➊はじめに
ここでは、**クラウド(Google Colab)でAIプログラミングを「手っ取り早く動かしてイメージをつかみたいと思っている方」**向けの手順を説明いたします。
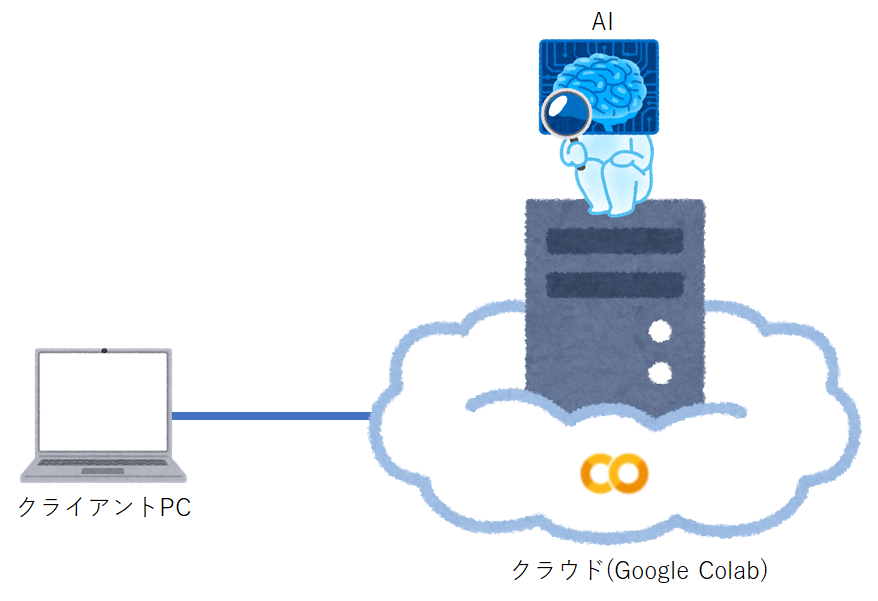
初心者向けのもので、目的は開発環境を整えてプログラム (プログラミングはしません。コピペでOKです^^;) を実行し、「ほぉ、AIプログラミングってこんな感じか~」というところがGOALです。
※ローカルPC版の『【0からはじめる「Python AIプログラミング」 for PC』は、こちらです
➋どんなことをやるか
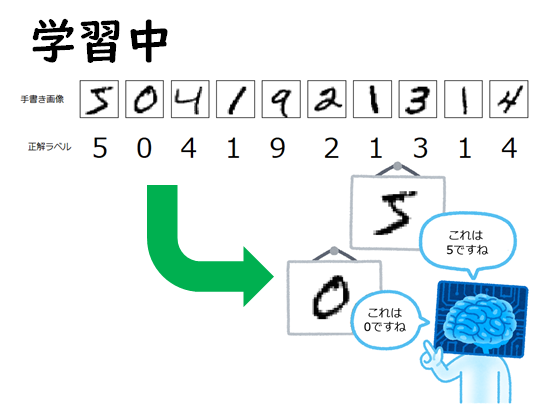
まず手書きの数字0~9とその正解ラベル(0~9)がセットになった教師データ60,000枚をAIに学習させます。
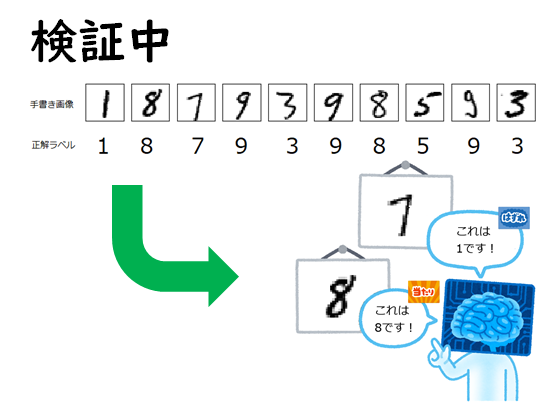
その後、手書きの数字0~9とその正解ラベル(0~9)がセットになった検証データ10,000枚をAIに検証させて、認識率や検証データの手書き数字がAIによって0~9のどの数字と認識したのかを試してみます。
(1) AIに学習させる
教師データ(60,000枚)を使用して、手書き画像を正解ラベルに沿って、0~9の数字として覚えさせます。
(2) AIに検証させる
検証データ(10,000枚)`を利用して、手書き画像をAIにより0~9の数字に分類(クラス分類)させ、正解データと比較し当たったかどうかを判定。
※上記データは プログラム実行時に MNISTデータベース から自動的にダウンロードされますので、画像ファイルの収集や正解ラベリング(画像データと正解ラベルの結びつけ)等の前準備は一切不要となっています。
➌開発環境準備
Google Colabが全部用意してくれるので、今回はインストールなどはありません。
「Google Colabサービス」を利用するのに「googleアカウント」が必要なだけです。
| No. | 開発環境 | 説明 |
|---|---|---|
| 1 | Googleアカウント | Google Colab利用のためにGoogleアカウントを使用します。無料です。 |
| 2 | Google Colabサービス | Googleのクラウド仮想マシン上で動くPython実行環境。使用料は無料です。インストール等の作業などは不要です。GPUも無料で使用でき、AI学習も素早く計算が可能です。 |
➍作業フロー
(1) Googleのサービスから「ドライブ」をクリック
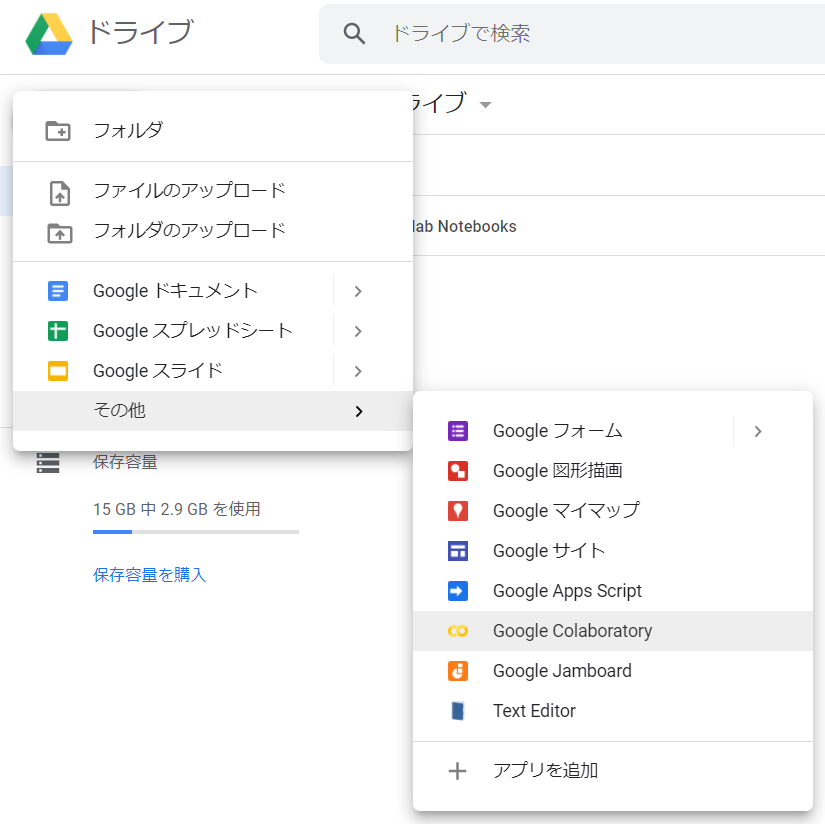
(2) ドライブの「新規」→「その他」→「Google Colaboratory」をクリック
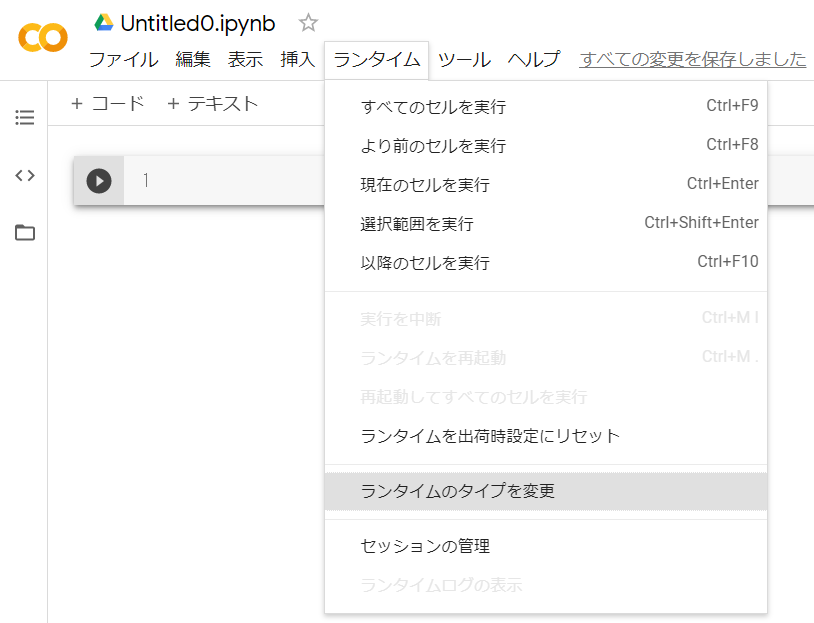
(3) 「ランタイム」→「ランタイムのタイプを変更」をクリック
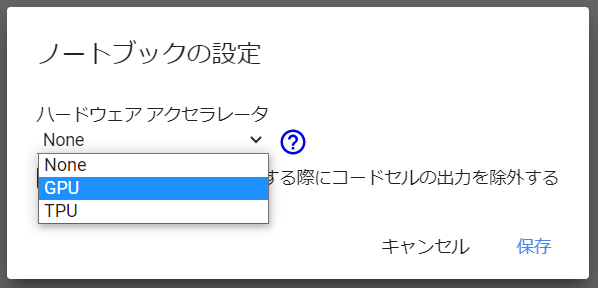
(4) ノートブックの設定で、ハードウェアアクセラレータとして「GPU」を選択し、「保存」をクリック
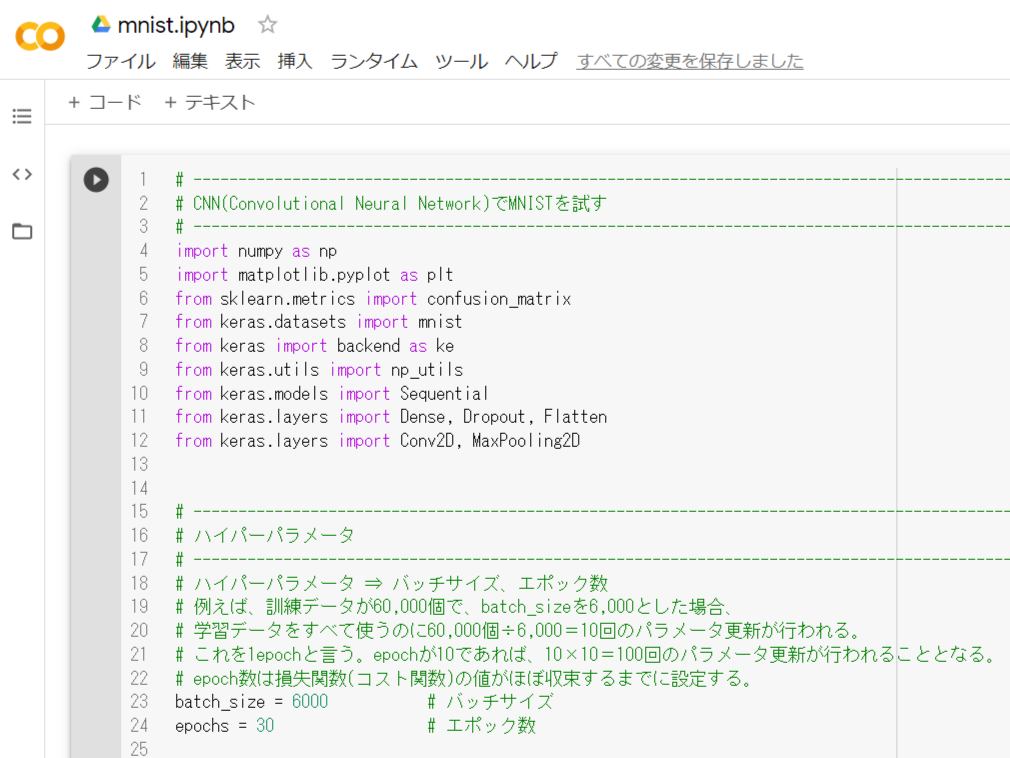
(5) AIプログラムをコピペ
以下のプログラムをGoogle Colabのコードのところへコピペしてください。
