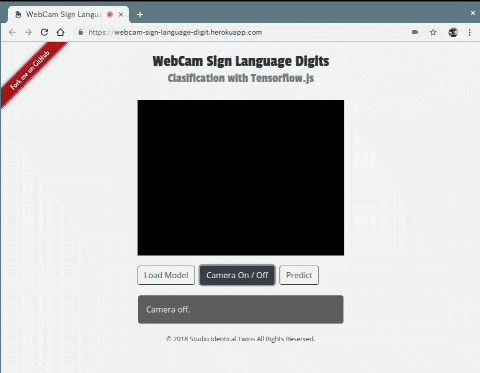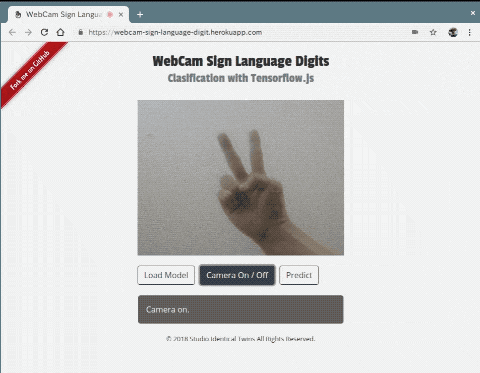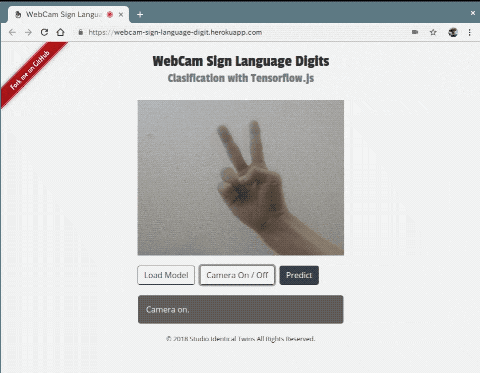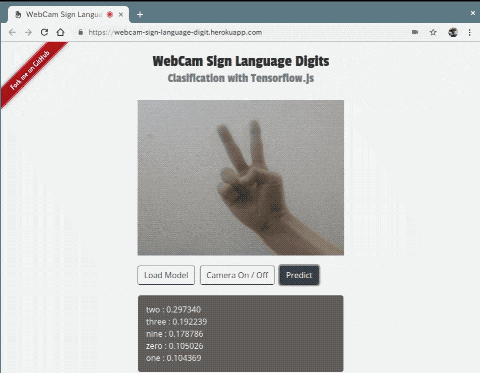
ブラウザのGPUを利用してディープラーニングを実行できるライブラリTensorflow.jsを利用して手話数字を認識させてみました。こんな感じ。
デモ: Webcam Sign Language Digit Classification with TensorFlow.js
学習済みモデルをブラウザにアップロードすることで、ウェブカメラから手話画像を識別することができます。デモはHerokuの無料枠で公開してみました。

手話数字のデータセットはSign Language Digits Dataset - Kaggleより、0~9までの手話画像2,000枚(各200枚)を使いVGG16モデルを使い学習させています。
学習モデル作成はPython3+Kerasで行い、JavaScriptで読み込み可能な形式にコンバート(変換)します。その学習モデルを使いTensorFlow.jsとブラウザで推論をおこなう仕組みです。
今回は「前編:Python編」でデータセットを利用した学習モデルの作成・変換を、「後編:Node.js編」で学習済モデルを利用したブラウザでの推論方法をまとめます。
環境
- GoogleColaboratory(python3/tensorflow v1.7.0)
- Node.js v8.11.1
画像枚数はそれ程多くないのですが、6層の畳込みニューラルネットワーク(VGG16モデル)で学習させるため、TensorFlow-GPUが利用できるPythonの環境が望ましいです。
前編:Python編
今回は無料でクラウドGPUを使用できるGoogleColaboratoryを使います。また、モデル作成に関してはKerasの作者Francois Cholletさんの著書1を参考にしました。
ノートブック: 4_webcam_sign_language_digits_classification - GitHub
データセット: Sign-Language-Digits-Dataset - GitHub
GoogleColaboratory
Colaboratoryは、機械学習の教育や研究の促進を目的に公開されているGoogle研究プロジェクトで、クラウドで実行されるJupyterノートブックを利用することができます。
機械学習に必要となるPythonライブラリのインストールが不要であり、また層の厚いディープラーニングで必要となるGPUを利用した学習をクラウドで行うことができます。なんと驚くこと無料です。
Colaboratoryへの画像アップロード
まず大量の画像をアップロードする方法まとめます。ここではColaboratoryに直接画像をアップロードする方法を紹介します。
まずは「上メニュー>ランタイムのタイプを変更」で「ハードウェアアクセラレータ>GPU」に設定し、「接続」をクリックします。
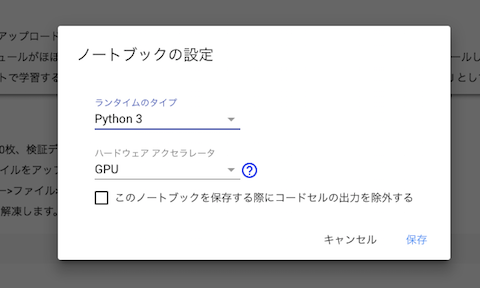
