はじめに
AIを組み込んだシステムやサービスを安定的に運用し、ビジネス価値を継続的に提供するためには、従来のシステム監視(リソース監視など)だけではなく、GenAIOpsの確立が不可欠である。
本記事ではGenAIOpsを、モデルごとのトークンコスト、数値化しにくいセマンティックな評価(人間から見て意味的に適切な評価をしているか等)、AI特有の指標を継続的にモニタリングし推論精度やコスト効率を改善し続けるサイクルと定義し、AWS Bedrock環境のモニタリングの仕組みを実装する。
以下の主要な観点をAWSのマネージドサービスでモニタリングできるようにする。
- AIが生成した回答の品質、またはブロックされた回答の数
- Bedrockの各モデルが消費するトークン数
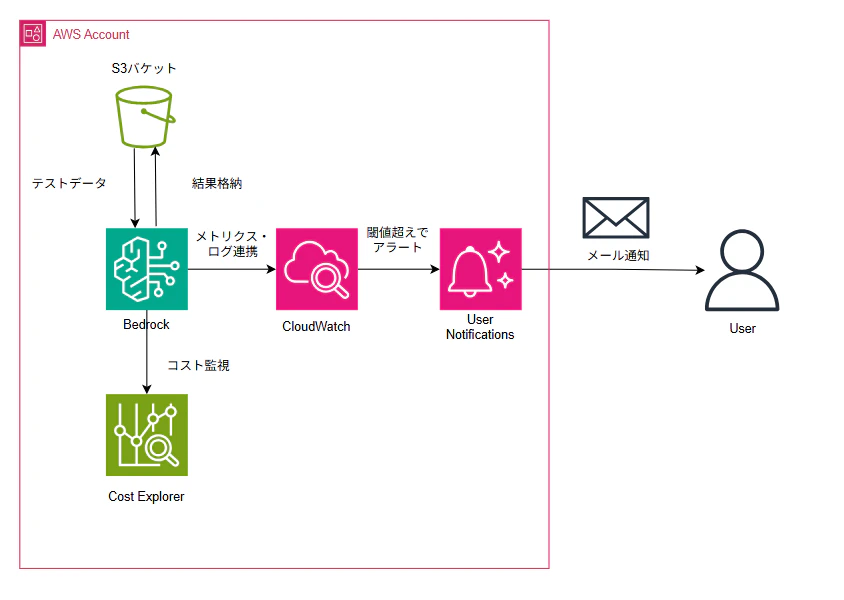
構成イメージ
1. AIが生成した回答の品質を評価する
