❶はじめに
AIの'Hello World'と呼ばれるMNIST(AIによる数字認識)について、今日もゆるりと試行錯誤していきたいと思います。

自分で書いた数字を認識させてみた
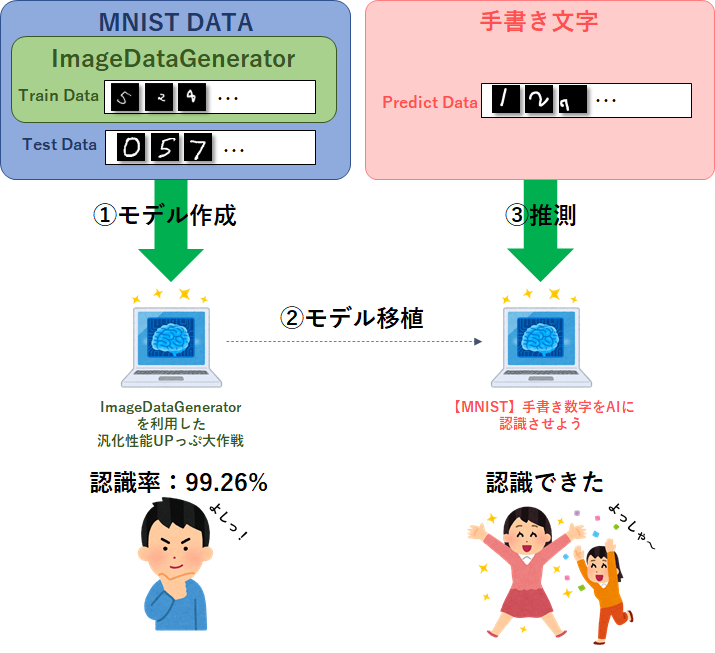
『0からはじめる「Python AIプログラミング」for Google Colab』で実施した通り、MNISTの認識精度は99.1%以上となり、ほぼ完成しているように見えました。
Test loss : 0.024685267359018326
Test accuracy : 0.991599977016449
しかし、『【MNIST】自分の数字をAIに認識させよう』で自分の手書き数字が正しく認識されるか試してみたところ、意外と誤認識が多いことが分かりました。
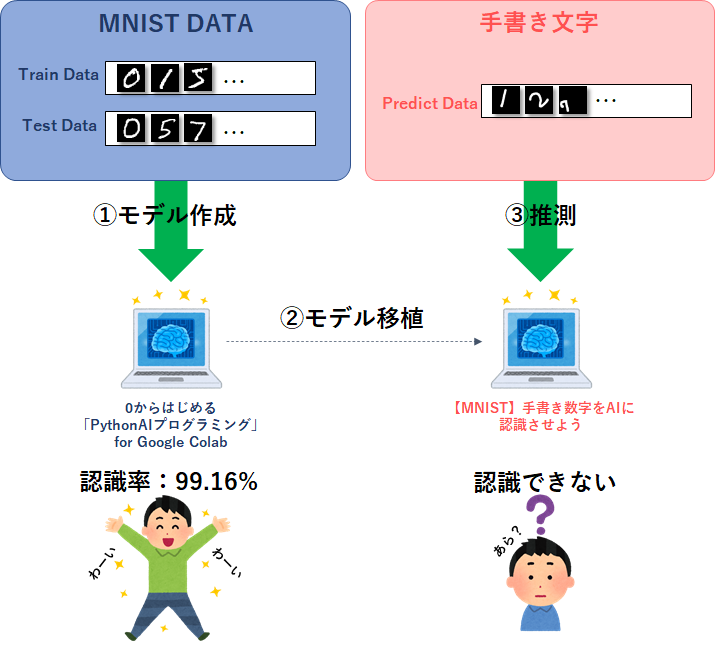
これはつまり、MNISTが用意したテストデータでの認識精度が99.1%以上になったに過ぎないということですね。
→考えてみたら、そりゃそーなんだけどね😅
誤認識サンプル
例えばですが、『0からはじめる「Python AIプログラミング」for Google Colab』で作ったモデルを使用しての、誤認識サンプルです。
