はじめに
DBのデータ異常検知というと、検知したいデータを抽出して
それをDB以外の何かしらの処理で判定するイメージですが
BigQueryにはERROR関数という関数でも検知できるのでご紹介します。
ERROR関数について
こちらに詳細があるので参照ください。
この関数は出力するとBigQueryのクエリ実行結果がエラーになります。
これがどう検知に繋がる?ってことで例をご紹介します。
例
データ重複
重複を検知したい場合
例:idが重複した場合は異常
SELECT
ERROR('id is not unique.')
FROM
table
GROUP BY
id
Having
count(1) > 1
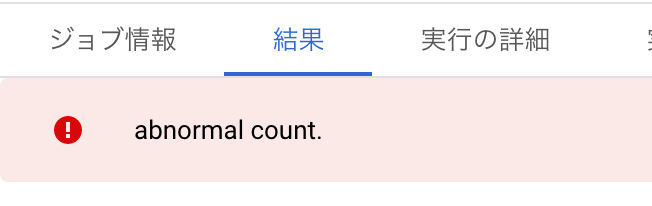
ERROR関数が出力されると以下のように実行結果がエラーとなります。
クエリが失敗したらアラートを投げる要領で異常検知ができるのがSQL書く人には嬉しいですね。

異常件数
指定件数より少ないなら異常としたい場合
例:10,000件より少ない場合は異常
SELECT
CASE
WHEN count(1) < 10000 THEN ERROR('abnormal count.')
END
FROM
table
特定の値の件数が指定割合より少ないなら異常としたい場合
例:statusがNewの割合が全体の10%より低い場合は異常
SELECT
CASE
WHEN status = 'New' and rate < 10 THEN ERROR('abnormal rate.')
END AS check
FROM (
SELECT
status
,(count(1) * 100)/(select count(1) from table) as rate
FROM
table
GROUP BY
rate
)

おまけ:ASSERT
ERROR関数に用途が似ているASSERTというステートメントがあります。
結果をboolで返す必要があり、falseの場合エラーとなるステートメントです。
これを使っても先の例と同等の検知は可能です。
ただし、ASSERTの場合はbool型の1レコードで返さないといけないので
先の"指定割合より少ないなら異常としたい場合"例だと
case文にelse true/falseつけないとboolにならないとか
group by checkしないとレコードが一意にならないとかで
正常にASSERTを通すためだけに、本来の目的よりも余分なクエリを書く必要があります。
目的が特定の異常検知だけであれば、ERROR関数の方が目的に沿った検知だけできて
お手軽だな。という使ってみての所感です。
テスト目的でデータ全体の事前評価をするとかであれば
ASSERTの方が網羅性があうケースも多々あるでしょうし
用途や書き方によってはASSERTの方がスッキリ書けることもあるかと思います。
お好みや用途に合わせてお使いいただくと良さそうです
最後に
BigQueryのデータ異常検知の手段として
SQL書く人にとってはお手軽に作れる粋な関数の紹介でした
特にデータの抽出内容を高頻度で変えてる場合は
仕込んでおくと盾になってくれるやもしれません。
ご参考までにの例のご紹介でした。