ブラウザ経由でRaspberry Piと会話してみました。
環境
- Raspberry Pi2 ModelB (raspbian-wheezy・Node.js v4.2.4)
- PLANEX 無線LAN子機 (USBアダプター型) GW-USNANO2A (FFP)
- サンワサプライ USBスピーカー(ブラック) MM-SPU8BK
- ASUS Chromebook C300MA-WHITE
こちらからの発話認識はRaspberry Piでは行わず、HTML5のWeb Speech Recognized API を利用します。Androidがあれば良いのですが持ち合わせがないので今回はChromebookを利用しました。
(もちろんMac、PCのChromeブラウザから利用出来ます。というかChromeしか対応していません。)
インストールなど
基本前回投稿(Raspberry Pi をNode.jsを使ってブラウザから喋らせる。)と一緒です。
パッケージとして、express・ejs・voicetext・node-aplayをインストールします。ファイル構成も一緒です。
Raspberry Piで合成音声を喋らせる。
var express = require('express');
var ejs = require("ejs");
var VoiceText = require('voicetext');
var Sound = require('node-aplay');
var fs = require('fs');
var app = express();
app.engine('ejs',ejs.renderFile);
app.get('/', function(req, res){
res.render('talk.ejs',
{title: 'Raspberry Pi Talk2'});
})
var voice = new VoiceText('uyxo9fc20r3bjp12');
app.get('/control', function (req, res) {
var text = req.query.text ? req.query.text : "";
console.log("Server:" + text);
var name = "ポンダッド"
if(text == "はじめまして"){
text = "はじめまして、わたしはラズベリーパイって言います。"
}else if(text == "私は誰"){
text = name + "さんですね。よろしくね"
}else if(text == "頑張れよ"){
text = name + "お前も、頑張れよ。"