分かりづらいのですが、画面左にある矢印キーをクリックすると左メニューが現れます。
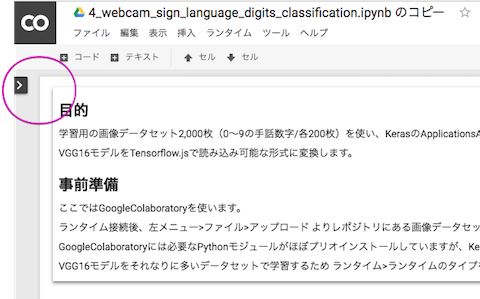
ランタイム接続するとColaboratoryのファイルが参照可能になります。「左メニュー>ファイル>アップロード」より画像をアップロードすることが可能になります。
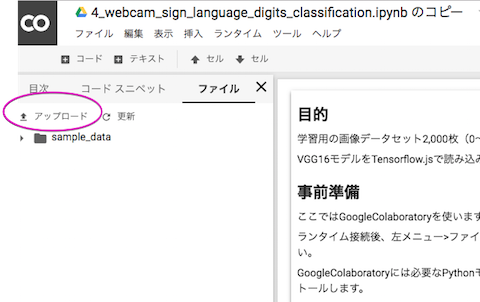
100x100ピクセルの画像約2,000枚で約30MBになりました。zipファイルに圧縮後アップロードしてください。アップロード後「更新」クリックでファイルを確認することができます。
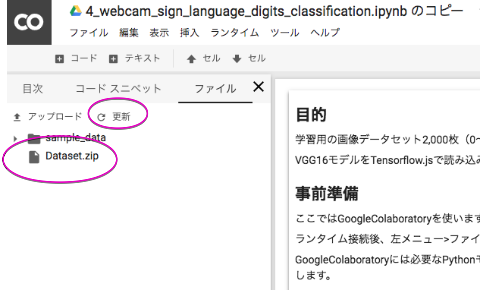
Colaboratoryでlinuxコマンドを使用する際は!を頭につけて実行します。
!unzip Dataset.zip
これでzipファイルを解凍することができました。
画像の前処理
ディープラーニングで画像を学習可能にするには、RGB画素を計算可能なNumPy形式のテンソルに変換しなければなりません。Kerasでは便利なメソッドImageDataGeneratorが用意されており、フォルダ分けされた訓練画像セット・検証デーセットを自動的にNumPy形式のデータに変換し、学習器で読み込むことができます。
そこで画像データセットをクラス毎に訓練データ・検証データに振り分ける必要があります。(学習後のテストデータは必須ではありませんが推論のテスト用に前処理段階で一緒に作成しておきましょう)
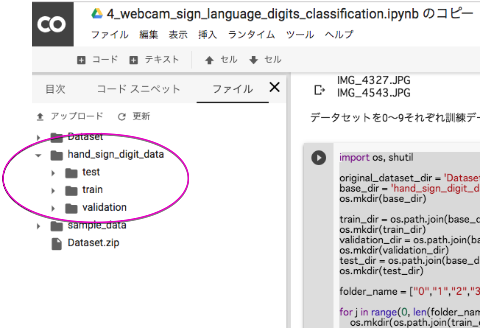
hand_sign_digit_data
├── test
│ ├── 0
│ ├── 1
│ ├── 2
│ ├── 3
│ ├── 4
│ ├── 5
│ ├── 6
│ ├── 7
│ ├── 8
│ └── 9
├── train
│ ├── 0
│ ├── 1
│ ├── 2
│ ├── 3
│ ├── 4
│ ├── 5
│ ├── 6
│ ├── 7
│ ├── 8
│ └── 9
└── validation
├── 0
├── 1
├── 2
├── 3
├── 4
├── 5
├── 6
├── 7
├── 8
└── 9
このような画像の階層分けが必要になります。振り分けのスクリプトの例は以下のようになります。
import os, shutil
original_dataset_dir = 'Dataset'
folder_name = ["0","1","2","3","4","5","6","7","8","9"]
for j in range(0, len(folder_name)):
print (folder_name[j])
files = os.listdir(original_dataset_dir + "/" + folder_name[j] + "/")
for i in range(0, len(files)):
print (files[i])
root, extension = os.path.splitext(files[i])
if files[i] == ".DS_Store":
print("This is no image.")
