TL;DR
- 相対音感を身につけるトレーニングをもっと簡単に,そして手軽にできるようにしたかった
- 採譜用の深層学習モデル
basic_pitchの利用と,前処理,特徴量後処理の工夫により実用性を重視した移動ド譜の作成を実現した
音感 欲しい!
音楽をやっていると,楽譜を使うのではなく自分の耳で音を聞き取って曲を演奏したいと思うようになります.こうした"耳コピ"は,自分の手で曲を再構成できることが面白いですし,耳を鍛えることにもつながります.しかし,音感の無い人にとって曲に現れる音の高さを当てることはとても難しいのです.
絶対音感は子どもの頃のトレーニングがないと獲得が難しい一方,一定の基準音からの距離に基づいて音を当てる相対音感は,大人になってからでも獲得できると言われています.
相対音感とは?
ほとんどのポップス音楽は,ひとつの中心音に基づいてメロディや伴奏が演奏されています.これを,調性と呼びます.調性に基づくと,中心音を聞き分けることは比較的容易です.

こんな感じのを,小中学の音楽の授業で聞いたことがある人も多いと思います.最後の音が鳴った時,「終わり」の感じがあると思いませんか?この最後に鳴ったメロディ(最高音)が,調性における「中心音」なのです.
もう一つ,もう少しポップスっぽいメロディの例を挙げます.こちらも同様に,最後の音で「終わり」の感じが伝わってくると思いますが,その音が曲の「中心音」です.

ほとんどの曲には,こんな感じで「中心音」が存在します.この中心音を基準にして音の高さを聞き取ろうというのが相対音感の考え方である,と私は認識しています.
相対音名:相対音感における音のラベリング
中心音を基準に聞き取るという相対音感の考え方は,ご理解いただけたかと思います.しかし,音の間の距離をそのまま数字で呼ぶと歌いにくいです.そのため,中心音基準の音の名前として,相対音名というものを使います.相対音名は,中心音をドとみなし,それを基準として「ドレミファソラシド」を割り当てる,という考え方のもとつけられた音の名前です.このようなドレミの割り当て方は,ドが移動するので,移動ドと言ったりします.ピアノの鍵盤で見ると,次のようなものになります.
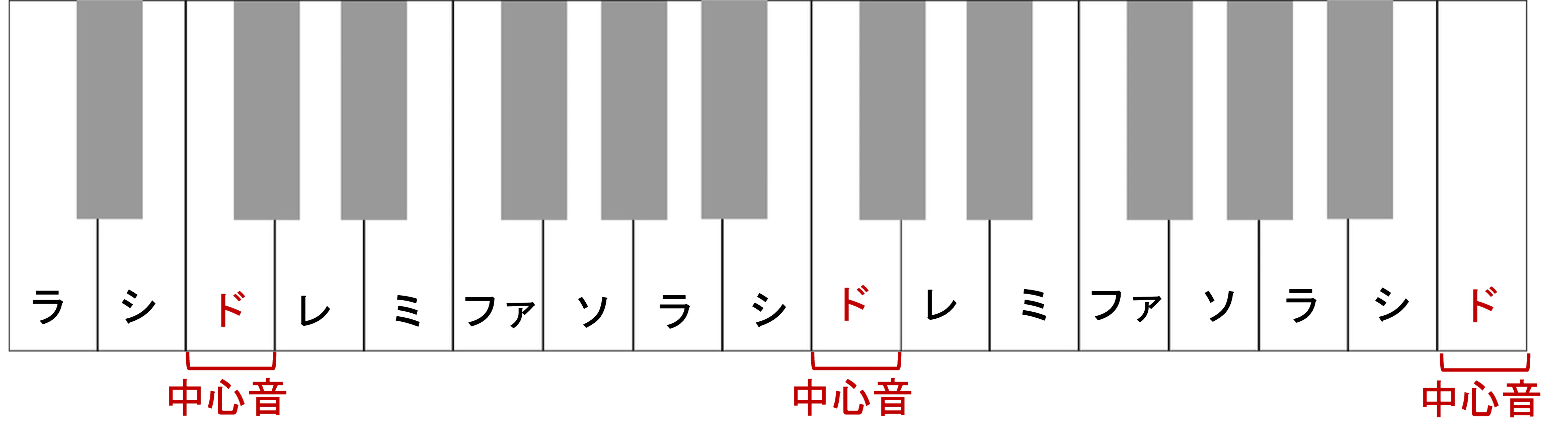
12鍵間隔(1オクターブ)で,同じ音名が繰り返されていると思います.相対音名(移動ド)の考え方では,このようにオクターブ間の違いは無視しつつ,中心音との距離に基づいて音のラベル付けを行います.
