言語分析
言葉を分解して、何を言ってるか・どう言ってるか・なぜそう言うのかを明らかにする作業です。
何を言ってるか(意味):ポジ/ネガ、要点、意図をつかむ
どう言ってるか(形・構造):単語の切れ目、品詞、文のつながりを見る
なぜそう言うのか(文脈・状況):相手・場面・目的による言い回しの違いを読む
使いどころの例:口コミの感情判定、よくある質問の自動分類、長文の要約、検索の精度アップ…など。
tokenとは
テキストを単語やサブワードなどの最小単位(トークン)に分割することです。
アルファベットの言語だとスペースで単語が分かれますが日本語が出来ません、ツールが必要。
単語の分割と同じ単語出ても違う意味可能性あります、それなら二つの問題あります:
- どうやって分ける
- 意味って?
Janomeとは
言葉の分析だとMeCabが一番有名ですが、今回はAWSのLambdaで使うことになってましたのでMeCab見たいのライブラリが重すぎて入れられなかったため、サイズの小さい日本語団体のライブラリが必要になりました。検索結果はJanomeを見つけたので、使ってみました。
以前Lambdaのレイヤの説明してましたので興味あれば:
https://qiita.com/Oukaria/items/0edfd9eaeee87d759c52
JanomeはPythonの形態素解析エンジンです。日本語のテキストを最小単位(トークン)ごとに分割して品詞を判定したり分かち書き(単語に分割)したりすることがでます。
TokenizerをインポートしてTokenizerオブジェクトのインスタンスを生成、tokenize()メソッドに対象の文字列を渡す。tokenize()メソッドはjanome.tokenizer.Tokenオブジェクトのジェネレータを返す。
Janomeのコードサンプル



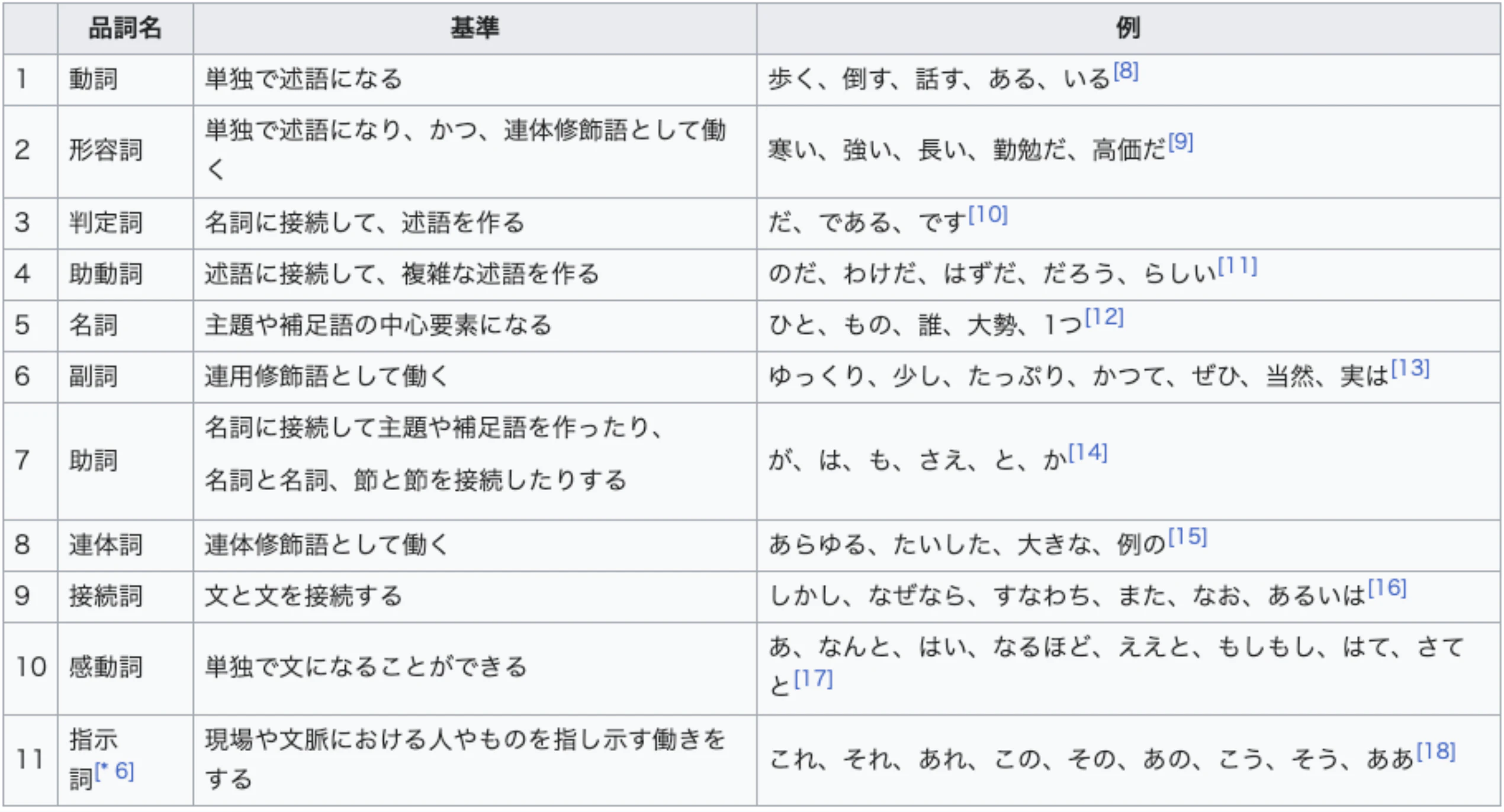
