのQ2とか、が、思ったほど性能が出なかったりトークン速度が遅すぎてツール側でタイムアウトしたり、とベストなモデルはなかなか無さそうです
今のところ私の環境では、性能と速度のバランスで上述の1位になったモデルが良さそうです
追記:unsloth/Qwen3.6-35B-A3B-GGUF
Qwen3.6が出たので同一条件で検証した。
結果はQwen3.6の圧倒的勝利でした
途中でClaude Codeが止まることもなくスムーズに完走することができました
詳細は以下

追記2
Qwen3.6に自分が欲しいプログラムを書かせてみました。
Qwen3.6+Claude Code環境です。