# ------------------------------------------------------------------------------------------------------------
# CNN(Convolutional Neural Network)でMNISTを試す
# ------------------------------------------------------------------------------------------------------------
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
from keras.datasets import mnist
from keras import backend as ke
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
# ------------------------------------------------------------------------------------------------------------
# ハイパーパラメータ
# ------------------------------------------------------------------------------------------------------------
# ハイパーパラメータ ⇒ バッチサイズ、エポック数
# 例えば、訓練データが60,000個で、batch_sizeを6,000とした場合、
# 学習データをすべて使うのに60,000個÷6,000=10回のパラメータ更新が行われる。
# これを1epochと言う。epochが10であれば、10×10=100回のパラメータ更新が行われることとなる。
# epoch数は損失関数(コスト関数)の値がほぼ収束するまでに設定する。
batch_size = 6000 # バッチサイズ
epochs = 30 # エポック数
# ------------------------------------------------------------------------------------------------------------
# 正誤表関数
# ------------------------------------------------------------------------------------------------------------
def show_prediction():
n_show = 100 # 全部は表示すると大変なので一部を表示
y = model.predict(X_test)
plt.figure(2, figsize=(10, 10))
plt.gray()
for i in range(n_show):
plt.subplot(10, 10, (i+1)) # subplot(行数, 列数, プロット番号)
x = X_test[i, :]
x = x.reshape(28, 28)
plt.pcolor(1 - x)
wk = y[i, :]
prediction = np.argmax(wk)
plt.text(22, 25.5, "%d" % prediction, fontsize=12)
if prediction != np.argmax(y_test[i, :]):
plt.plot([0, 27], [1, 1], color='red', linewidth=10)
plt.xlim(0, 27)
plt.ylim(27, 0)
plt.xticks([], "")
plt.yticks([], "")