LLMの回答に差別的・公序良俗に反するような不適切な表現が含まれていないかといった一般的な観点に加え、サービス提供側の想定通りの回答を返しているかといった個別の観点での評価も重要。
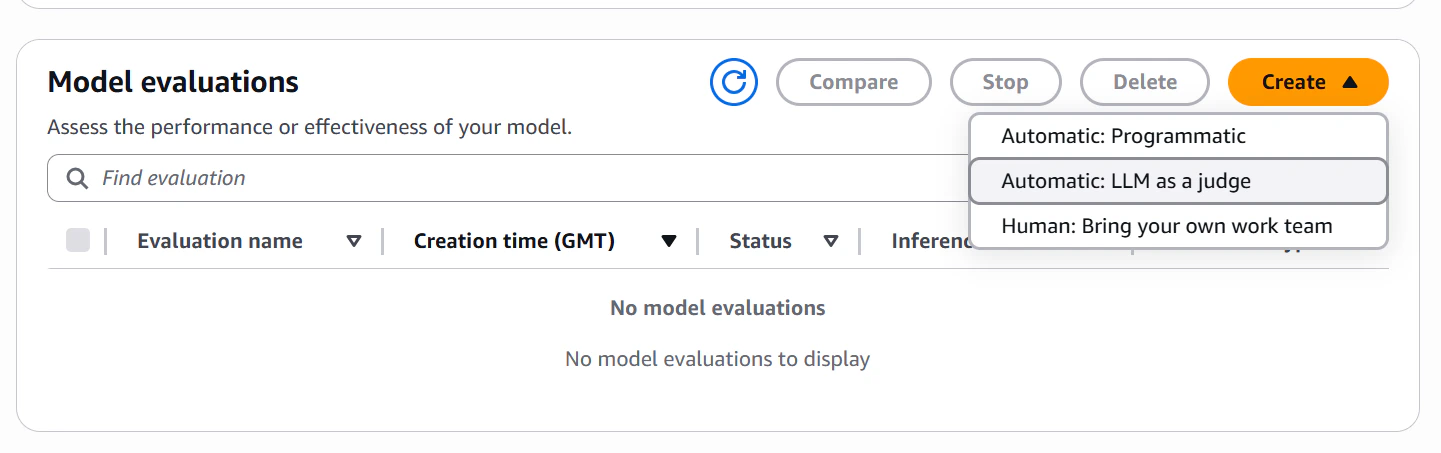
Bedrockモデル評価
2026/3/1現在、Bedrock上でProgrammatic , LLM as a judge , Bring your own work teamのモパフォーマンスと有効性の評価を実施することができる。
Bedrockの基盤モデルに加え、外部からインポートしたモデルやRAGソースも評価可能。
Programmaticは組み込みデータセットを使用して正解率や有害性を評価する方式で、LLM as ajudgeはLLMを使用して別のLLMを評価する方式。
LLM as a judge方式は評価者モデルにどんなロールで何をどう評価させたいかを指定できるため、プロンプトの工夫次第でプロジェクト独自の評価もできそう。
Automatic: Programmaticで評価する
