「赤りんご」と「青りんご」を見分けるだけの簡単なものですが、はじめて自分の用意した画像で深層学習をしてみました。
こんな感じ
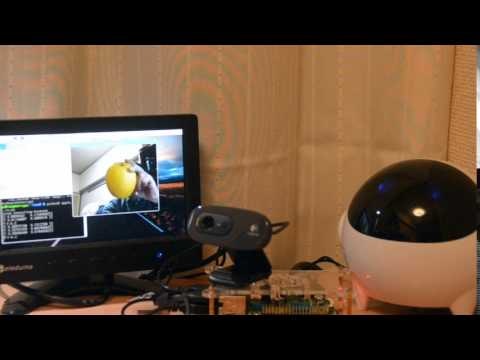
Deep Learning Apple Recognition - YouTube
「赤りんご」と「青りんご」を見分けます。

まずは「青りんご」から、確率91.4%と推測しました。

続いて「赤りんご」、確率91.1%と推測しています。
今回は推測結果が90%以上で「赤りんご」と「青りんご」を判定しています。りんごがない時に(例えば私の丸顔を写した場合)80%の推測がされた際は、判定結果が出ない様にしています。
環境
前回記事と同様です。
学習の流れ
- Web上から画像をダウンロードする
- ダウンロードした画像を
NumPy配列にし、訓練データとテストデータに分ける - 畳み込みニューラルネットワークで学習する
- OpenCVで撮影した画像を
NumPy配列にし推測データとして使用する
基本的な流れは、書籍「 Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう - クジラ飛行机(著) 」の第7章「7-3牛丼屋のメニューを画像判定しよう」を参考にさせて頂きました。
1〜3はMacで行い、4はRaspberryPiで行います。さて、少し詳しくまとめてみます。
1. Web上から画像をダウンロードする
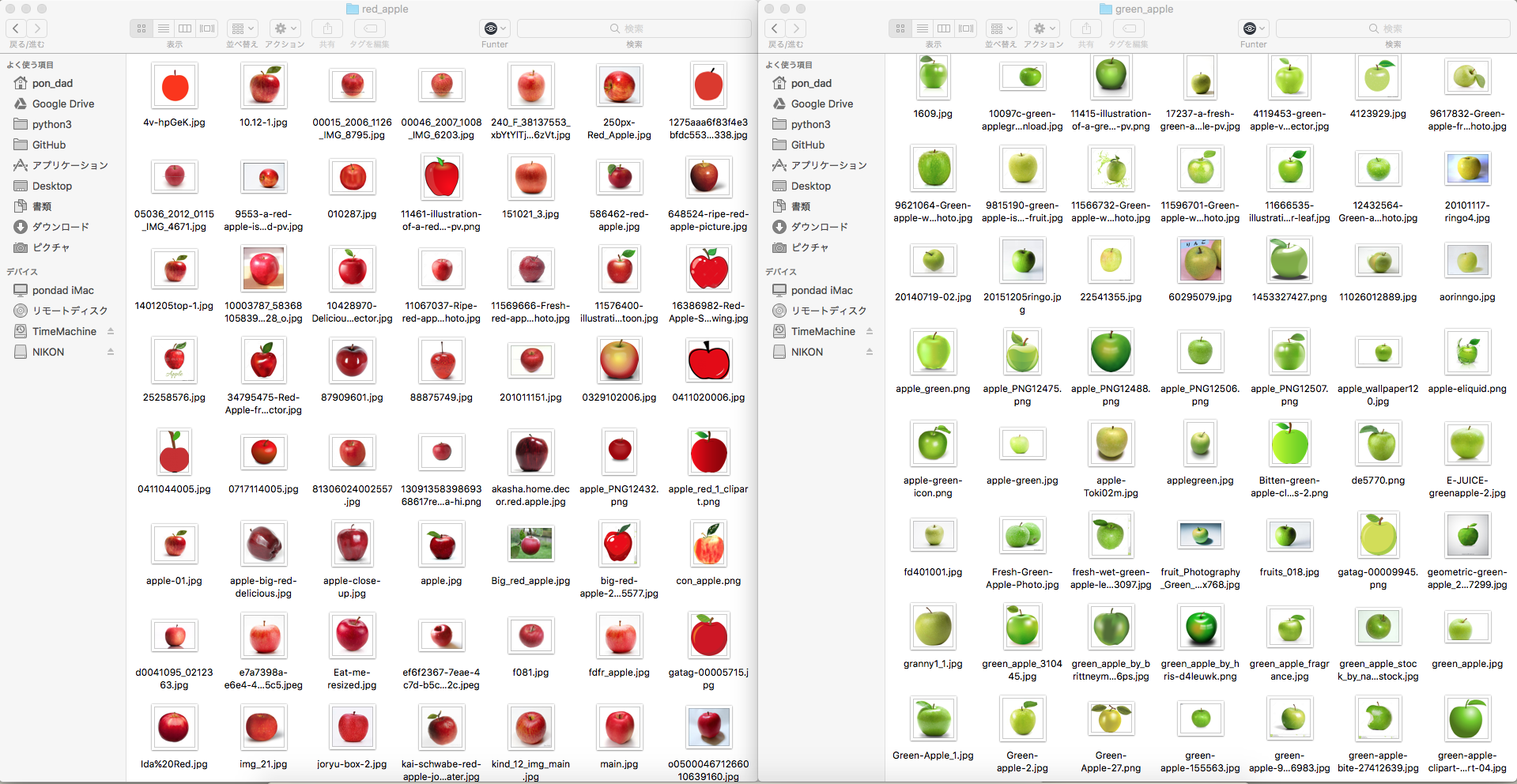
Web上からのクローリングはこちらのコードを利用させて頂きました。
TomoProg/HatenaBlog/python/web_crawler.py - GitHub
クローリング先に負担をかけない様に3秒おきに実行するようになっています。特に画像の大きさの変更などは行わずred_appleフォルダに100枚、green_appleフォルダに100枚保存しました。
一部りんごが複数あったり学習に向かないものは手作業で削除しました。
2. ダウンロードした画像をNumPy配列にし、訓練データとテストデータに分ける
ダウンロードした画像は今回は32×32ピクセルに縮小して畳み込みニュラルネットワークで学習させます。

CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
ちょうどこの図が同じ大きさなので引用させて頂きます。カラー画像(RGB3チャンネル)を維持したまま学習させなければなりません。
最初ここで躓いてしまったんですが、ここでカラー画像の3チャンネルを1チャンネルにしてしまうと、カラー画像の特徴量が消えてしまうんですね。
そこで、RGB3チャンネルを維持したまま配列に格納する必要があります。今回は画像が200枚あるので、200×32×32×3の4次元配列にしなければならないという訳です。
上述の書籍では、enumerate()メソッドを使ってforループで画像データを格納していく方法が紹介されていました。