品詞
Janomeは品詞なら4パートに分けてます:
品詞,品詞細分類1,品詞細分類2,品詞細分類3
いい使い方
言葉のジャンルを見えれば良い言葉を選べる
フィルター追加して、名前だけを選ぶと

token_filtersのオプション
tokenizerの出力に対して、小文字化,品詞によるトークンのフィルタリングなどを行います。
- CompoundNounFilter
Tokenizerによって分割されたトークンを複合名詞として扱えるように再結合するクラスです。
e.g. "形態素/解析/器" ⇒ "形態素解析器"
- ExtractAttirbuteFilter
Token内から指定した属性の情報を取り出します。
e.g. ExtractAttributeFilter("base_form")ではそのトークンの基本形が抽出されます。
- LowerCaseFilter
Tokenのsurfaceとbase_formを小文字に変換します。
- POSKeepFilter
引数に入れた品詞に該当するTokenは残し、それ以外のTokenを除外します。
e.g. POSKeepFilter(["動詞"])とすると、‘動詞,自立,*,*’や‘動詞,非自立,*,*’などが残ります。
- POSStopFilter
POSKeepFilterの逆で、引数に入れた品詞に該当するTokenを除外します。
- TokenCountFilter
入力テキスト内の単語出現回数を数える。単語と出現回数をペアとして出力します。
トークンの使い方
やっと綺麗な言葉の分割が出来ましたが、どうやって使うか?
色んな使い方がありまして、今回はワードクラウドを作ってみました!
ワードクラウドとは
文章や大量のテキストに出てくる単語を「出現頻度に応じた大きさ」で並べて可視化する図です。よく出る語ほど大きく表示され、全体の話題感を直感的につかめます。
何が分かる?