Automatic: Programmaticを選択するとプログラムによる評価ジョブを作成することができる。
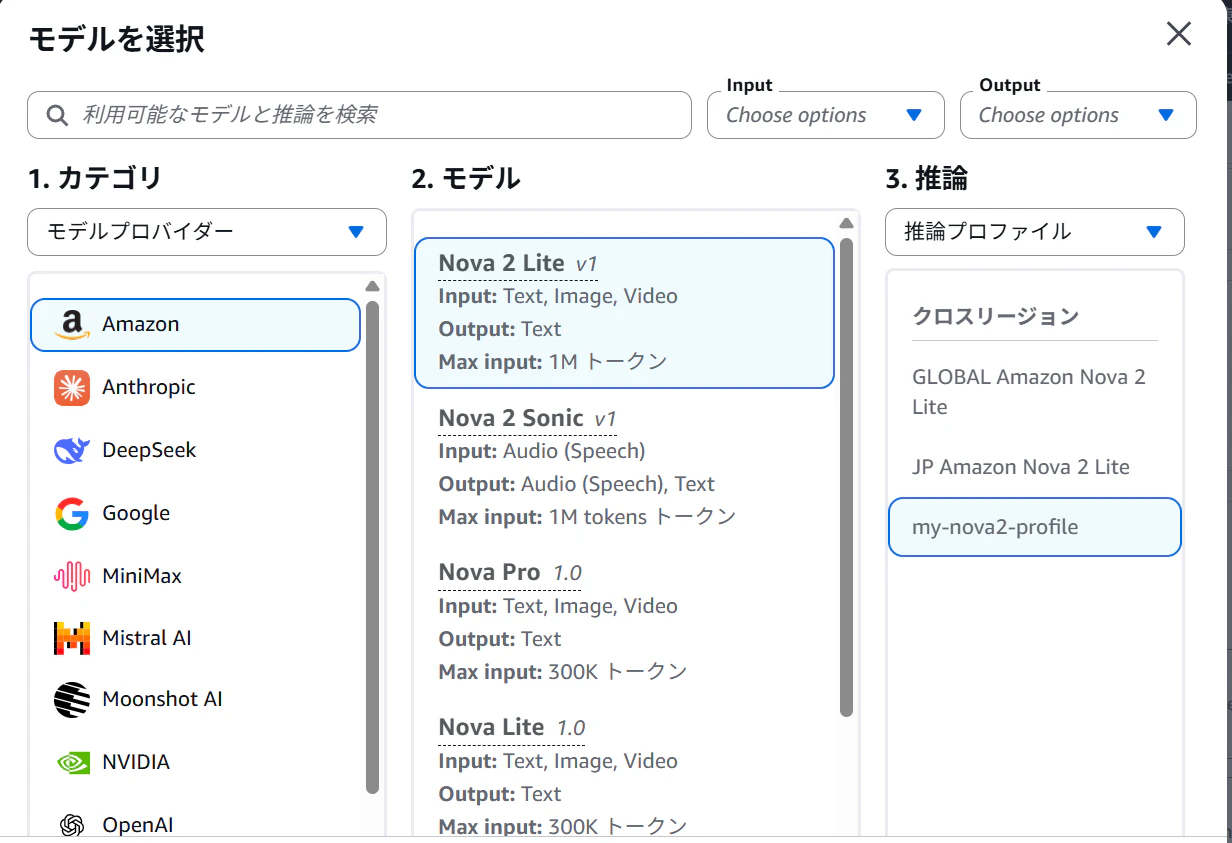
モデルとプロファイルを設定する。
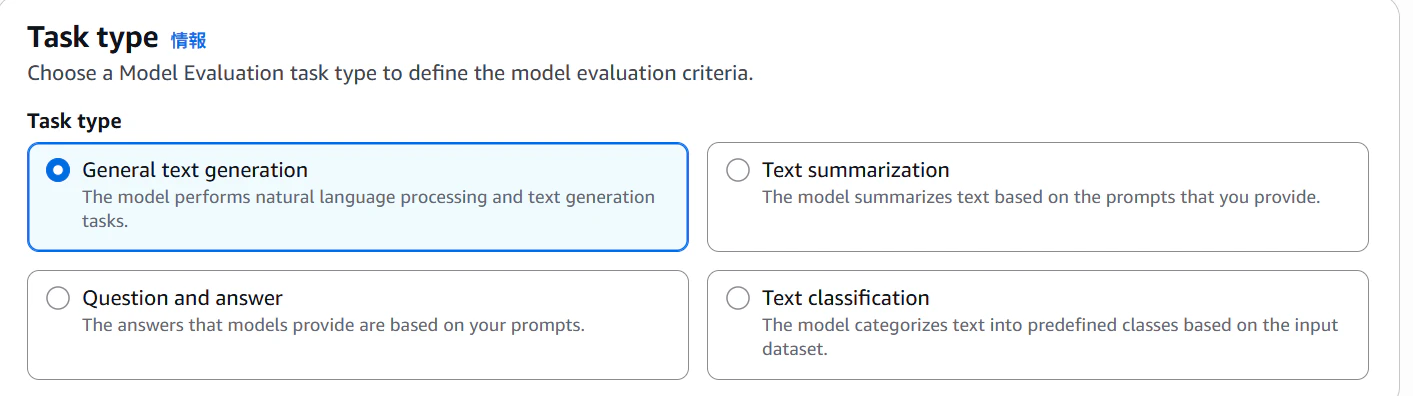
その後どんなタスクを評価するかを選択。とりあえずGeneral text generation(一般的なテキスト生成)で。
データセットとメトリクスを選択。
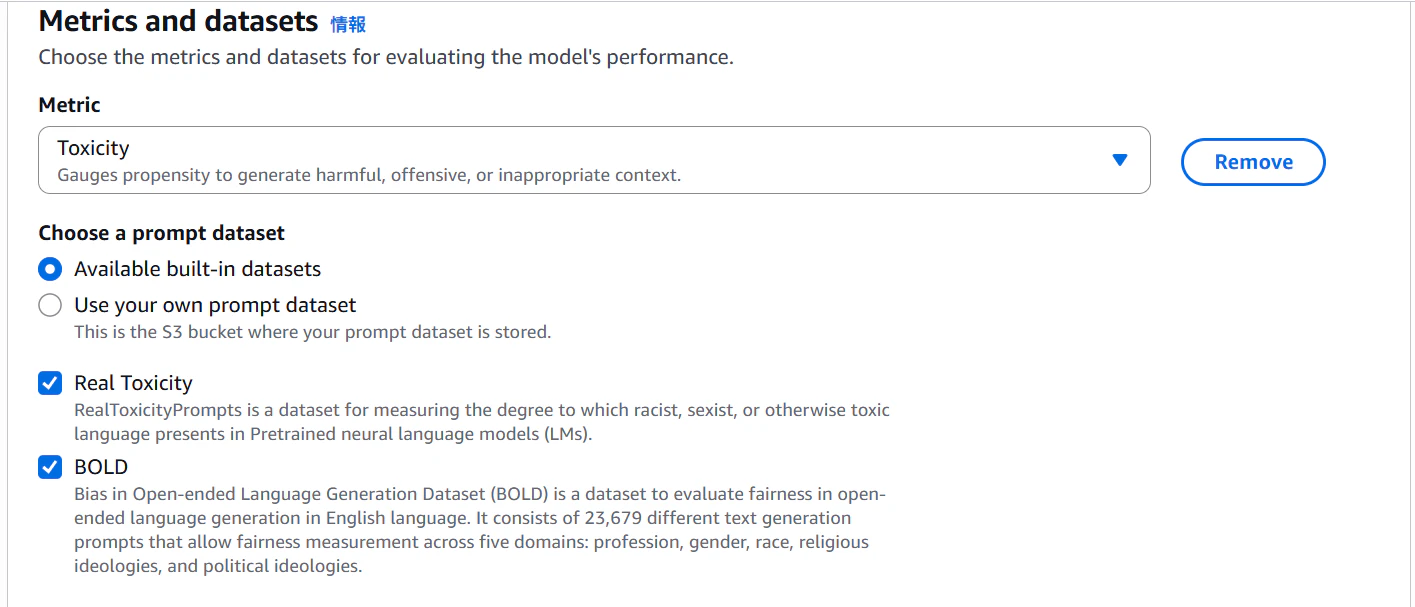
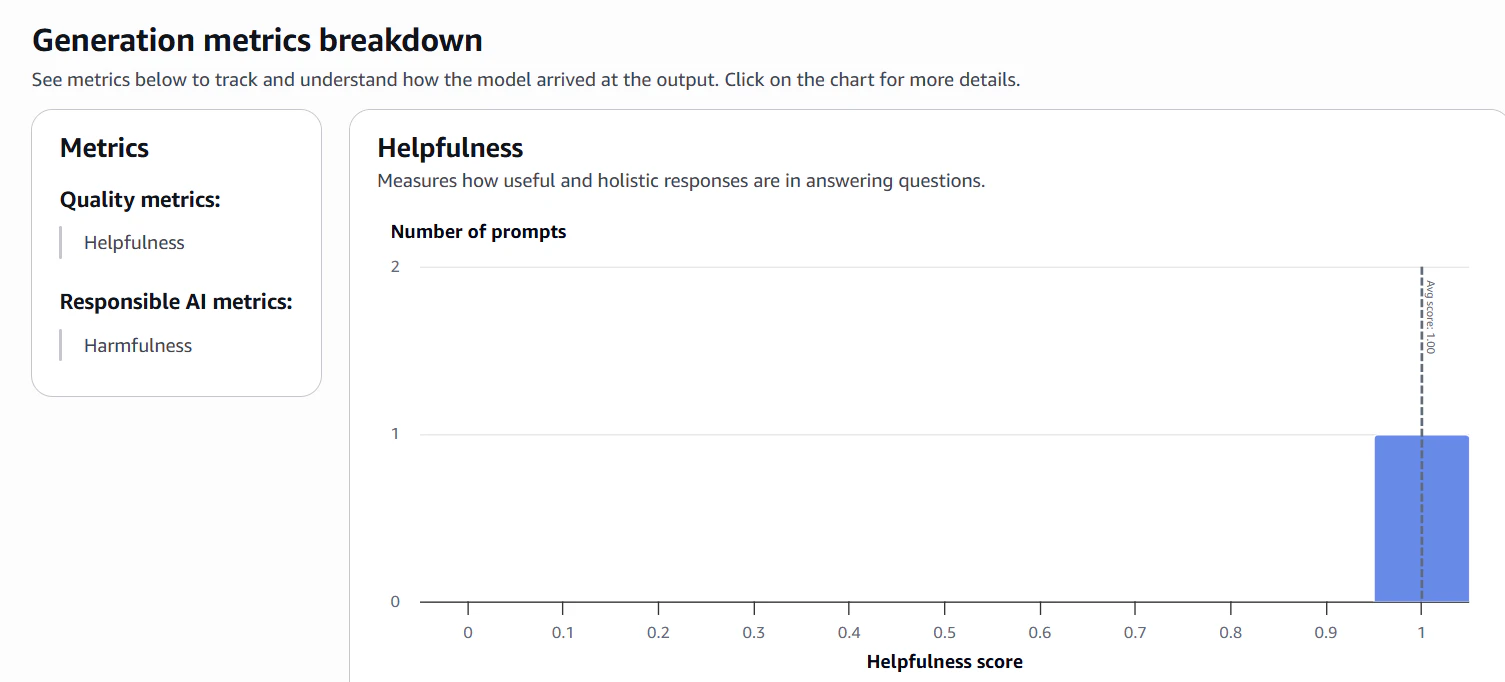
結果は概要がコンソールに表示され、詳細はS3に出力される。
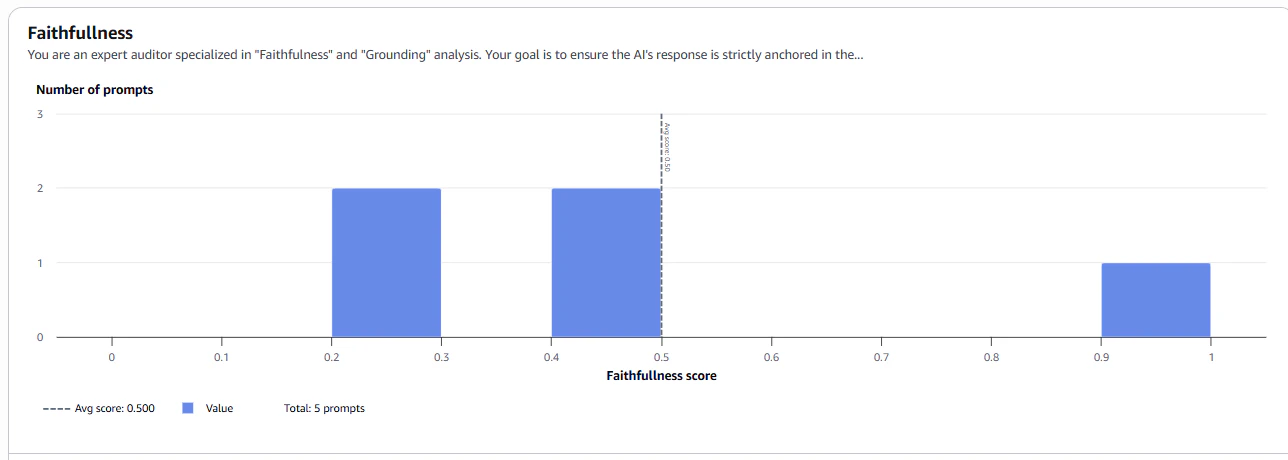
キャプチャはHelpfulnessのメトリクス。
LLM as a judgeで評価する
評価者、評価対象となるモデルをそれぞれ選択する。
