はじめに
今回はTwitterAPI申請編の続きです。
Tweepyを導入して、実際に色々としてみましょう。
Twitter APIの申請まだ終わってないよ、って方は前の記事参照です。
目次
- TwitterAPI申請編
- Tweepy編 ⏪ 今回はココ!
- 形態素解析・Mecab編
- WordCloud表示編
- 最終目標・Tweet可視化編
Tweepyを導入してTwitter APIで遊ぶ準備をする
ここからはPythonにTweepyを導入して、色々遊んでみましょう!
① Pythonのバージョンを確認する
python -V
Python 3.10.6
もし、command not found: pythonが出力された場合、以下のことが考えられます。
- Python自体をインストールしていない
- Python2.xとPython3.xが混在している(Mac等の場合)
2.の場合、以下のコマンドをお試しください。
python3 -V
以降、コマンドが分かれる場合はパターン1, 2と分けて記載します。
② Tweepyを導入
以下のコマンドを入力してTweepyのパッケージをインストールします。
pip install tweepy
pip3 install tweepy
準備はOKです!
次からは実際にコードを書いていきます。
③ APIキーなどをセットする
Tweepyを利用するためにメモしたAPIキーを読み込ませていきます。
コード内に直接記載しても良いのですが、これではGitHub等に上げられないので
.envファイルに記載して、読み込む手順で説明します。
BEARER_TOKEN=メモしたBearer Tokenをペースト
CONSUMER_KEY=メモしたAPI Keyをペースト
CONSUMER_SECRET=メモしたAPI Key Secretをペースト
ACCESS_TOKEN=メモしたAccess Tokenをペースト
ACCESS_TOKEN_SECRET=メモしたAccess Token Secretをペースト
左辺の名前は自由ですが、読み込む際に分かりやすいのでこの名前にしています。
右辺で""や()等で囲まなくて大丈夫です。
そのまま記載でOKです。
次に読み込みです。 以下が読み込みの.pyファイルになります。
from dotenv import load_dotenv
import os
import tweepy
# .envファイルの読み込みが上手く行かない場合
load_dotenv()
BEARER_TOKEN = os.environ.get('BEARER_TOKEN')
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_TOKEN = os.environ.get('ACCESS_TOKEN')
ACCESS_TOKEN_SECRET = os.environ.get('ACCESS_TOKEN_SECRET')
.envファイルに書いた内容はos.environ.get()で取得しています。
os.environ[]でも取得できますが、個人的な好みです。
存在しない名前を指定したときにNoneが返ってくる、Errorになる違いがあります。
もしNoneになった場合、load_dotenv()を記載すると解決します。
pip install dotenvでインストールする必要があります。
ツイートの取得、書き込みをするためにtweepy.Client()に渡していきます。
client = tweepy.Client(
bearer_token=BEARER_TOKEN, # OAuth2.0の場合
consumer_key=CONSUMER_KEY, # OAuth1.0aの場合
consumer_secret=CONSUMER_SECRET, # OAuth1.0aの場合
access_token=ACCESS_TOKEN, # OAuth1.0aの場合
access_token_secret=ACCESS_TOKEN_SECRET, # OAuth1.0aの場合
wait_on_rate_limit=True # Trueにするとレート制限の解除を待つ
)
OAuth2.0を使用している場合、bearer_tokenのみで大丈夫です。
OAtuth1.0aの場合はconsumer_key以降の記載が必要です。
分からない場合は私のように全部書いちゃえばOKです。
全部書かなくて良いとはさっきまで思ってませんでした←
wait_on_rate_limit=Trueは必須ではありません。
API使用にも制限があり、制限になると15分間待つ必要がありますが
そのときに解除されれば自動で続行してくれるようになるため、Trueにしておきます。
ここまでを以下にまとめます。
from dotenv import load_dotenv
import os
import tweepy
# .envファイルの読み込みが上手く行かない場合
load_dotenv()
BEARER_TOKEN = os.environ.get('BEARER_TOKEN')
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_TOKEN = os.environ.get('ACCESS_TOKEN')