どんな語が目立つか(話題の中心・キーワード)
例えば:

トークンとの関係:tf–idf
「term frequency–inverse document frequency」
Term Frequency - Inverse Document Frequencyはテキストの中でどこの言葉が意味が高いを選べる方法です。googleや図書館などで使われています。
- Term Frequencyはどれぐらいテキストの中で出て来る
- Inverse Document Frequencyはテキストの中でレアさ
意味が高いとは、大きなテキストの中でたまーに出て来る言葉のことです。つまり、出現頻度の低い言葉のことになります。

こまかいところ
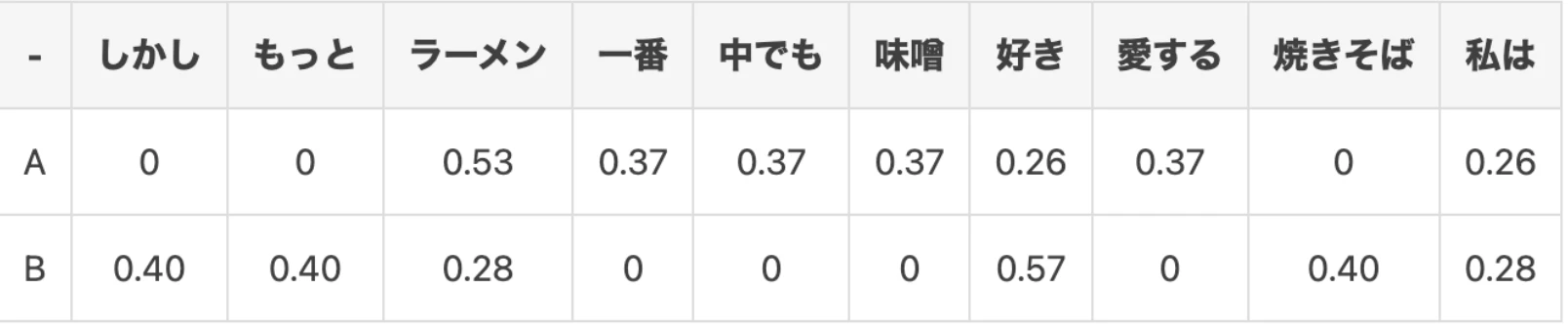
A:私はラーメンが好きだ。中でも味噌ラーメンが一番好きだ。
B:私は焼きそばが好きだ。しかしラーメンはもっと好きだ。
Aなら:tf値とTF-IDF値を比較したときに、「ラーメン」に関しては同じ値ですが、「味噌」に関してはTF-IDFの方が値が大きくなっています。これは、文書Aにおいて「味噌」という単語のレア度が高い(=文書を特徴付ける単語になっている)ためだと考えられます。

ざっくりの作成
今回は二つのライブラリを使います:
Pandasは表データをいじる道具
読む・整える・結合する・集計する。
scikit-learn(sklearn)は整えたデータで学習する道具
前処理 ➜ モデル学習 ➜ 予測・評価まで同じ書き方でできる。
サンプルコード:
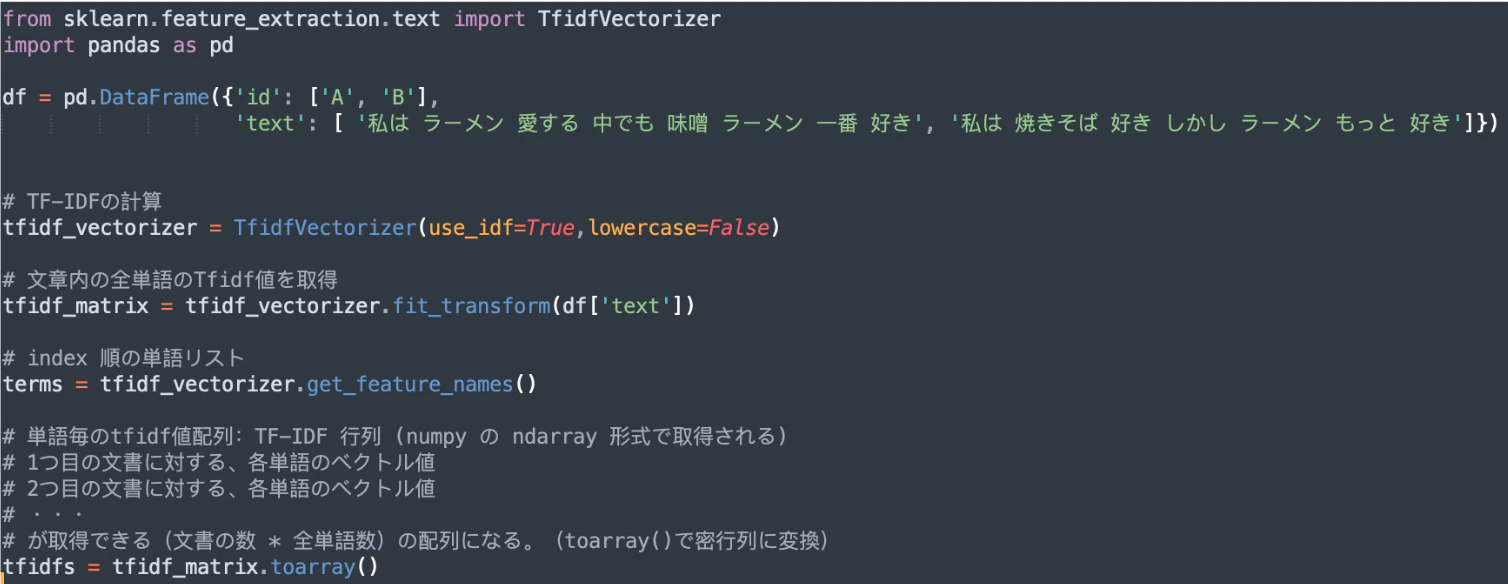
Termsは文の中で選ばれたtokenです。
tfidfsはそのtokenの中で結果です。
実行結果:

言語の問題
普通のテキストをvectorすると勝手にtokenを作成してくれます。英語だとスペースで切れますので言葉ごとで別れるだけど日本語はないのでこれのせいで日本語を3文字で割れてます、それなら「あれば」「だけど」などの文字出ます。