また,中心音の位置が変われば,相対音名によるラベリングも変化します.
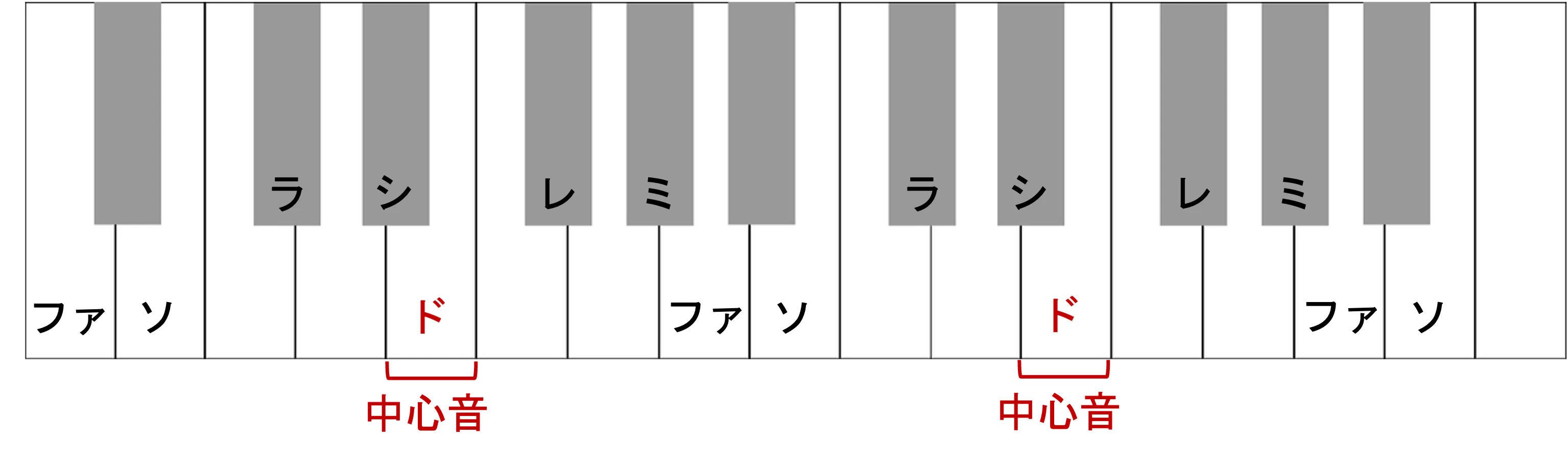
相対音感は,聞こえてきた音がこのドレミのどれであるかを当てることにより,音の高さを認識しようという考え方を持っていると思います.
混乱してしまうかもしれませんが,重要なことは以下の2点です.
- 曲には圧倒的安定感を持つ中心音が存在する
- 中心音を基準に音をラベリングし,それに基づいて音の高さを認識するのが相対音感
才能として認識されやすい音感ですが,大人にとって獲得が困難なのは絶対音感のほうです.対して,相対音感はトレーニングにより後天的に獲得することができると言われています.
ここでの解説はとても簡素なものになります.より詳しく体系的な知識を得たい方は,他の文献を参照してください🙏
私自身はSoundQuestというWebサイトに,大変お世話になっています.
相対音感の面白さ
相対音感の凄さは,後天的に獲得できるという点だけに留まりません.色々な音楽を抽象化して,構造的に理解することにも大いに役立ちます.先ほどのどっかで聞いたことあるような曲を再掲します.ここでは,相対音名にラベリングを行います.

ここで,中心音に対する音高,つまり相対音名さえ守ってあげれば,中心音をいじっても同じような曲が出来上がるのです.これは移調と呼びます.先ほどの音源を移調してあげると以下のようになります.

全体的に音高が低くなり,ちょっと落ち着いた雰囲気が出ているかもしれません.しかし,先ほどの音源と同じ曲だと認識することはできると思います.その理由は,全ての音の,中心音に対する相対的な位置関係,つまり相対音名が全く一緒だからです.
このように,違う曲だけど相対音名を用いて抽象化すると共通点が見えてくるというのが,面白いのです.ここでは,分かりやすく移調した例を示しましたが,全く違うような曲でも抽象化された世界から見ると繋がりが見えてくるのが興味深いです.これは,絶対的な音高を言い当てるだけの絶対音感にはなし得ない,相対音感の強みです.