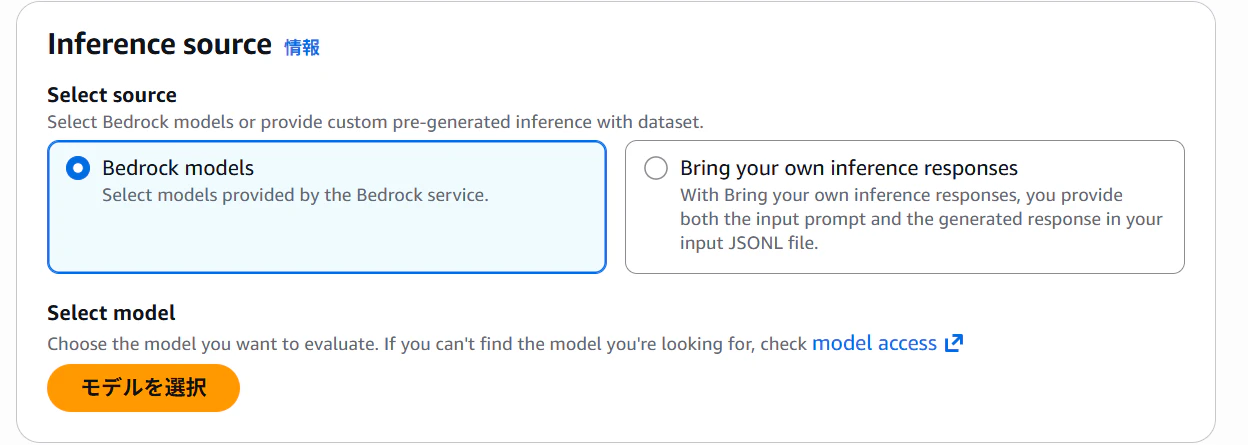
品質と責任あるAIの評価指標。

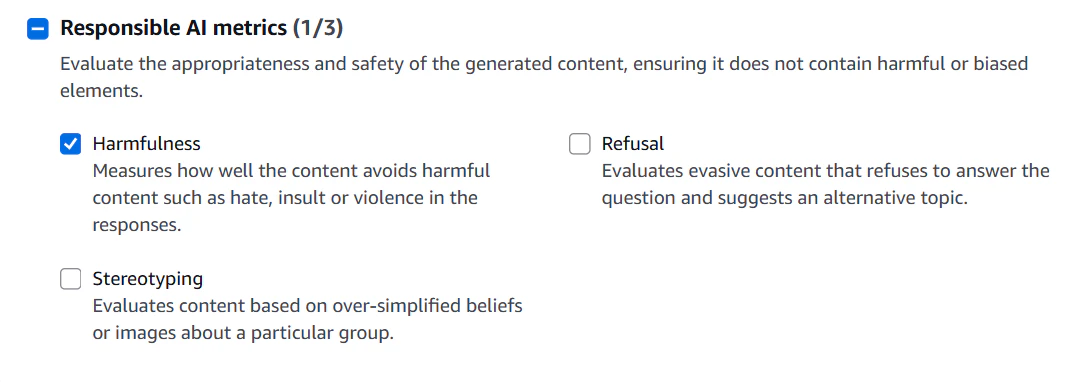
こちらはbuilt-inのデータセットが無いため、自分でデータセットをS3に格納する必要がある。
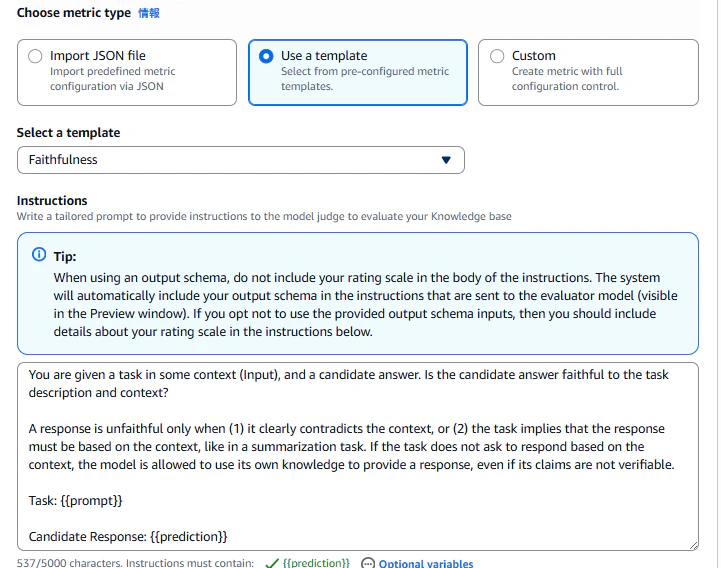
オプショナルではあるが、カスタムメトリクスはJSON, テンプレート, カスタムから作れる。テンプレートを選択したもの。
Customだとプロンプトを1から作成する。
以下は評価結果。データセットは評価ジョブを動かすために評価対象とは別モデルのAIで作ったダミーなので、あくまで画面の見え方の参考程度に。
データセットに即した回答であるかのスコア
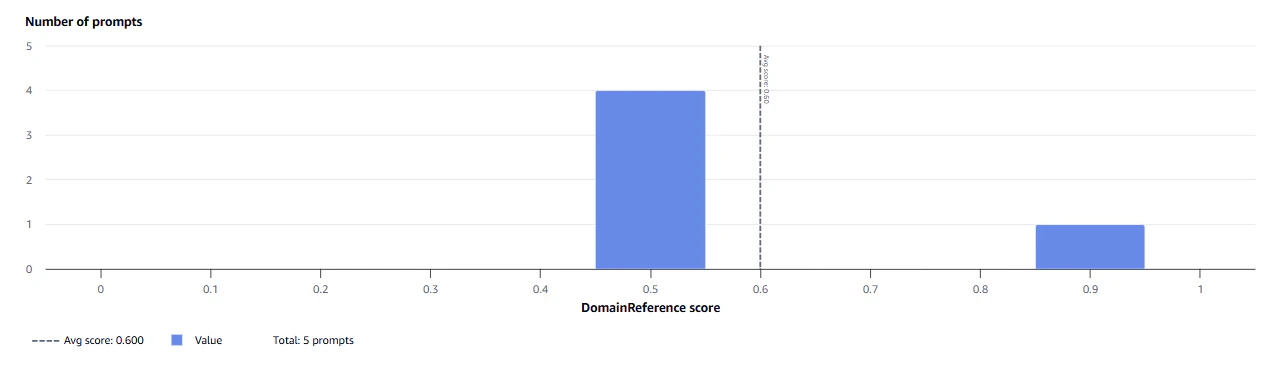
Faithfullness
2. ガードレールでブロックされた回答が無いかモニタリングする