それでキレイに作りたいなら自分でtokenを作成しなきゃ。
「私はラーメンが好きだ。中でも味噌ラーメンが一番好きだ。」
ちゃんとしてるtokenなら:
「私」「ラーメン」「好き」「中」「味噌」「ラーメン」「一番」「好き」
ワードクラウドのpythonライブラリに入れたら結果は見えます。
意見
メリット
- 純Python・導入が簡単
追加のネイティブ依存がなく、pip install janome で完結。Docker/Windows環境でもハマりにくい。
- 辞書同梱で即使える
追加ダウンロードや設定なしで基本的な解析が可能。小規模スクリプトやプロトタイプに向く。
- 使い方がシンプル
APIが分かりやすく、トークン列・品詞情報・基本形などの取得までが最短コードで書ける。
- ユーザー辞書対応
頻出の固有名詞や専門用語を追加して精度を補強できる。
- 軽量で学習コストが低い
形態素解析を初めて触る人、教育用途、簡単な前処理用途に向く。
- ライセンスが緩やか(MIT系)
商用利用でも扱いやすい。
デメリット
- 速度はMeCabやSudachiに劣りがち
C/C++実装のMeCabや、高速化された他エンジンと比べると大量テキスト処理で遅いことがある。
- 語彙のカバレッジ/未知語対応は限定的
新語・ネットスラング・業界用語には素のままだと弱く、ユーザー辞書の整備が必要。
- 機能の幅はやや控えめ
多段モードや分割粒度の切替(A/B/Cモードのような)を持つSudachiほど柔軟ではない。
- 極端に高い精度が要る場合は不足
品詞細分類や固有表現抽出を高精度で行いたい場合、専用モデル(GiNZA/SpaCy日本語、Sudachi+追加処理等)に軍配が上がることが多い。
こんなときにJanomeが向く
- 解析の導入を最速で済ませたい(研究メモ、社内スクリプト、ETL前処理)。
- 環境依存を避けたい(ネイティブビルド不可の環境やWindows配布)。
- 小〜中規模データで簡易トークナイズと品詞取得が目的。