※この記事は前回の続きです。
参照:図・表・JP/EN混在PDFでRAGはうまく動くのか?軽く検証してみた
前回のまとめ
前回は、図・表・JP/EN混在のPDFにナイーブRAGを当てると「読み順が壊れる・表構造が崩れる・根拠が示せない」という問題が出てくること、そしてその原因は 「意味のまとまり」と「検索単位(chunk)のまとまり」がズレていることにある、という話をしました。
今回は、「構造ごと取り出す」アプローチを試して、実際に何が変わったのかを見ていきます。
「構造付き抽出」とは何か
「構造ごと取り出す」というのは、具体的にどういうことでしょうか。
ナイーブなアプローチでは、PDFからテキストだけを抽出していました。このとき失われていたのは、
- これはテキストなのか、表なのか、図なのか(要素の種類)
- ページのどの位置にあるのか(位置情報)
- 何ページ目なのか(ページ番号)
という情報です。
「構造付き抽出」とは、テキストを抜き出すのではなく、これらの情報をセットで取り出すことを指しています。
「何が書かれているか」だけでなく、「何として、どこに書かれているか」を取り出す
というイメージです。
ADEがやっていること(ざっくり)
今回使ったのは、Landing AIのADE(Agentic Document Extraction)というツールです。
ADEの解析モデルはDPT(Document Pre-Trained Transformer)として説明されています。
通常のOCRと何が違うかというと、
「文字を読む」のではなく「ページ上の要素を認識してからchunk化する」
という発想で設計されている点です。
ADEの解析モデルについては、Document Pre-Trained Transformers - LandingAI が参考になります。
つまり、
- まずページ全体のレイアウトを解析する
- 要素ごとに「これはテキスト」「これは表」「これは図」と分類する
- 分類された要素をそれぞれchunkとして出力する
という流れです。ここが、前回試したPyMuPDFやOCR系ツールとの一番の違いでした。
まず試してみたい場合は、Quickstart - LandingAI から入るとわかりやすいです。
なお、今回は日本語ドキュメントに対しても試してみましたが、DPT-2では問題なく動作しました。ただし完璧ではなく、あくまで今回の検証レベルでの話です。
利用にはLandingAIのアカウントとAPIキーが必要です。今回は月1000クレジットのプランで検証しました。
実際にparseしてみる(最小コード)
まずは最小構成だけ載せます。(細かい前処理やエラーハンドリングは省略しています)
import os
from pathlib import Path
from landingai_ade import LandingAIADE
# APIキーは環境変数から取得
api_key = os.getenv("VISION_AGENT_API_KEY")
assert api_key is not None, "API key is not set"
client = LandingAIADE()
# PDFを渡してparseする
parse_result = client.parse(
document=Path("sample.pdf"),
model="dpt-2-latest" # dpt-2-latest を指定