elif extension == ".png" or ".jpeg" or ".jpg":
shutil.move(original_dataset_dir + "/" + folder_name[j] + "/" + files[i], original_dataset_dir + "/" + folder_name[j] + "/" + folder_name[j] + "_" + str(i + 1) + ".jpg")
print("Rename Done.")
まずはshutilモジュールを使いフォルダ内のバラバラな画像名IMG_1118.JPGなどをフォルダごとの連番0_153.jpgなどの様な名前に変更します。ここでは10クラスですがfolder_nameの配列を変更すれば何クラスでも自動に変更できます。
mport os, shutil
original_dataset_dir = 'Dataset'
base_dir = 'hand_sign_digit_data'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
folder_name = ["0","1","2","3","4","5","6","7","8","9"]
for j in range(0, len(folder_name)):
os.mkdir(os.path.join(train_dir, folder_name[j]))
os.mkdir(os.path.join(validation_dir, folder_name[j]))
os.mkdir(os.path.join(test_dir, folder_name[j]))
fnames = [folder_name[j] + '_{}.jpg'.format(i) for i in range(1,101)]
for fname in fnames:
src = os.path.join(original_dataset_dir, folder_name[j], fname)
dst = os.path.join(train_dir, folder_name[j], fname)
shutil.copyfile(src, dst)
fnames = [folder_name[j] +'_{}.jpg'.format(i) for i in range(101, 151)]
for fname in fnames:
src = os.path.join(original_dataset_dir, folder_name[j], fname)
dst = os.path.join(validation_dir, folder_name[j], fname)
shutil.copyfile(src, dst)
fnames = [folder_name[j] +'_{}.jpg'.format(i) for i in range(151, 201)]
for fname in fnames:
src = os.path.join(original_dataset_dir, folder_name[j], fname)
dst = os.path.join(test_dir, folder_name[j], fname)
shutil.copyfile(src, dst)
print("Data generate Done.")