顧客向けのサービスにLLMを組み込む際、機密情報・公序良俗に反する表現を含んだ回答はもちろん、用途に即していない質問への回答(例:製品サポート用のチャットボットなのに晩御飯の献立聞かれる)やビジネス的にリスクのある回答(例:他社製品との比較)もブロックする必要がある。
ガードレールを設定する
BedcorkのGuardrailsで有害カテゴリ、プロンプト攻撃、指定されたトピックやワード、機密情報に関する回答を拒否するよう設定できる。
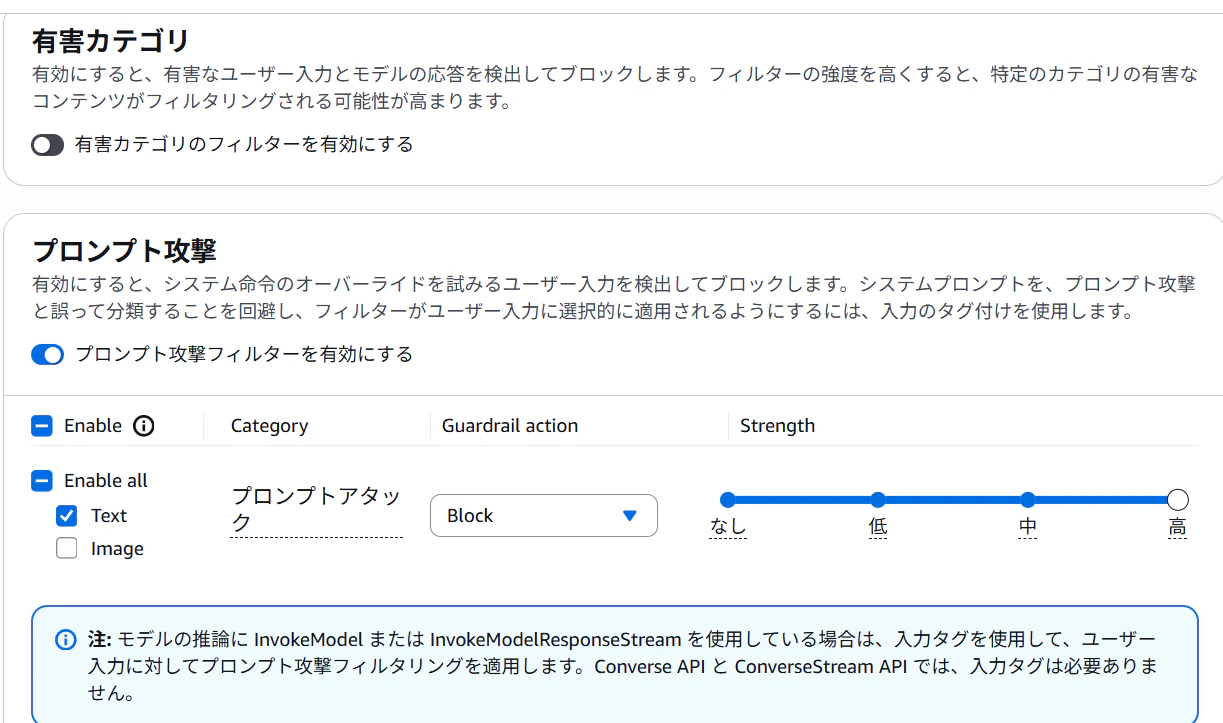
特定の目的に特化したAIを組み込む際、腕の見せ所が拒否トピックの指定。
単語だけでフィルタすると回答するべきトピックもブロックしてしまう可能性があるため、文脈でブロックをかける。
例えば、一般的な金融知識の質問に答えるAIチャットボットがあったとして、「投資」というワードで回答をブロックすると「投資の基礎知識を教える回答」もブロックしてしまうため、「特定の銘柄の売買を推奨したり、将来の利益を保証したりする投資助言」といった文脈をブロックすることで、コンプライアンス的にリスクのある回答をさせないようにする。