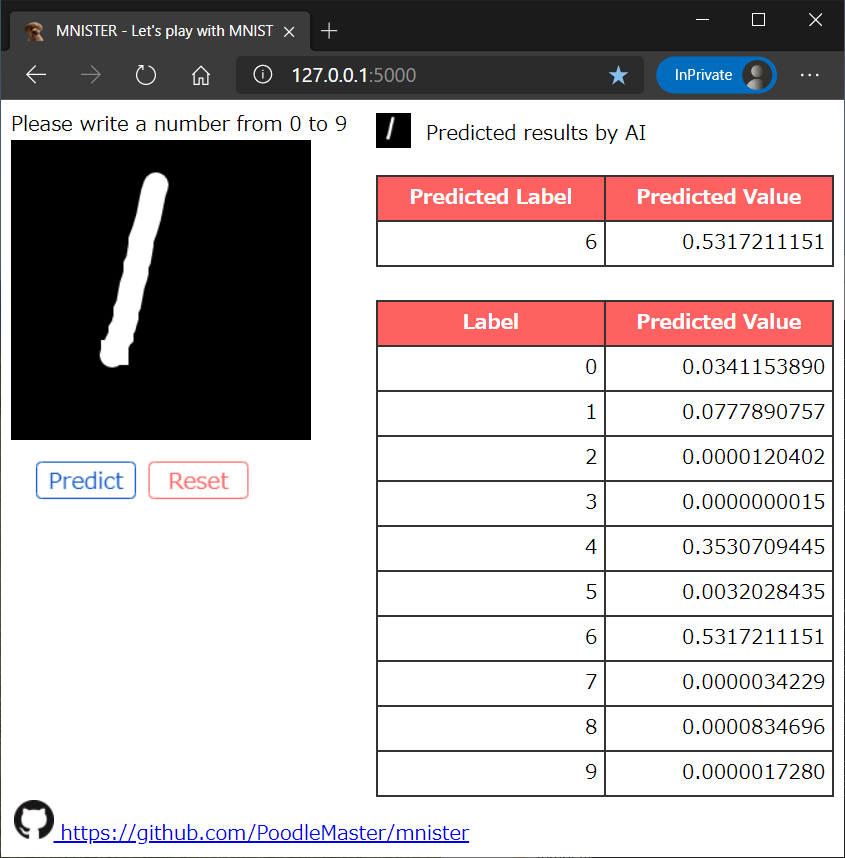
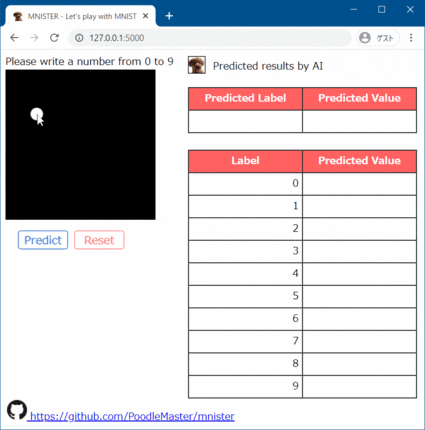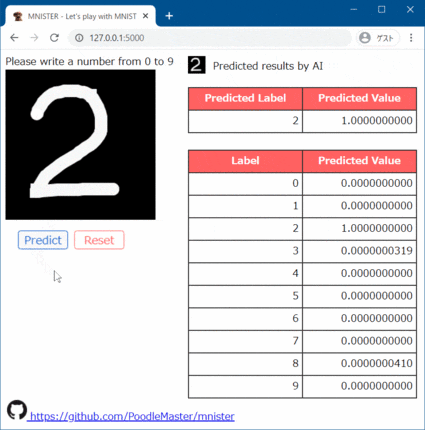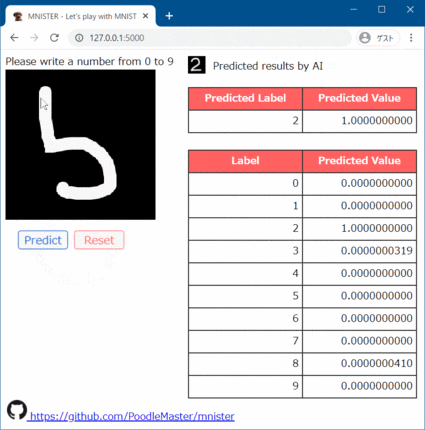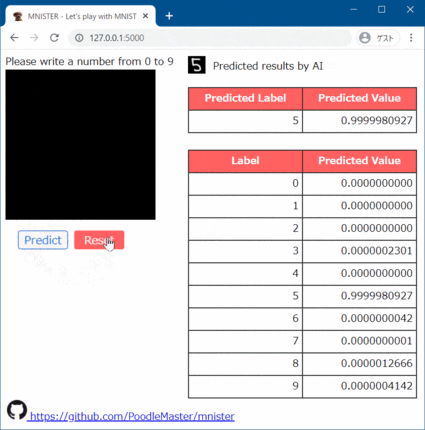
(1) 誤認識:1を6と勘違い
結構まっとうに書いたんだけどダメか…
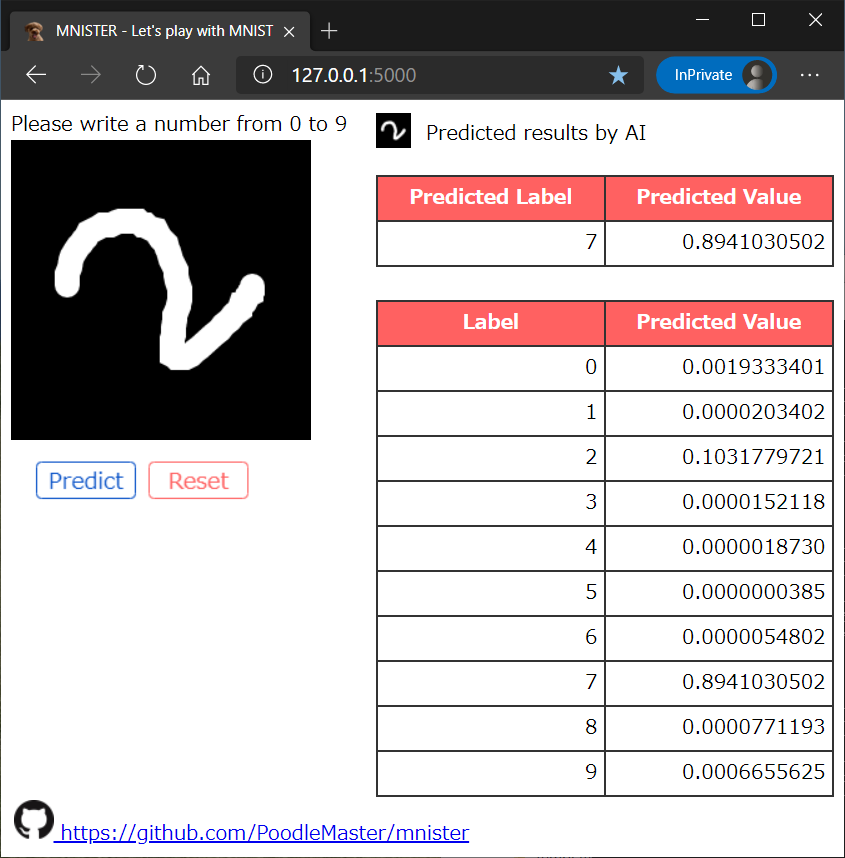
(2) 誤認識:2を7と勘違い
回転しているとダメか…
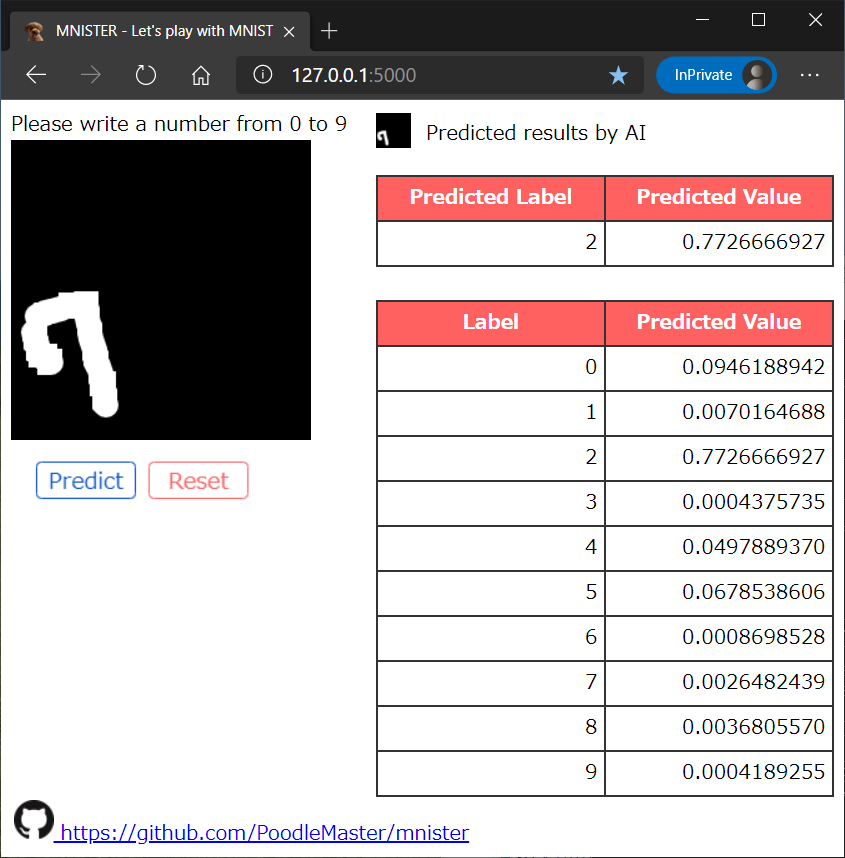
(3) 誤認識:7を2と勘違い
縮小して端に書くとダメか…
➋今回やること
ということで、『0からはじめる「Python AIプログラミング」for Google Colab』で作ったモデルでは、汎化性能が低いことが分かったので、学習データを回転、拡大・縮小、移動などさせて、もっと多種多様な入力にも対応できるモデルを作れるかを試してみたいと思います。
名付けて、汎化性能UPっぷ大作戦!
「ツール作るのメンドクセ」という方はこちらからすぐに遊べます。
HEROKUへデプロイしました。すぐに遊べます😊!