訓練データ・検証データ・テストデータの枚数を指定してフォルダごとに振り分けします。ここではデータセットを0〜9それぞれ訓練データ100枚、検証データ50枚、テストデータ50枚に振り分けしました。
ここでは10クラスですがfolder_nameの配列を変更すれば何クラスでも自動でフォルダ分けできます。また枚数の調整はループ処理range()の数字を変更してください。
これで画像の前処理ができました。
VGG16モデルでの学習
学習モデルはKerasのチュートリアルにあるVGG16モデルをそのまま使いました。GPUを使い通常の学習をおこないます。
ひとつColaboratoryでKeras.jsモデルを作成するときに注意点があります。Colaboratoryには機械学習に必要なライブラリは一通りインストールされていますが、tensorflowjsライブラリは手動でインストールしなければなりません。さらにTensorFlov 1.7.0が必要になります。
!pip3 install tensorflow==1.7.0
!pip3 install keras
!pip3 install tensorflowjs
この様にインストールしてください。
import keras
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import tensorflowjs as tfjs
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(100, 100, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['acc'])
classes = ['zero', 'one', 'two', 'three', 'four',
'five', 'seven', 'eight', 'nine']
train_dir = 'hand_sign_digit_data/train'
validation_dir = 'hand_sign_digit_data/validation'
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(100, 100),
batch_size=32,
class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(100, 100),
batch_size=32,
class_mode='categorical')
history = model.fit_generator(
train_generator,
steps_per_epoch=50,
epochs=70,
validation_data=validation_generator,
validation_steps=25)
model.save('sign_language_vgg16_1.h5')
今回は他クラス分類のため、ImageDataGeneratorのclass_modeを'categorical'で指定します。拡張機能を使い訓練データ1,000枚から32バッチ毎に水増しした新たな画像を生成するように指定しました。
全結合層はlayers.Dense(10, activation='softmax')とし、10クラスを活性化関数softmaxで分類します。
モデルの損失関数lossは'categorical_crossentropy'、オプティマイザoptimizerは'adam'としました。
モデル訓練はsteps_per_epoch=50(バッジサイズ32で1エポック当たり50枚の訓練画像生成)、validation_steps=25(バッジサイズ32で1エポック当たり25枚の検証画像)と指定し、epochs=70で学習します。
モデルの推論用に sign_language_vgg16_1.h5 をダウンロードします。(これはTensolFrow.jsには使いません)
訓練データ、検証データの推移をグラフで確認します。
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
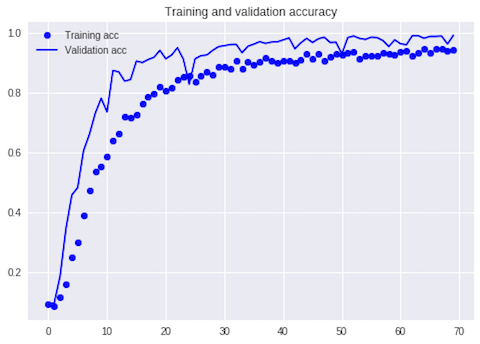
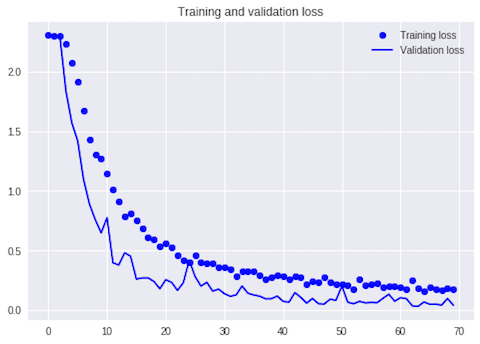
検証データのロス率が上がっていないので過学習していないことが分かります。
TensorFlow.js用コンバーターモデルの作成
ようやく本番です。TensorFlow.js用の変換モデルを作成します。tfjs.converters.save_keras_model()というKerasモデルを自動的に変換するメソッドを使います。
save_path = 'sign_language_vgg16'
tfjs.converters.save_keras_model(model, save_path)
print("[INFO] saved tf.js vgg16 model to disk..")
変換されたモデルは以下のようにフォルダで生成されます。
.sign_language_vgg16
├── group1-shard1of2
├── group1-shard2of2
└── model.json
ひとつ注意が必要ですjsonファイルだけでなく、同時に生成された重みファイル(group1-shard1of2など)と合わせて使用するのでフォルダごと保存してください。
Colaboratoryからダウンロードする際はフォルダをzipファイルにしてダウンロードします。
!zip -r sign_language_vgg16.zip sign_language_vgg16
これでTensorFlow.jsが読み込める独自画像を利用した学習済みモデルが手に入りました。次回はこのモデルを使ってカメラ画像を元に推論する仕組みをまとめてみます。
【後編:Node.js編】は以下のサイトの5節「TensorFlow.jsモデルへのコンバート」以降を参照してください。
Tech Book Zone Manatee - 機械学習で遊ぼう! - 第16回 TensorFlow.jsで「じゃんけん」を判別してみよう
-
PythonとKerasによるディープラーニング (出版社:マイナビ出版 / 著者:Francois Chollet / 翻訳:株式会社クイープ / 監訳:巣籠悠輔) ↩