1. はじめに
前回に引き続き、データサイエンス100本ノックの解説を行う。
[データサイエンス100本ノック解説(P001~020)] (https://qiita.com/ProgramWataru/items/42ff579a3cdb4f0ad158)
データサイエンス100本ノック解説(P021~040)
導入についてはこちらの記事を参考に進めてください(※ MacでDockerを扱います)
基本的には解答の解説ですが別解についても記述しています。
※徐々に難易度が上がってきています。
2. 解説編
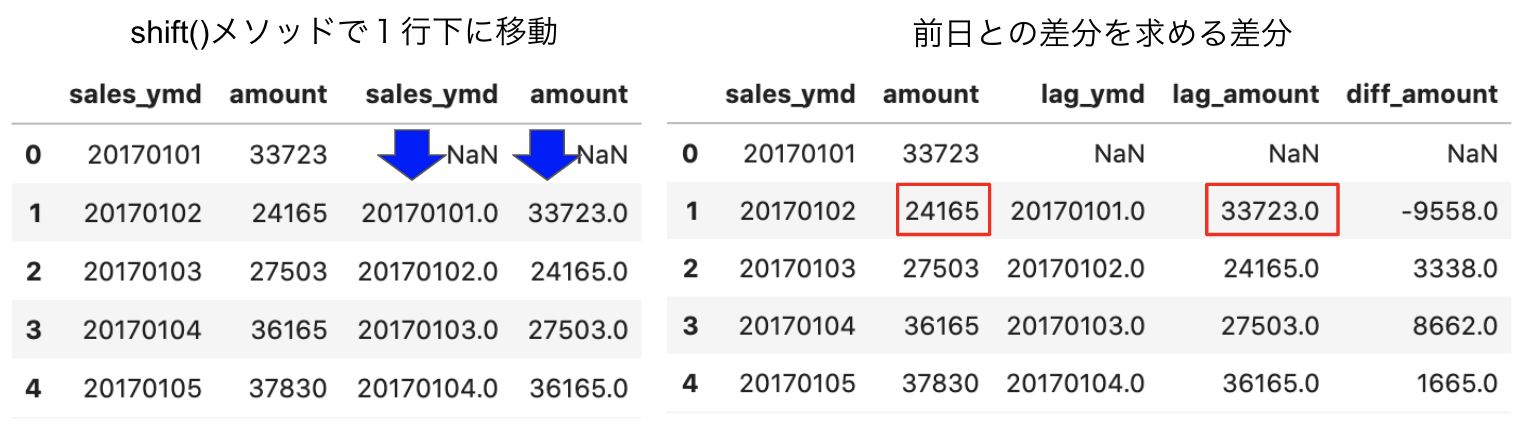
P-041: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前日からの売上金額増減を計算せよ。なお、計算結果は10件表示すればよい。
# 売上金額(amount)を日付(sales_ymd)ごとに集計(groupbyメソッド)
# reset_index()でインデックスを振り直す。
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
# 比較用に売上金額(amount)を日付(sales_ymd)のコピーを下に1行移動したものを結合する。
# concat([df1, df2], axis=1)で横方向に結合。shift()で1行下に移動
df_sales_amount_by_date = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1)
# カラム名を変更する
df_sales_amount_by_date.columns = ['sales_ymd','amount','lag_ymd','lag_amount']
# 売上金額増減(diff_amount)を追加する
df_sales_amount_by_date['diff_amount'] = df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount']
df_sales_amount_by_date.head(10)
参考: pandas.DataFrame, Seriesを連結するconcat
参考: pandasでデータを行・列(縦・横)方向にずらすshift
P-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
# (縦持ちのケース)
# 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby)
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
# for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。
for i in range(1, 4):
# i==1のときは横方向に結合。shiftで1行下に移動(1日前)
if i == 1:
df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1)
# iが1以外の場合、データフレームに追加する。
else:
df_lag = df_lag.append(pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)], axis=1))
# カラム名を変更する
df_lag.columns = ['sales_ymd', 'amount', 'lag_sales_ymd', 'lag_amount']
# 欠損値NaNを除外(dropna())し、ソートする(sort_values)。
df_lag.dropna().sort_values('sales_ymd').head(10)
# 横持ちのケース
# 売上金額(amount)を日付(sales_ymd)ごとに集計(groupby)
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
# for文で繰り返す。range(1, 4)>>>1, 2, 3がiに入る。
for i in range(1, 4):
# iが1の時、横方向に連結したdf_lagを作成する。
if i == 1:
df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(1)], axis=1)
# iが1以外の場合、すでにdf_lagが作成されているのでdf_lagと連結させる。
else:
df_lag = pd.concat([df_lag, df_sales_amount_by_date.shift(i)], axis=1)
# カラム名を変更する
df_lag.columns = ['sales_ymd', 'amount', 'lag1_sales_ymd', 'lag1_amount',
'lag2_sales_ymd', 'lag2_amount', 'lag3_sales_ymd', 'lag3_amount']
# 欠損値NaNを除外(dropna())し、ソートする(sort_values)。
df_lag.dropna().sort_values('sales_ymd').head(10)
参考: pandasで欠損値NaNを除外(削除)・置換(穴埋め)・抽出
P-043: レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合し、性別(gender)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータフレーム(df_sales_summary)を作成せよ。性別は0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。
# レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合
# merge(df1, df2, on='キー名', how='inner')
df_tmp = pd.merge(df_receipt, df_customer, on='customer_id', how='inner')
# 年代を10歳ごとの階級にする。
# math.floor: 小数点以下を切り捨て。ex) 22の場合 22/10 * 10 = 2(2.2の切り捨て) *10 = 20
df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x/10)*10)
# ピボットテーブルを作成(pivot_table()関数)詳細は下記
df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd', values='amount', aggfunc='sum').reset_index()
# カラム名を変更する
df_sales_summary.columns = ['era', 'male', 'female', 'unknown']
df_sales_summary
pivot_table()関数
・data(第一引数): 参照するデータフレーム
・index: 行名を指定
・columns: 列名を指定
・values: 参照しているデータフレームの列名を指定すると、その列に対する結果のみが算出
・aggfunc: 結果の値の算出方法を指定
