どうもこんにちは。
今回は初めてAWSのSageMakerを使用してみました。
想定
今回、モデルを学習させるにあたって、想定したケースは、
〇〇ゲートを何月何日何時何分に何人の人間が通ったか
です。
例えば、「2021年1月1日 12時00分00秒」に何人がゲートを通ったかをモデルに教えてもらうイメージです。
準備
今回は、S3に作成したトレーニングデータを保存します。
そのため、「sagemaker~」から始まるバケットを作成して置いてください。
また、手順ごとにコードブロックを分けて記述してください。
実装手順
1. SageMakerのノートブックインスタンスの作成からノートブックを作成
ノートブックインスタンスのタイプはml.t3mediumを使用しました。
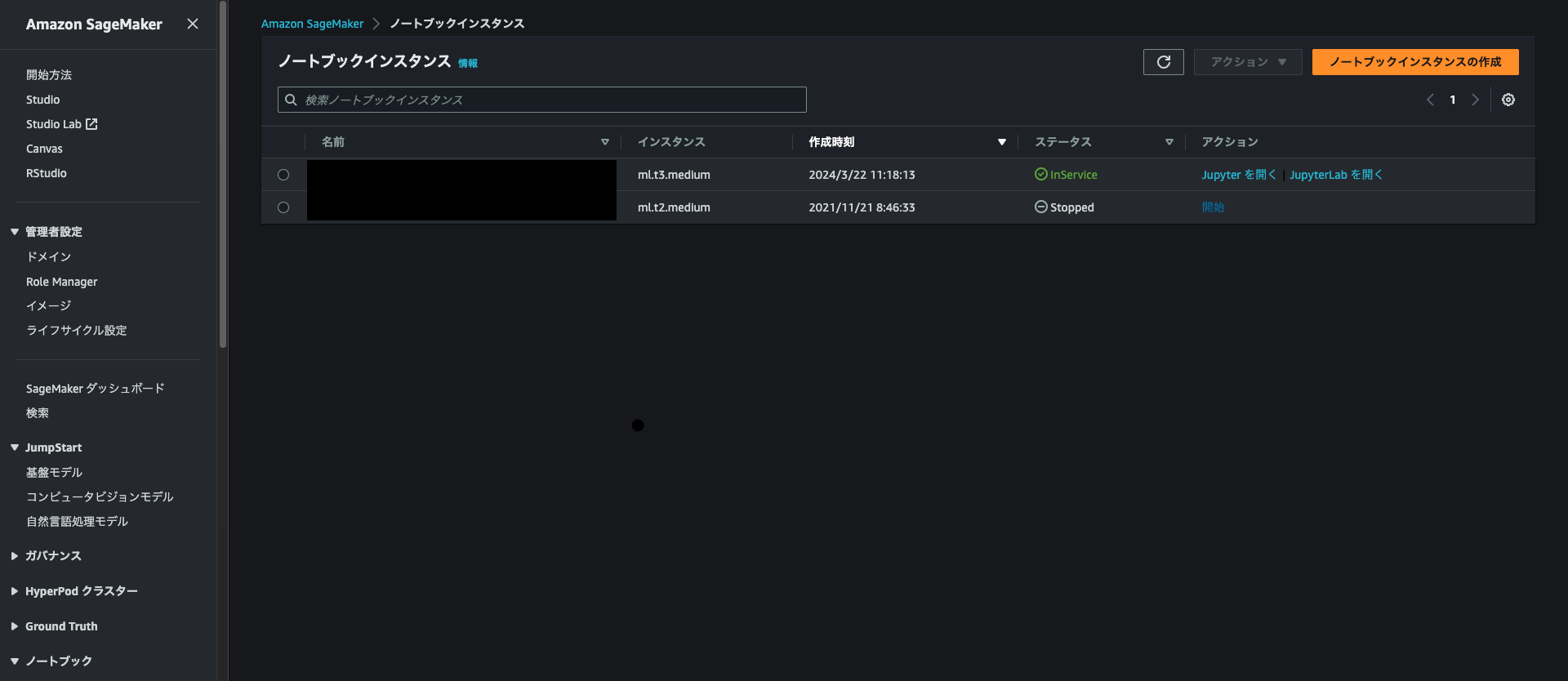
2. JupyterLabを開く
作成したノートブックインスタンスがinServiceになったらJupyterLab を開くリンクをクリックします。
3. 新しいノートブックを開く
[File]>[New]>[Notebook]から新しくノートブックを立ち上げます。
この時、conda_python3を選択してください。
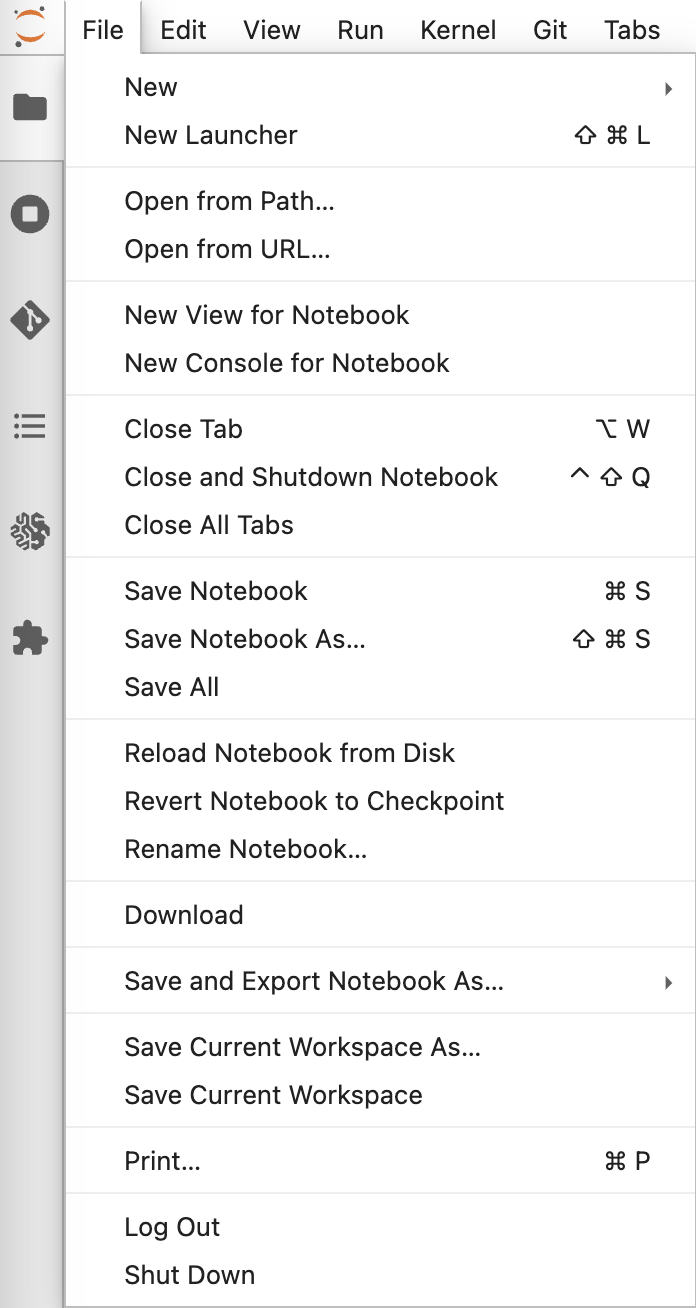
4. 必要なライブラリをインポート
以下をコピペしてください。
# 必要ライブラリインストール
import boto3
import pandas as pd
# テストデータ用ライブラリ
from sklearn.datasets import load_iris
!pip install faker
from faker import Faker
import random
import json
from datetime import datetime, timedelta
import io
# SageMaker用ライブラリ
import sagemaker
from sagemaker import get_execution_role
from sagemaker.serializers import CSVSerializer
from sagemaker.image_uris import retrieve
5. トレーニング用データの作成
count変数には、ゲートを通った人数、time変数には、観測した時間が代入されています。
この時、timeはモデルのトレーニングができるように、UNIXタイムスタンプとして数値化した値を代入しています。
fake = Faker()
# データセットの生成
n = 1000
data = []
for _ in range(n):
count = fake.random_int(min=0, max=100)
time = fake.date_time_this_decade().timestamp() # UNIXタイムスタンプとして時間を数値化
data.append([count, time])
