概要
GPT などの言語モデルに対するプロンプトの新しい手法として、こちらの論文で提案された Tree-of-Thoughts (ToT) を取り上げます。
同じくプロンプト手法で有名な Chain-of-Thoughts (CoT) と古典的なツリー探索を組み合わせたような手法です。
論文の実験に使われたコードは GitHub で公開されています。
アルゴリズム
通常の CoT だと、LLM は問題の答えに向けて一直線に考えるため、その過程で何か間違っていたとしても誤った考えに基づいたまま突き進みます。
一方で ToT の場合は思考の各ステップで LLM 自身による評価を挟み、「無理筋」を早々に打ち切って別のアプローチを探索します。両者のこの違いを示すのが論文の以下の図です。

ツリーの各ノードは LLM によって生成された思考過程を表し、ノードの色は LLM によって評価されたスコアに対応します。
論文中で実験に使われている「24 ゲーム」を例として見てみましょう。与えられた 4 つの整数 (4, 9, 10, 13) をそれぞれ 1 回ずつ使って、四則演算だけで答えを 24 にするゲームです。 (答えは (10 - 4) * (13 - 9) = 24 など)
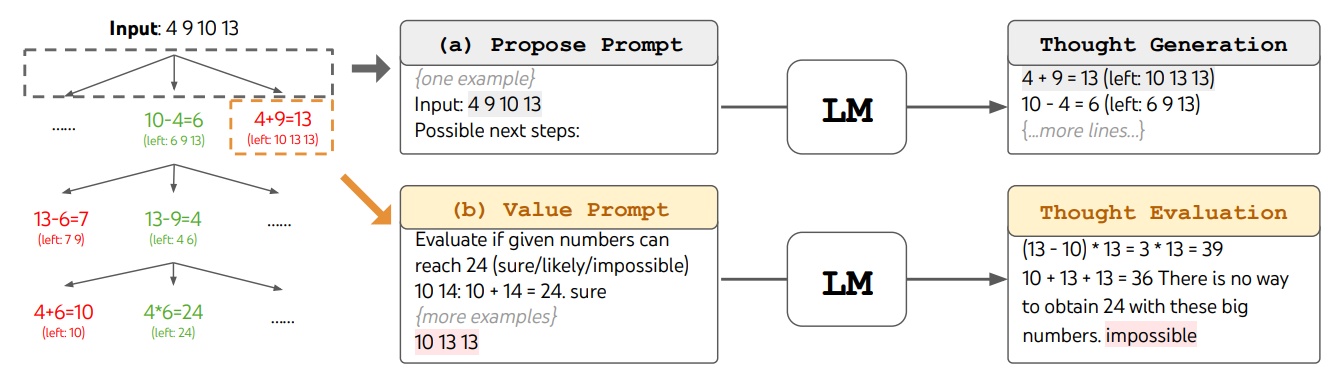
上の図では「与えられた数の中から 2 つを選んで + - * / のどれかを適用」が LLM の思考の 1 ステップとなっていて、3 ステップで必ず答え (の候補) に辿り着きます。
実験結果
論文の中では、前述の 24 ゲームに加えて作文とクロスワード問題で実験して ToT と他のプロンプト手法の性能を比較しています。
24 ゲーム
4nums.com の問題 100 件を使った実験結果です、

- ToT の正答率は 74% で、他のプロンプト手法より高い
- 「探索したツリーのノード数」に対する正答率を比較しても、他の手法より高い
- CoT は最初の 1, 2 ステップで大半が無理筋に当たっているが、ToT はそれを回避できている
作文
4 つの段落それぞれが指定された文で終わるような、自然に繋がる文章を作る問題です。

- 出力された文章を GPT-4 に評価させた結果、ToT のスコアが高い
- CoT と ToT で生成された文章のどちらかを人間に選ばせた場合でも、ToT の方が良い結果
クロスワード
5x5 のクロスワードパズル問題で、文字レベル、単語レベル、問題レベルの正答率を評価しています。

- ToT の正答率が最も高い
- ツリー探索の際に枝刈りやバックトラックをさせないと正答率が落ちる
問題点
実験タスクの選定
論文中で実験しているタスクは 3 種類だけと少なく、またそれぞれについて以下のような疑問が浮かびます。
- 24 ゲーム:簡単なスクリプトで解ける (それこそ GPT にコードを書かせれば一発で正解できる 1 )
- クロスワード:LLM 以外で解く既存手法がある 2
- 作文:ToT と Self-Refinement のスコアにあまり差が無い
トークン消費量
GitHub レポジトリの /logs 以下に各実験のログが残っており、そこには OpenAI API のトークン消費量も記録されています。これを見ると全てのタスクで ToT の方が多くトークンを消費しているため、フェアな実験設定とは言い難いところです。
"usage_so_far": {
"completion_tokens": 547859,
"prompt_tokens": 1387936,
"cost": 74.50962
}
"usage_so_far": {
"completion_tokens": 461878,
"prompt_tokens": 148580,
"cost": 32.17008
}