→ https://mnister-web.herokuapp.com/
➌ImageDataGeneratorの利用
MNISTの学習データを汎化するため、多種多様な学習データを用意する必要があります。しかし、新規にデータを用意したりラベル付けする事は、とても大変です。そこで、kerasライブラリに用意されているImageDataGeneratorというリアルタイムにデータ拡張(Data Augmentation)ができる関数を使い、学習させたいと思います。
■Keras Documentation
https://keras.io/ja/preprocessing/image/#imagedatagenerator
ImageDataGeneratorの設定値ですが、今回は数字なので水平反転、垂直反転はしないようにしました。また、回転角度を90度にしてしまうと数字の6と9を混同してしまう恐れがあるため、回転角度は-50~50度としました。テストデータを見ると数字の一部しかないような悪質な画像もありますが、今回はなるべく画像ははみ出さないよう、左右、上下のスライド幅も調整してします。
# ImageDataGenerator設定
GenTrain = ImageDataGenerator(
featurewise_center=False, # データセット全体で,入力の平均を0に調整
samplewise_center=False, # 各サンプルの平均を0に調整
featurewise_std_normalization=False, # 入力をデータセットの標準偏差で正規化
samplewise_std_normalization=False, # 各入力をその標準偏差で正規化
zca_whitening=False, # ZCA白色化のイプシロン
rotation_range=50, # 回転角度(-50~50度)
width_shift_range=0.3, # 左右のスライド幅
height_shift_range=0.2, # 上下のスライド幅
zoom_range=[1.0,1.5], # 拡大・縮小率
horizontal_flip=False, # 水平反転しない
vertical_flip=False) # 垂直反転しない
ImageDataGeneratorが吐き出すサンプル画像
上記の設定においてImageDataGeneratorが吐き出す画像を確認したところ、以下のように回転、拡大・縮小、左右・上下スライドなどができています。数字がハミ出ていないし、文字潰れも少ないことが確認できたので、これらを使って学習していきます!