# DataFrameに変換
df = pd.DataFrame(data, columns=['Count', 'Time'])
print(df.head())
↓printの結果↓
Count Observation Time
0 15 1.705957e+09
1 85 1.619990e+09
2 93 1.630492e+09
3 88 1.643634e+09
4 37 1.698472e+09
6. S3に作成したトレーニングデータをアップロード
以下はコピペでOKです。
# boto3を使用してS3にアップロード
s3_client = boto3.client('s3')
bucket_name = '<作成しているバケット名>'
file_name = 'test/dataset/sample_dataset.csv'
# DataFrameをCSV形式の文字列としてメモリに保存
csv_buffer = io.StringIO()
df.to_csv(csv_buffer, index=False, header=False)
# メモリからS3に直接書き込み
s3_client.put_object(Bucket=bucket_name, Key=file_name, Body=csv_buffer.getvalue())
7. セッションとロールの設定
以下をコピペしてください。
# SageMakerセッションとロールの設定
session = sagemaker.Session()
role = get_execution_role()
8. トレーニング実行
今回は、Linear LearnerというSageMakerに組み込まれているモデルを使用します。
最も単純?な線型学習をしてくれるとかなんとか。。。(わかる人いましたらコメントで教えてください。。。)
トレーニングには、何分かかかります。
# S3のデータパス
data_location = 's3://{}/test/dataset/sample_dataset.csv'.format(bucket_name)
# Linear Learnerのコンテナイメージを取得
container = retrieve('linear-learner', session.boto_region_name)
# 推定器の設定
linear = sagemaker.estimator.Estimator(container,
role,
train_instance_count=1,
train_instance_type='ml.m5.large',
output_path='s3://{}/test/output'.format(bucket_name),
sagemaker_session=session)
# ハイパーパラメータの設定
linear.set_hyperparameters(feature_dim=1,
predictor_type='regressor',
mini_batch_size=100)