ACCESS_TOKEN_SECRET = os.environ.get('ACCESS_TOKEN_SECRET')
client = tweepy.Client(
bearer_token=BEARER_TOKEN, # OAuth2.0の場合
consumer_key=CONSUMER_KEY, # OAuth1.0aの場合
consumer_secret=CONSUMER_SECRET, # OAuth1.0aの場合
access_token=ACCESS_TOKEN, # OAuth1.0aの場合
access_token_secret=ACCESS_TOKEN_SECRET, # OAuth1.0aの場合
wait_on_rate_limit=True # Trueにするとレート制限の解除を待つ
)
④ 遊ぶ(ここからが楽しいところです)
Tweepyでは数多くのことができます。
Twitter API v2 Reference
ユーザー情報の取得、ツイートの取得・送信をここでは試してみたいと思います。
ユーザー情報の取得
以下のclient.get_userを追加するのみです。
user = client.get_user(username="PomericanCoffee", expansions="pinned_tweet_id")
print(user)
usernameには@以降のユーザー名を指定します。
expansions="pinned_tweet_id"を書くことで固定ツイートを取得できます。
Response(data=<User id=1257608554019610626 name=ジャンピングジョーカーポメリ缶コーヒー🤞 username=PomericanCoffee>, includes={'tweets': [<Tweet id=1471797103190245379 text='応用情報技術者試験に合格しましたーーーー!\n三度目の正直です🥰\nやった…やってやったぞーー!\n\n1度も勉強してなかったプロジェクトマネジメントの分野(アジャイルの問題)に試験中に変えた判断が功を奏した😊 https://t.co/Y1QRbHiQml'>]}, errors=[], meta={})
Twitterでの名前と固定ツイートが上手く取れています◎
利用用途は思いつかないです...でも取れて楽しかったので...。
ツイートの送信
client.create_tweetを用いて設定したメッセージをツイートしてみます。
val = '璃果'
client.create_tweet(text=f"国語算数{val}社会")
textにツイートしたい内容を指定します。
文字列内に\nを入れると改行もできますし、上記のように変数を埋め込むことも可能です。
(f"{変数名]"これをf文字列、フォーマット済み文字列リテラルと言います。)
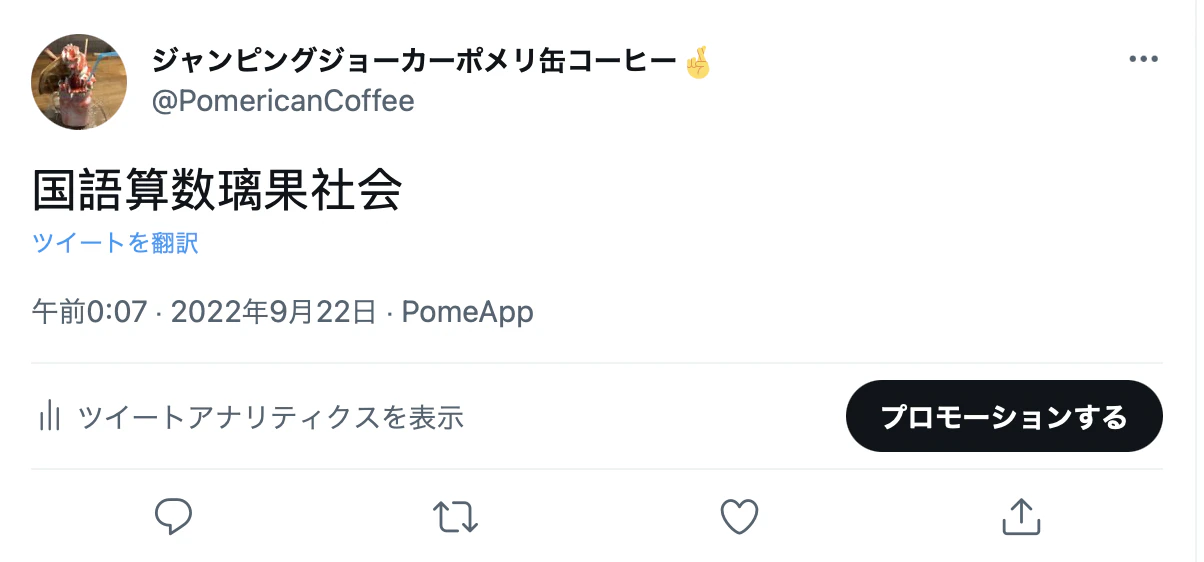
ツイートできました◎
ツイート元は、作成時のアプリ名(PomeApp)が表示されていますね。
ツイートの取得
キーワード検索して、タイムラインからツイートを取得していきましょう。
Twitterで検索するときと同じ感覚でOKです。(lang:jaや-RTなど使えます)
ツイートを取得するだけならclient.search_recent_tweets()で出来ますが、
今回はページネーション処理をするためtweepy.Paginatorで指定していきます。
以下のままでは使用しづらいため、不完全Ver.としています。
説明(備忘)のために1ステップずつコーディングの修正をしていきます。
tweets = tweepy.Paginator(
client.search_recent_tweets,
query='ジャンピングジョーカーフラッシュ -RT',
max_results=10
)
for tweet in tweets:
print(tweet)
print('-'*10) # 見やすくするために記載
client.search_recent_tweetsは直近7日間までのツイートを検索できるメソッドです。
他にもありますが、研究用のアカウントでないと使用できないものもあるので断念しました...。
queryは検索キーワードです。
RTが出ると邪魔なので、-RTを付けています。
上記コードのように(Twitterのように)スペース区切りで複数ワード検索できます。
max_resultsは10~100の間で指定できます。
指定した数のツイートがまとめて取得されるので、1レスポンスあたりに10件分のツイート情報が入ってきます。
ここで一度実行してみます。
