このブログは、siddontangの"How We Optimize RocksDB in TiKV — SST Compaction Guard"の抄訳です。翻訳はGeminiの翻訳をベースに、@bohnenが担当しました。
コンパクションはRocksDB内で最もコストのかかる操作の1つであり、分散型リージョンベースのキーバリューストアであるTiKVにとって、コンパクションの非効率性は、I/Oの浪費、書き込み増幅(Write Amplification)の増加、そして読み取り操作の遅延に直結します。
この記事では、TiKVのコンパクションワークフローにおける根本的な問題、RocksDBのデフォルトのSST分割ロジックが不十分である理由、PebblesDBの研究がどのように私たちの解決策にインスピレーションを与えたか、そしてTiKVのSSTコンパクションガードが、どのように書き込み増幅を劇的に削減するかについて説明します。
問題点:SSTの範囲がTiKVのリージョンと一致しない
TiKVのデータモデルは「リージョン(Region)」という概念に基づいて構築されています。
各リージョンはキーの範囲をカバーします。
リージョンの範囲 = [start_key, end_key)
耐障害性と負荷分散のために、リージョンは以下のことができます。
- TiKVノード間を移動する(Raftレプリカの移行)
- データ分布に適応し分割またはマージする
- RocksDBの
DeleteFilesInRangesAPIを使用して完全に削除される
しかし、問題があります
RocksDBのデフォルトのSSTファイル境界は、リージョンの境界と一致しません。
デフォルトでは、RocksDBは以下の設定でSSTファイルサイズを制御します。
target_file_size_base = 8MB // TiKVのデフォルト
これは、1つのSSTに複数のTiKVリージョンのデータが含まれる可能性があることを意味します。
リージョンが移動または削除されると、TiKVは以下を行う必要があります。
- 大きなSSTを書き換える
- 無関係なキー範囲にまたがってコンパクションを行う
- もしくは、大量の不要なI/Oを伴いデータを削除する
⠀
例
あるリージョンがキー [A, C) をカバーし、別のリージョンが [C, F) をカバーしているとします。
もしRocksDBが以下を含むSSTを生成した場合:
[A, F)
その場合:
- リージョン [A, C) を移行すると、[C, F) に属するキーのコンパクションが強制されます
- リージョン [C, F) を削除するとき、[A, C) のデータにもアクセスが発生します
- リージョンの範囲内の操作が、無関係なデータに影響を与えてしまいます
この過剰なコンパクションI/Oは、書き込み増幅を大幅に増加させ、パフォーマンスを低下させます。
SSTファイルの境界をリージョンの境界に合わせる方法が必要でした。
PebblesDBに触発されて:キー範囲に基づくガード付き分割
このアイデアは、PebblesDB Guard メカニズムから借用したものです。
(SOSP’17の論文より: https://www.cs.utexas.edu/~vijay/papers/sosp17-pebblesdb.pdf)
PebblesDBでは、コンパクションが明確に定義された境界内に制限されるよう、キー範囲を整理するためにガードが使用されます。
私たちはこのアイデアをTiKVに適応させました。
コンパクション中のSSTファイル分割をガイドするために、リージョンの境界をガードとして使用する。
目標は単純明快です。
異なるリージョンに属するキーは、異なるSSTファイルに配置されるべきである。
これにより、リージョン範囲をまたぐ不要なコンパクションが回避され、よりクリーンな分離、低い書き込み増幅、そしてより良いデータ局所性が実現します。
しかし、RocksDBでカスタム境界分割をどのように実装すればよいのでしょうか?