)
# 最初のchunkを確認
first_chunk = parse_result.chunks[0]
print(first_chunk)
やっていることはシンプルです。
- PDFを渡す
- モデルを指定(
dpt-2-latest) - chunk配列が返ってくる
ナイーブOCRと比べて、「文字列だけ」ではなく、構造を持ったオブジェクトが返るのがポイントです。
実際の出力イメージ
返ってくるchunkは、例えばこんな形です。
{
"chunk_id": "4a1e983a-2414-448e-9e8e-45af2e5362b1",
"chunk_type": "table",
"text": "<table id=\"26-1\">\n<tr><td>No,</td><td>確認項目</td></tr>\n<tr><td>1-1</td><td>工場システムのセキュリティの必要性について...</td></tr>\n...\n</table>",
"page": 26,
"bbox": [0.023, 0.141, 0.977, 0.439],
"document": "SampleFile.pdf"
}
注目してほしいのは、
-
chunk_type→ これは「表(table)」なのか「テキスト(text)」なのか「図(figure)」なのか -
page→ 何ページ目か -
bbox→ ページ内のどの位置か(ページ全体を1.0とした相対座標)
が最初から揃っていることです。
ナイーブ抽出では、自前で設計して付与しないといけなかった情報が、最初からメタデータとして返ってきます。
出力を可視化すると
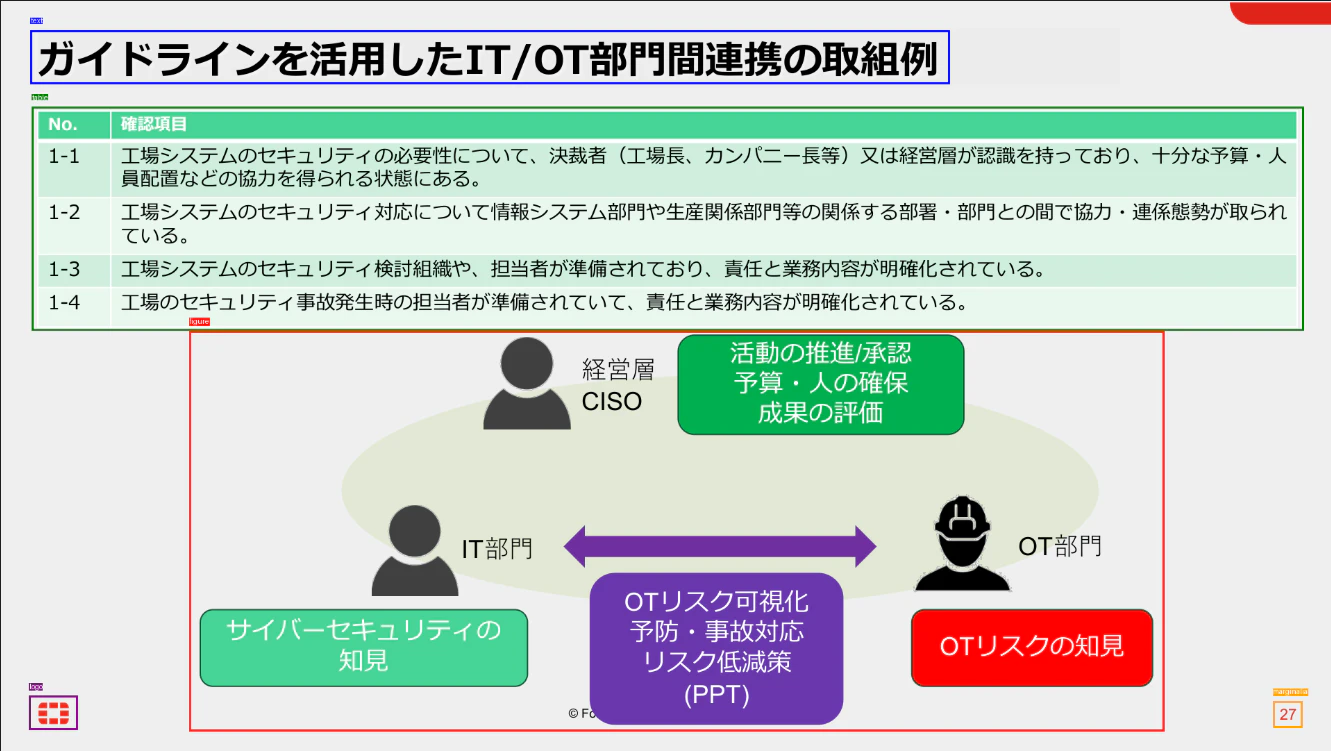
抽出結果をPDFページ上に重ねて可視化してみると、各要素がどう分類されているかが確認できます。
例えば、あるページに「上部にテキスト・中央に表・下部に図・下隅にロゴ・欄外にページ番号」が混在していた場合、ADEはそれを以下のように分離します。
- テキストブロック →
chunk_type: text - 表 →
chunk_type: table - 図・ダイアグラム →
chunk_type: figure - ロゴ →
chunk_type: logo - ページ番号などの欄外注記 →
chunk_type: marginalia
ナイーブOCRでは、これらが混ざり合ったひとかたまりのテキストとして出てきていました。それが、要素ごとに分かれて取り出せるようになります。
実際に可視化するとこんな感じです。
RAGに組み込む
抽出の仕組みがわかったところで、次はこれをRAGパイプラインに組み込みます。パイプライン全体の流れはこちらです。
変えたのは最初の「抽出フェーズ」だけです。それ以降の構成はナイーブRAGとほぼ同じです。
各ステップを少し詳しく説明します。
① 構造付きChunk抽出
LandingAI ADEがPDFを解析し、chunk_type / page / bbox / text を持つchunkの配列を返します。marginalia(欄外注記)など検索に不要な要素はあらかじめ除外しておくと安定感が上がります。
② Embedding生成
各chunkのtextをEmbeddingモデルでベクトル化します。構造を持ったchunkなので、表なら表全体のベクトル、図の説明なら説明のベクトルとして、自然に分かれます。
③ ChromaDB保存