Response(data=[<Tweet id=1575460381275074562 text='今回のライブで気づいたこと⬇️\n\n4番目の光より\n「光たちよ~」 👈好き\n\nジャンピングジョーカーフラッシュより\n 「誰かが昔 歌ったんだってね」👈好き\n\n北川悠理さんの歌声好きですわ笑笑\n今回のとある曲で痛感したわ\n\n #北川悠理\n #30thアンダーライブ'>, <Tweet id=1575458986001719297 text='まさか自分がこんなジャンピングジョーカーフラッシュにハマるなんてね(ジャンピングジョーカーフラッシュで出退勤してる人)'>, <Tweet id=1575458614617067520 text='kyujyoshoさんのライフを回復させたいから僕が手を叩く方へとジャンピングジョーカーフラッシュを生でやってほしい、30thミニライブ有観客でやって'>, <Tweet id=1575454803437633541 text='@y_m0846 Am I Loving?\n全部夢のまま\nトキトキメキメキ\nアザトカワイイ\nジャンピングジョーカーフラッシュ\n五月雨よ\n自分じゃない感じ'>, <Tweet id=1575431269902848001 text='ジャンピングジョーカーフラッシュは最高\n\nこの曲ほんと元気出るよね\n\nほんと好き https://t.co/bs0RWTi0hA'>, <Tweet id=1575423374620524544 text='ジャンピングジョーカーフラッシュ退勤'>, <Tweet id=1575421466962952193 text='ジャンフラなりきりセット(清宮レイ🍊ver.)\n\n洗車バトル対戦よろしくお願いします👊\n\n#ジャンピングジョーカーフラッシュ\n#清宮レイ https://t.co/4PPsBDmHGt'>, <Tweet id=1575412871306977280 text='@camelliamofy おはよう(*゚∀゚)っ\n敢えてそこ!?\n...あっ、そうか!\n「ジャンピングジョーカーフラッシュ」ってタイトル自体がまさに、特に意味はないけど語呂が良くて気持ちいい響きだもんね!\n納得だわ(笑)'>, <Tweet id=1575410572488634368 text='ジャンピングジョーカーフラッシュ!!\n #レコメン'>, <Tweet id=1575408933287514118 text='ライブで観て以来 #ジャンピングジョーカーフラッシュ 中毒が続く\nMVを見るのが日課\nMVって永遠に残るのでそこだけはせーらも参加出来てたらなぁと思ってしまう\n#絶望の一秒前 もそうだけど\n\n#早川聖来'>], includes={}, errors=[], meta={'newest_id': '1575460381275074562', 'oldest_id': '1575408933287514118', 'result_count': 10, 'next_token': 'b26v89c19zqg8o3fpzblrv1l17t4stoguibnjqlfgdocd'})
----------
Response(data=[<Tweet id=1575403364174548992 text='ジャンピングジョーカーフラッシュでGo!Go!'>, <Tweet id=1575401019575455744 text='ジャンピングジョーカーフラッシュでGO!GO!を現地で出来ないまま夏を終えてしまったので、窓から冷たい風が吹き込むたびに少し寂しくなるんですけどこれもしかして来年の夏まで続くんですか'>, <Tweet id=1575400486710444035 text='【ヘビロテ中の曲】\n乃木坂46 ジャンピングジョーカーフラッシュ\n乃木坂46 好きというのはロックだぜ!\n日向坂46 僕なんか\n日向坂46 恋した魚は空を飛ぶ\nMr.Children 永遠'>, <Tweet id=1575394365970604032 text='ジャンピングジョーカーフラッシュがn回目の環状線逆回りをかまし丸善インテックアリーナ到着が大幅遅延。 https://t.co/OvFyuYxQpz'>, <Tweet id=1575392594812862464 text='4時間巻きで今月の最終労働が終了して今歓喜のジャンピングジョーカーフラッシュで退勤をキメました。最高すぎますありがとうございました。'>, <Tweet id=1575386768358010880 text='ジャンピングジョーカーフラッシュがずっと脳内を流れててマジで手が止まる'>, <Tweet id=1575375103290126336 text='@kazuniki0608 iseeみたいな乃木坂4期生のモンスター楽曲になれたら良いですね…(*´﹃`*)\n#乃木坂46 #乃木坂4期生 #賀喜遥香 #isee #筒井あやめ #ジャンピングジョーカーフラッシュ'>, <Tweet id=1575374008476106752 text='@kazuniki0608 あやめんセンター楽曲…(*´﹃`*)\n#筒井あやめ #乃木坂46 #ジャンピングジョーカーフラッシュ'>, <Tweet id=1575334909400317954 text="under's loveとジャンピングジョーカーフラッシュ一日3回は聞いてるけど飽きん\n\nお前何おたん?">, <Tweet id=1575333999186104321 text='ジャンピングジョーカーフラッシュでGOGO\n\n#レコメン'>], includes={}, errors=[], meta={'newest_id': '1575403364174548992', 'oldest_id': '1575333999186104321', 'result_count': 10, 'next_token': 'b26v89c19zqg8o3fpzblrsxr1kv55zfuq385lvfpqzb7h'})
----------
・
・
・
確かにツイートは取得できました。