どうやって相対音感をトレーニングするのか?
相対音感をどうやってトレーニングするのか.それには,曲に現れる音の相対音名を言い当てられるように,中心音の位置の認識と中心音に基づいた相対音名の認識に取り組むことが重要です.私は,相対音名という概念を知った後,自分が好きな曲のメロディをとにかく相対音名でラベリングするという作業(トレーニング)を行っていました.少しお恥ずかしいですが,自分の当時のメモを添付します.
当時のメモ
空も飛べるはず C
Intro.ドレミーミーレドシードーシラードレミーミーレミファーミーラーソドレミーミーレドシードーシラ シドソー ミファソドソファミドー
A-ミミソミファミーレーファーレレソレミレードーミー
ファミレドーレーミードーシドレーラーシー *2
B-レミミミドーラドーレミミミドーラドー ラーシードーレーソソーファーミーファミミレー
サビ-ソドレミーミーレミファーミード ラーラーシドレララソミソー ミーソラーレレーレソードド ドシラーシドーミドレー ソドレミーミーレミファーミード ラーラーシドレーララソミソー ミーソラーレレーレソードドーファーラーシーミードー
これは,Spitzの「空も飛べるはず」のメモになります.メロディを,相対音名と伸ばし棒で頑張って表現してます.見返したらこんなメモが何十曲も乱雑に残っていました.メモり方はともかく,もうちょい綺麗に残しておきたかったです.
課題の定義
慣れないうちのこのようなメモ作業はとても労力と時間を必要とします.やる気がない時は,YouTubeでこのようなラベリングをすでに行った音源を公開してくれている人がいらっしゃったので,活用させていただきました.でも,こういうトレーニングは自分が楽しめないと全く身につかないのです.公開していただいている中でも,自分が興味を持てたのは好きな数曲に限られました.
このような問題意識から,次のような問題を仮定しました.
相対音名を獲得するためのトレーニングは多大な労力を必要とするため,初心者が興味を持って継続的に取り組むことは困難である
この問題の解決のためには,自分が興味の持てる題材を用いて相対音感を鍛えることができるツールの開発が必要である,と考えたのです.
ツールの開発
構想したツールは次のようなものです.
- 好きな楽曲の音声ファイルを入力する
- メロディを採譜する
- 中心音を予測する
- 中心音とメロディに基づいて,相対音名をラベリングする
- メロディとその相対音名を可視化し,音源に合わせて歌えるようにすることで,相対音感の定着を助ける
当初は,機械学習技術の発展を考えればこんなことぐらい簡単にできてしまうのではと考えたのです.しかし,実際は自分が定義した課題の解決にあたっては様々な困難が生じました.
生じた困難:メロディ採譜の精度が悪い
メロディ採譜をうたう機械学習モデルはいくつか見つかりました.しかし,どれも最初は全くと言って良いほどうまくいきませんでした.
試したモデルは以下のようになります.
-
torchcrepe:単旋律用,リズムが大きく崩れる,謎のノイズを採譜してくる(?),異常な跳躍がよく起きる -
basic_pitch:複数旋律用,リズムは同様に崩れる,メロディの外形はめっちゃ合ってる,音がない区間で音が採譜される
以下では,これらのモデルの使いづらさを実際の採譜結果とともに示します.なお,以降は私がSuno AIで作成した音源の一部を使用します.プロンプトは覚えてません.
torchcrepe
まず,torchcrepeです.私の使い方が悪いのか,全くうまくいきませんでした.今回試したモデルはどちらも,音源の各フレームにおける各音の存在確率を予測するものになっています.そのため,確率の閾値次第で精度も変化します.
パラメータの変更を色々と試したのですが,torchcrepeではリズムが滑ったり,全くメロディと関係ない音の確率が強くなったりなど,扱いにくい印象を受けました.
basic_pitch
次に,basic_pitchです.Spotifyが開発したこのモデルは結構すごいです.下の採譜結果を聞いてもらうとわかると思いますが,曲がしっかり再現されているのがわかると思います(複数旋律モデルなので,伴奏も取れています).
しかし,相対音感のトレーニングとしてそのまま使うのは難しいと判断しました.理由はボーカルの表現に弱いという点です.