}
var speaker = req.query.speaker ? req.query.speaker : voice.SPEAKER.HARUKA;
var emotion = req.query.emotion ? req.query.emotion : voice.EMOTION.HAPPINESS;
var emotion_level = req.query.emotion_level ? req.query.emotion_level : voice.EMOTION_LEVEL.LOW;
var pitch = req.query.pitch ? req.query.pitch : 100;
var speed = req.query.speed ? req.query.speed : 100;
var volume = req.query.volume ? req.query.volume : 100;
voice.speaker(speaker)
.emotion(emotion)
.emotion_level(emotion_level)
.pitch(pitch)
.speed(speed)
.volume(volume)
.speak(text, function(e, buf){
return fs.writeFile('./talk.wav', buf, 'binary', function(e){
if(e){
return console.error(e);
}
new Sound('talk.wav').play();
})
});
res.send(text);
});
var server = app.listen(3000, function () {
var host = server.address().address
var port = server.address().port
console.log('This app running at http://192.168.0.12:'+ port)
});
前回投稿とほとんど変わっていません。ただGoogleの音声認識の癖に合わせてキーワード登録を少し変更しました。(「ポンダッド」って何回言っても認識してくれませんでした…「本だど」とか「本that」とかそんな感じです。)
日本語の認識指定をする場合は漢字で書き変えてくれるので、もしキーワード登録する際は漢字・ひらがな両方指定しておくと良いかもしれません。
ブラウザで音声認識させる
<!DOCTYPE html>
<html lang="ja">
<head>
<meta http-equiv="content-type"