➍MNISTデータ整理
MNISTで共有されているデータは、学習データ60,000個、テストデータ10,000個です。
今回は学習データの中からバリデーション用に2割を分別したいと思います。
・学習データ (60,000)─┬─学習データ (48,000)
│
└─バリデーションデータ(12,000)
・テストデータ(10,000)
➎ネットワーク定義
今回は学習データのバリエーションをもっと増やすので、複雑なものも扱えるようにネットワーク定義を少し調整してみました。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 64) 640
_________________________________________________________________
activation (Activation) (None, 28, 28, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 64) 36928
_________________________________________________________________
activation_1 (Activation) (None, 28, 28, 64) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 64) 36928
_________________________________________________________________
activation_2 (Activation) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 14, 14, 64) 36928
_________________________________________________________________
activation_3 (Activation) (None, 14, 14, 64) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 7, 7, 128) 73856
_________________________________________________________________
activation_4 (Activation) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 64) 401472
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 587,402
Trainable params: 587,402
Non-trainable params: 0
_________________________________________________________________
➏学習結果
学習データ48,000個、イテレーション数100回、バッチ数480個、epoc数200回(200回繰り返し)として学習しました。
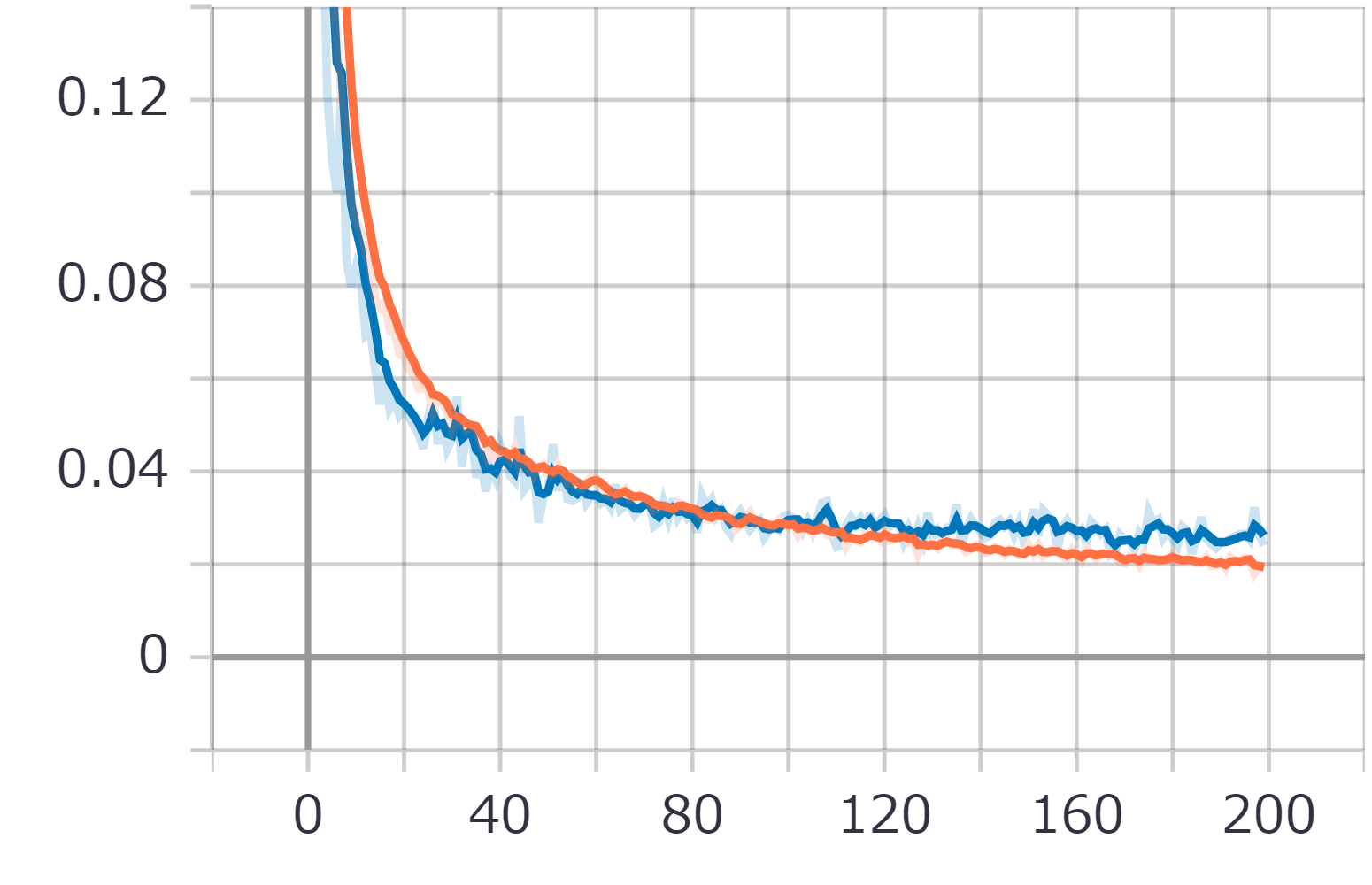
AccutuaryとLossのグラフ
今回入力データを複雑になったのでepoc数も200と大幅に増加させていますが、少し過学習傾向になっていました。

MNISTのTESTデータで検証した結果
ImageDataGeneratorを用いて汎化学習させたあと、MNISTのTESTデータを使用して評価(Evaluate)を行いました。結果は、以下の通りとなり、汎化学習させた結果としては、なかなか良いのではないでしょうか。
Test loss : 0.026212161406874657
Test accuracy: 0.9926000237464905
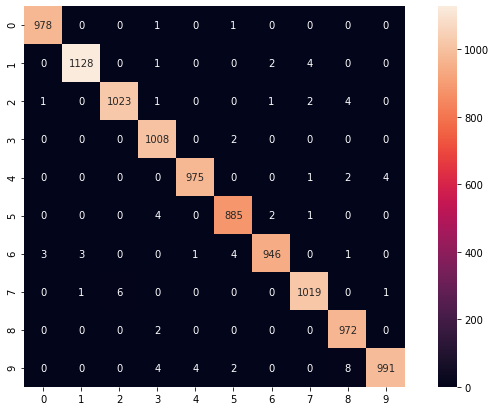
Confusion Matrixのヒートマップ
MNISTが用意した10,000個のテストデータを推測させ、ヒートマップを作成しました。ほぼ正解なので、左上から右下へ向かってのみ色がついています。ここの数字の意味合いとしては、例えば、「5と推測し、本当に5でした」というのが885個、「2と推測したけど、本当は7でした」というのが6個、「8と推測したけど、本当は9でした」というのが8個あったというのが分かります。
・縦軸:正解ラベル
・横軸:推測ラベル
誤認識データ一覧
MNISTが用意した10,000個のテストデータを推測させ、誤りのみを抽出しました。
誤りの結果を見てみると、人間でも判断が分かれそうなものが結構ありますね😅
・左上の黄色数字:正解ラベル
・右下の赤色数字:AIが推測したラベル
NG count : 74個 / 10,000個

誤認識した結果を見ると、もう少し頑張れる余地はあるものの、MNISTのテストデータで、認識率100%を取ろうというのはナンセンスだということが分かりました。
➐改善効果確認
ということで、まだまだ改善の余地はありそうですが、本番はここからです!
さっそく先程誤認識したものが改善しているか、ImageDataGeneratorを利用して学習させたモデルを使用して、汎化性能がUPっぷしたのかを確認していきます。
改善効果サンプル
(1) 正しく認識:6と勘違いしていたものが、正しく1と認識
問題ないッスね!