参考: pandasのピボットテーブルでカテゴリ毎の統計量などを算出
P-044: 前設問で作成した売上サマリデータフレーム(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータフレームから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を'00'、女性を'01'、不明を'99'とする。
# set_indexで既存の列をインデックスindex(行名、行ラベル)に割り当てる
# stack()で列から行へピボット。
# replace()で文字列を置換する
# rename()メソッドで任意の行名・列名を変更する
df_sales_summary.set_index('era').stack().reset_index().replace(
{'female': '01', 'male': '00', 'unknown': '99'}).rename(
columns={'level_1': 'gender_cd', 0: 'amount'})
参考: pandas.DataFrameの列をインデックス(行名)に割り当てるset_index
参考: pandasでstack, unstack, pivotを使ってデータを整形
参考: Pythonで文字列を置換(replace, translate, re.sub, re.subn)
参考: pandas.DataFrameの行名・列名の変更
P-045: 顧客データフレーム(df_customer)の生年月日(birth_day)は日付型(Date)でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
# 顧客ID(customer_id)とYYYYMMDD形式の文字列に変換した生年月日(birth_day)を結合する。
# concat([df1, df2], axis=1)で横方向に結合する。
# pd.to_datetimeで文字列をdatetime64[ns]型に変換する。
# dt.strftime()で列を一括で任意のフォーマットの文字列に変換する。
pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['birth_day']) \
.dt.strftime('%Y/%m/%d')], axis=1).head(10)
参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-046: 顧客データフレーム(df_customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型(dateやdatetime)に変換し、顧客ID(customer_id)とともに抽出せよ。データは10件を抽出すれば良い。
# 顧客ID(customer_id)と日付型(dateやdatetime)に変換した申し込み日(application_date)を結合する
# P-045を参考
pd.concat([df_customer['customer_id'], pd.to_datetime(df_customer['application_date'])], axis=1).head(10)
参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-047: レシート明細データフレーム(df_receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
# 売上日(sales_ymd)をto_datetime()で日付型に変換する
# pandas.concat()で横方向に結合する
# astype()メソッドで文字列str型に変換すると、標準的な書式で文字列に変換する
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10)
# (別解)
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no'],
pd.to_datetime(df_receipt['sales_ymd']).dt.strftime('%Y-%m-%d')]], axis=1).head(10)
参考: pandasで日付・時間の列を処理(文字列変換、年月日抽出など)
P-048: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型(dateやdatetime)に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
# pd.concat()を用いての売上エポック秒(sales_epoch)のデータフレームとレシート番号(receipt_no)、レシートサブ番号(receipt_sub_noを結合
# 売上エポック秒(sales_epoch)を日付型に変換する(to_datetime(df, unit='s')で変換)
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'].astype(int), unit='s')], axis=1).head(10)
参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-049: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"年"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。データは10件を抽出すれば良い。
# 売上エポック秒(sales_epoch)を日付型(timestamp型)に変換
# "年"だけ取り出す(dt.year)
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s').dt.year], axis=1).head(10)
参考: Pandasで時間や日付データに変換するto_datetime関数の使い方
P-050: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"月"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"月"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s'))
# "月"だけ取り出す(0埋め2桁で取り出すためstrftime('%m'))
# pd.concatでデータフレームを結合する
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s') \
.dt.strftime('%m')], axis=1).head(10)
P-051: レシート明細データフレーム(df_receipt)の売上エポック秒(sales_epoch)を日付型(timestamp型)に変換し、"日"だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに抽出せよ。なお、"日"は0埋め2桁で取り出すこと。データは10件を抽出すれば良い。
# 売上エポック秒(sales_epoch)を日付型に変換(to_datetime(, unit='s'))
# 日だけを抜き出す(dt.strftime('%d'))
# pd.concat()で結合
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'], unit='s') \