サンプルではPILを利用してNumPy配列に変換していましたが、Kerasのメソッドでkeras.preprocessing.imageという便利なものがあるので、今回はそちらを使いました。
格納後のNumPy配列はこんな風になっています。
[[[[ 255. 255. 255.]
[ 255. 255. 255.]
[ 255. 255. 255.]
...,
[ 255. 255. 255.]
[ 255. 255. 255.]
[ 255. 255. 255.]]
略
[[ 255. 255. 255.]
[ 255. 255. 255.]
[ 255. 255. 255.]
...,
[ 255. 255. 255.]
[ 255. 255. 255.]
[ 255. 255. 255.]]]]
4次元配列になっているのが分かると思います。
これをscikit-learnのcross_validationメソッドを利用して訓練データとテストデータに分けます。今回は訓練ラベル、テストラベルはred_appleと green_appleの2種類だけです。
ここでは一旦分けた訓練データ、テストデータ、訓練ラベル、テストラベルをapple.npyというファイルにしています。
3. 畳み込みニューラルネットワークで学習する
さて、学習する前にもう一つ事前準備が必要になります。
float型に変換したのち、RGBの色調(0〜255)を正規化します。
[[[[ 0.9921875 0.9921875 0.9921875 ]
[ 0.99609375 0.99609375 0.99609375]
[ 0.9921875 0.9921875 0.9921875 ]
...,
[ 0.99609375 0.99609375 0.99609375]
[ 0.99609375 0.99609375 0.99609375]
[ 0.99609375 0.99609375 0.99609375]]
略
[[ 0.9921875 0.984375 0.99609375]
[ 0.9921875 0.984375 0.99609375]
[ 0.99609375 0.98828125 0.99609375]
...,
[ 0.99609375 0.98828125 0.99609375]
[ 0.99609375 0.98828125 0.9921875 ]
[ 0.99609375 0.98828125 0.9921875 ]]]]
これにより推測結果を割合で得ることが出来ます。(詳細後程)
さて、これで準備はOKです。Kerasのメイン開発者(たまに日本語で呟くイカした人)のサンプルコードを利用して畳み込みニューラルネットワークで学習させます。
fchollet/keras/examples/cifar10_cnn.py
今回は画像が単純なこともありnb_epoch=10で設定しました。学習結果はiMacで10秒程です。
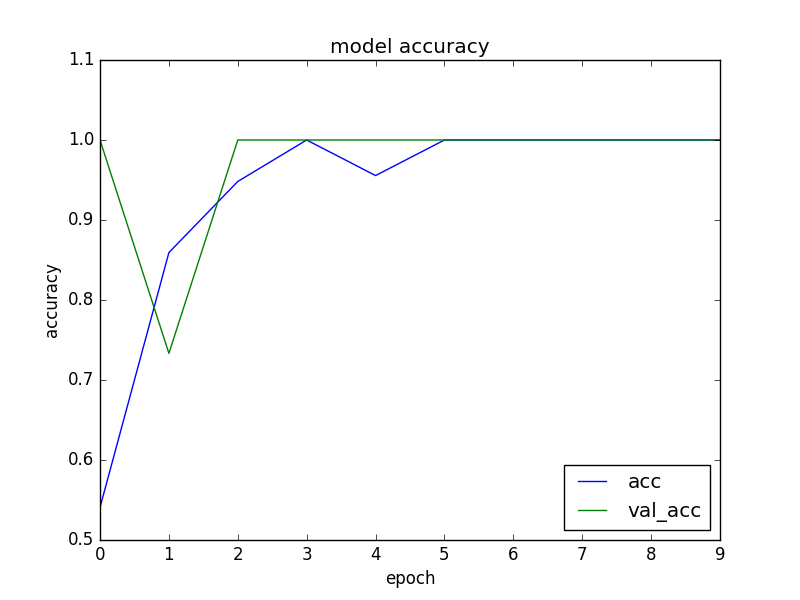
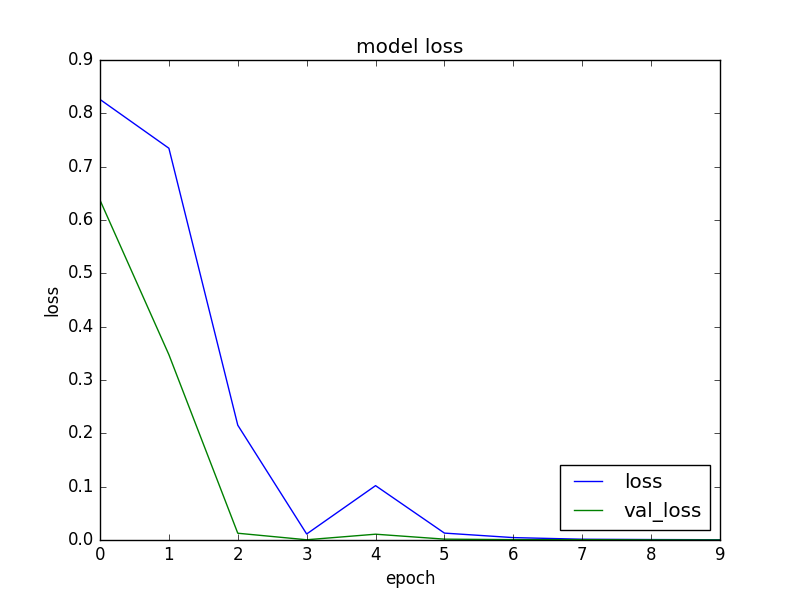