RocksDBのSSTパーティショナーの使用
RocksDBは SST Partitioner と呼ばれるメカニズムを提供しており、アプリケーションがコンパクション中にSSTファイルをどこで切断するかを定義できるようになっています。
ドキュメント: https://github.com/facebook/rocksdb/wiki/SST-Partitioner
コンパクション中、SSTパーティショナーは以下を行います。
- 出力されるキーを監視する
- 境界を越えたときに新しいSSTファイルを開始するかどうかを決定する
TiKVにとって、境界は単純です。
リージョンの開始キー。
連続する2つのキーが異なるリージョンに属している場合、パーティショナーはSSTの分割をトリガーします。
これが、以下で実装された最適化の基礎を形成しています: https://github.com/tikv/tikv/pull/8115
TiKVのSSTコンパクションガード
TiKVは3つの新しい設定を導入しました。
enable_compaction_guard
compaction_guard_min_output_file_size
compaction_guard_max_output_file_size
仕組み
enable_compaction_guard が有効な場合:
- SSTファイルはリージョンの境界に従って分割されます
- 異なるリージョンに属する2つのキーは、異なるSSTに配置されます
- 分割はRocksDBのコンパクションプロセス中に遅延的に(積極的ではなく)行われます
実用的なファイルサイズを確保するための2つの例外:
- SSTサイズ <
compaction_guard_min_output_file_sizeの場合 → 極小のSSTが生成されるのを避けるため、分割しません。 - SSTサイズ >
compaction_guard_max_output_file_sizeの場合 → たとえ正確にリージョン境界でなくても、強制的に分割します。
結果:書き込み増幅の大幅な削減
私たちは、バルクインサート(一括挿入)と更新のワークロードでSSTコンパクションガードをテストしました。
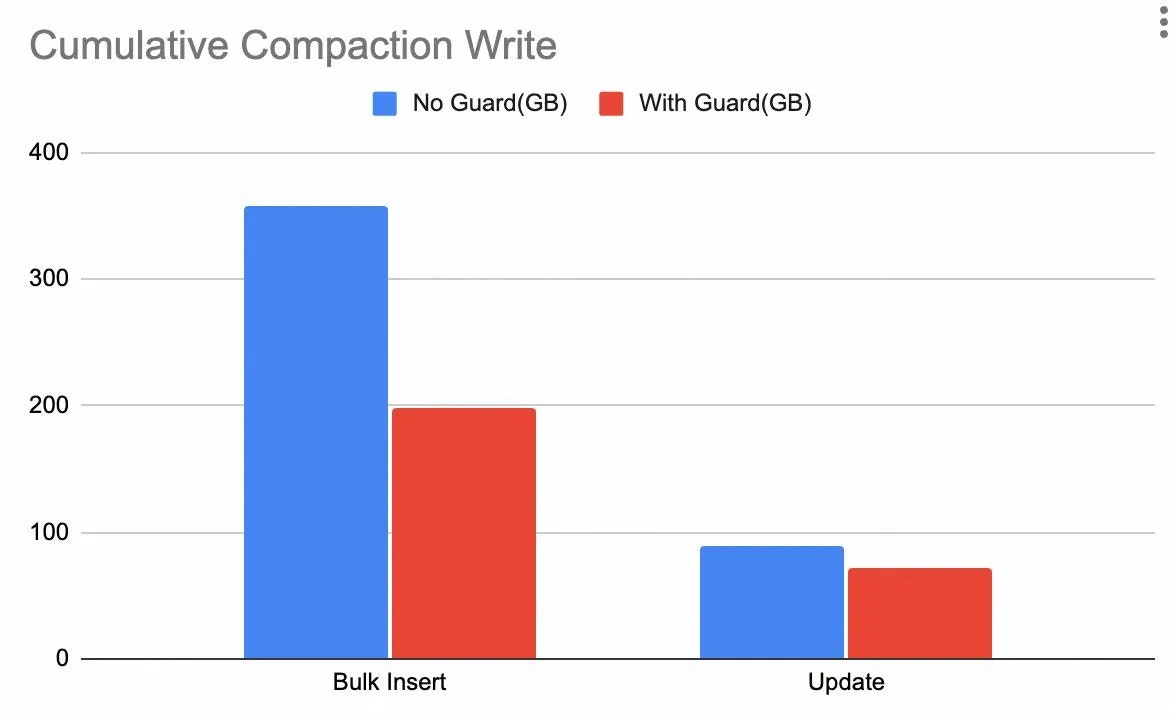
バルクインサートワークロード:書き込み増幅が 45%削減
更新ワークロード:書き込み増幅が 約20%削減
これらの数字は直感と一致しています。
- リージョンに合わせたコンパクションにより、範囲をまたぐ書き換えが減少します
- RocksDBは無関係な範囲を書き換えなくなります
- リージョンの削除/移動操作が劇的に低コストになります
- LSM構造がより安定的で予測可能になります
これにより、TiKVは大規模環境においてより効率的になります。
最後に
SSTコンパクションガードは、TiKVが分散KVストアとしてのニーズに合わせてRocksDBの柔軟なアーキテクチャをどのように適応させているかを示す素晴らしい例です。
LSMの境界をリージョンの境界に合わせることで、以下を実現しました。
- 書き込み増幅の低減
- コンパクションの高速化
- より効率的なリージョン操作
- スペース使用効率の向上
- 高負荷時のレイテンシの予測可能性の向上
小さなアイデアが、大きな違いを生み出します。