# ------------------------------------------------------------------------------------------------------------
# keras backendの表示
# ------------------------------------------------------------------------------------------------------------
# print(ke.backend())
# print(ke.floatx())
# ------------------------------------------------------------------------------------------------------------
# MNISTデータの取得
# ------------------------------------------------------------------------------------------------------------
# 初回はダウンロードが発生するため時間がかかる
# 60,000枚の28x28ドットで表現される10個の数字の白黒画像と10,000枚のテスト用画像データセット
# ダウンロード場所:'~/.keras/datasets/'
# ※MNISTのデータダウンロードがNGとなる場合は、PROXYの設定を見直してください
#
# MNISTデータ
# ├ 教師データ (60,000個)
# │ ├ 画像データ
# │ └ ラベルデータ
# │
# └ Testデータ (10,000個)
# ├ 画像データ
# └ ラベルデータ
# ↓教師データ ↓Testデータ
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# ↑画像 ↑ラベル ↑画像 ↑ラベル
# ------------------------------------------------------------------------------------------------------------
# 画像データ(教師データ、Testデータ)のリシェイプ
# ------------------------------------------------------------------------------------------------------------
img_rows, img_cols = 28, 28
if ke.image_data_format() == 'channels_last':
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
else:
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
# 配列の整形と、色の範囲を0~255 → 0~1に変換
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# ------------------------------------------------------------------------------------------------------------
# ラベルデータ(教師データ、Testデータ)のベクトル化
# ------------------------------------------------------------------------------------------------------------
y_train = np_utils.to_categorical(y_train) # 教師ラベルのベクトル化