embeddingとあわせて、page / bbox / chunk_type / document をメタデータとして一緒に保存します。bboxは後の可視化に使うため、文字列として保持します。
④ 類似検索
質問文をEmbeddingして、コサイン類似度でtop-K件を取得します。このときchunk_typeでフィルタリングもできます(例:「表に関する質問なのでtablechunkだけ検索する」)。
⑤ LLMで回答生成
取得したchunkをコンテキストとしてLLMに渡し、回答を生成します。
⑥ ページ+位置をハイライト表示
回答とあわせて、取得したchunkのpageとbboxをUIに渡します。PyMuPDFを使ってPDFの該当箇所に枠を描画すると、「どこに書いてあったか」を視覚的に確認できます。
実際の質問例
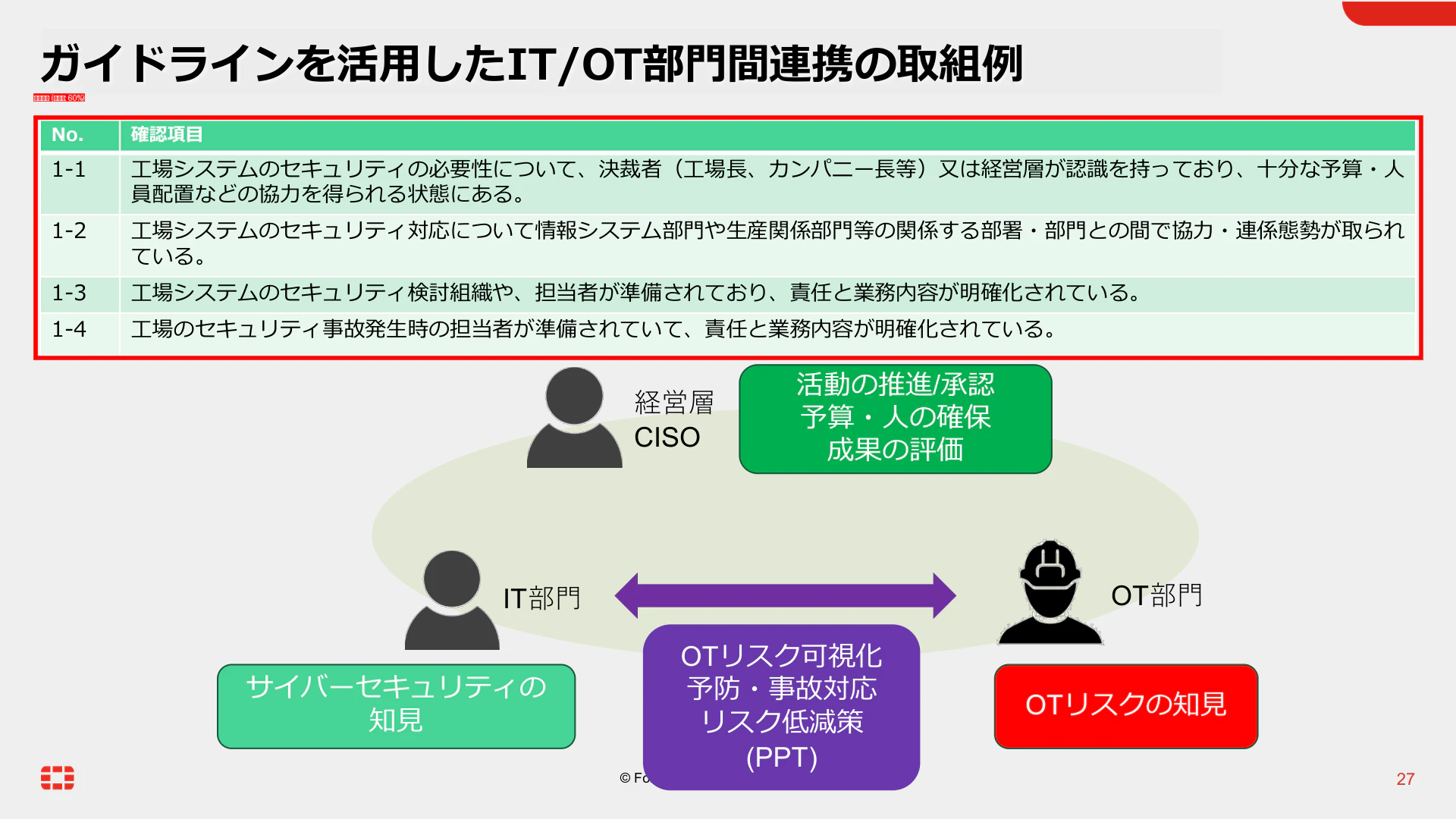
例1:表を参照する質問
「工場でセキュリティ事故が発生した場合、誰が対応し、責任や役割はどのように決められていますか?」
============================================================
💬 ANSWER:
============================================================
ページ27の表(No.1-4)によると、工場でセキュリティ事故が発生した場合には、
事前に担当者が準備されており、その責任と業務内容が明確化されています。
つまり、事故対応は指定された担当者が行い、役割や責任は事前に定義されています。
============================================================
ナイーブ抽出では、表が分断されて一部の行だけ拾われることがありました。構造付き抽出後は、該当するtablechunkがそのまま取得され、表全体のまとまりが保たれます。ページ番号(27ページ)も安定して返ってきました。
何が変わったか
構造付き抽出に切り替えてから、体感できる変化がいくつかありました。
表検索が安定した
チェックリスト形式の表が分断されて微妙にズレた回答になることが減りました。「あれ、なんか変な答えが減ったな」という感覚に近いです。
ページ根拠の提示が安定した
pageとbboxを保持しているため、「何ページのどの位置」をそのままUIに渡せるようになりました。以前は「それっぽい回答」で終わっていましたが、今は「どこに書いてあるか」を示せます。
読み順の問題も改善した
完全に解決したわけではありませんが、構造単位でchunkが生成されるため、図と説明が分断されるケースは減りました。
まとめると、今回変えたのはLLMでもEmbeddingモデルでもベクトルDBでもありません。変えたのは抽出フェーズだけです。
それでも検索結果の安定感や根拠提示のしやすさに明確な差が出ました。
RAGはモデル勝負というより、入力データの設計勝負という印象が改めて強くなりました。
まだ難しいこと
安定感は増しましたが、もちろん万能ではありません。
図の理解について
シンプルな図やダイアグラムについては、以前のアプローチよりも内容を把握しやすくなりました。ADEは図に対して補助的な説明(caption)を生成する仕組みがあり、単なる「画像として存在する」ではなく、「内容を含むchunk」として扱えます。