.dt.strftime('%d')], axis=1).head(10)
P-052: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2000円以下を0、2000円超を1に2値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
# lambdaを使った場合
# 顧客IDが"Z"から始まるのものを除外する(queryで探し、notで以外、str.startswith('Z'))
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python')
# 顧客ID(customer_id)ごとにグループ分けする。売上金額(amount)を合計(sum)
df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
# 2000円以下を0、2000円超を1に2値化(apply(lambda)で指定の列に1行ずつ条件を適用する)
df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x>2000 else 0)
df_sales_amount.head(10)
# (別解: np.where)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python')
df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
# np.where(条件式, x(真の場合), y(偽の場合))
df_sales_amount['sales_flg'] = np.where(df_sales_amount['amount']>2000, 1, 0)
df_sales_amount.head(10)
# (別解)
df_sales_amount = df_receipt[~df_receipt['customer_id'].str.startswith('Z')].groupby('customer_id').amount.sum().reset_index()
df_sales_amount.loc[df_sales_amount['amount']<=2000, 'threshold'] = 0
df_sales_amount.loc[df_sales_amount['amount']>2000, 'threshold'] = 1
df_sales_amount.head(10)
参考:pandasで指定の列に1行ずつ関数を適用するapply+lambdaの使い方
P-053: 顧客データフレーム(df_customer)の郵便番号(postal_cd)に対し、東京(先頭3桁が100〜209のもの)を1、それ以外のものを0に2値化せよ。さらにレシート明細データフレーム(df_receipt)と結合し、全期間において買い物実績のある顧客数を、作成した2値ごとにカウントせよ。
# 郵便番号(postal_cd)を2値化する(東京:1, その他:0)
df_tmp = df_customer[['customer_id', 'postal_cd']].copy()
df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <=209 else 0)
# レシート明細データフレーム(df_receipt)と結合(pd.merge(df1, df2, on='キー', how='inner'))
# ユニークな要素の個数(重複のない個数)をcustomer_idごとに算出(pandas.DataFrame.nunique())
pd.merge(df_tmp, df_receipt, on='customer_id', how='inner') \
.groupby('postal_flg').agg({'customer_id': 'nunique'})
# (別解) np.whereの使い方はP-052を参考
df_tmp = df_customer[['customer_id', 'postal_cd']].copy()
df_tmp['postal_flg'] = np.where(df_tmp['postal_cd'].str[0:3].astype(int)
.between(100, 209), 1, 0)
pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \
groupby('postal_flg').agg({'customer_id':'nunique'})
P-054: 顧客データデータフレーム(df_customer)の住所(address)は、埼玉県、千葉県、東京都、神奈川県のいずれかとなっている。都道府県毎にコード値を作成し、顧客ID、住所とともに抽出せよ。値は埼玉県を11、千葉県を12、東京都を13、神奈川県を14とすること。結果は10件表示させれば良い。
# 住所(address)の都道府県部分を抽出し、それぞれ値をつける
# map()の引数に辞書dict({key: value})を指定すると、keyと一致する要素がvalueに置き換えられる。
pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3] \
.map({'埼玉県': '11', '千葉県': '12', '東京都': '13', '神奈川': '14'})], axis=1).head(10)
参考: pandas.Seriesのmapメソッドで列の要素を置換
P-055: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、その合計金額の四分位点を求めよ。その上で、顧客ごとの売上金額合計に対して以下の基準でカテゴリ値を作成し、顧客ID、売上金額と合計ともに表示せよ。カテゴリ値は上から順に1〜4とする。結果は10件表示させれば良い。
# 顧客ID(customer_id)ごとにグループ分け(groupby)し、売上金額(amount)を合計する(sum)
df_sales_amount = df_receipt[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
# 売上金額(amount)ごとに四分位点を求める。(25パーセンタイル: 25pct, 50パーセンタイル: 50pct, 75パーセンタイル: 75pct)
pct25 = np.quantile(df_sales_amount['amount'], 0.25)
pct50 = np.quantile(df_sales_amount['amount'], 0.5)
pct75 = np.quantile(df_sales_amount['amount'], 0.75)
# カテゴリ値の関数を作成し、適用する
def pct_group(x):
if x < pct25:
return 1
elif pct25 <= x < pct50:
return 2
elif pct50 <= x < pct75:
return 3
elif pct75 <= x:
return 4