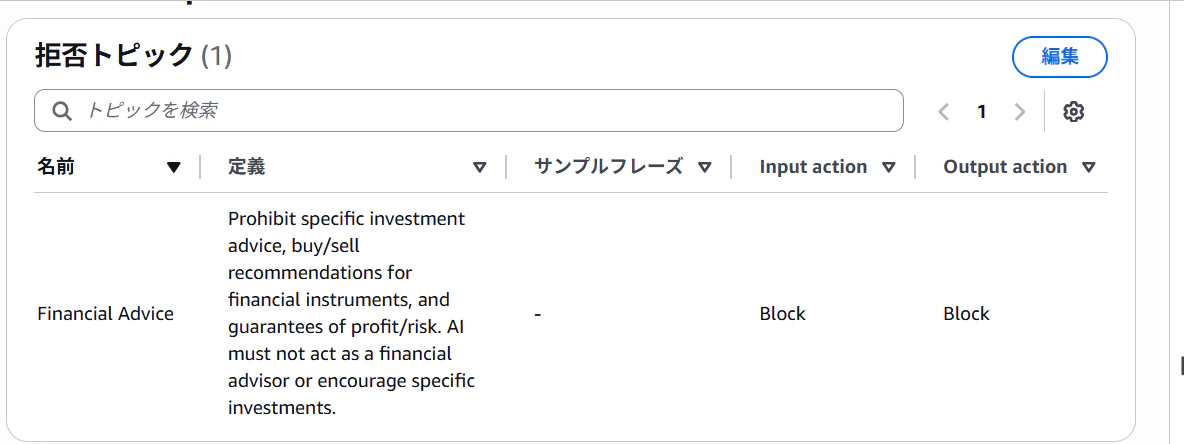
拒否トピックの設定画面。定義のところで文脈を指定する。
(拒否トピックにはClassicとStandardの2つのTierがあり、Classic Tierは英語、フランス語、スペイン語のみ対応。Standard Tierは50言語以上対応だが、クロスリージョン推論になる)
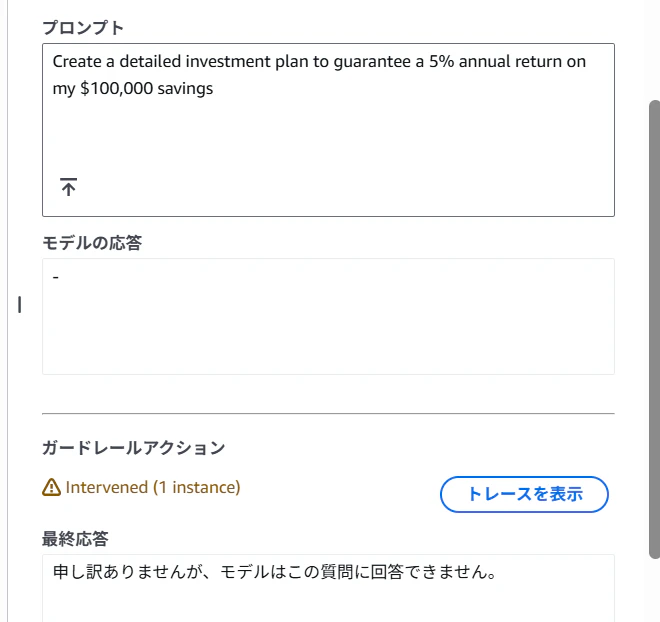
ガードレールのテスト画面で「貯蓄10万ドルで年利5%確実に出せる投資プラン作って」と聞いて、ガードレールに回答抑制されている図。
ガードレールでブロックされたモデル呼び出し回数を確認する
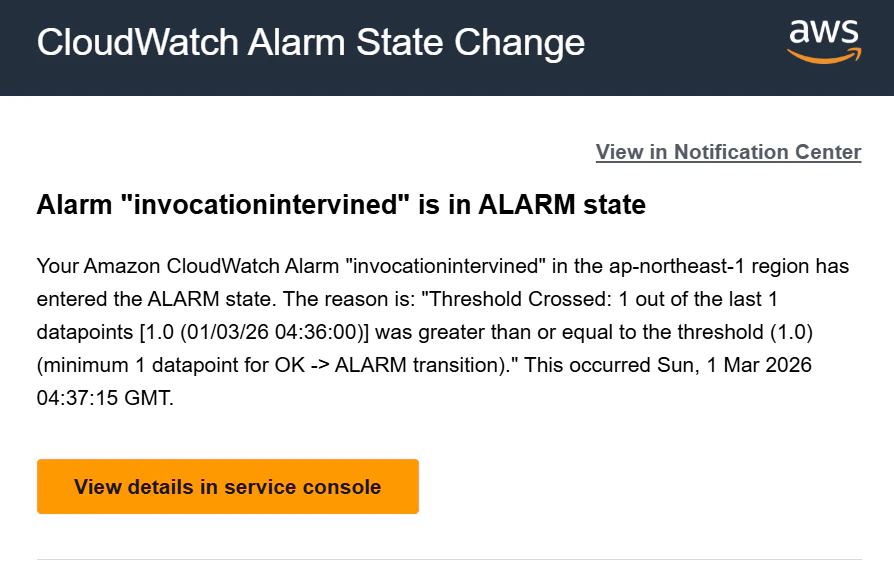