content="text/html; charset=UTF-8">
<title><%=title %></title>
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/css/bootstrap.min.css" type="text/css" />
<link rel="stylesheet" href="https://maxcdn.bootstrapcdn.com/font-awesome/4.5.0/css/font-awesome.min.css">
<style>
article{
margin: 20px;
}
</style>
</head>
<body>
<header>
<h1 class="text-center h2"><%=title %></h1>
</header>
<article>
<div id="buttons" class="text-center">
<button id="recBtn" class="btn btn-default btn-lg fa fa-microphone"> マイク 開始</button>
</div>
</article>
<script src="http://ajax.googleapis.com/ajax/libs/jquery/1.4.2/jquery.min.js"></script>
<script>
$(document).ready(function() {
var rec;
var nowRec = false;
var rec = new webkitSpeechRecognition();
rec.continuous = true;
rec.interimResults = false;
rec.lang = 'ja-JP';
rec.onresult = function(e) {
for (var i = e.resultIndex; i < e.results.length; ++i) {
if (e.results[i].isFinal) {
var msg = e.results[i][0].transcript;
msg = msg.replace(/^\s+/g, "");
console.log("Recognised :" + msg);
$.get("http://192.168.0.12:3000/control",{text:msg}, function(data){console.log('Send :' + data);});
};
};
};
$("#recBtn").click(function() {