y_test = np_utils.to_categorical(y_test) # Testラベルのベクトル化
# ------------------------------------------------------------------------------------------------------------
# ネットワークの定義 (keras)
# ------------------------------------------------------------------------------------------------------------
print("")
print("●ネットワーク定義")
model = Sequential()
# 入力層 28×28×3
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu', input_shape=input_shape, padding='same')) # 01層:畳込み層64枚
model.add(Conv2D(64, (3, 3), activation='relu', padding='same')) # 02層:畳込み層64枚
model.add(MaxPooling2D(pool_size=(2, 2))) # 03層:プーリング層
model.add(Dropout(0.30)) # 04層:ドロップアウト
model.add(Conv2D(64, (3, 3), activation='relu', padding='same')) # 05層:畳込み層64枚
model.add(MaxPooling2D(pool_size=(2, 2))) # 06層:プーリング層
model.add(Flatten()) # 08層:次元変換
model.add(Dense(128, activation='relu')) # 09層:全結合出力128
model.add(Dense(10, activation='softmax')) # 10層:全結合出力10
# model表示
model.summary()
# コンパイル
# 損失関数 :categorical_crossentropy (クロスエントロピー)
# 最適化 :Adam
model.compile(loss='categorical_crossentropy',
optimizer='Adam',
metrics=['accuracy'])
print("")
print("●学習スタート")
f_verbose = 1 # 0:表示なし、1:詳細表示、2:表示
hist = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
verbose=f_verbose)
# モデル保存
model.save('colab_mnist.hdf5')
# ------------------------------------------------------------------------------------------------------------
# 損失値グラフ化
# ------------------------------------------------------------------------------------------------------------
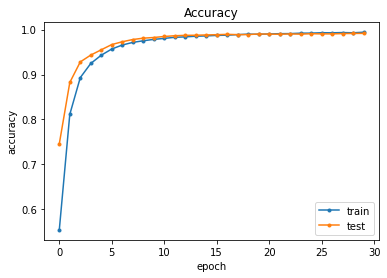