Guardrailsがブロックしたモデル呼び出しの回数はInvocationIntervenedというメトリクスで確認できるため、CloudWatch AlarmでInvocationIntervenedメトリクスの閾値を設定しておき、User Notificationsと連携させれば閾値を超えてアラート状態になった際、読みやすい形式でメール通知をすることも可能。
InvocationIntervinedが発生したことを示すメール通知。(閾値1)
3. モデルごとのコストを確認する
モデルの性能によってトークンあたりのコストに差があるため、用途に合わせて高速で安価なモデルと高品質なモデルを併用したり、リクエストの中身によってルーティング先を切り替えるプロンプトルーティング機能が登場している。
モデルや呼び出し用途別にLLM呼び出しのコストを可視化することで、モデルの使い分けで実際どれだけコストを最適化できたのかを評価しやすくなる。
モデル/用途別のコスト管理を実装する
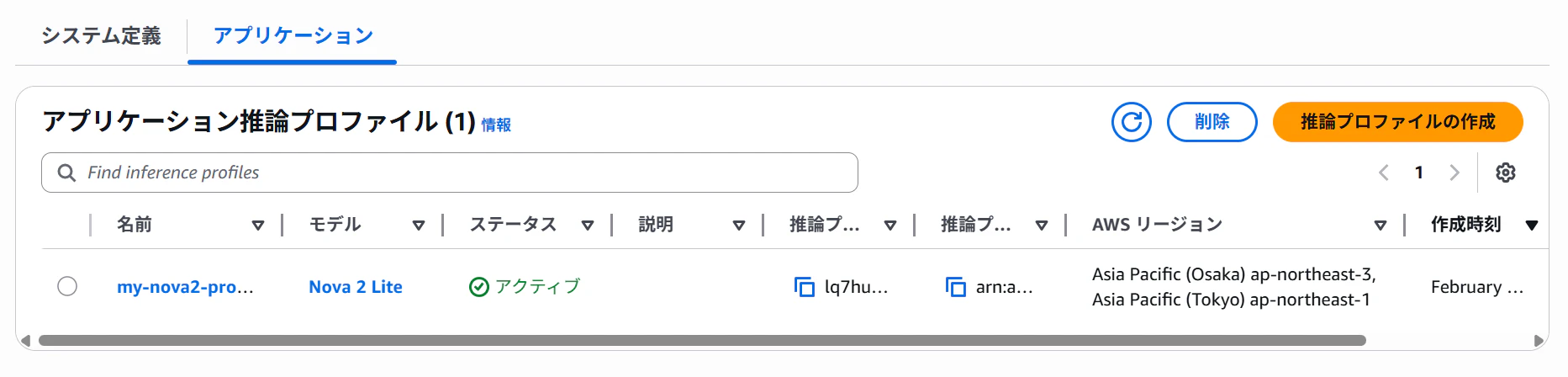
アプリケーション推論プロファイル+コスト配分タグを付与することで、Bedrock全体でいくらかかったか、よりもドリルダウンして、モデルごとのコストを確認することが可能。
以前はアプリケーション推論プロファイルの操作はCLIやSDK等でAPIにリクエストを送る必要があったけど、マネジメントコンソールにもアプリケーションのタブができ、GUI操作ができるようになっていた。
アプリケーション推論プロファイルにコスト配分タグを付与。タグの値をモデルや用途によって変えることでCost Explorerからタグの値別にコストを表示することができる。
おわりに
特定の用途に特化したLLMで、回答が適切かというのをどうモニタリングしていくかは課題に思っていたので、カスタムメトリクスを組めるLLM-as-a-judgeは活用していきたい。
ガードレールを設定する際に「どういう単語」ではなく「どういう文脈」を回答させないようにするのか整理する必要があり、境界線(ポリシー)を定義するスキルが今後求められそう。