# applyを用いてpct_groupを各行に適用する
df_sales_amount['pct_group'] = df_sales_amount['amount'].apply(lambda x: pct_group(x))
df_sales_amount
参考: pandasのcut, qcut関数でビニング処理(ビン分割)
P-056: 顧客データフレーム(df_customer)の年齢(age)をもとに10歳刻みで年代を算出し、顧客ID(customer_id)、生年月日(birth_day)とともに抽出せよ。ただし、60歳以上は全て60歳代とすること。年代を表すカテゴリ名は任意とする。先頭10件を表示させればよい。
# 年齢(age)を10歳刻みで年代を算出
# math.floorで切り捨て。min(, 60)で60以上が出力されない。
df_customer_era = pd.concat([df_customer[['customer_id', 'birth_day']],
df_customer['age'].apply(lambda x: math.floor(x / 10) * 10, 60)], axis=1)
df_customer_era.head(10)
# (別解)
# 年齢(age)を(10代未満、10代、20代、30代、40代、50代、60代以上)で分ける。(flg_age)
def age_group(x):
if x < 10:
return '10代未満'
elif 10 <= x <20:
return '10代'
elif 20 <= x < 30:
return '20代'
elif 30 <= x < 40:
return '30代'
elif 40 <= x < 50:
return '40代'
elif 50 <= x < 60:
return '50代'
elif 60 <= x:
return '60代以上'
df_customer['flg_age'] = df_customer['age'].apply(lambda x: age_group(int(x)))
# 顧客ID(customer_id)、生年月日(birth_day)とともに抽出
df_customer[['customer_id', 'birth_day', 'flg_age']].head(10)
P-057: 前問題の抽出結果と性別(gender)を組み合わせ、新たに性別×年代の組み合わせを表すカテゴリデータを作成せよ。組み合わせを表すカテゴリの値は任意とする。先頭10件を表示させればよい。
# カテゴリーデータ(性別x年代)'gender_era'を作成する
# ageはint型なのでastype(str)で変換する
df_customer_era['gender_era'] = df_customer['gender_cd'] + df_customer_era['age'].astype(str)
df_customer_era.head(10)
P-058: 顧客データフレーム(df_customer)の性別コード(gender_cd)をダミー変数化し、顧客ID(customer_id)とともに抽出せよ。結果は10件表示させれば良い。
# 性別コード(gender_cd)をダミー変数化する(get_dummies)
# 引数columnsにダミー化したい列の列名をリストで指定
pd.get_dummies(df_customer[['customer_id', 'gender_cd']], columns=['gender_cd'])
参考: pandasでカテゴリ変数をダミー変数に変換(get_dummies)
P-059: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を平均0、標準偏差1に標準化して顧客ID、売上金額合計とともに表示せよ。標準化に使用する標準偏差は、不偏標準偏差と標本標準偏差のどちらでも良いものとする。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
# 顧客IDが"Z"から始まるのものを除外し、顧客ID(customer_id)ごとに売上金額(amount)を合計する
df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \
.groupby('customer_id').agg({'amount': 'sum'}).reset_index()
# 売り上げ金額を標準化する
df_sales_amount['amount_ss'] = preprocessing.scale(df_sales_amount['amount'])
df_sales_amount.head(10)
# (別解)
# コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
scaler = preprocessing.StandardScaler()
scaler.fit(df_sales_amount[['amount']])
df_sales_amount['amount_ss'] = scaler.transform(df_sales_amount[['amount']])
df_sales_amount.head(10)
参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
P-060: レシート明細データフレーム(df_receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計し、合計した売上金額を最小値0、最大値1に正規化して顧客ID、売上金額合計とともに表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。結果は10件表示させれば良い。
# 売上金額(amount)を顧客ID(customer_id)ごとに合計
df_sales_amount = df_receipt.query("not customer_id.str.startswith('Z')", engine='python') \
.groupby('customer_id').agg({'amount': 'sum'}).reset_index()
df_sales_amount
# 売上金額を最小値0、最大値1に正規化(preprocessing.minmax_scale)
df_sales_amount['amount_mm'] = preprocessing.minmax_scale(df_sales_amount['amount'])
df_sales_amount.head(10)
# (別解)
# コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
scaler = preprocessing.MinMaxScaler()
scaler.fit(df_sales_amount[['amount']])
df_sales_amount['amount_mm'] = scaler.transform(df_sales_amount[['amount']])
df_sales_amount.head(10)
参考: Pythonで正規化・標準化(リスト、NumPy配列、pandas.DataFrame)
3. 参考文献
データサイエンス100本ノック
Macでデータサイエンス100本ノックを動かす方法
4. 所感
40以降難易度が上がった。写経でもいいので何が書かれているか言語化する。