このResponse1つの内に10件分のツイートが格納されています。
このままではあまりにも使いづらいので、以下のように修正していきます。
tweets = tweepy.Paginator(
client.search_recent_tweets,
query='ジャンピングジョーカーフラッシュ -RT',
max_results=10,
tweet_fields=['id','created_at', 'author_id', 'lang']
).flatten(20)
for tweet in tweets:
print(tweet) # tweet.textも同じ結果
print('-'*10)
.flatten()を追加しました。
追加することで、1件ずつツイートが表示されるようになります。
.flatten(20)とすることで、20件分取り出せます。(max_resultsより小さくてもOKです)
tweet_fieldsも追加しました。
追加することで、ツイートの別情報(言語、作成時間など)を取得できるようになります。
ツイート作成時間はtweet.created_atで取得できますが、tweet_fieldsに記載がない場合はNoneが返ってきます。
このままではUTC(協定世界時)の時刻になります。
JST(日本標準時)は+9時間なので、以下のコードを追加してください。
from datetime import timedelta
...
for tweet in tweets:
tweet.created_at += timedelta(hours=9) # これでOKです。
print(tweet.created_at) # もうJSTになっています。
最終的なソースコードと出力結果は以下のようになりました。
import os
from dotenv import load_dotenv
import tweepy
from datetime import timedelta
load_dotenv()
BEARER_TOKEN = os.environ.get('BEARER_TOKEN')
CONSUMER_KEY = os.environ.get('CONSUMER_KEY')
CONSUMER_SECRET = os.environ.get('CONSUMER_SECRET')
ACCESS_TOKEN = os.environ.get('ACCESS_TOKEN')
ACCESS_TOKEN_SECRET = os.environ.get('ACCESS_TOKEN_SECRET')
client = tweepy.Client(
bearer_token=BEARER_TOKEN, # OAuth2.0の場合
consumer_key=CONSUMER_KEY, # OAuth1.0aの場合
consumer_secret=CONSUMER_SECRET, # OAuth1.0aの場合
access_token=ACCESS_TOKEN, # OAuth1.0aの場合
access_token_secret=ACCESS_TOKEN_SECRET, # OAuth1.0aの場合
wait_on_rate_limit=True # Trueにするとレート制限の解除を待つ
)
tweets = tweepy.Paginator(
client.search_recent_tweets,
query='ジャンピングジョーカーフラッシュ -RT',
max_results=10,
tweet_fields=['id','created_at', 'author_id', 'lang']
).flatten(20)
for tweet in tweets:
print(tweet.text)
tweet.created_at += timedelta(hours=9)
print(tweet.created_at)
print('-'*10)
今回のライブで気づいたこと⬇️
4番目の光より
「光たちよ~」 👈好き
ジャンピングジョーカーフラッシュより
「誰かが昔 歌ったんだってね」👈好き
北川悠理さんの歌声好きですわ笑笑
今回のとある曲で痛感したわ
#北川悠理
#30thアンダーライブ
2022-09-29 21:20:00+00:00
----------
まさか自分がこんなジャンピングジョーカーフラッシュにハマるなんてね(ジャンピングジョーカーフラッシュで出退勤してる人)
2022-09-29 21:14:27+00:00
----------
kyujyoshoさんのライフを回復させたいから僕が手を叩く方へとジャンピングジョーカーフラッシュを生でやってほしい、30thミニライブ有観客でやって
2022-09-29 21:12:58+00:00
----------
・
・
・
良い感じに取れました◎
おわりに
今回はTweepyを導入してAPIの機能を試してみました。
ツイートや作成時間を大量に収集すればマーケティングに活用できたり、
自身のツイートを機械学習させれば、自分っぽいツイートをしてくれるbotにもなりそうですね。
面白い活用法など思いついたら、ぜひコメントやTwitterなどで教えてもらえると嬉しいです!
直接お伝えしたい質問などもお気軽にどうぞ!
【Twitter】
https://twitter.com/PomericanCoffee
次回はガラッと変わって自然言語処理を行なっていきます。