採譜された音源をよく聴いてもらうとメロディがブツ切れになっていたり,音楽的でない細かい揺らぎが感じられます.basic_pitchは,ボーカル特有のピッチの揺らぎに敏感に反応します.ボーカルは自由に表現できるので,ちょっとした表現で音高が上がり上の音(スケール外の音)と認識されてしまったり,歌いようがない細かいリズムになってしまうことがあります.
しかし,basic_pitchはあくまで基盤として優秀です.問題は,ボーカルという入力の特殊性にあります.ボーカルはピッチが滑らかに揺れ,息遣いや表現によって音高が安定しません.これは,楽器音を前提に設計されたモデルにとって難しい条件です.そこで,モデルそのものを変えるのではなく,前処理と後処理の工夫によって出力を「歌いやすい採譜」に補正するというアプローチを取りました.具体的には,入力を整える(音源分離・チューニング補正)と,出力を整える(ビートに基づくグリッド化・キー補正・モチーフ補正)の2段階で対処しています.
ツールに昇華するために行ったこと
相対音感をトレーニングするツールとして使うには,こうしたボーカル採譜,そしてトレーニングという目的における特有の問題を解決する必要がありました.そのために,以下のような工夫を行いました.
- ボーカル音源の分離:Demucsを利用してパートごとに分離することで,モデルをボーカル採譜に集中させる
- チューニング補正:チューニング補正により標準的なチューニング(A=440Hz)に合わせ,精度を上げる
- ビート基準のグリッド化:曲のビート位置を基準に特徴量を集約することにより,リズムの崩れを軽減する
- キーに基づく補正:キー(中心音の位置)の予測を採譜と同時に行い,スケール内の音(「ドレミファソラシド」のいずれか)の確率が高くなるよう補正する
- モチーフに基づく補正:モチーフ(同じメロディの繰り返し)により確率を補正し,一貫した予測を行う
ボーカル音源を分離する
basic_pitchを使う上で,複数旋律への対応という特性は余分になります.なぜなら,音高を予測したいのはメロディだけだからです.そこで,Demucsというパート分離モデルを活用することでボーカルだけを採譜し,それをbasic_pitchの入力としました.(Demucs本当にすごいです.こんなに綺麗に分離できることに感動しました!)
- ボーカル
- 伴奏(ドラムとベースのぞく)
ボーカル音源に関しては,息遣いによるノイズを減少させるためにハーモニー成分とパーカッション成分の分解も行います.こちらは,音楽処理用のpythonライブラリであるlibrosaのlibrosa.effects.hpssを利用します.
# marginで分離の厳しさを制御可能
y_harmonic, _ = librosa.effects.hpss(y_vocal, margin=1.0)
チューニング補正
チューニングはA=440Hzという風に標準化されています.しかし,すべての楽曲がこのチューニングであるとは限りません.A=440Hzからズレている場合,採譜される音もズレがちになるという問題が発生しました.
librosaはチューニングのずれを推定するメソッドも持っています.ここでは,librosa.estimate_tuningを用いてオフセットを推定し,音質を低下させないリサンプリング方式によるチューニングを行いました.先述の通り,ボーカルの音高には揺らぎがあり,息遣いなどのノイズが多く含まれるためDemucsにより分離済みのインスト音源のみを使用しています.
# オフセットの予測
tuning_offset = librosa.estimate_tuning(y=y_inst_raw, sr=sr)
# リサンプルによるチューニング後のサンプリングレート
tuning_rate = 2 ** (-tuning_offset / 12)
# リサンプルによるチューニング
y_inst = librosa.resample(y_inst_raw, orig_sr=sr*tuning_rate, target_sr=sr)
ビート基準のグリッド化
この工夫が,最もインパクトが大きいと考えています.
先述の通り,basic_pitchの出力をそのままMIDIに変換しようとすると,細かすぎるリズムが入り歌いにくいものになります.そこで,曲のビートの位置を予測し,そのビートを基準にして分割するというアプローチをとります.
basic_pitchの出力は(n_pitches, n_frames)という形状になっています.各frameに88音の確率が入っているという感じです.私のアプローチは,曲から推定したビートを基準にこれらのframeをグリッドに集約するというものです.