# Accuracy (正解率)
plt.plot(range(epochs), hist.history['accuracy'], marker='.')
plt.plot(range(epochs), hist.history['val_accuracy'], marker='.')
plt.title('Accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='lower right')
plt.show()
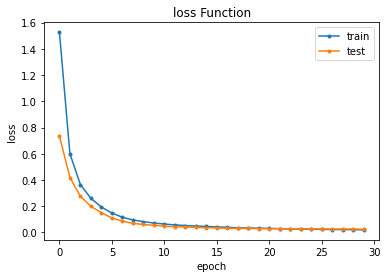
# loss (損失関数)
plt.plot(range(epochs), hist.history['loss'], marker='.')
plt.plot(range(epochs), hist.history['val_loss'], marker='.')
plt.title('loss Function')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper right')
plt.show()
# ------------------------------------------------------------------------------------------------------------
# テストデータ検証
# ------------------------------------------------------------------------------------------------------------
print("")
print("●検証結果")
t_verbose = 1 # 0:表示なし、1:詳細表示、2:表示
score = model.evaluate(X_test, y_test, verbose=t_verbose)
print("")
print("batch_size = ", batch_size)
print("epochs = ", epochs)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
print("")
print("●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ")
# predict_classes = model.predict_classes(X_test[1:10000, ], batch_size=batch_size)
predict_classes = np.argmax(model.predict(X_test[1:10000, ], batch_size=batch_size), axis=-1)
true_classes = np.argmax(y_test[1:10000], 1)
print(confusion_matrix(true_classes, predict_classes))
# ------------------------------------------------------------------------------------------------------------
# 正誤表表示
# ------------------------------------------------------------------------------------------------------------
show_prediction()
plt.show()
GoogleColabのコード欄へコピペして、こんな感じ ↓ になりましたか?