$ python3 apple_keras.py
Using TensorFlow backend.
loss= 6.48597096733e-05
accuracy= 1.0
正解率100%になりました。まあ、今回は赤と緑のりんごを分けるだけなので、間違えようもないのかなと思います。ちょっと不安になりますが、過学習も起きていないのでこのまま進めます。
学習結果をh5ファイルに保存できたら、MacからRaspberryPiにデータを移動します。
4. OpenCVで撮影した画像をNumPy配列にし推測データとして使用する
今回は、RaspberryPiで撮影した画像を、学習した時と同じようにNumPy配列に変換することで、推測データとして利用することにします。
「青りんご」を撮影した画像はこのようなNumPy配列に格納されます。
[[[[ 0.0625 0.078125 0.09375 ]
[ 0.140625 0.05859375 0.0859375 ]
[ 0.203125 0.1328125 0.11328125]
...,
[ 0.9140625 0.984375 0.96875 ]
[ 0.9140625 0.9765625 0.97265625]
[ 0.84765625 0.93359375 0.96875 ]]
略
[[ 0.2734375 0.25390625 0.390625 ]
[ 0.51953125 0.15625 0.2578125 ]
[ 0.0390625 0.0390625 0.0390625 ]
...,
[ 0. 0.0078125 0.00390625]
[ 0.015625 0.01171875 0.0390625 ]
[ 0.09765625 0.0859375 0.1171875 ]]]]
これを学習済みデータを元に、Kerasのmodel.predict(X)メソッドを使いラベルを推測します。
$ python3 apple_checker_cv.py
Using TensorFlow backend.
[[ 0.00830923 0.99169075]]
青りんご
今回ラベルは2種類だけ["赤りんご", "青りんご"]なので、学習結果は
"赤りんご" = [1, 0]
"青りんご" = [0, 1]
の2次元配列で判定出来ます。学習させる時にsoftmax関数を利用しているので、推測結果が正規化された形で返ってきます。
青りんごを撮影した際は[[ 0.00830923 0.99169075]]こんな配列が返ってきます。「赤りんご0.8%」、「青りんご99.1%」と推測出来るわけですね。
これを利用して推測した値が0.9以上であれば「赤りんご」「青りんご」であると判定する様にしてみました。前回と同じくOpenJTalkで話させて完成です。
まとめ
画像の大きさを32ピクセル、枚数を100枚ということで、本当に特徴量が抽出出来るのか謎だったのですが、対象が単純だったこともあり予想以上の精度で分類・認識することが出来ました。
同じパターンで顔識別も出来そうなので、今度試してみたいと思います。ではまた。