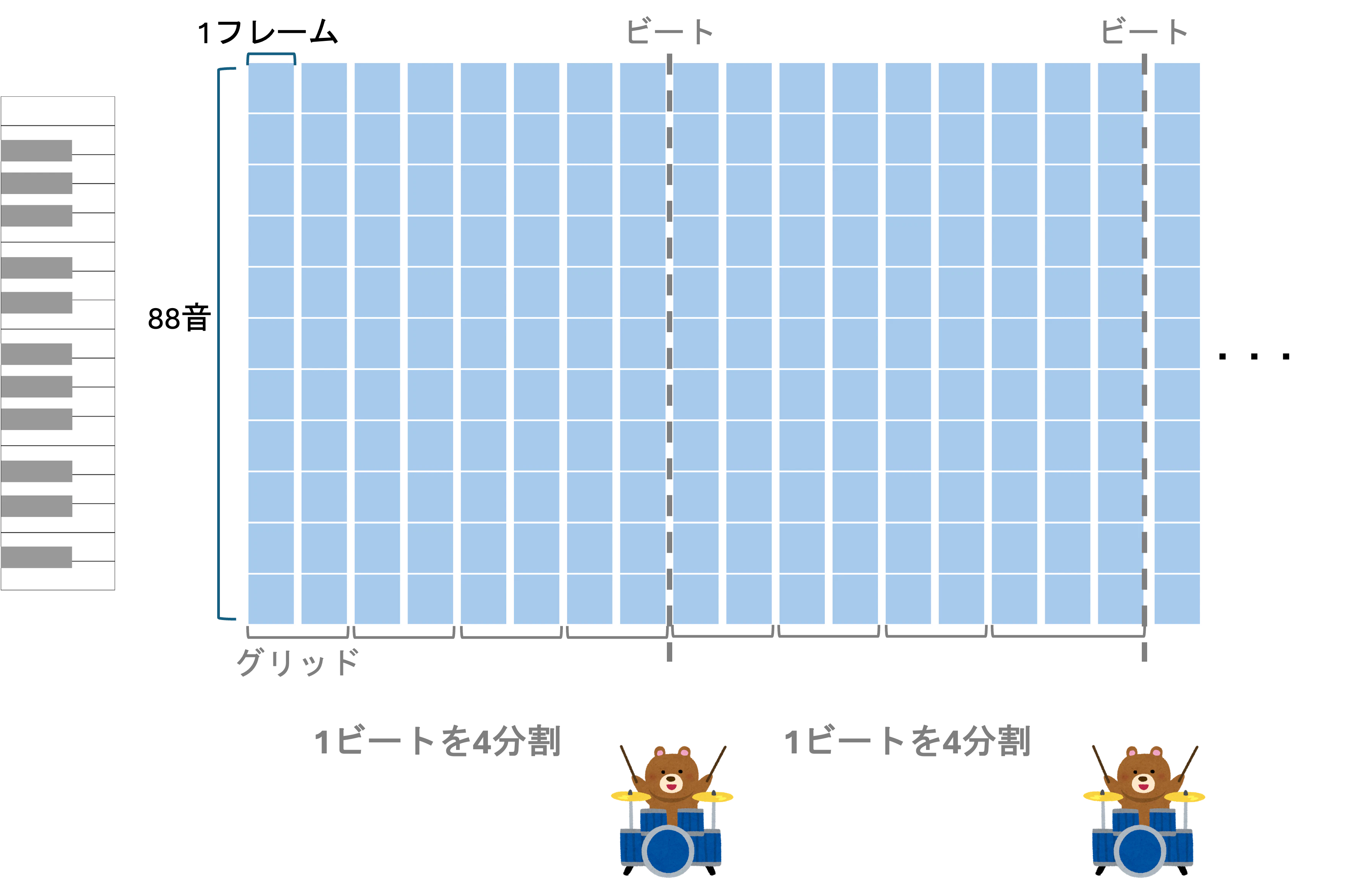
4/4拍子の曲においてビートを4分割する場合,各グリッドは16分音符に相当します.ほとんどの曲は16分音符の粒度で大まかなリズムをカバーすることができると考えてました.ビートを基準にしてframeを集約することにより,音楽的に意味のある単位でリズムを捉えることができるようになります.この処理により,リズム,そして細かい音の揺らぎも抑制することができるようになります.
ちなみに,ビート位置の予測もlibrosaがやってくれます.
# インスト音源からテンポを予測
bpm = librosa.feature.tempo(y=y_inst, sr=sr)
# 予測されたテンポを与え,ビートが存在するframeを予測
tempo, beat_track = librosa.beat.beat_track(y=y_inst, sr=sr, hop_length=HOP_LENGTH, start_bpm=bpm[0], units='frames')
キーに基づく補正
ボーカルの採譜タスクを対象にしているため,ちょっとした音の揺らぎにより音高が変化してしまいます.こうした揺らぎを抑制し,より尤もらしい予測を可能にするため,キーに基づいた確率の補正を行います.「キー」に関してはあまり説明していませんが,「中心音」がどこにあるのか,と同じような考え方です.