ただし、複雑な図における矢印の意図、レイヤー構造の関係性、図全体のシステム的な意味などは、まだ自動では読み取れません。業界特有の複雑な図については、ドメイン特化のファインチューニングがあればさらに改善すると考えられます。
複数ページにまたがる文脈理解
1ページ単位では整理できても、
- 前ページの図を参照している文章
- 章全体を前提にした説明
といったケースでは、依然として工夫が必要です。構造が取れても、「文脈をまたぐ推論」は別の問題です。
chunk設計はやっぱり重要
構造付き抽出に切り替えることで、「意味のまとまり」に近いchunkが自動で生成されるようになりました。これはナイーブ抽出と比べて大きな違いです。
ただ、それで「chunk設計の問題が解決した」わけではありません。
- どの粒度で分割するか
- tableをそのままEmbeddingするか、要約して使うか
- どのメタデータを保持・活用するか
これらはやはり設計次第です。
ここで重要なのは、ADEのようなAgenticなドキュメント解析ツールが、「意味のある単位でchunkを作ること」を可能にしてくれている、という点です。以前は読み順整理・要素分類・位置情報付与を自前で実装する必要がありました。それが最初からメタデータとして揃った状態で返ってくる。
ただし、これはあくまで汎用的なドキュメントでの話です。製造業の設備図面や業界固有のレイアウトなど、特定ドメインの複雑な資料に対しては、ドメイン特化のファインチューニングがあればさらに精度が上がると思われます。
補足・注意点
実際に試してみる際に知っておいてほしいことをまとめます。以降は技術的な補足です。
API利用について
利用にはLandingAIのアカウントとAPIキーが必要です。今回は月1000クレジットのプランで検証しました。
これから試す場合は、まず サインアップページ でアカウントを作成し、APIキーを発行すれば進められます。
ストレージ設計の選択肢
今回はChromaDBへのベクトルEmbeddingを選択しましたが、設計次第では他のアプローチも考えられます。例えば、抽出した情報をグラフDB(ツリー構造)に格納する方法や、特定のオブジェクト形式に変換してプログラム的に処理する方法なども有効です。どれが最適かは、ユースケースや設計要件によります。
全体を通じて感じたこと
最初の問いは「図・表・JP/EN混在PDFでRAGはうまく動くのか?」でした。
結論としては、「そのままでは厳しい。でも設計次第」 というのが今回の印象です。
あらためて感じたのは、RAGは「LLMの賢さ」よりも、
前処理設計にかなり依存している
ということでした。特にレイアウトを持つドキュメントでは、抽出・chunk設計・メタデータ保持がそのまま検索品質に影響します。
「RAGは思ったより精度が出ない」と感じている場合は、モデルを変える前に、抽出方法・chunkの粒度・メタデータ設計を見直してみるのも一つかもしれません。
今回はPOCレベルの検証でしたが、「構造を意識する」というだけで、かなり景色が変わった印象です。
FPTとLandingAIについて
FPTはLandingAIの戦略的パートナーであり、
FPT AI FactoryのNVIDIA H100 GPUインフラをLandingAIのモデル学習・ファインチューニングに提供しています(参考:FPT × LandingAI)。
同様のドキュメント処理課題をお持ちの方は、お気軽にご相談ください。