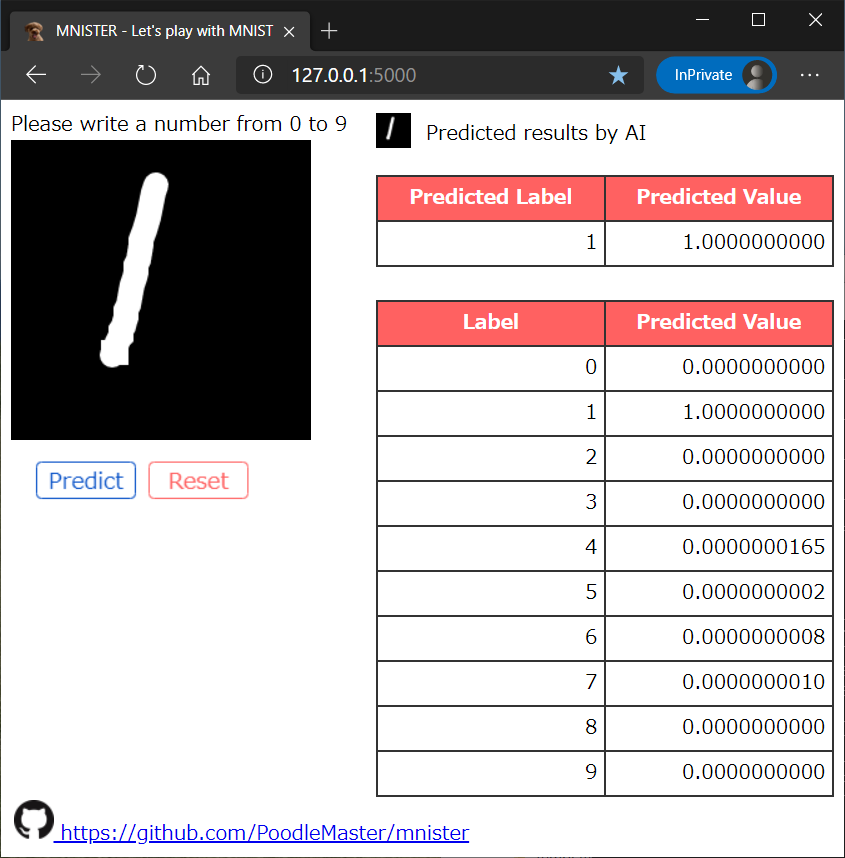
(2) 正しく認識:7と勘違いしていたものが、正しく2と認識
回転もかなり強くなりました!!
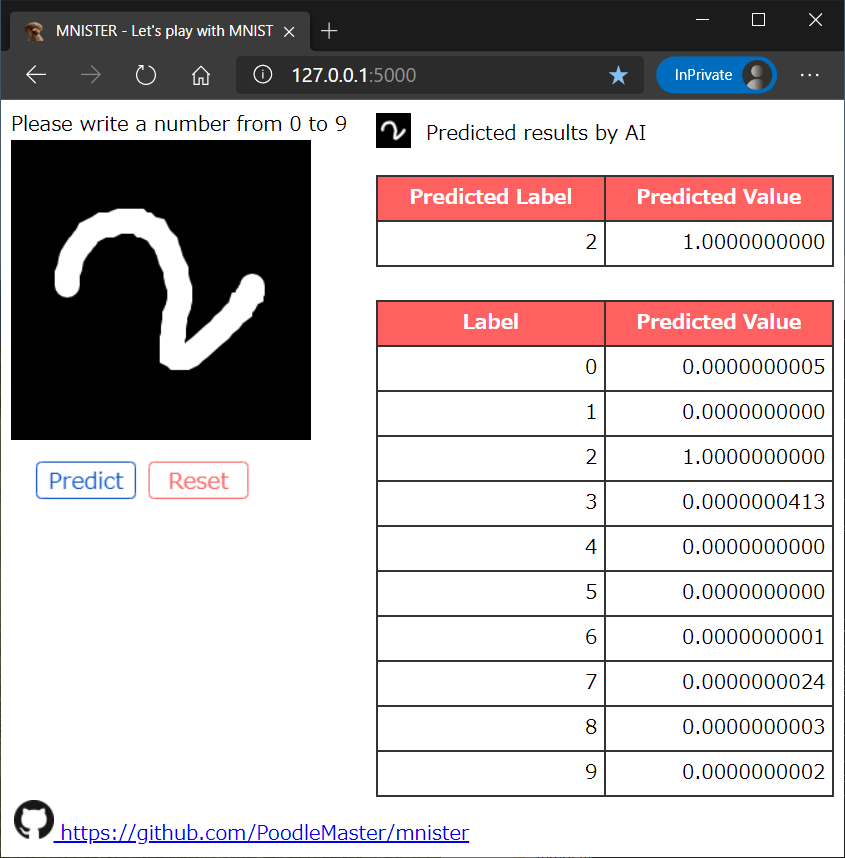
(3) 正しく認識:2と勘違いしていたものが、正しく7と認識
縮小や位置移動などにもかなり強くなりました!