キー,つまり中心音が決まると,「ドレミファソラシド」という相対音名の割り当ても決定されます.もちろん曲には「ドレミファソラシド」以外の音(キーから外れた音)も出てくるのですが,確率的には滅多にないことです.そこで私は,キーから外れた音の確率を抑制し,キー内の音の確率は補強するというアプローチをとりました.
これにより,無駄な音高の揺らぎを抑制することにつながりました.
これをやるためには,まずキー推定を行う必要があります.端的に言うと,曲のクロマベクトルを算出し,キーのプロファイルとの類似度を計算することでキーの確率分布を計算.さらに,Viterbiアルゴリズムを利用して音楽理論に即したキー遷移予測を実現しています.詳細については割愛します.
モチーフに基づく補正
ほとんどの楽曲は,モチーフをもとに展開します.モチーフと呼ばれる同じような音形を繰り返すことにより,記憶に残りやすい曲になります.こうしたパターンを利用して採譜の精度を上げられないかという考えから,モチーフを用いて確率を補正するという考えに達しました.
librosaには,こうしたモチーフをとらえるためのメソッドも存在しています.librosa.segment.recurrence_matrixを用いることで,離れた時刻にあるモチーフの繰り返しを捉えます.出力は(n_grid, n_grid)になり,対角線方向に大きな確率が連続している区間にモチーフが存在すると予測することができます.recurrence matrixにはtimelag_filterを適用することで,ちょっとしたリズムや音高のずれを補完できるようにしています.
rec_input = interval_features.T # (n_pitch, n_grid)
R = librosa.segment.recurrence_matrix(
rec_input,
k=None,
width=REC_WIDTH,
metric="cosine",
mode="affinity",
sym=True,
sparse=False,
) # (n_grid, n_grid)
# timelag_filterによる補完
R_enhanced = librosa.segment.timelag_filter(gaussian_filter1d)(R, sigma=1.2, mode='mirror')
これによりモチーフの存在する区間を取得することができるので,その区間は音高の確率の重み付き平均を取ることで,モチーフ情報による補正を実現しています.
統合してインターフェースで表示する
以上で述べた処理をパイプラインとして統合し,採譜結果とDemucsで分離したインスト音源と重ねれば完成です.パイプラインの統合とフロントエンドの作成はClaudeさんにお願いしました.
Mac OS以外では試していません.当初はGPUが必要かなと思っていたのですが,結局CPUだけで動くようになったはずです.Dockerで動くようにしたいですが,今後の課題としています.
また,ローカルで実行して使うことを想定しています.Claudeさんがジョブ管理方式(?)を提案してきたのですが,設計が複雑になりそうなのでやめました.もう少し発展させる機会があればちゃんと設計したいです.
結果
結果は次のようになります.
まとめと今後の課題
自分の興味の持てる題材を用いて相対音感を鍛えることができるツールの開発が必要であるという課題感のもと,自動でボーカルの採譜を行いUIとして表示する機構を作成しました.
今後の課題としては,以下が挙げられます.
- Demucsで完全にボーカルを分離できず,漏れ出たインストにより無ボーカル区間に音が採譜されてしまうことを抑制する
- 相対音名を表示するだけでなく,合成音声などを使って音名を歌わせることで,直感的な理解を助ける
- 異常な音の跳躍を抑制する
- Dockerで動かす
- アプリを公開する場合の設計
感想
このツールを開発する過程で,音声分離モデルをはじめ,軽量で高性能なモデルを実際に触ることができて感動しました.また,目的を達成するためにモデルの出力を補正する様々な試行錯誤は辛かったのもありますが,とても楽しかったです.AIのおかげで,改善案をアルゴリズムに落とし込む作業が大幅に楽になりました.
私はもう,こうしたツールを使うよりは自分で採譜したほうが早いし勉強になると思っています.しかし,学びはじめの自分を振り返った時に,相対音名に慣れるのがすごく大変だったのを思い出し,同じような苦労をしている初心者の力になれればと思い,このようなものを作ってみたいと思いました.
そのような自分もまだまだ音楽も開発も初心者なので,これからも頑張ります!
ここまでお読みいただきありがとうございました!