if(nowRec){
rec.stop();
$(this).attr("class","btn btn-default btn-lg fa fa-microphone");
$(this).text(" マイク 開始");
nowRec = false;
}else{
rec.start();
$(this).attr("class","btn btn-danger btn-lg fa fa-microphone");
$(this).text(" マイク 停止");
nowRec = true;
}
});
});
</script>
</body>
</html>
Web Speech Recognized APIは必要最低限の部分しか記述していません。録音の進捗状況などを確認しない場合はrec.onresult = function(e){ }だけ指定すれば大丈夫です。
WC3のドキュメントに従って記述すれば、「録音」→「候補一覧を検索」→「一番可能性の高いものを選択」までAPIがやってくれるので、その結果をGETで飛ばすだけです。
一つだけ細かいところなのですが、日本語で音声認識する際には必ずエスケープ処理をしておいた方が良さそうです。(エスケープしないと文字列の前にスペースができてしまい、キーワードと一致させようとするとエラーになってしまいます。)
こんな感じ
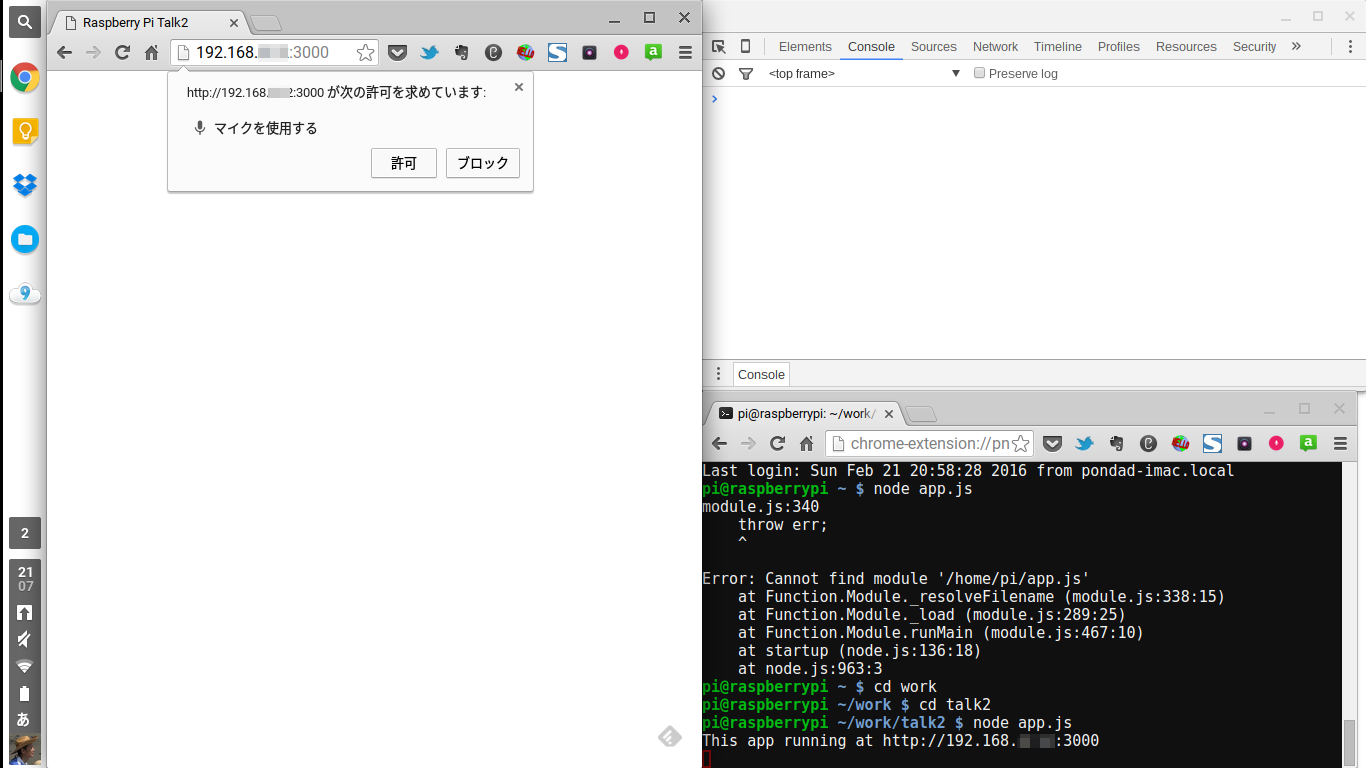
指定アドレスに接続後、マイクの接続許可を求められますので許可してください。(rec.continuous = true; の指定をしておくと認識が継続するので便利です)
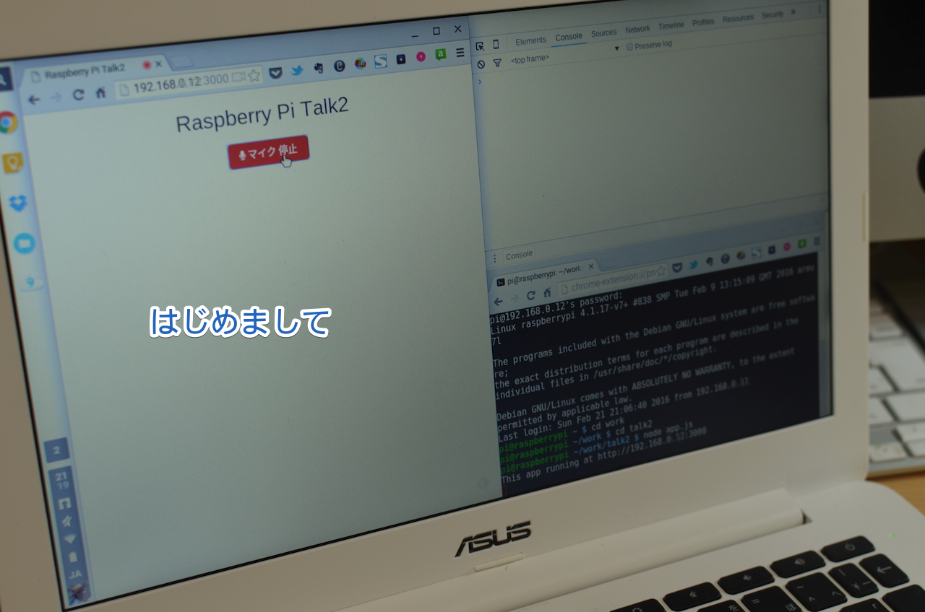
「はじめまして」

「はじめまして、私はラズベリーパイっていいまあす。(アニメ声)」
(今日一日中こんなことをしていたら娘 ※双子・4歳 が「ママ〜!パパがなんかおんなの子と、おはなししてる〜!」と蔑むような視線を浴びせてきました。どうしようもないですね。)
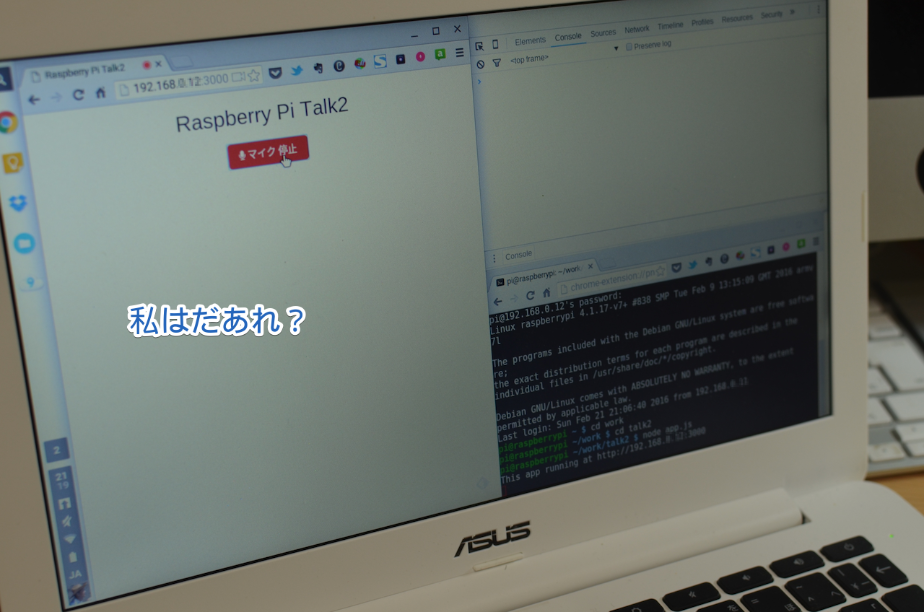
「私は誰」

「ポンダッドさんですね。よろしくね〜。(アニメ声)」
(以下略)
音声認識をコンソールとSSHから見るとこんな風になります。
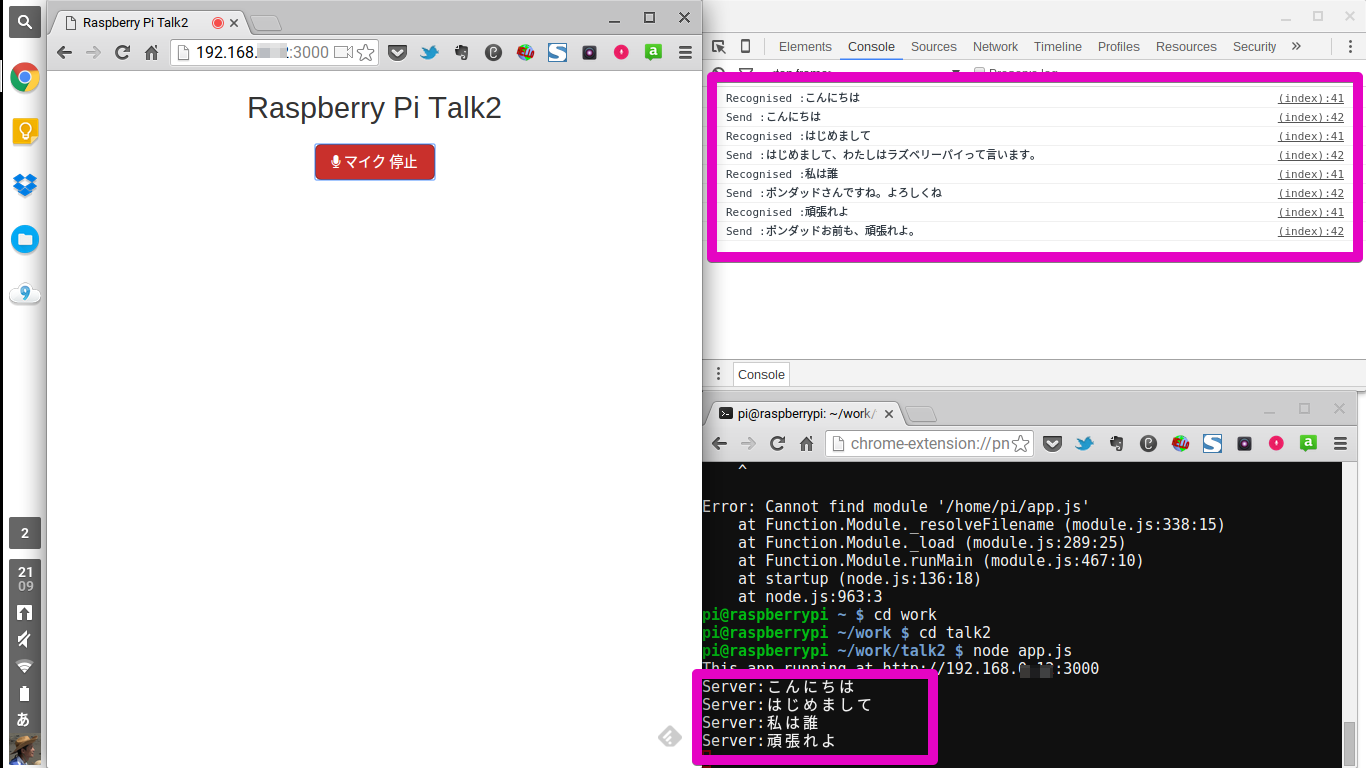
一応、「音声認識結果」「送信結果」「受信結果」はコンソールで確認できるようにしておきました。
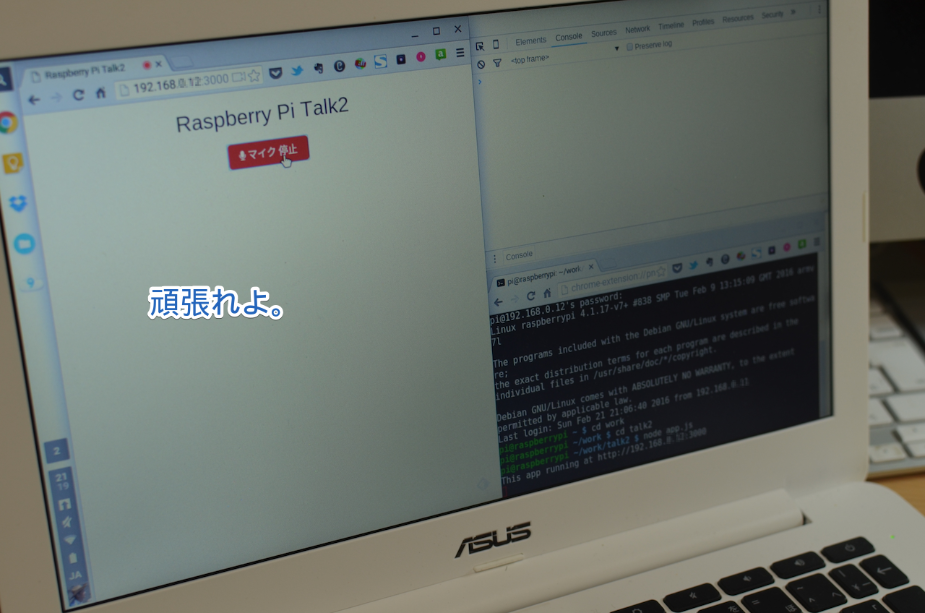
最後に「頑張れよ」とか言ってみます。

…。(終わり)