# トレーニングジョブの開始
s3_input_train = sagemaker.inputs.TrainingInput(s3_data=data_location, content_type='text/csv')
linear.fit({'train': s3_input_train})
9. トレーニングしたモデルのデプロイ
以下を実行するとデプロイされます。
predictor = linear.deploy(initial_instance_count=1, instance_type='ml.m5.large')
10. テストデータの作成
「2100/10/31 12:00:00」にゲートを通った人数をモデルに予測してもらいましょう。
# 任意入力(yyyy/mm/dd hh:mm:ss)
timestamp_str = '2100/10/31 12:00:00'
timestamp = datetime.datetime.strptime(timestamp_str, '%Y/%m/%d %H:%M:%S')
unix_timestamp = timestamp.timestamp()
# 特徴量を同様の形式で生成する
features = {
'Time': unix_timestamp
}
test_df = pd.DataFrame([features])
print(test_df.head())
csv_buffer = io.StringIO()
test_df.to_csv(csv_buffer, index=False, header=False)
csv_payload = csv_buffer.getvalue()
print('---CSVファイルの中身確認---')
print(csv_payload)
11. テストデータを使用して評価
# 評価用コード
predictor.serializer = CSVSerializer()
result = predictor.predict(csv_payload)
decoded_result = result.decode('utf-8')
print('出力された内容')
print(decoded_result)
parsed_result = json.loads(decoded_result)
score = parsed_result['predictions'][0]['score']
print('人数')
print(score)
↓出力された内容↓
出力された内容
{"predictions": [{"score": 39.422813415527344}]}
人数
39.422813415527344
結果
「2100/10/31 12:00:00」にゲートを通った人数がおよそ39.4人だと予測されました!
終わりに
満足したら必ず以下のコードをコピペして実行してください。
# デプロイ後は必ずエンドポイントを削除すること
predictor.delete_endpoint()