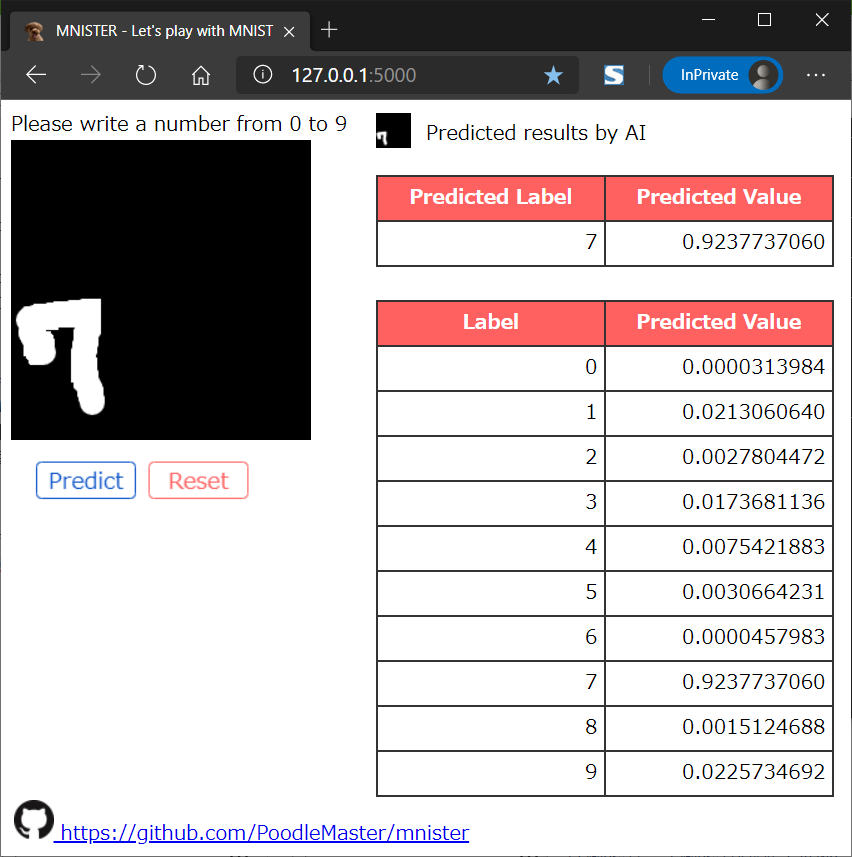
結果
結果は、先程のもの程度ならバッチリ改善されました!
他にも色々と手書き文字で試しましたが、今回のImageDataGeneratorにより、かなり汎化性能がUPっぷしたことが分かりました😄
➑ソースコード
(1) 今回のソースコード (MNIST_ImageDataGenerator)
今回のImageDataGeneratorを利用したモデル作成のソースコードは、以下のGitHubで公開しております。ご参考ください。
Github : https://github.com/PoodleMaster/MNIST_ImageDataGenerator


(2) mnisterツール
Browserで手書きの文字を入力できるツール(低認識のモデル付き)です。モデルを差し替えて遊んでください。こちらは『【MNIST】自分の数字をAIに認識させよう』の記事で公開しておりますので、よろしければご利用ください。ソースコードは、以下のGitHubで公開しております。
➒以上
自分で書いた数字をきちんと認識してくれるとなんだか嬉しくなりますよね。
お疲れ様でした!