(6) AIプログラムを実行
「ランタイム」->「すべてのセルを実行」をクリックして、AIプログラムを実行してください。
(7) 実行結果
さすがGPUです😊とても処理が早いです!
●ネットワーク定義
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_19 (Conv2D) (None, 28, 28, 64) 640
_________________________________________________________________
conv2d_20 (Conv2D) (None, 28, 28, 64) 36928
_________________________________________________________________
max_pooling2d_13 (MaxPooling (None, 14, 14, 64) 0
_________________________________________________________________
dropout_7 (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_21 (Conv2D) (None, 14, 14, 64) 36928
_________________________________________________________________
max_pooling2d_14 (MaxPooling (None, 7, 7, 64) 0
_________________________________________________________________
flatten_6 (Flatten) (None, 3136) 0
_________________________________________________________________
dense_12 (Dense) (None, 128) 401536
_________________________________________________________________
dense_13 (Dense) (None, 10) 1290
=================================================================
Total params: 477,322
Trainable params: 477,322
Non-trainable params: 0
_________________________________________________________________
●学習スタート
Epoch 1/30
2/10 [=====>........................] - ETA: 1s - loss: 2.2641 - accuracy: 0.1649WARNING:tensorflow:Callbacks method `on_train_batch_end` is slow compared to the batch time (batch time: 0.0182s vs `on_train_batch_end` time: 0.2118s). Check your callbacks.
10/10 [==============================] - 3s 259ms/step - loss: 1.5261 - accuracy: 0.5543 - val_loss: 0.7360 - val_accuracy: 0.7458
Epoch 2/30
10/10 [==============================] - 2s 241ms/step - loss: 0.6002 - accuracy: 0.8113 - val_loss: 0.4189 - val_accuracy: 0.8823
Epoch 3/30
10/10 [==============================] - 2s 241ms/step - loss: 0.3648 - accuracy: 0.8931 - val_loss: 0.2760 - val_accuracy: 0.9281
︙ (省略)
Epoch 28/30
10/10 [==============================] - 2s 240ms/step - loss: 0.0221 - accuracy: 0.9934 - val_loss: 0.0266 - val_accuracy: 0.9911
Epoch 29/30
10/10 [==============================] - 2s 240ms/step - loss: 0.0221 - accuracy: 0.9929 - val_loss: 0.0267 - val_accuracy: 0.9914
Epoch 30/30
10/10 [==============================] - 2s 241ms/step - loss: 0.0196 - accuracy: 0.9941 - val_loss: 0.0247 - val_accuracy: 0.9916
●検証結果
313/313 [==============================] - 1s 4ms/step - loss: 0.0247 - accuracy: 0.9916
batch_size = 6000
epochs = 30
Test loss: 0.024685267359018326
Test accuracy: 0.991599977016449
●混同行列(コンフュージョンマトリックス) 横:識別結果、縦:正解データ
[[ 974 0 1 0 0 0 2 1 2 0]
[ 0 1131 2 0 0 1 1 0 0 0]
[ 2 1 1024 1 0 0 0 4 0 0]
[ 1 0 1 1002 0 5 0 0 1 0]
[ 0 0 0 0 978 0 1 1 0 2]
[ 1 0 0 3 0 886 1 0 0 1]
[ 4 2 0 0 1 3 947 0 1 0]
[ 0 2 6 2 0 0 0 1014 1 2]
[ 3 0 2 2 0 1 0 0 965 1]
[ 0 3 0 1 3 3 0 2 3 994]]

➎以上
Google ColabはGPUを使用できるので、AIの学習が比較的早く終わります。
自前のノートPCだと5epocくらいでイライラしちゃうのに、Google Colabだと20epocでもへっちゃらです😋ソースコードのepoc数を変えてみたり、ネットワーク定義を変えてみたりして、より良い認識率となるモデルを作って、遊んでみてください。
お疲れ様でした!